
当前最强大的大语言模型(LLM)虽然代码能力飞速发展,但在解决真实、复杂的机器学习工程(MLE)任务时,仍像是在进行一场“闭卷考试”。它们可以在单次尝试中生成代码,却无法模拟人类工程师那样,在反复的实验、调试、反馈和优化中寻找最优解的真实工作流。
为了打破这一瓶颈,来自佐治亚理工学院和斯坦福大学的研究团队正式推出了 MLE-Dojo,一个专为训练和评测大模型智能体(LLM Agents)设计的“交互式武馆”。它将LLM从静态的“答题者”转变为可以在一个包含200多个真实Kaggle竞赛的环境中,不断试错、学习和进化的“机器学习工程师”。

MLE-Dojo是一个专为机器学习工程设计的综合性Gym风格基准测试框架。与现有依赖静态数据集或单次评估的基准不同,MLE-Dojo提供了一个完全可执行的交互式环境,让AI智能体可以通过结构化的反馈循环,反复实验、调试并优化解决方案 。
在MLE-Dojo的竞技场上,团队对当前八个顶尖的LLM进行了全面评测。
结果显示,Gemini-2.5-Pro在综合Elo评分中拔得头筹,但即便是最强的模型,在自主生成长流程解决方案和高效解决复杂错误方面也仍然有提升空间 。
目前,团队已将MLE-Dojo的框架、基准和排行榜完全开源,旨在推动社区共同创新,加速下一代自主机器学习智能体的到来 。
一起来看详细内容。
现有问题与解决方法
团队通过深入分析发现,尽管现在已有多个针对LLM代码能力的基准,但它们普遍存在以下问题:
- 评测真空:
为了填补这一空白,MLE-Dojo应运而生。它不仅仅是一个“考卷”,更是一个能让AI智能体学习、成长和对战的“练功房”和“竞技场”。如下表所示,MLE-Dojo在交互性、训练支持和任务广度上全面超越了以往的基准。
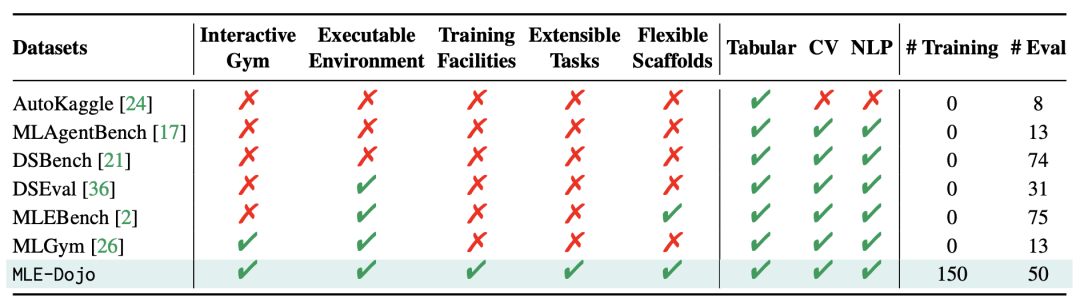
△表1:MLE-Dojo与其他MLE智能体基准的比较
MLE-Dojo:一个给AI Agent的真实“练功房”
MLE-Dojo的核心是一个连接AI智能体和机器学习任务环境的标准化交互框架 。在这个框架中,智能体可以像人类工程师一样,通过一系列动作来解决复杂的Kaggle竞赛任务。
整个交互过程被建模为一个循环:智能体根据当前观察(Observation)做出动作(Action),环境执行该动作后,返回新的观察和相应的奖励(Reward) 。
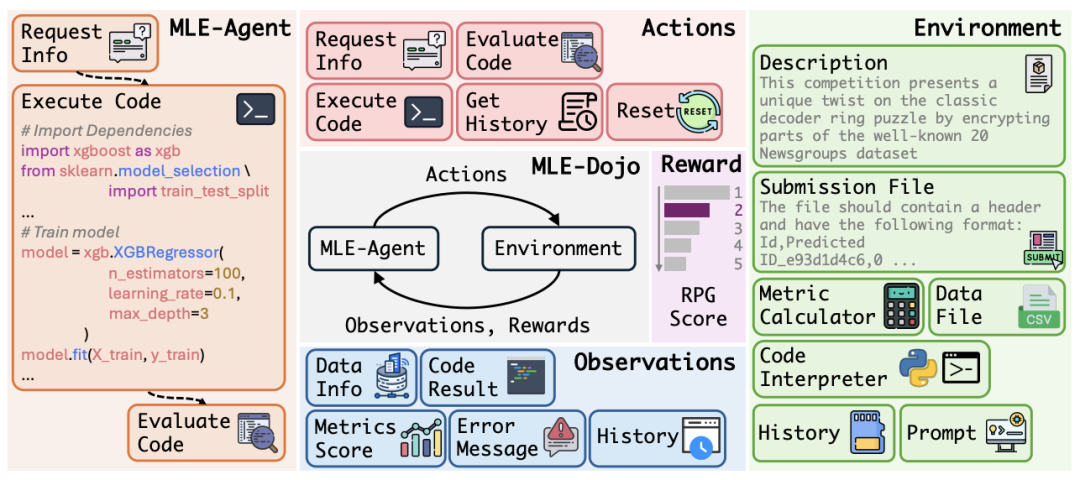
△图4:MLE-Dojo框架概览,展示了智能体与环境的交互循环
其主要贡献和特点可以概括为:
- 全面的基准和框架:
八大顶尖LLM同台竞技,谁是Kaggle之王?
为了全面、公正地评估各大顶尖LLM的机器学习工程能力,研究团队设计了一套多维度的综合评测体系,而非依赖单一指标。
多维度综合评测体系
- HumanRank Score (%):
综合性能对决
在这套严格的评测体系下,八大前沿LLM在50个评估任务上展开了激烈角逐。
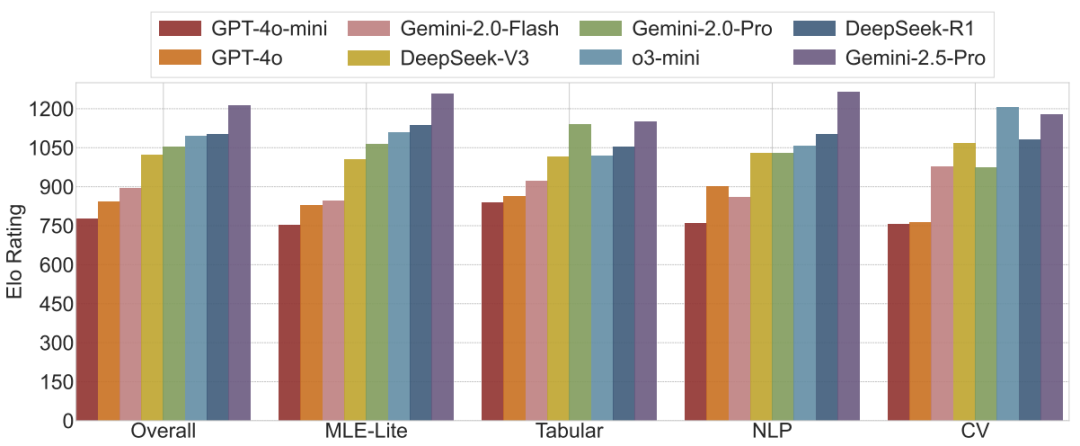
△图6 & 图1:八大前沿LLM在MLE-Dojo上的Elo综合评分及排名
Gemini-2.5-Pro综合实力登顶:在最关键的Elo综合评分中,Gemini-2.5-Pro展现出最强的竞争力,拔得头筹 。在衡量绝对性能的HumanRank分数上,它同样表现优异,例如在MLE-Lite任务集上超越了61.95%的人类选手 。
顶尖模型各有千秋:紧随其后的是DeepSeek-R1和o3-mini等模型,它们同样展现了作为机器学习智能体的强大实力和适应性,在各项指标中均名列前茅 。
深度分析:解码冠军策略
除了最终排名,MLE-Dojo的精细化数据还让我们得以深入剖析每个模型的行为模式和“性格”。
行动策略与模型“性格”:
分析发现,不同模型展现出迥异的解题策略。
例如,表现优异的o3-mini策略非常“激进”,超过90%的动作都是直接执行代码,展现出极高的自信 。
而gpt-4o则相当“保守”,仅有约20%的动作是直接执行,花费了大量时间在初步验证上 。这种策略差异直接影响了它们的解题效率和最终表现。
失败率与稳健性分析:如下图所示,Gemini-2.5-Pro不仅性能领先,其在代码验证和执行中的总体失败率也是最低的 ,这表明其生成的代码不仅效果好,而且更加稳健可靠。相比之下,一些性能同样不俗的模型却伴随着更高的失败率 。
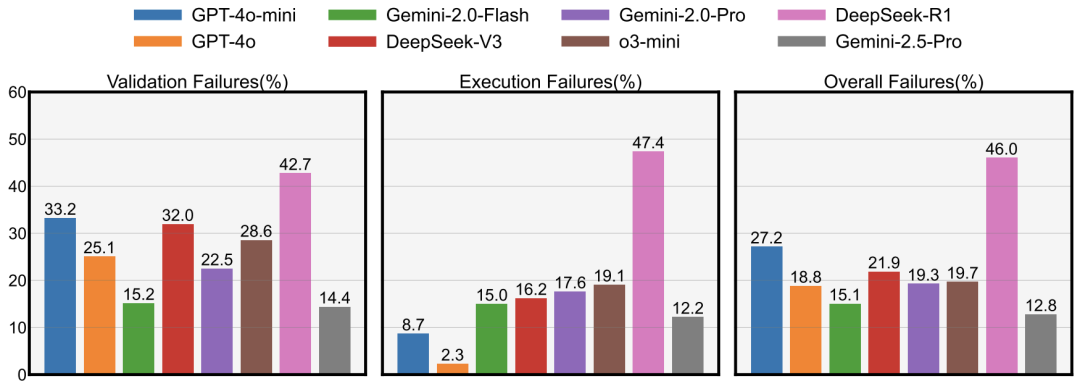
△图12:各模型在任务中的平均失败率,Gemini-2.5-Pro的总体失败率最低
- 解题深度与复杂性:
此项研究为评估和提升AI智能体的机器学习工程能力提供了一个强大的开源平台。通过模拟真实世界的挑战,并提供一个可以不断学习和进化的环境,MLE-Dojo将推动AI从一个“解题工具”向一个真正的“自主工程师”迈进,并最终对整个科学研究和工程领域产生深远影响。
项目主页:https://mle-dojo.github.io/MLE-Dojo-page/
排行榜:https://huggingface.co/spaces/MLE-Dojo/Leaderboard
论文:https://arxiv.org/abs/2505.07782
Github:https://github.com/MLE-Dojo/MLE-Dojo
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
