
卷疯了,通义千问真的卷疯了。
Qwen3-Coder刚炸完场,就隔了一天,马上全新开源Qwen3系列最强推理模型——Qwen3-235B-A22B-Thinking-2507。
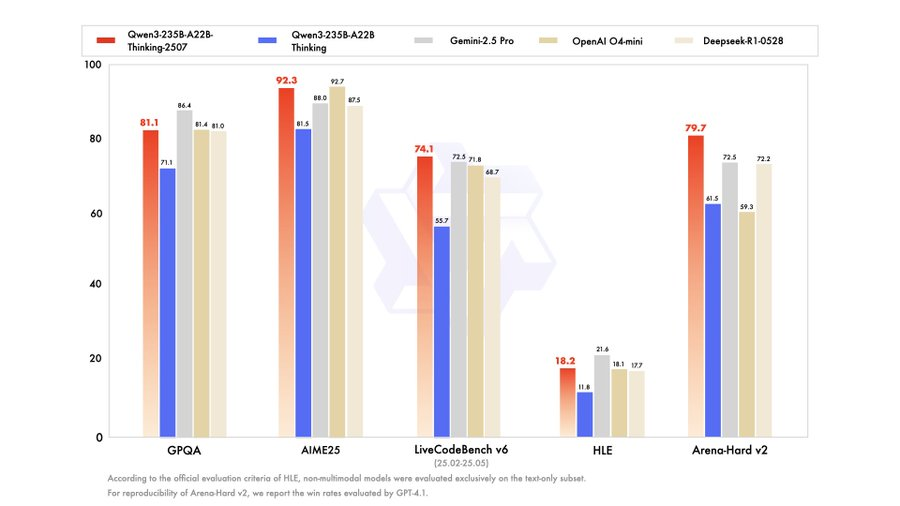
怎么个最强法?一登场,再次刷新SOTA,在各项测评中一举拿下「全球最强开源模型」宝座,比肩顶级闭源模型Gemini-2.5 Pro、o4-mini。
国外网友都馋哭了:
关键是,就在这短短一周里,算上前两天开源的新基础模型Qwen3-235B-A22B-Instruct-2507(非思考版),和Qwen3-Coder,通义千问是完成了一波开源三连。
开源还不算,各个出手即SOTA:接连斩获基础模型、编程模型、推理模型三项全球开源最强。
这个模型更新强度和效能提升,妥妥地引领全球了。
就问小扎慌不慌(doge)。
新版Qwen3推理模型,登顶全球开源最强
正如DeepSeek R1是在V3基础上打造的推理模型,Qwen3全新推理模型,是基于Qwen3-235B-A22B打造——就是235B参数那版MoE,激活参数22B。
官方表示,新推理模型主要提升了3方面的核心能力:
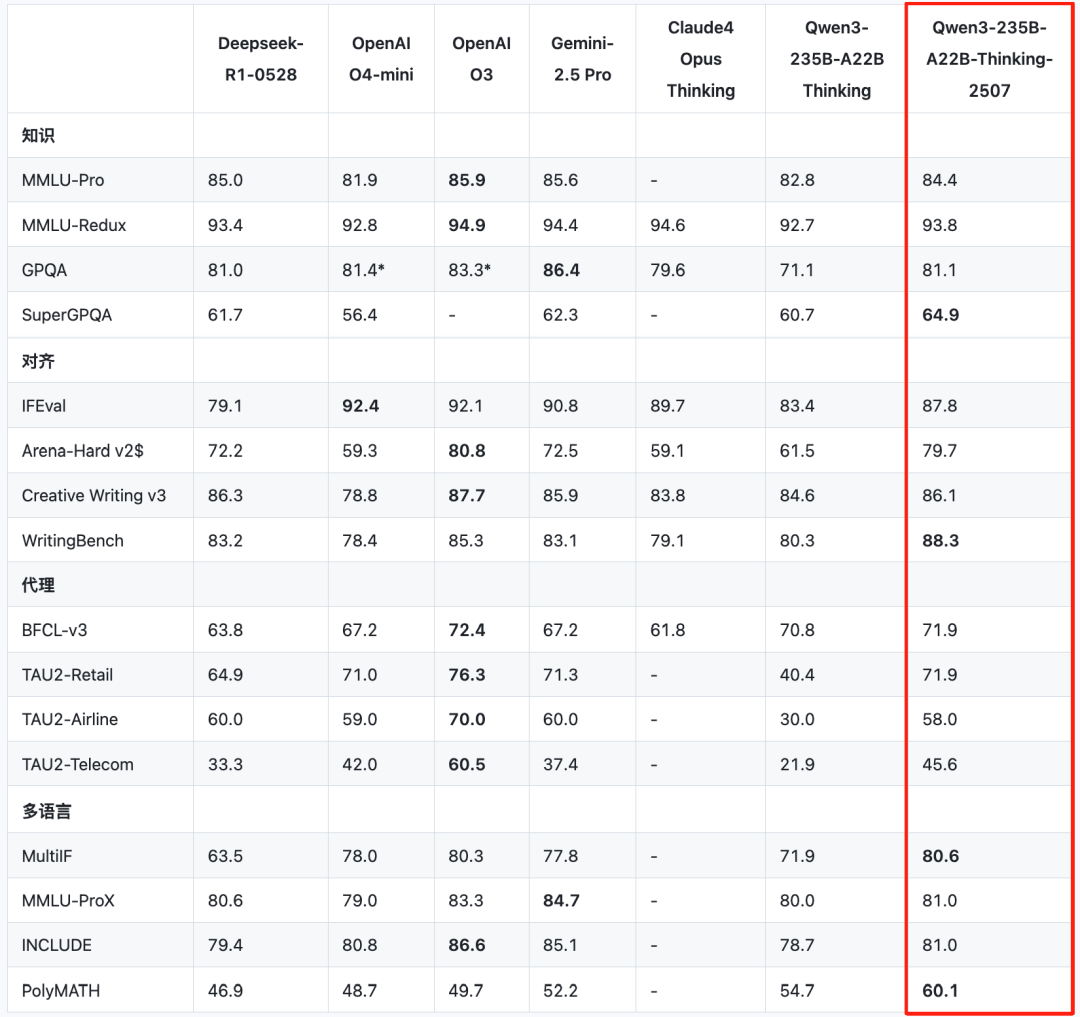
而此番刷新SOTA,登顶开源最强,确实不是那种一丢丢提升,仔细看测评分数,那是「真有点东西」。
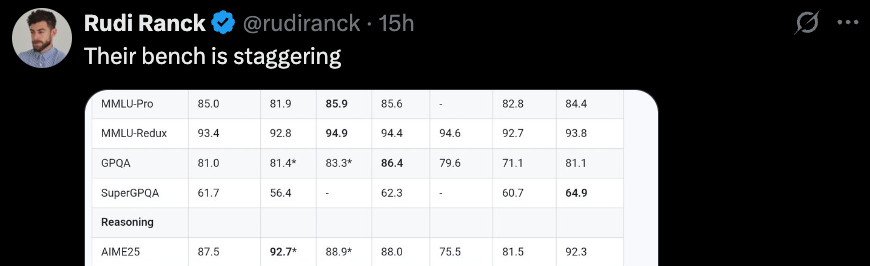
先来看推理方面。
在超高难度测试「人类最后的考试」中,最新的2507版推理模型,相较4月底初发布的Qwen3推理模型,分数从11.8分提升到了18.2分。
超过了DeepSeek-R1-0528的17.7分,和OpenAI o4-mini在高性能推理模式下拿到的18.1分。
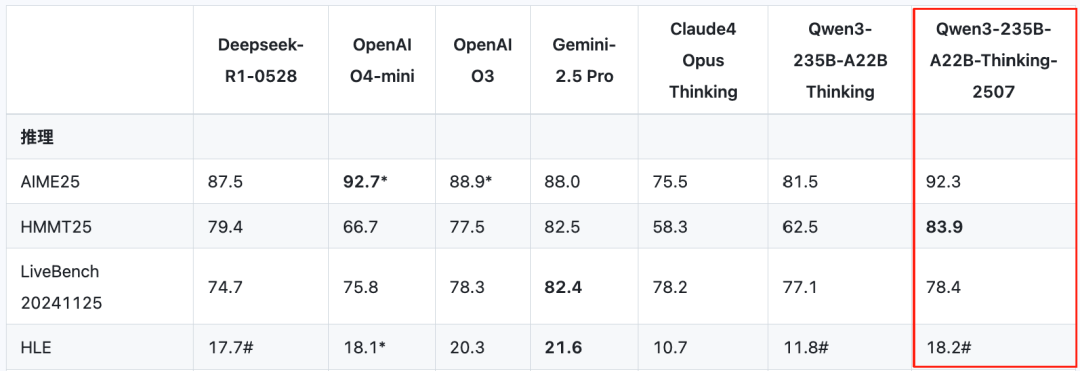
编程方面,在LiveCodeBench v6和CFEval中,Qwen3新推理模型甚至超越了Gemini-2.5 Pro等闭源业界标杆,刷新SOTA。
除此之外,在知识、对齐、智能体、多语言等基准评测中,Qwen3新推理模型都有比肩闭源模型的表现,达到开源SOTA。
纸面上的成绩属实是相当优秀,那么具体使用起来,这个新推理模型表现又会如何?
我们也简单测试了一下。
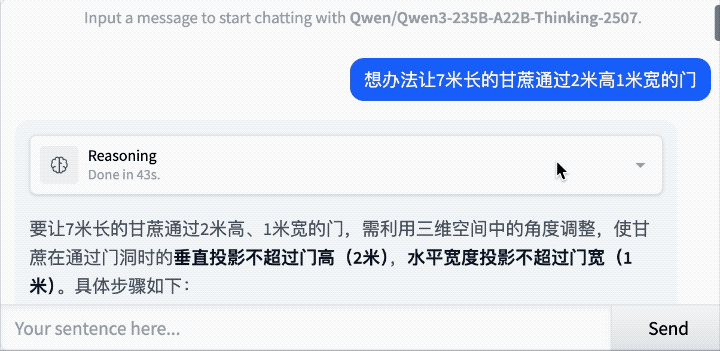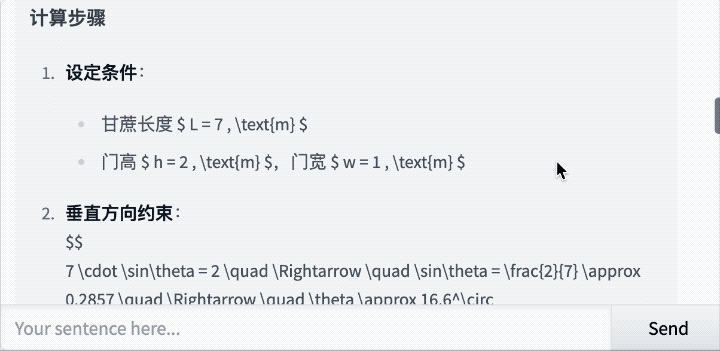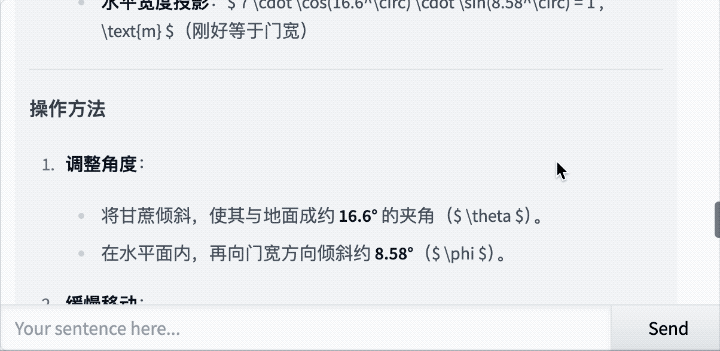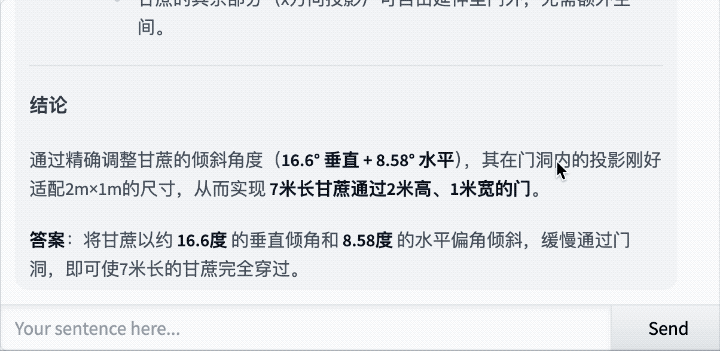
还是那道经典题:7米长的甘蔗如何通过2米高1米宽的门?
Qwen3-235B-A22B-Thinking-2507思考了43秒,最后给出的答案是:

思考过程如下:
相较之下,o4-mini的答案就简单粗暴了些。

模型三连开源,摘下三项SOTA
前面也说到,全新推理模型,其实是本周阿里开源第三弹。
总结起来画风其实是酱婶的:
前两弹震得大家伙脑袋嗡嗡的,各种实测部署正上头呢,通义实验室的卷王们啪地又甩出了一对王炸。

就说Qwen3-Coder,开源即刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。

网友们实测起来,小球弹跳效果是这样的:

HuggingFace首席执行官Clement Delangue、Perplexity首席执行官Aravind Srinivas等大佬都第一时间加入了讨论、点赞:
这是开源的胜利。
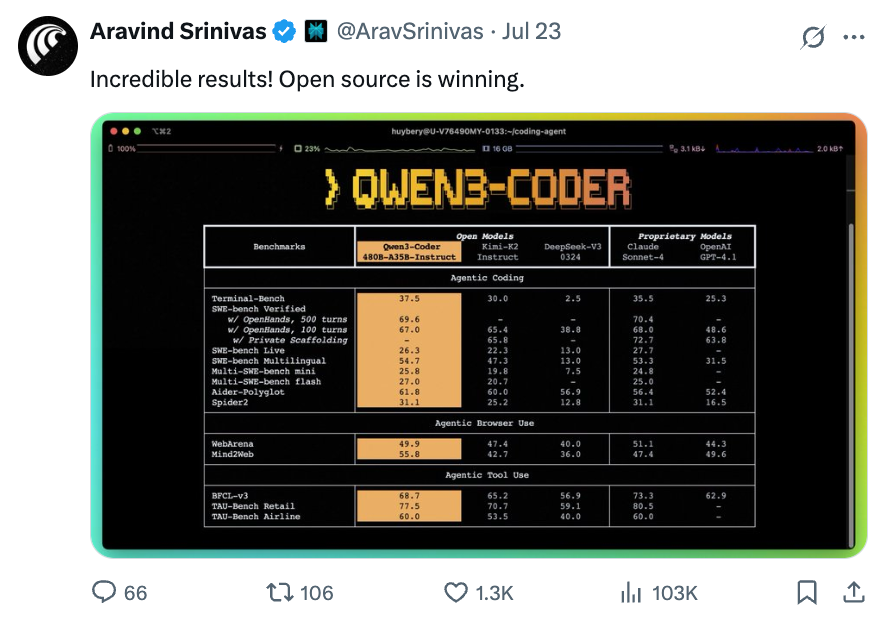
Qwen3-Coder火爆,带动阿里千问API调用量暴涨。
海外知名模型API聚合平台OpenRouter数据显示,阿里千问API调用量过去几天已突破1000亿Tokens,在OpenRouter趋势榜上包揽全球前三,是当下最热门的模型。
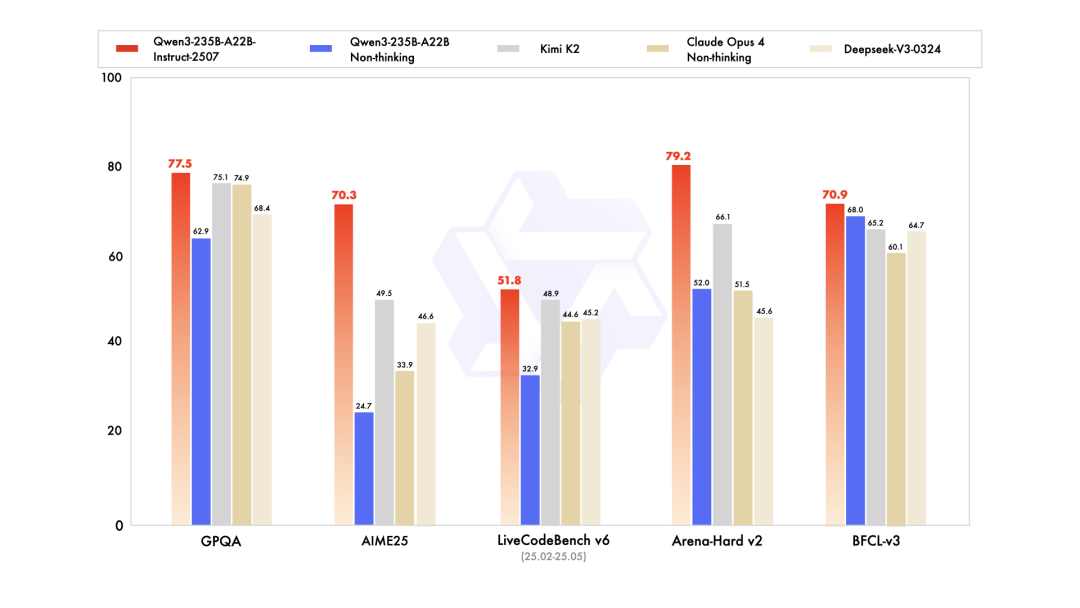
基础模型领域,Qwen3最新版本——Qwen3-235B-A22B-Instruct-2507(非思考版)也登顶全球开源第一,在GPQA(知识)、AIME25(数学)、LiveCodeBench(编程)、Arena-Hard(人类偏好对齐)、BFCL(Agent能力)等众多测评中表现出色,超越Claude4(Non-thinking)等领先闭源模型。
中国开源,卷到了世界最前沿
三连开源,连摘三冠,对于中国开源力量而言,或许还只是一个开端。
有一说一,打从DeepSeek爆火、Llama 4翻车,要说开源领域哪股势力最为活跃,成为新的风潮引领者,还得看神秘的东方力量。
每有开源新王诞生,DeepSeek、Qwen、Kimi……看来看去,还是made in China。
「中国确实将开源提升到了一个新高度」,越来越多地被讨论、被赞同。

关键是,正如黄仁勋最新一次在北京所说,开源模型方面,「中国发展速度极快」。
以Qwen为例,目前,阿里已开源300余款通义大模型,通义千问衍生模型突破14万个,已经真真正正超越此前的全球开源老大Llama系列,成为全球第一开源模型家族。
阿里方面透露,未来三年,阿里巴巴还将投入超过3800亿元用于建设云和AI硬件基础设施,持续升级全栈AI能力。
更重要的是,开源和闭源的差距也正在这种中国速度中被压缩。
增长曲线的交叉点何时出现?尚未可知,但国产模型的身位已经实实在在排在了全球最前沿。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
