
Welcome to machine learning for software engineers. Each week, I share a lesson in AI from the past week, some resources to help you become a better engineer, some other interesting things that happened, and usually job postings (but I’m still figuring this one out). All content is geared towards software engineers and those that like building software products.
If you’re interested in receiving these directly in your inbox, make sure to subscribe.
There have been a lot of comments about the progress that Google has made within the past year or so and how quickly Google’s models have developed. This is usually shared as Google making a massive comeback because they were behind before.
If you’re an avid reader of machine learning for software engineers, this comeback really shouldn’t have surprised you. Google is one of the few companies that has the three pillars needed to be successful in AI development.
What should be surprising to you and to most people is how quickly Google was able to not only develop incredible models, but also turn around the public perception of their models. Google accomplished this by doing one simple thing really well and this one simple thing is fundamental to all of software development.
If you’ve been following Google developers on social media, you’ve seen this happen in real time over the past year or so. Instead of determining internally what needs to be done to push AI developments forward, Google engineers have turned to their user base via social media to understand what they want and deliver it.
This is huge for many reasons.
First: Those building the product get high-quality feedback. Instead of determining action items and what needs to be done to improve a platform through layers of leadership, product management, and engineering, the Google engineers were able to get feedback directly from the source.
Too many companies have processes that model receiving feedback and make it largely actionable. By getting it directly from the user base, it makes it really easy to understand what is valuable to clients and customers and enact what needs to be done to make that happen.
Second: It builds trust within the user base. Users are much more likely to trust a product and company when they can see the feedback they’re given is successfully received and acted upon.
Third: It builds a community. Community is huge in AI, especially for long-term success. An active and responsive community is huge for dispelling fear, uncertainty, and doubt within a user base. Community is also helpful when it comes to brand loyalty and developers trusting a platform to support their development long term.
Fourth: It increases development velocity. When products make enough of a profit and a team becomes comfortable with where it’s at development velocity slows down and isn’t prioritized. By receiving feedback and putting work items out publicly, it holds the team accountable to a development velocity that prioritizes their users.
If you find ML for SWEs helpful, please consider supporting it by becoming a paid subscriber. You also get access to more resources, more job postings, and more articles. Until we hit bestseller status, you can become a paid member for just $3 a month forever. After that, it’ll go up to $5.
I’m surprised at how few companies prioritize this. I used to think it was due to a fear of over promising and under delivering or that product teams were just comfortable with where they were at, but I’ve realized enabling this feedback and iterating cycle is a bit more complex.
First, it fundamentally takes power away from management and leadership and gives it to individual contributors. The individual contributors are the ones who are receiving the feedback, communicating with clients and deciding on the work items.
Second, and more importantly, enabling this cycle requires a shift in company culture. That shift also takes power away from management and leadership at a much larger scale that many companies aren’t willing to do.
For example, for this process to be effective, companies need to do a few things:
Dedicate work cycles to receiving feedback. Whether this is employees who are dedicated to this single task or cycles are allotted within each individual contributor's time to do this, it means allowing less time heads down.
Give employees more autonomy. If employees are unable to make their own decisions and decide the work that needs to be done, there’s no way this process can work. This process requires an inherent trust companies must have with their employees.
Prioritize development velocity. Teams need to be able to deliver upon their promises. Prioritizing development velocity is difficult because it’s often an effort that takes a while to yield results. Thus, management doesn’t prioritize it.
Enable a culture of risk-taking. Publicly receiving feedback introduces risk. Historically, senior executives do not like risk, but in tech it’s required for any innovation. This particular process won’t work if companies aren’t willing to tolerate risk. Employees won’t be willing to take the risks necessary if companies are constantly doing layoffs or putting pressure on employees based on delivering shareholder value instead of providing value to users.
Interestingly enough, most of this just comes back to hiring the right people to push products forward and to provide value for users. This is why machine learning and software engineers can make a great living if they can be one of ‘the right people’.
If there’s one takeaway you get from this lesson, it should be that software engineering is fundamentally an exercise in understanding and improving the user experience.
All software is built for an end user and by prioritizing that end user and what they need done (within the confines of how a system can be built) is how successful software is created.
That’s all for this week. Let me know if you have any questions and enjoy the resources below!
If you missed ML for SWEs last week, check it out the articles here:
Must reads to help you become a better engineer
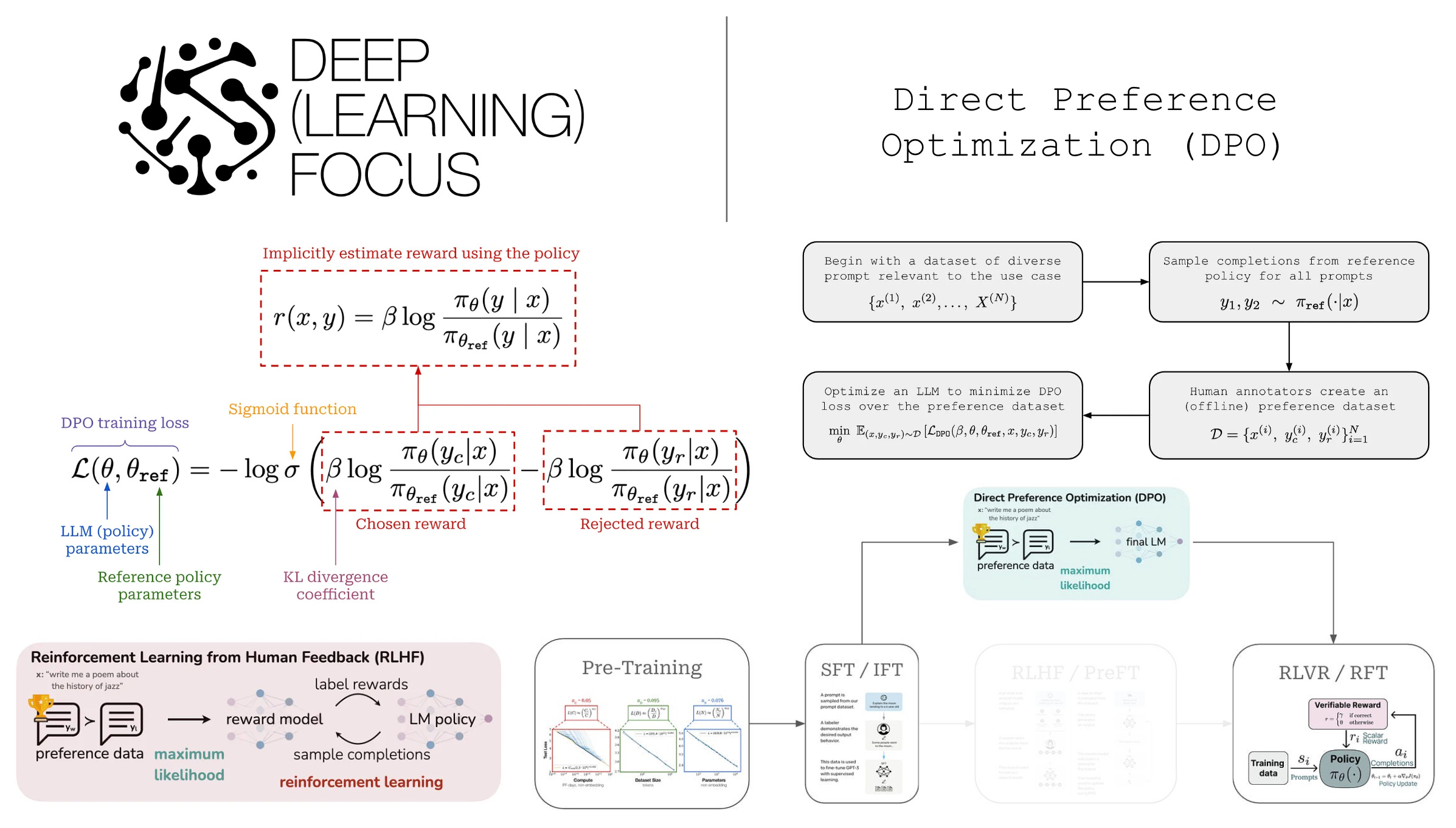
Direct Preference Optimization (DPO): an incredible, comprehensive overview of Direct Preference Optimization (DPO). An LLM alignment approach that uses a simpler objective optimized with gradient descent. DPO is important to understand how LLMs are post-trained to align their output with human preferences. Another incredible overview by .
AI Architectural Breakthroughs as a Computation-Scalable Process: AI is able to research and find architectural breakthroughs for the next generation of models on its own. AI can search for and test different architectures much faster than humans enabling new discoveries much more quickly. Essentially, this turns architecture discovery into a compute-bound process.

Kimi K2 is the most important model of the year [Breakdowns]: Kimi K2 represents a major shift in AI model development through its engineering. It’s especially worth reading about its optimizer. K2 isn’t just a scaled up LLM, but will drive improvements for AI systems of the future. A great breakdown here by .
Enabling Self-Improving Agents to Learn at Test Time With Human-In-The-Loop Guidance: A novel framework empowers Large Language Model agents to continuously learn and adapt to evolving knowledge in real-time operational settings. Large language model agents frequently fail in dynamic environments like regulatory compliance due to their inability to adapt to new information during operation. The Adaptive Reflective Interactive Agent (ARIA) framework solves this by enabling continuous learning of updated domain knowledge at test time.
A Comprehensive Evaluation on Quantization Techniques for Large Language Models: This comprehensive evaluation reveals optimal component strategies for Large Language Model quantization, addressing prior inconsistencies and uncovering new insights. Post-training quantization significantly reduces LLM memory and computational overhead, but diverse existing methods lack fair comparative evaluations. This study systematically analyzes state-of-the-art techniques by decoupling them into pre-quantization transformation and quantization error mitigation.
Other interesting things this week

Gemini 2.5 Flash-Lite is now ready for scaled production use: Gemini 2.5 Flash-Lite is stable and generally available as the fastest, lowest-cost model in the Gemini 2.5 family. It is priced at $0.10 per 1M input tokens and $0.40 per 1M output tokens, offering a 1 million-token context window. The model includes native reasoning capabilities and supports tools like Grounding with Google Search, Code Execution, and URL Context.
Qwen3-Coder: Agentic coding in the world: Qwen3-Coder-480B-A35B-Instruct is a 480B-parameter Mixture-of-Experts model with 35B active parameters. It natively supports a 256K token context length, extensible to 1M tokens with extrapolation methods. The model sets new state-of-the-art results among open models on Agentic Coding, Agentic Browser-Use, and Agentic Tool-Use.
Train a Reasoning-Capable LLM in One Weekend with NVIDIA NeMo: A reasoning model can be trained in approximately 48 hours on a single GPU. NVIDIA's Llama Nemotron family of open models is designed for high-performance reasoning. These models include a dynamic reasoning toggle, enabling switches between standard chat and advanced reasoning modes during inference via a system prompt instruction.
FastVLM: Efficient Vision Encoding for Vision Language Models: Vision Language Models (VLMs) enable visual understanding alongside textual inputs. VLM accuracy generally improves with higher input image resolution, which creates a tradeoff between accuracy and efficiency. FastVLM is a new VLM technique that significantly improves accuracy-latency trade-offs with a simple design and a hybrid architecture visual encoder.
Listen to a conversation about the newest AI capabilities in Search.: Robby Stein, VP of Product for Search, features in the latest Google AI: Release Notes podcast episode. Google Search capabilities include Gemini 2.5 Pro, Deep Search, and new multimodal features in AI Mode.
Google is destroying its own business - and still winning: Google held an earnings call where its CEO positioned Alphabet as strategically best placed across AI dimensions. Slack, GitHub, and Linear all had major new releases. A Replit user experienced a catastrophic mistake from an AI agent, which resulted in an apology from their CEO.
US AI Action Plan: President Trump directed the creation of an AI Action Plan during his second term in office. This Action Plan is based on three pillars: accelerating innovation, building AI infrastructure, and leading in international diplomacy and security. The Accelerate AI Innovation pillar includes initiatives such as removing red tape, encouraging open-source AI, and investing in AI-enabled science.
Alibaba’s new Qwen reasoning AI model sets open-source records: Alibaba's Qwen team released a new version of their open-source reasoning AI model called Qwen3-235B-A22B-Thinking-2507. This model's "thinking capability" was scaled up to improve the quality and depth of its reasoning.
Startups can apply now for the Google for Startups Gemini Founders Forum.: The Google for Startups Gemini Founders Forum, hosted by Google DeepMind and Google Cloud, is a two-day in-person summit in San Francisco from November 11–12. Series A startup founders will engage with Gemini APIs, Google AI tools, and product teams, and co-develop AI roadmaps. Applications are open until September 10.
Why your AI fails in Production [Guest]: The primary title is "Why your AI fails in Production." Devansh authored the content, published on July 23, 2025. The subtitle names real users, messy data, and infrastructure constraints as factors for lab model failure.
Pushing the boundaries of secure AI: Winners of the Amazon Nova AI Challenge: The Amazon Nova AI Challenge, focused on Trusted AI, began in January 2025 with ten university teams participating globally. Team PurpCorn-PLAN from the University of Illinois Urbana-Champaign won the Defending Team category, and Team PurCL from Purdue University won the Attacking Team category. The high-stakes finals were held in Santa Clara, California, on June 26–27.
AI Roundup 128: AI Action Plan: The Trump Administration unveiled an AI Action Plan to achieve global dominance in artificial intelligence. Drafted by the Office of Science and Technology Policy, the plan focuses on accelerating AI innovation, building infrastructure, and leading international diplomacy and security. It includes over 90 recommended policies, aiming to roll back regulatory hurdles for new AI models.
How to use other models like Gemini 2.5 Pro in Claude Code | MCP is all you need!: Other models, including Gemini 2.5 Pro, can be used within Claude Code. This functionality leverages MCP servers.
Thanks for reading!
Always be (machine) learning,
Logan
