华为在2025世界人工智能大会上首次线下展出昇腾384超节点(Atlas 900 A3 SuperPoD),该产品基于超节点架构,通过总线技术实现384个NPU间的大带宽低时延互联,有效解决了集群通信瓶颈。华为CEO任正非曾表示,可通过数学和集群方法弥补单芯片的不足。昇腾超节点具备超大带宽、超低时延、超强性能,能够满足大模型训练和推理的严苛要求。与传统AI集群不同,CloudMatrix 384采用扁平化管理模式,CPU与NPU地位平等,直接通信效率更高。该方案在多项关键指标上被认为超越了英伟达GB200 NVL72,标志着中国在AI基础设施领域取得重要突破,具备与国际巨头竞争的实力。
💡 华为通过系统工程创新应对单芯片劣势:华为CEO任正非提出的“用数学补物理、非摩尔补摩尔、用群计算补单芯片”的策略,在昇腾384超节点上得到体现。该产品通过超节点架构和总线技术,实现了384个NPU的高效互联,解决了集群通信瓶颈,确保了计算结果的实用性,证明了系统级创新可以有效弥补单芯片性能上的代差。
🚀 昇腾384超节点的核心技术优势:该超节点具备超大带宽、超低时延、超强性能,特别是其384个NPU(昇腾910C)与192颗鲲鹏CPU的全对等互联,形成了强大的“超级AI服务器”。其单卡推理吞吐量达到2300Tokens/s,集群算力高达16万卡且万卡线性度达95%,并支持40天长稳训练和10分钟快速恢复,为大模型应用提供了极致算力支持。
🤝 创新的扁平化通信架构提升效率:与传统AI集群中CPU作为“领导”而NPU为“下属”的层级化通信模式不同,CloudMatrix 384采用了扁平化管理,CPU和NPU地位平等,通过UB网络直接通信。这种“平等对话”的模式大幅提升了数据传输效率,避免了CPU审批和签字的环节,使集群整体运行更像一台高效的超级计算机。
🏆 华为云CM384在AI算力领域实现重大突破:根据SemiAnalysis的报道,华为云CloudMatrix 384在系统架构设计和全栈技术创新上,多项关键指标超越了英伟达GB200 NVL72。虽然单颗昇腾芯片性能不及英伟达GPU,但华为通过规模化系统设计,实现了整体算力跃升,尤其在超大规模模型训练和实时推理方面展现出更强的竞争力,被认为在规模化解决方案上领先英伟达和AMD一个代差。
🌐 华为的系统级创新引领全球AI产业格局:华为的工程优势不仅体现在芯片本身,更在于网络架构、光学互联和软件优化等系统级创新。这些创新使得CM384能够充分发挥集群算力,满足超大规模AI计算需求。华为云CloudMatrix 384的发布,标志着中国在AI计算系统领域已具备与国际巨头正面竞争的实力,其规模化解决方案对全球AI产业格局将产生深远影响。
快科技7月27日消息,今年6月,华为CEO任正非接受人民日报采访时曾表示,芯片问题其实没必要担心,用叠加和集群等方法,计算结果上与最先进水平是相当的。
“我们单芯片还是落后美国一代,我们用数学补物理、非摩尔补摩尔,用群计算补单芯片,在结果上也能达到实用状况。”他说。如今,这句话已经应验。
7月26日,2025世界人工智能大会(WAIC)在上海世博中心启幕,华为首次线下展出昇腾384超节点,即Atlas 900 A3 SuperPoD,该产品基于超节点架构,通过总线技术实现384个NPU之间的大带宽低时延互联,解决集群内计算、存储等各资源之间的通信瓶颈。通过系统工程的优化,实现资源的高效调度,让超节点像一台计算机一样工作。
在今年5月的鲲鹏昇腾开发者大会上,华为推出了昇腾超节点(CloudMatrix 384),成功实现业界最大规模的384卡高速总线互联。昇腾超节点具备超大带宽、超低时延、超强性能的三大优势,包括多款训练和推理产品,基于超节点创新架构,更好的满足模型训练和推理对低时延,大带宽,长稳可靠的要求。
本月初,华为云官微通过一段视频展示了CloudMatrix 384超节点算力集群的威力——384颗昇腾NPU(昇腾910C)+192颗鲲鹏CPU全对等互联,形成一台“超级AI服务器”;业界最大单卡推理吞吐量——2300Tokens/s;业界最大集群算力——16万卡,万卡线性度高达95%;云上确定性运维-40天长稳训练、10分钟快速恢复。华为云表示,新一代昇腾AI云服务,是最适合大模型应用的算力服务。简单来说,华为CloudMatrix并非简单的“堆卡”,而是通过高带宽全对等互联(Peer-to-Peer)来设计,这也是CloudMatrix 384硬件架构的一大创新。传统的AI集群中,CPU相当于公司领导的角色,NPU等其它硬件更像是下属,数据传输的过程中就需要CPU审批和签字,效率就会大打折扣。但在CloudMatrix384中,CPU和NPU等硬件更像是一个扁平化管理的团队,它们之间的地位比较平等,直接通过UB网络通信直接对话,效率自然就上来了。今年4月份,国际知名半导体研究和咨询机构SemiAnalysis发布专题报道称,华为云最新推出的AI算力集群解决方案CloudMatrix 384(简称CM384)凭借其颠覆性的系统架构设计与全栈技术创新,在多项关键指标上实现对英伟达旗舰产品GB200 NVL72的超越,标志着中国在人工智能基础设施领域实现里程碑式突破。据SemiAnalysis披露,华为云CM384基于384颗昇腾芯片构建,通过全互连拓扑架构实现芯片间高效协同,可提供高达300 PFLOPs的密集BF16算力,接近达到英伟达GB200 NVL72系统的两倍。此外,CM384在内存容量和带宽方面同样占据优势,总内存容量超出英伟达方案3.6倍,内存带宽也达到2.1倍,为大规模AI训练和推理提供了更高效的硬件支持。
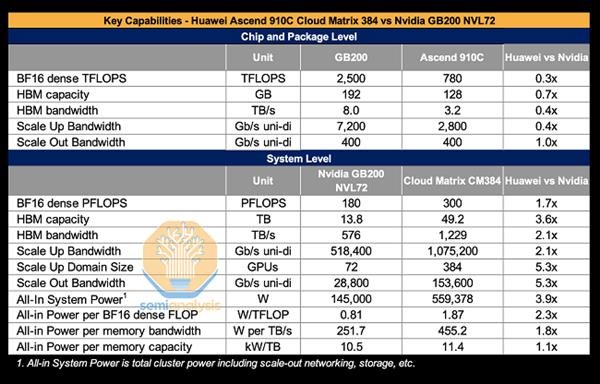
(图片引自SemiAnalysis报道)报道分析称,尽管单颗昇腾芯片性能约为英伟达Blackwell架构GPU的三分之一,但华为通过规模化系统设计,成功实现整体算力跃升,并在超大规模模型训练、实时推理等场景中展现更强竞争力。SemiAnalysis也指出,华为的工程优势不仅体现在芯片层面,更在于系统级的创新,包括网络架构、光学互联和软件优化,使得CM384能够充分发挥集群算力,满足超大规模AI计算需求。此次华为云CloudMatrix 384的发布,标志着中国在AI计算系统领域已具备与国际巨头正面竞争的实力。SemiAnalysis在报道中特别指出,华为的规模化解决方案“领先于英伟达和AMD目前市场上的产品一代”,并认为中国在AI基础设施上的突破将对全球AI产业格局产生深远影响。【本文结束】如需转载请务必注明出处:快科技责任编辑:朝晖文章内容举报]article_adlist-->








