
Introduction
Reinforcement Learning (RL) has emerged as a pivotal paradigm for scaling language models and enhancing their deep reasoning and problem-solving capabilities. To scale RL, the foremost prerequisite is maintaining stable and robust training dynamics. However, we observe that existing RL algorithms (such as GRPO) exhibit severe instability issues during long training and lead to irreversible model collapse, hindering further performance improvements with increased compute.
To enable successful RL scaling, we propose the Group Sequence Policy Optimization (GSPO) algorithm. Unlike previous RL algorithms, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. Compared to GRPO, GSPO demonstrates remarkable advantages in the following aspects:
- Performant and Efficient: GSPO possesses significantly higher training efficiency and can achieve continuous performance improvements through increasing training compute;Notably Stable: GSPO maintains stable training processes and inherently resolves the stability challenges in the RL training of large Mixture-of-Experts (MoE) models;Infrastructure-Friendly: Due to sequence-level optimization, GSPO is fundamentally more tolerant to precision discrepancies, offering attractive potential for simplifying RL infrastructure.
These merits have contributed to the exceptional performance of the latest Qwen3 models (Instruct, Coder, Thinking).
Sequence-Level Optimization Objective
Let $x$ be a query, $\pi_{\theta_\mathrm{old}}$ be the old policy that generates responses, $\{y_i\}_{i=1}^G$ be the sampled response group, $\widehat{A}_{i}$ be the group relative advantage of each response, and $\pi_\theta$ be the current policy to be optimized. GSPO adopts the following optimization objective:
$$\mathcal{J}_\text{GSPO} (\theta)=\,\mathbb{E}_{ x \sim \mathcal{D},\, \{y_i\}_{i=1}^G \sim \pi_{\theta_\mathrm{old}}( \cdot | x) }\left[\frac{1}{G} \sum_{i=1}^{G}\min \left( s_{i}(\theta) \widehat{A}_{i}, \, \mathrm{clip} \left( s_{i}(\theta), 1 - {\varepsilon}, 1 + {\varepsilon} \right) \widehat{A}_{i} \right)\right],$$
where
$$s_{i}(\theta)=\left( \frac{ \pi_{\theta} (y_i | x) }{ \pi_{\theta_\text{old}} (y_i | x)} \right)^{\frac{1}{|y_i|}}=\exp \left( \frac{1}{|y_i|} \sum_{t=1}^{|y_i|} \log \frac{ \pi_{\theta} (y_{i,t} | x, y_{i,<t}) }{ \pi_{\theta_\text{old}} (y_{i,t} | x,y_{i,<t})} \right).$$
Here, $s_i(\theta)$ is the importance ratio defined based on sequence likelihood in GSPO, where we perform length normalization to reduce variance and unify the numerical range of $s_i(\theta)$.
Training Efficiency and Performance
We experiment with a cold-start model fine-tuned from Qwen3-30B-A3B-Base and report its training reward curves as well as performance curves on the AIME'24, LiveCodeBench, and CodeForces benchmarks. We compare against GRPO as the baseline. Note that GRPO necessitates the Routing Replay training strategy for the normal convergence of MoE RL (which we will discuss later), while GSPO has obviated the need for this strategy.

Experimental results
As shown in the figure above, GSPO demonstrates significantly higher training efficiency than GRPO, achieving better performance under the same training cost. Particularly, we observe that GSPO can deliver continuous performance improvement through increasing the training compute, regularly updating the query set, and extending the generation length — this is exactly the scalability we expect from an algorithm. Ultimately, we successfully applied GSPO to the large-scale RL training of the latest Qwen3 models, further unleashing the potential of RL scaling!
An interesting observation is that the fraction of tokens clipped in GSPO is two orders of magnitude higher than that in GRPO (as shown in the figure below), while GSPO still achieves higher training efficiency. This further demonstrates that GRPO’s token-level optimization objective is noisy and inefficient, while GSPO’s sequence-level approach provides a more reliable and effective learning signal.
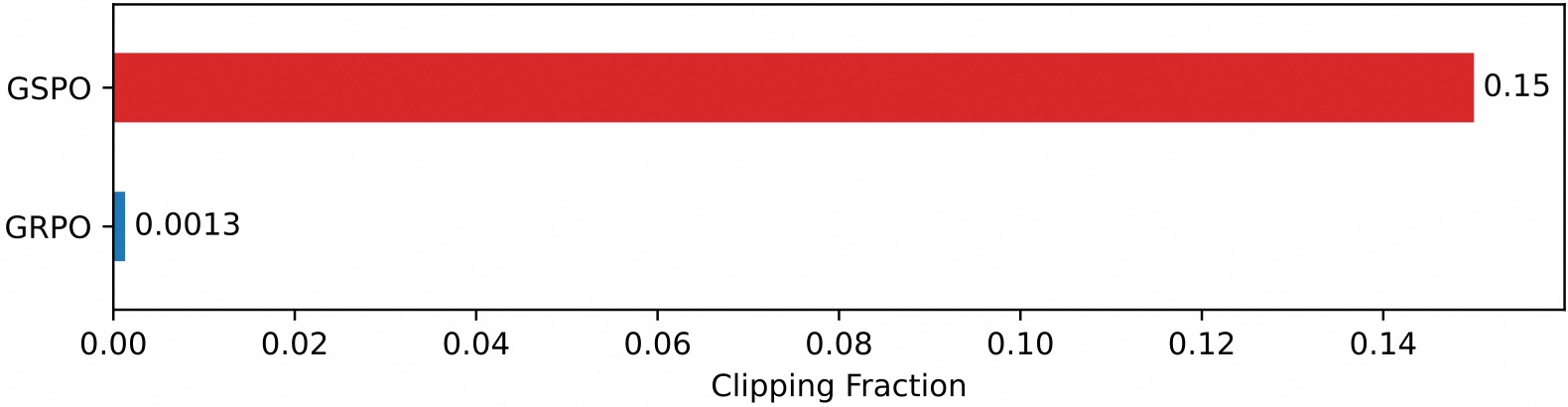
Fractions of clipped tokens
Benefits for MoE RL and Infrastructure
We found that when adopting the GRPO algorithm, the expert activation volatility of MoE models prevents RL training from converging properly. To address this challenge, we previously employed the Routing Replay training strategy, which caches the activated experts in $\pi_{\theta_\text{old}}$ and “replays” these routing patterns in $\pi_\theta$ when computing importance ratios. As shown in the figure below, Routing Replay is crucial for normal convergence of GRPO training on MoE models. However, the Routing Replay strategy incurs additional memory and communication overhead and may limit the actual capacity of MoE models.
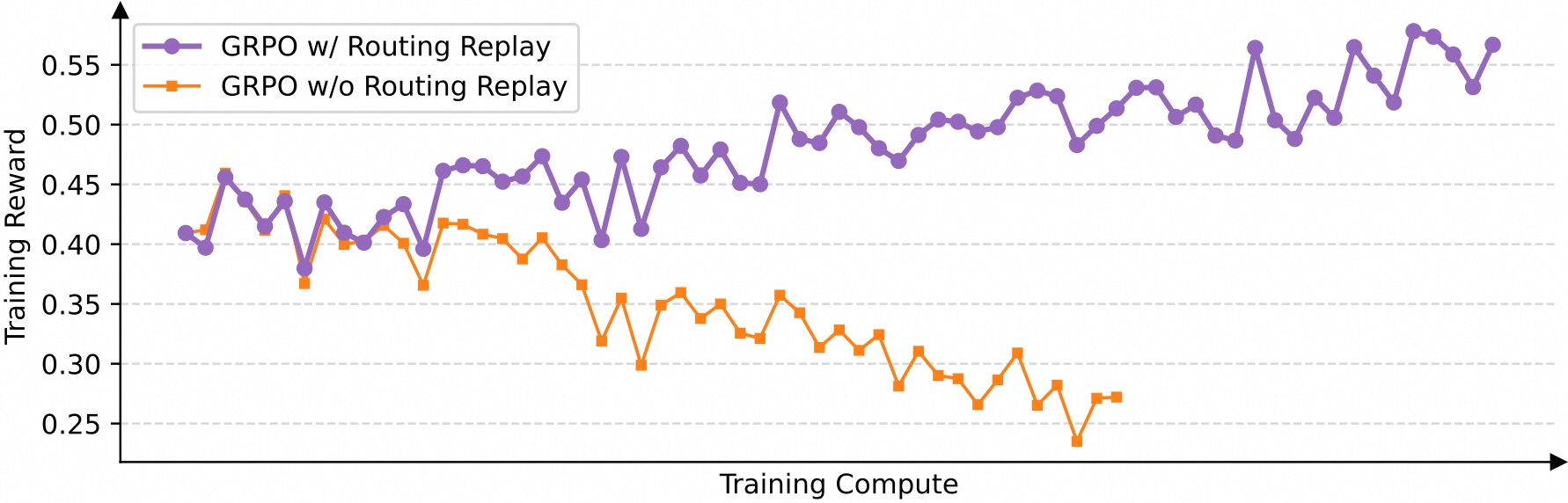
Effect of Routing Replay in the GRPO training of MoE models
The notable advantage of GSPO lies in completely eliminating the dependency on Routing Replay. The key insight is that GSPO only focuses on sequence-level likelihood (i.e., $\pi_\theta(y_i|x)$) and is not sensitive to individual token likelihood (i.e., $\pi_\theta(y_{i,t}|x,y_{i,<t})$). Therefore, it does not require infrastructure-heavy workarounds like Routing Replay, both simplifying and stabilizing the training process while allowing models to maximize their capacity.
Additionally, since GSPO uses only sequence-level rather than token-level likelihoods for optimization, intuitively the former is much more tolerant of precision discrepancies. Therefore, GSPO makes it possible to directly use likelihoods returned by inference engines for optimization, eliminating the need for recomputation with training engines. This is particularly beneficial in scenarios such as partial rollout, multi-turn RL, and training-inference disaggregated frameworks.
Conclusion
We propose Group Sequence Policy Optimization (GSPO), a new RL algorithm for training language models. GSPO demonstrates notably superior training stability, efficiency, and performance compared to GRPO and exhibits particular efficacy for the large-scale RL training of MoE models, laying the foundation for the exceptional improvements in the latest Qwen3 models. With GSPO as our algorithmic cornerstone, we will continue to push the boundaries of RL scaling and look forward to the resulting fundamental advances in intelligence.
Citation
If you find our work helpful, feel free to give us a citation.
@article{gspo, title={Group Sequence Policy Optimization}, author={ Chujie Zheng and Shixuan Liu and Mingze Li and Xiong-Hui Chen and Bowen Yu and Chang Gao and Kai Dang and Yuqiong Liu and Rui Men and An Yang and Jingren Zhou and Junyang Lin }, journal={arXiv preprint arXiv:2507.18071}, year={2025}}