
Financial regulations and compliance are constantly changing, and automation of compliance reporting has emerged as a game changer in the financial industry. Amazon Web Services (AWS) generative AI solutions offer a seamless and efficient approach to automate this reporting process. The integration of AWS generative AI into the compliance framework not only enhances efficiency but also instills a greater sense of confidence and trust in the financial sector by promoting precision and timely delivery of compliance reports. These solutions help financial institutions avoid the costly and reputational consequences of noncompliance. This, in turn, contributes to the overall stability and integrity of the financial ecosystem, benefiting both the industry and the consumers it serves.
Amazon Bedrock is a managed generative AI service that provides access to a wide array of advanced foundation models (FMs). It includes features that facilitate the efficient creation of generative AI applications with a strong focus on privacy and security. Getting a good response from an FM relies heavily on using efficient techniques for providing prompts to the FM. Retrieval Augmented Generation (RAG) is a pivotal approach to augmenting FM prompts with contextually relevant information from external sources. It uses vector databases such as Amazon OpenSearch Service to enable semantic searching of the contextual information.
Amazon Bedrock Knowledge Bases, powered by vector databases such as Amazon OpenSearch Serverless, helps in implementing RAG to supplement model inputs with relevant information from factual resources, thereby reducing potential hallucinations and increasing response accuracy.
Amazon Bedrock Agents enables generative AI applications to execute multistep tasks using action groups and enable interaction with APIs, knowledge bases, and FMs. Using agents, you can design intuitive and adaptable generative AI applications capable of understanding natural language queries and creating engaging dialogues to gather details required for using the FMs effectively.
A suspicious transaction report (STR) or suspicious activity report (SAR) is a type of report that a financial organization must submit to a financial regulator if they have reasonable grounds to suspect any financial transaction that has occurred or was attempted during their activities. There are stipulated timelines for filing these reports and it typically takes several hours of manual effort to create one report for one customer account.
In this post, we explore a solution that uses FMs available in Amazon Bedrock to create a draft STR. We cover how generative AI can be used to automate the manual process of draft generation using account information, transaction details, and correspondence summaries as well as creating a knowledge base of information about fraudulent entities involved in such transactions.
Solution overview
The solution uses Amazon Bedrock Knowledge Bases, Amazon Bedrock Agents, AWS Lambda, Amazon Simple Storage Service (Amazon S3), and OpenSearch Service. The workflow is as follows:
- The user requests for creation of a draft STR report through the business application. The application calls Amazon Bedrock Agents, which has been preconfigured with detailed instructions to engage in a conversational flow with the user. The agent follows these instructions to gather the required information from the user, completes the missing information by using actions groups to invoke the Lambda function, and generates the report in the specified format. Following its instructions, the agent invokes Amazon Bedrock Knowledge Bases to find details about fraudulent entities involved in the suspicious transactions. Amazon Bedrock Knowledge Bases queries OpenSearch Service to perform semantic search for the entities required for the report. If the information about fraudulent entities is available in Amazon Bedrock Knowledge Bases, the agent follows its instructions to generate a report for the user. If the information isn’t found in the knowledge base, the agent uses the chat interface to prompt the user to provide the website URL that contains the relevant information. Alternatively, the user can provide a description about the fraudulent entity in the chat interface. If the user provides a URL for a publicly accessible website, the agent follows its instructions to call the action group to invoke a Lambda function to crawl the website URL. The Lambda function scrapes the information from the website and returns it to the agent for use in the report. The Lambda function also stores the scraped content in an S3 bucket for future use by the search index. Amazon Bedrock Knowledge Bases can be programmed to periodically scan the S3 bucket to index the new content in OpenSearch Service.
The following diagram illustrates the solution architecture and workflow.
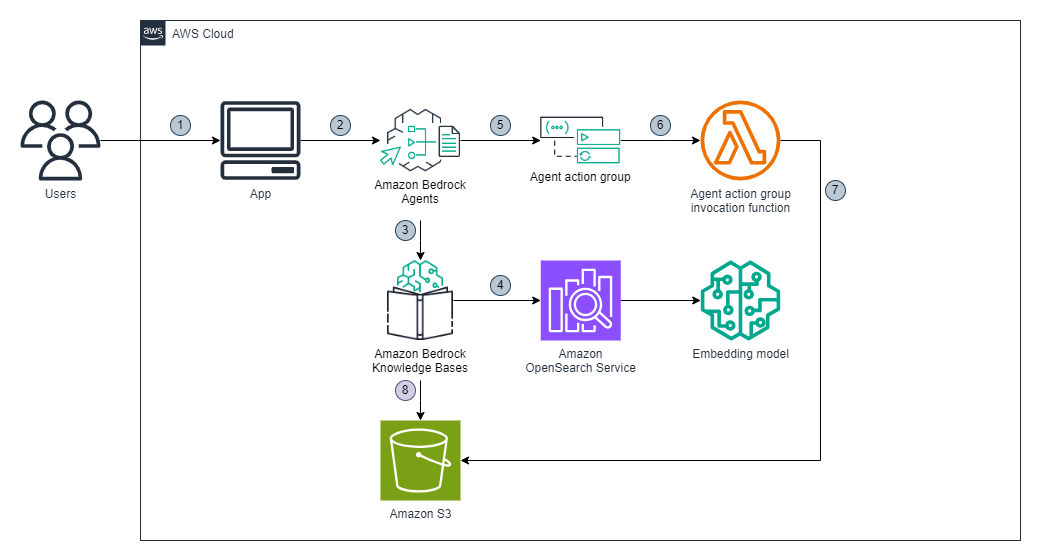
You can use the full code available in GitHub to deploy the solution using the AWS Cloud Development Kit (AWS CDK). Alternatively, you can follow a step-by-step process for manual deployment. We walk through both approaches in this post.
Prerequisites
To implement the solution provided in this post, you must enable model access in Amazon Bedrock for Amazon Titan Text Embeddings V2 and Anthropic Claude 3.5 Haiku.
Deploy the solution with the AWS CDK
To set up the solution using the AWS CDK, follow these steps:
- Verify that the AWS CDK has been installed in your environment. For installation instructions, refer to the AWS CDK Immersion Day Workshop. Update the AWS CDK to version 36.0.0 or higher:
- Initialize the AWS CDK environment in the AWS account:
- Clone the GitHub repository containing the solution files:
- Navigate to the solution directory:
- Create and activate the virtual environment:
Activating the virtual environment differs based on the operating system. Refer to the AWS CDK workshop for information about activating in other environments.
- After the virtual environment is activated, install the required dependencies:
- Deploy the backend and frontend stacks:
- When the deployment is complete, check these deployed stacks by visiting the AWS CloudFormation console, as shown in the following two screenshots.
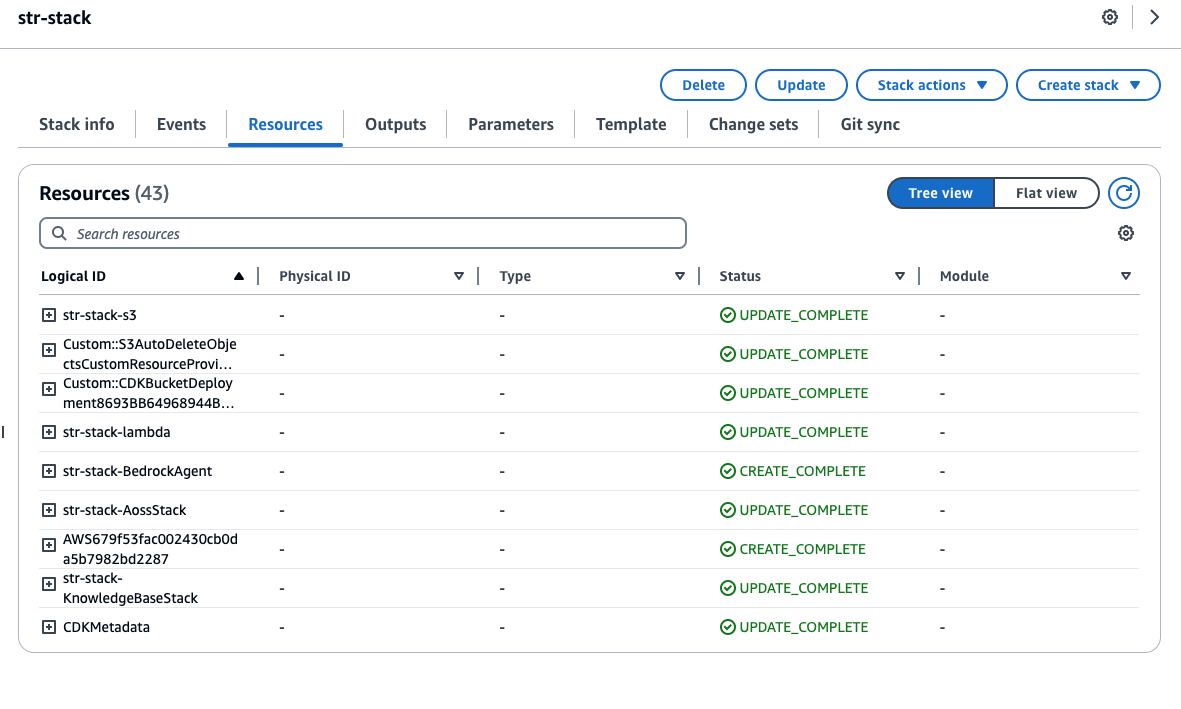
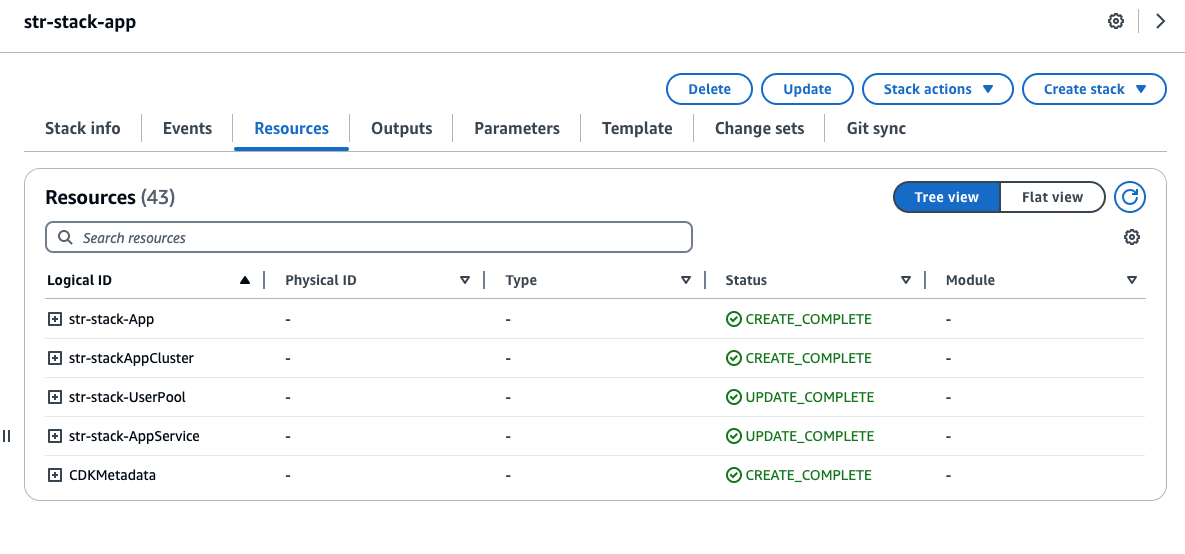
Manual deployment
To implement the solution without using the AWS CDK, complete the following steps:
- Set up an S3 bucket. Create a Lambda function. Set up Amazon Bedrock Knowledge Bases. Set up Amazon Bedrock Agents.
Visual layouts in some screenshots in this post might look different than those on your AWS Management Console.
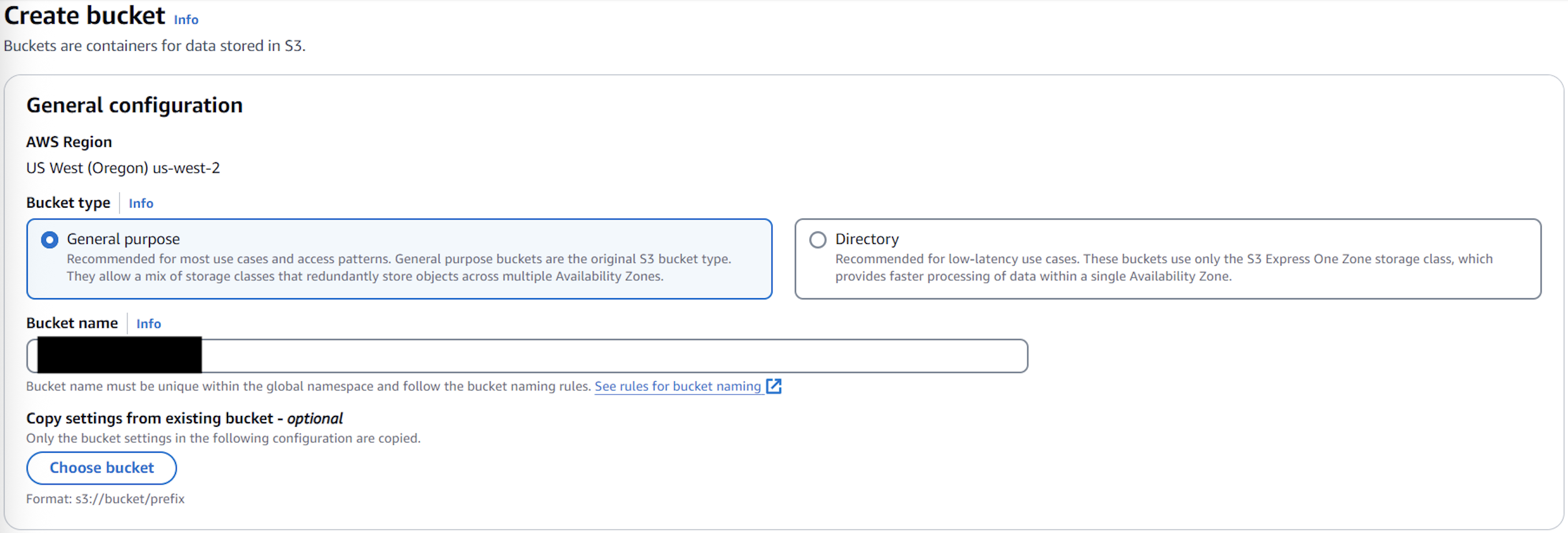
Set up an S3 bucket
Create an S3 bucket with a unique bucket name for the document repository, as shown in the following screenshot. This will be a data source for Amazon Bedrock Knowledge Bases.
Create the website scraper Lambda function
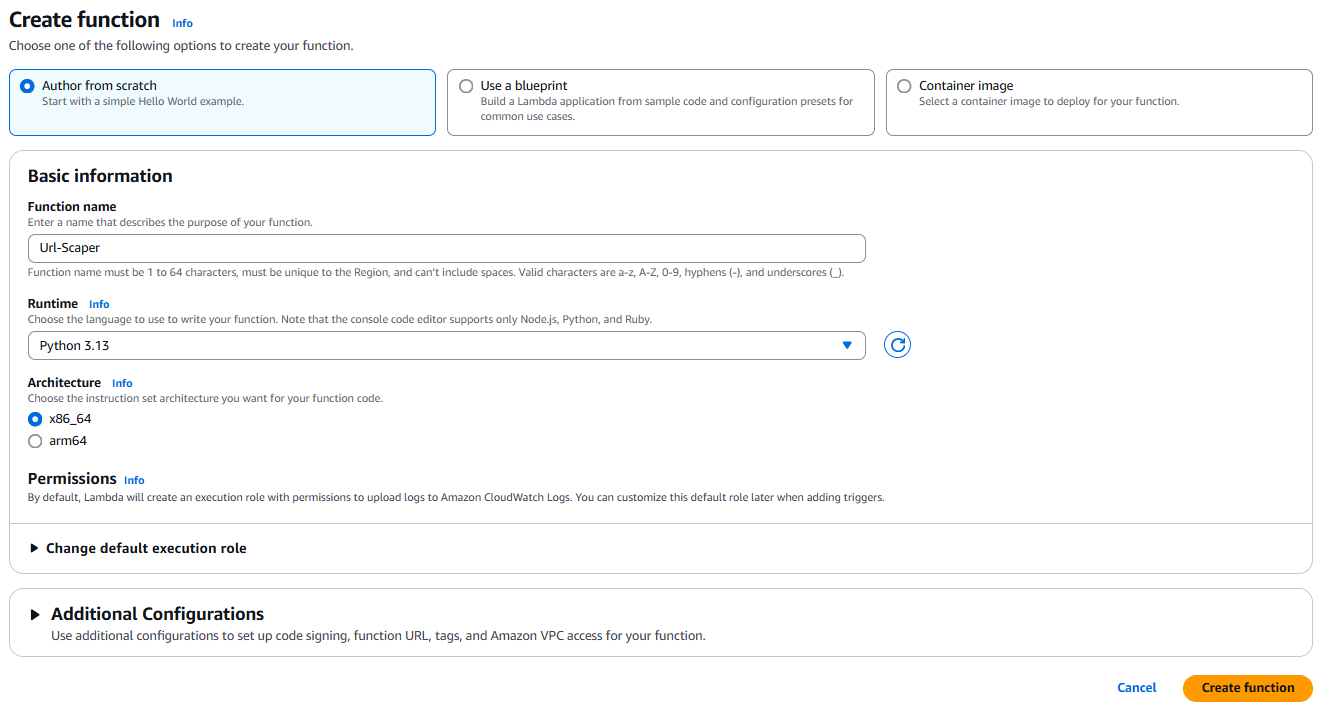
Create a new Lambda function called Url-Scraper using the Python 3.13 runtime to crawl and scrape the website URL provided by Amazon Bedrock Agents. The function will scrape the content, send the information to the agent, and store the contents in the S3 bucket for future references.
Error handling has been skipped in this code snippet for brevity. The full code is available in GitHub.
Create a new file called search_suspicious_party.py with the following code snippet:
Replace the default generated code in lambda_function.py with the following code:
Configure the Lambda function
Set up a Lambda environment variable S3_BUCKET, as shown in the following screenshot. For Value, use the S3 bucket you created previously.

Increase the timeout duration for Lambda function to 30 seconds. You can adjust this value based on the time it takes for the crawler to complete its work.

Set up Amazon Bedrock Knowledge Bases
Complete the following steps to create a new knowledge base in Amazon Bedrock. This knowledge base will use OpenSearch Serverless to index the fraudulent entity data stored in Amazon S3. For more information, refer to Create a knowledge base by connecting to a data source in Amazon Bedrock Knowledge Bases.
- On the Amazon Bedrock console, choose Knowledge bases in the navigation pane and choose Create knowledge base. For Knowledge base name, enter a name (for example,
str-knowledge-base). For Service role name, keep the default system generated value. 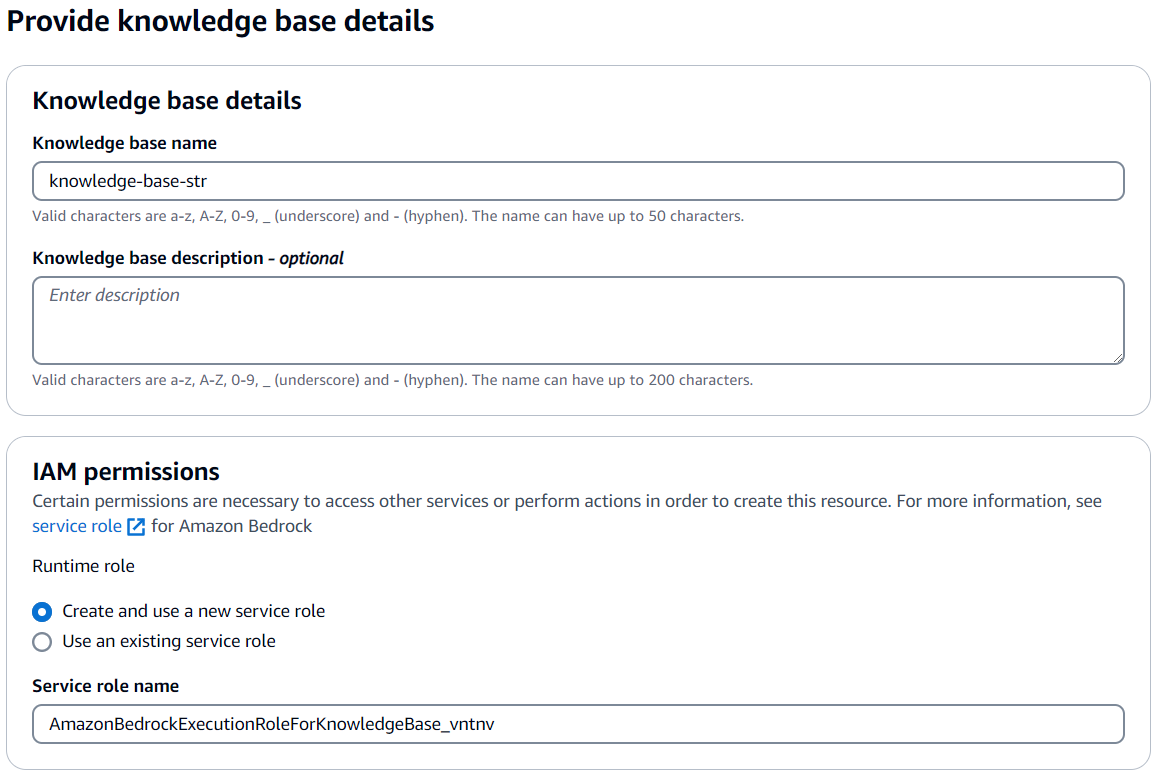
- Select Amazon S3 as the data source.
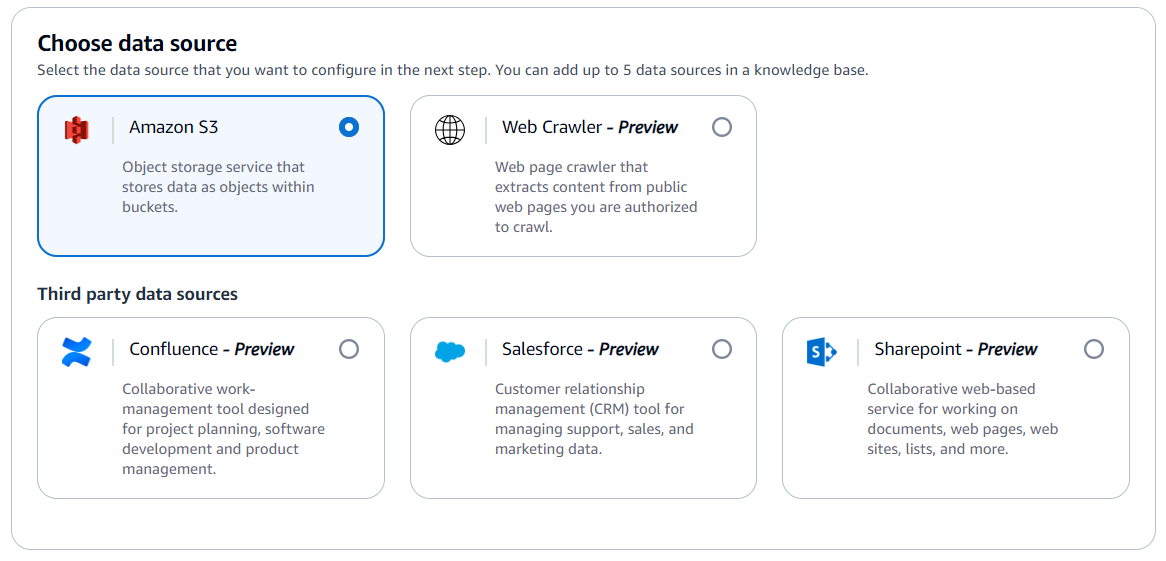
- Configure the Amazon S3 data source:
- For Data source name, enter a name (for example,
knowledge-base-data-source-s3). For S3 URI, choose Browse S3 and choose the bucket where information scraped by web crawler about fraudulent entities is available for the knowledge base to use. Keep all other default values. 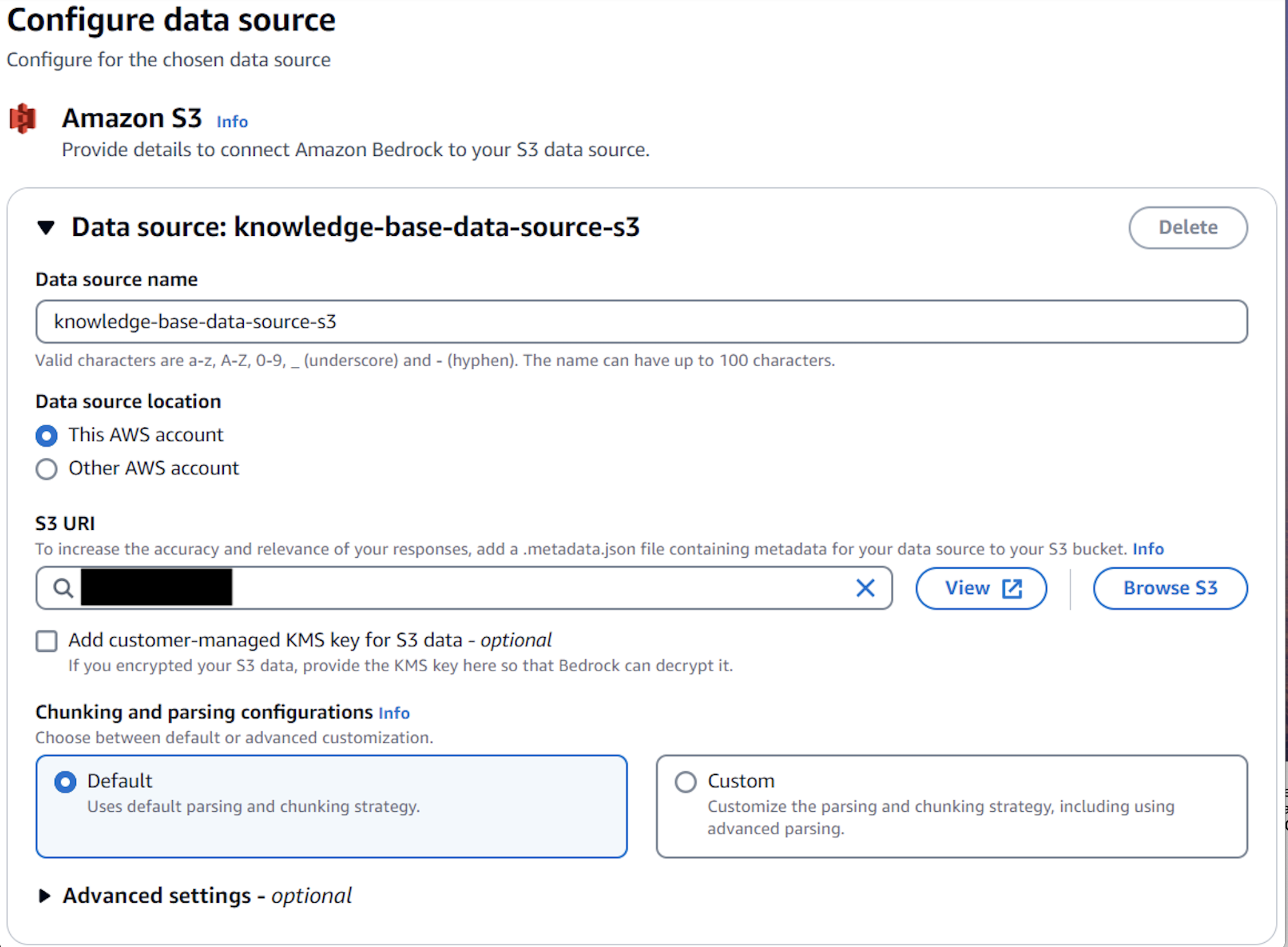
- For Embeddings model, choose Titan Text Embeddings V2.
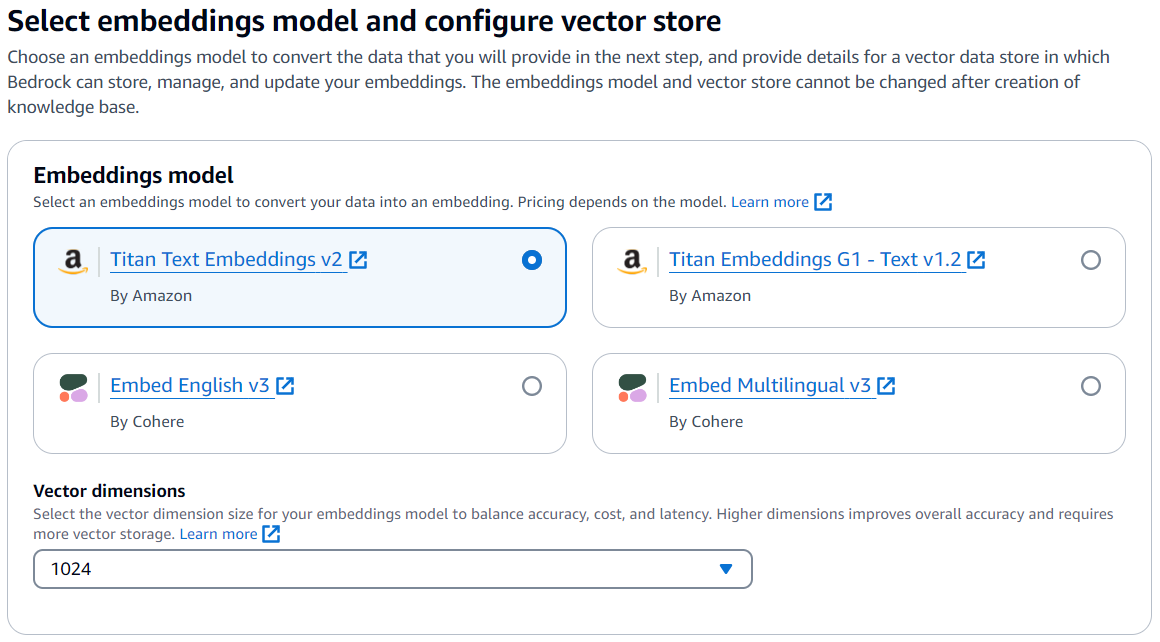
- For Vector database, select Quick create a new vector store to create a default vector store with OpenSearch Serverless.
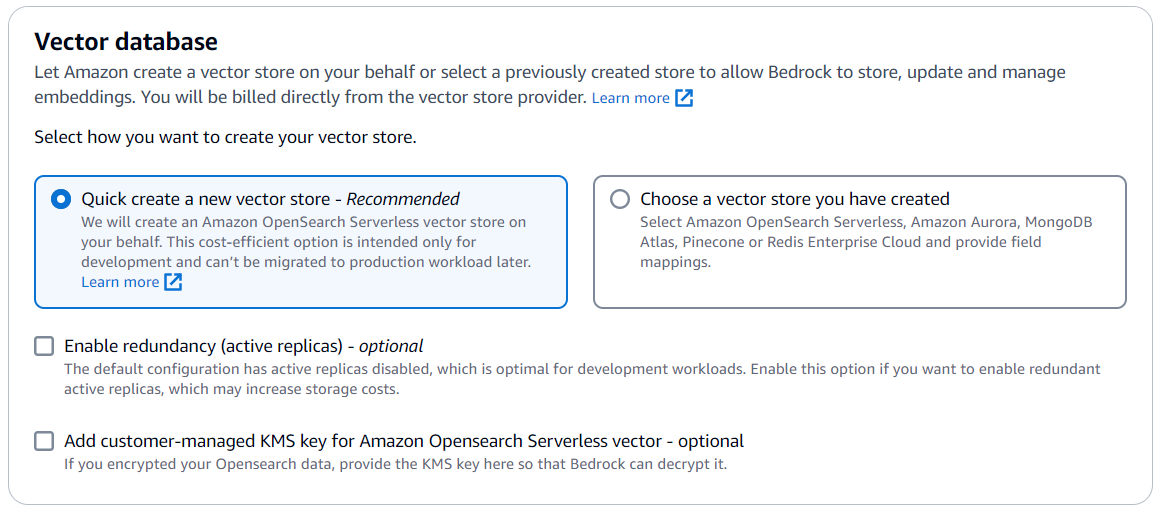
- Review the configurations and choose Create knowledge base.
After the knowledge base is successfully created, you can see the knowledge base ID, which you will need when creating the agent in Amazon Bedrock.
- Select
knowledge-base-data-source-s3 from the list of data sources and choose Sync to index the documents. 
Set up Amazon Bedrock Agents
To create a new agent in Amazon Bedrock, complete the following steps. For more information, refer to Create and configure agent manually.
- On the Amazon Bedrock console, choose Agents in the navigation pane and choose Create Agent. For Name, enter a name (for example,
agent-str). Choose Create. 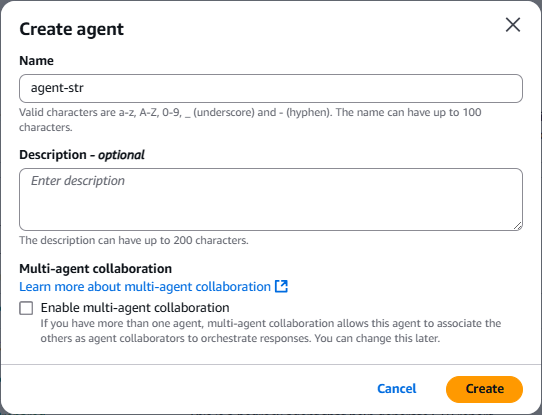
- For Agent resource role, keep the default setting (Create and use a new service role). For Select model, choose a model provider and model name (for example, Anthropic’s Claude 3.5 Haiku) For Instructions for the Agent, provide the instructions that allow the agent to invoke the large language model (LLM).
You can download the instructions from the agent-instructions.txt file in the GitHub repo. Refer to next section in this post to understand how to write the instructions.
- Keep all other default values. Choose Save.
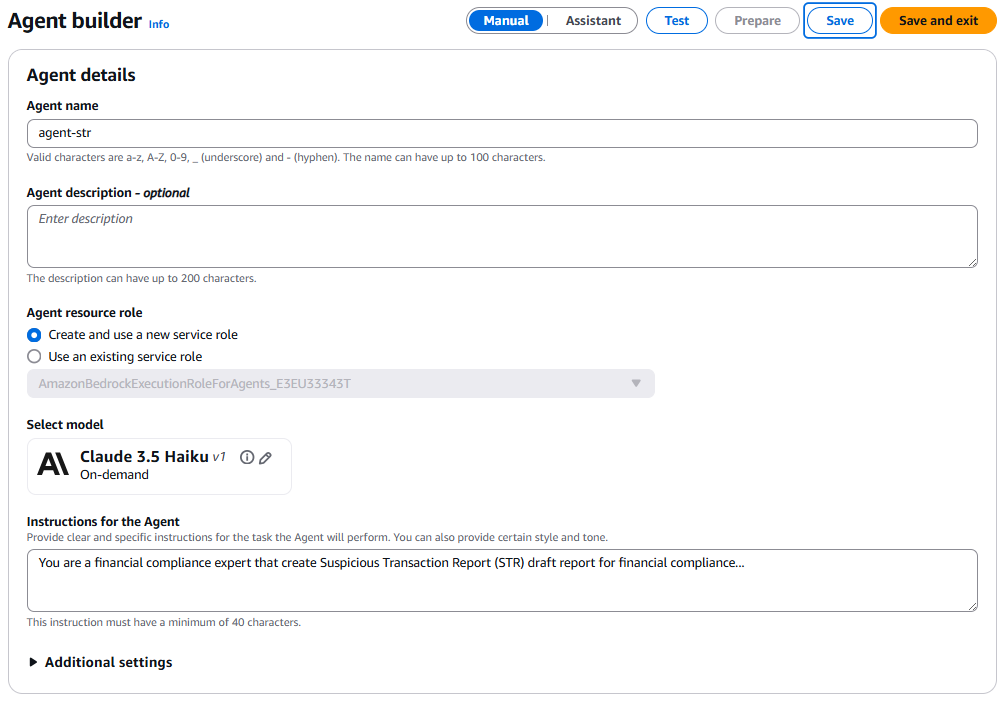
- Under Action groups, choose Add to create a new action group.
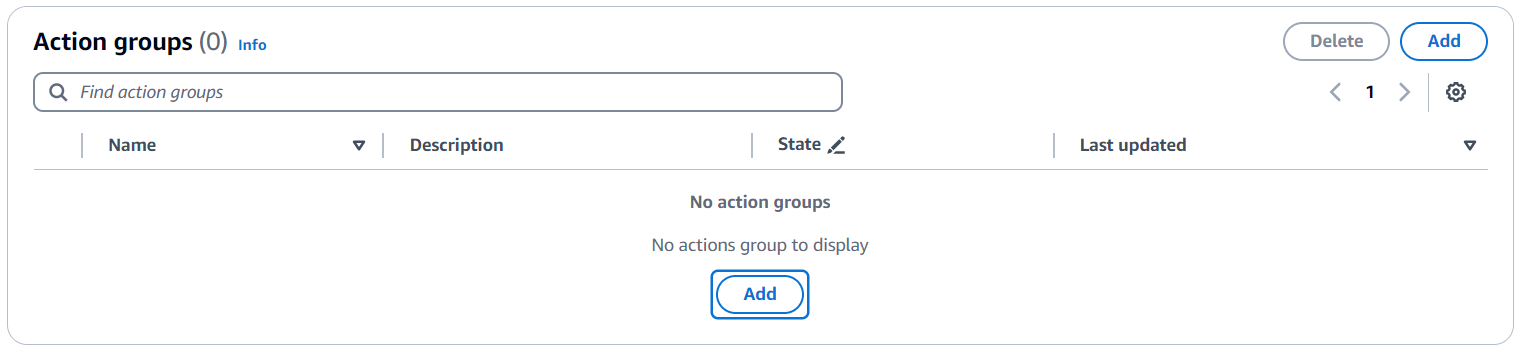
An action is a task the agent can perform by making API calls. A set of actions comprises an action group.
- Provide an API schema that defines all the APIs in the action group. For Action group details, enter an action group name (for example,
agent-group-str-url-scraper). For Action group type, select Define with API schemas. For Action group invocation, select Select an existing Lambda function, which is the Lambda function that you created previously. 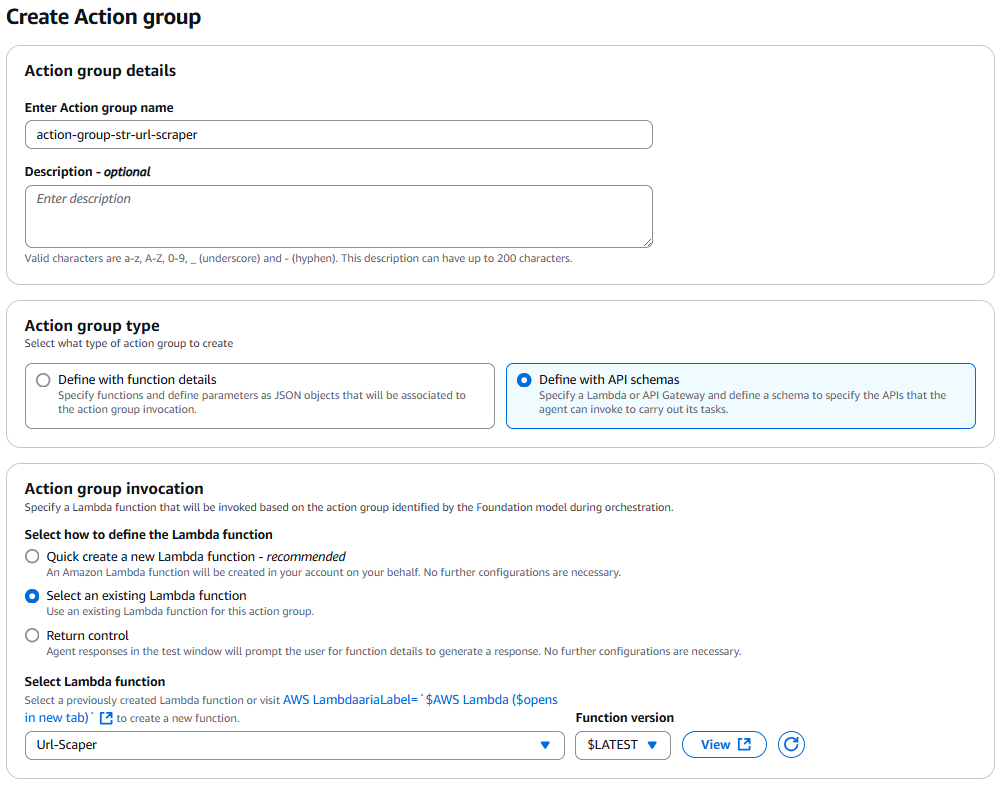
- For Action group schema, choose Define via in-line schema editor. Replace the default sample code with the following example to define the schema to specify the input parameters with default and mandatory values:
- Choose Create. Under Knowledge bases, choose Add.
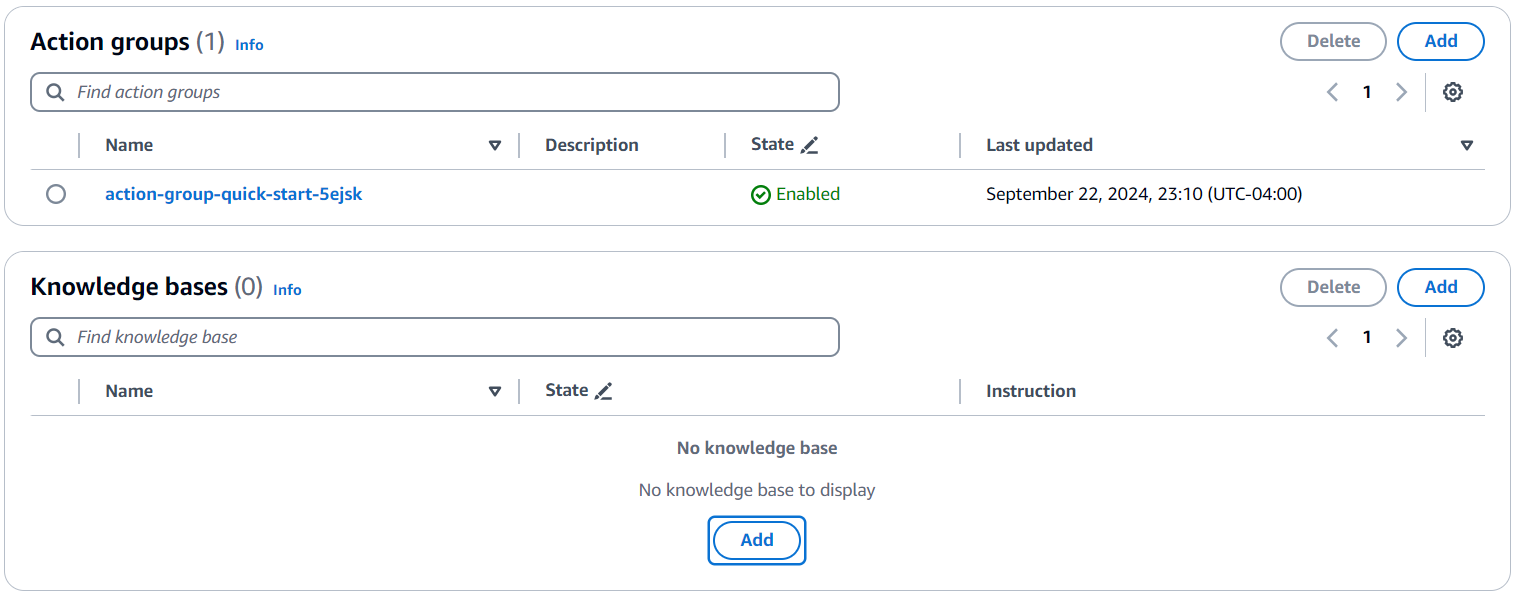
- For Select knowledge base, choose
knowledge-base-str, which you created previously, and add the following instructions: Use the information in the knowledge-base-str knowledge base to select transaction reports.
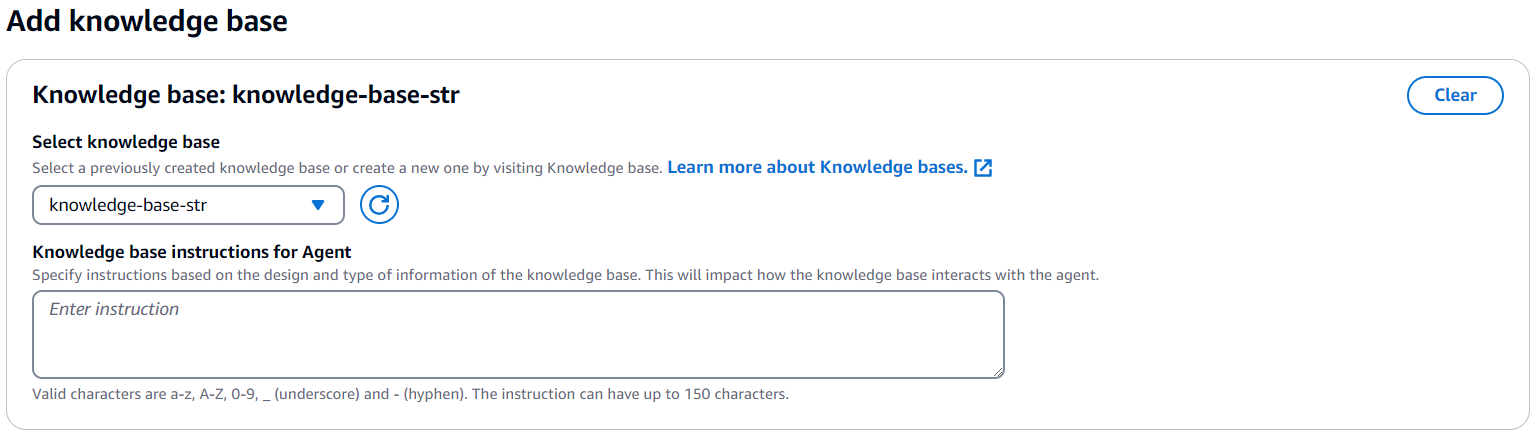
- Choose Save to save all changes. Finally, choose Prepare to prepare this agent to get it ready for testing.
You can also create a Streamlit application to create a UI for this application. The source code is available in GitHub.
Agent instructions
Agent instructions for Amazon Bedrock Agents provide the mechanism for a multistep user interaction to gather the inputs an agent needs to invoke the LLM with a rich prompt to generate the response in the required format. Provide logical instructions in plain English. There are no predefined formats for these instructions.
- Provide an overview of the task including the role:
- Provide the message that the agent can use for initiating the user interaction:
- Specify the processing that needs to be done on the output received from the LLM:
- Provide the optional messages that the agent can use for a multistep interaction to gather the missing inputs if required:
- Specify the actions that the agent can take to process the user input using action groups:
- Specify how the agent should provide the response, including the format details:
Test the solution
To test the solution, follow these steps:
- Choose Test to start testing the agent. Initiate the chat and observe how the agent uses the instructions you provided in the configuration step to ask for required details for generating the report. Try different prompts, such as “Generate an STR for an account.”
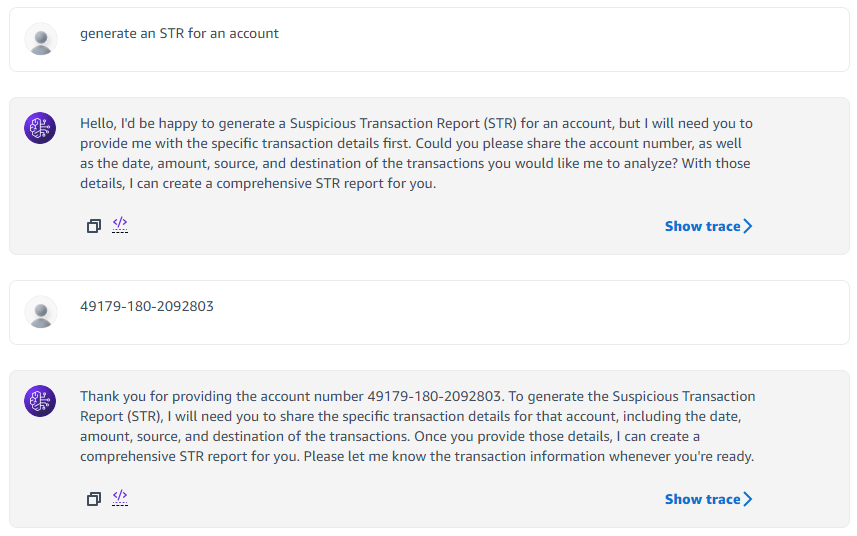
The following screenshot shows an example chat.
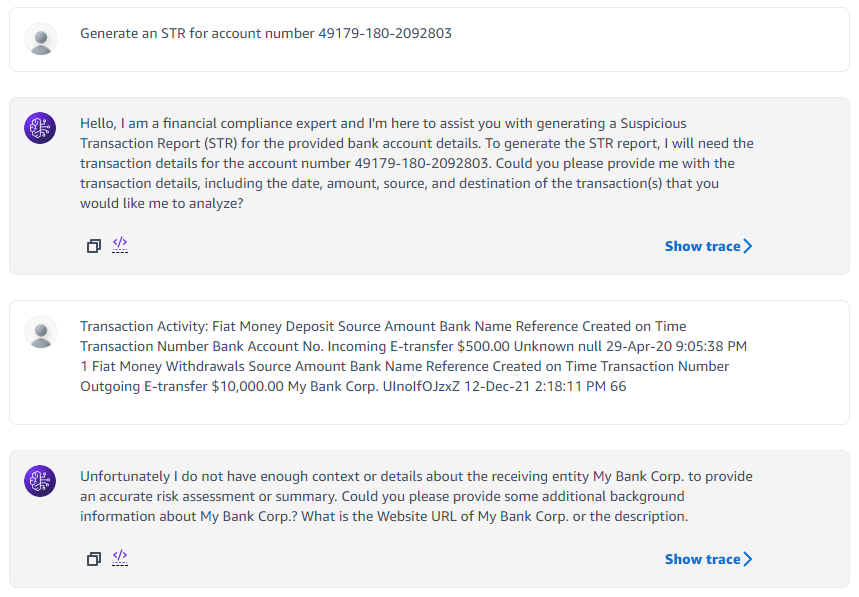
The following screenshot shows an example chat with the prompt, “Generate an STR for account number 49179-180-2092803.”
Another option is to provide all the details at the same time, for example, “Generate an STR for account number 12345-999-7654321 with the following transactions.”
- Copy and paste the sample transactions from the sample-transactions.txt file in GitHub.
The agent keeps asking for missing information, such as account number, transaction details, and correspondence history. After it has all the details, it will generate a draft STR document.
The code in GitHub also contains a sample StreamLit application that you can use to test the application.
Clean up
To avoid incurring unnecessary future charges, clean up the resources you created as part of this solution. If you created the solution using the GitHub code sample and the AWS CDK, empty the S3 bucket and delete the CloudFormation stack. If you created the solution manually, complete the following steps:
- Delete the Amazon Bedrock agent. Delete the Amazon Bedrock knowledge base. Empty and delete the S3 bucket if you created one specifically for this solution. Delete the Lambda function.
Conclusion
In this post, we showed how Amazon Bedrock offers a robust environment for building generative AI applications, featuring a range of advanced FMs. This fully managed service prioritizes privacy and security while helping developers create AI-driven applications efficiently. A standout feature, RAG, uses external knowledge bases to enrich AI-generated content with relevant information, backed by OpenSearch Service as its vector database. Additionally, you can include metadata fields in the knowledge base and agent session context with Amazon Verified Permissions to pass fine-grained access context for authorization.
With careful prompt engineering, Amazon Bedrock minimizes inaccuracies and makes sure that AI responses are grounded in factual documentation. This combination of advanced technology and data integrity makes Amazon Bedrock an ideal choice for anyone looking to develop reliable generative AI solutions. You can now explore extending this sample code to use Amazon Bedrock and RAG for reliably generating draft documents for compliance reporting.
About the Authors
 Divyajeet (DJ) Singh is a Senior Solutions Architect at AWS Canada. He loves working with customers to help them solve their unique business challenges using the cloud. Outside of work, he enjoys spending time with family and friends and exploring new places.
Divyajeet (DJ) Singh is a Senior Solutions Architect at AWS Canada. He loves working with customers to help them solve their unique business challenges using the cloud. Outside of work, he enjoys spending time with family and friends and exploring new places.
 Parag Srivastava is a Senior Solutions Architect at AWS, where he has been helping customers successfully apply generative AI to real-life business scenarios. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
Parag Srivastava is a Senior Solutions Architect at AWS, where he has been helping customers successfully apply generative AI to real-life business scenarios. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
 Sangeetha Kamatkar is a Senior Solutions Architect at AWS who helps customers with successful cloud adoption and migration. She works with customers to craft highly scalable, flexible, and resilient cloud architectures that address customer business problems. In her spare time, she listens to music, watches movies, and enjoys gardening during summertime.
Sangeetha Kamatkar is a Senior Solutions Architect at AWS who helps customers with successful cloud adoption and migration. She works with customers to craft highly scalable, flexible, and resilient cloud architectures that address customer business problems. In her spare time, she listens to music, watches movies, and enjoys gardening during summertime.
 Vineet Kachhawaha is a Senior Solutions Architect at AWS focusing on AI/ML and generative AI. He co-leads the AWS for Legal Tech team within AWS. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value.
Vineet Kachhawaha is a Senior Solutions Architect at AWS focusing on AI/ML and generative AI. He co-leads the AWS for Legal Tech team within AWS. He is passionate about working with enterprise customers and partners to design, deploy, and scale AI/ML applications to derive business value.
