
刚刚,就在WAIC现场的一个展台,我亲眼看到一只机器狗,在完全离线断网的情况下,学会了一个新动作。
是一位中年男性观众现场教的。让它先转个圈,再立起来做了个经典的小狗拜拜。
教完过后没两分钟,狗子自己就原模原样复现出来了——
没有预定程序,没人遥控操纵,狗子全程离线。

一扭头,这展台还摆着几只灵巧手,一会儿在愉快地玩黄金矿工,一会儿又玩推箱子推得正起劲。
听展台工作人员说,玩儿得这么溜的灵巧手,也是纯离线,全靠它本地部署模型的视觉能力,看得懂画面,也玩得转策略。
其实灵巧手、机器狗、机器人等是本届WAIC不少展位吸引目光的招牌产品。
之所以想和大家分享刚刚的所见所闻,一方面是因为在真·离线的状态下,这俩端侧设备表现得实在是不错;另一方面,是因为部署在它们身上的模型,是非Transformer架构的大模型。
展台负责介绍的小姐妹告诉我们,背后是设备原生智能:能离线跑、会多模态,还能边用边学。
这套体系的幕后推手,是一家成立刚满两年的公司——RockAI。
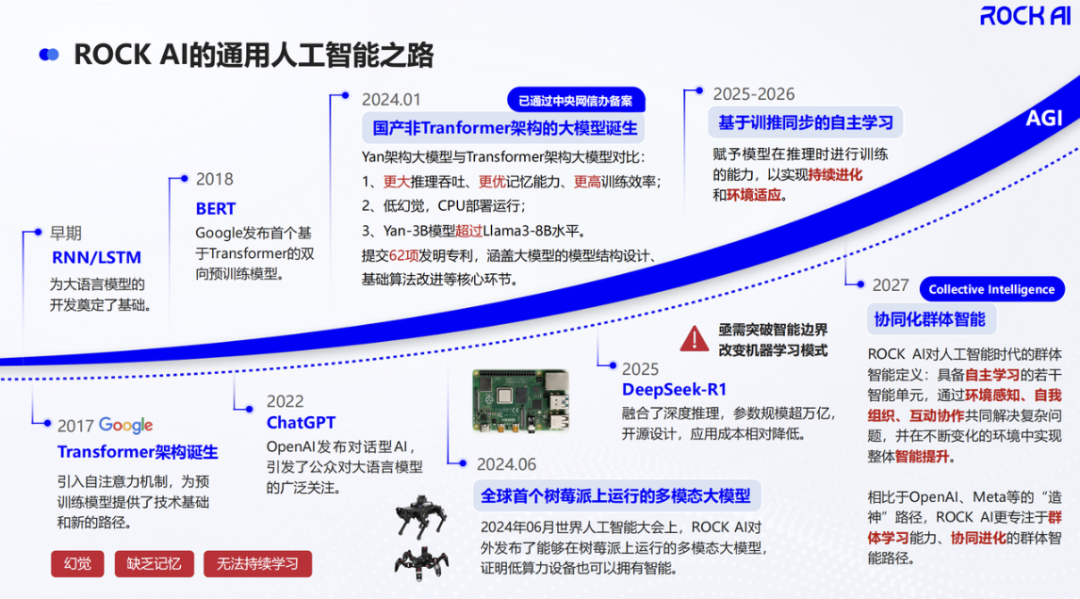
早在ChatGPT名动全球之前的2022年初,这家公司就开始全心押注非Transformer架构大模型,从最底层重构AI模型的运行逻辑。
今年WAIC期间,RockAI创始人刘凡平公开表示:
目前AI的发展需要推翻两座大山,一个是反向传播,一个是Transformer。
当大模型具备“原生记忆”能力
在RockAI展台上自学新动作的机器狗、会玩游戏的灵巧手,都运行着RockAI最新推出的Yan 2.0 Preview大模型。
这个版本,相比初代Yan 1.0的语言能力、Yan 1.3的多模态理解能力,最大的突破在于它开始具备“记忆”了——引入了原生记忆模块。
这里的“记忆”,不是对某个长度上下文的窗口限制,而是Yan 2.0 Preview具备了边用边学、可持续进化的能力。
现在大家用大模型,都会遇到这样一种情况:提的问题超出了Chatbot的训练数据覆盖范围,得到一句“很抱歉,我的知识截至于2024年x月,无法提供相关信息”,要么就是得到一顿瞎编的结果,令人头秃。
这是传统大模型“先训练→再部署→使用过程不能更新”导致的。
所以,现在联网搜索功能几乎成了Chatbot们的标配。

但相比于原生记忆,联网搜索、外挂记忆库、拓展长上下文等解决方案其实没有解决根本问题。
在这个问题上,Yan 2.0 Preview引入了一种训推同步的新机制。
训推同步意味着模型不再是一个冻结的产品,而是一个持续进化的智能体。每一次与环境的交互,每一个新的任务场景,都能成为模型自主学习、进化的养分。
要展开说这种持续学习能力的实现,就不得不提到RockAI对Yan 2.0 Preview的记忆模块设计。
其前向过程可分为记忆更新与记忆检索两个阶段。
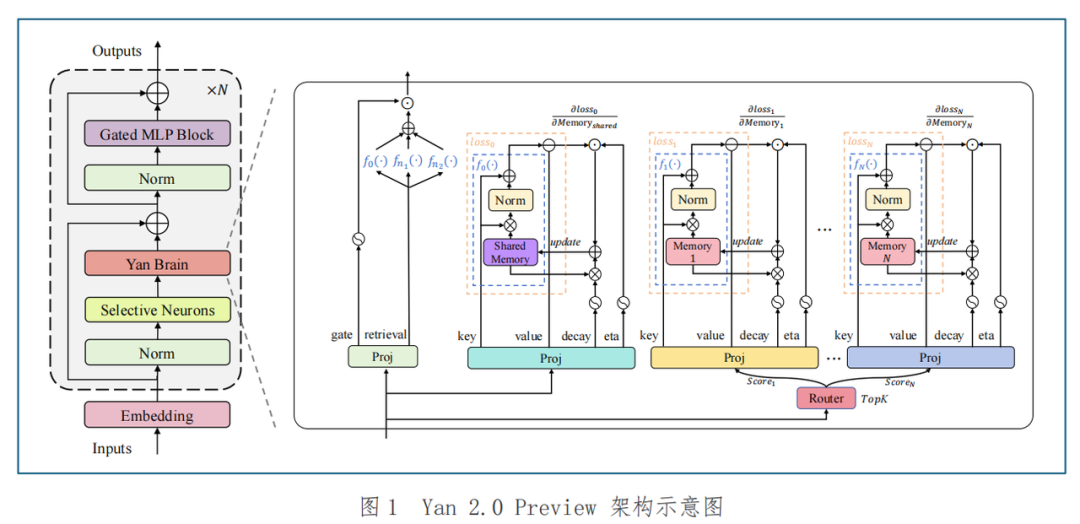
首先来看记忆更新阶段。
这一阶段,模型会判断哪些旧知识可以被遗忘,然后再从当前任务中提取出有价值的信息,写入记忆模块。
这个过程不靠外挂、不靠缓存,而是由一个专门的神经网络来模拟记忆行为来实现动态擦除与增量写入,以此实现在保留重要历史信息的同时,灵活整合新知识。
其次是记忆检索阶段。
Yan 2.0 Preview设计了记忆稀疏机制,模型会从多个记忆槽中选出Top-K激活记忆,与长期共享记忆融合,生成新的输出。
这使得模型不只是有记性,更能“带着记性去推理”。
这些机制组合在一起,让Yan 2.0 Preview完成了对记忆网络有效性的初步验证,模型不再是静态的大脑,而开始变成一个能生长的智能体。
用RockAI的话来说,这是迈向基于训推同步的自主学习的一大步。

虽然完全实现基于训推同步的自主学习在现在看来还是不可能之事,但这背后其实有一个非常现实主义的出发点。
早在2022年,RockAI创业之初就彻底放弃了Transformer架构,走一条完全不同的AI底层路径。
原因很简单——
RockAI专注为端侧服务,而Transformer架构模型虽然在语言处理任务上表现出色,但它们消耗大量计算资源和内存,推理也异常吃算力。
尤其是对于长序列输入,Transformer的自注意力机制存在二次复杂度的计算和内存需求,在诸如端侧部署等场景中是天然的bug。
对于手机、机器人、IoT设备这些典型端侧环境,资源敏感是一种常态,不是一种例外。
彼时的RockAI就做出判断:
AI要成为真正的基础设施,就必须与具体设备深度融合,只有当AI能够在每一个终端设备上高效运行之时,它才能真正渗透到人类生活的每一个角落。
在这样的思路下,Yan架构诞生了,并逐渐迭代出1.0、1.3版本,直到今天来到Yan 2.0 Preview版本。
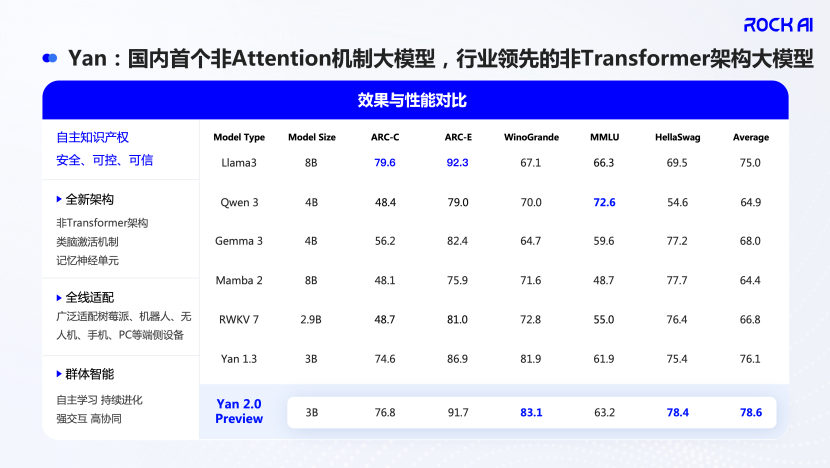
需要强调的是,Yan 2.0 Preview不是一个完整的产品版本,它的意义更多是RockAI进行的一次重要技术预演。
这次他们想验证的,不是模型能不能答题、会不会生成图文,而是一个更本质的问题:
AI模型,能不能像人一样,边用边学、越用越聪明?
这个问题的重要性远超技术本身。
如果答案是肯定的,我们对AI的理解就该改一改,它不再是工具,而是能主动成长的智能伙伴。
基于训推同步的自主学习机制,将有效信息隐式地存储到多层神经网络的权重中,这比显性的上下文工程更加优雅,也更接近人类大脑的工作原理。
所以,展台上玩游戏的灵巧手和自主学习的机器狗,不能当个逛展的乐子看,更深层次的,这能被视作是一种可能性的预告,AI或许能进入一个全新的进化阶段。
“离线智能”让模型直接在设备上出生和成长
最终通向AGI的路径还在探索中,但方向是确定的:算法更简单、算力依赖更低、数据需求更少。
RockAI表示,要让AI真正进入这样的进化阶段,光靠外部功能拼装是不够,必须从底层架构动刀,解决那些阻碍AI落地生长的系统性问题。
“Transformer架构的模型,从一开始就注定不适合在端侧设备上跑。”RockAI的CTO杨华如是说。
是不是有那么一丝丝“暴论”的味道?(doge)
但其实这句话绝不是没有道理的歪理邪说——
ChatGPT一鸣惊人后,Transformer架构的模型席卷行业,越攀越高,在国内外无数次被证明有效。
但众所周知,受限于Transformer架构本身的底层计算设计,在不少场景下,它会显得比较笨拙。
譬如在推理模型风头正盛的现在,Transformer模型一旦进入推理阶段,模型的复杂度就会伴随输入序列长度疯狂增长。每多处理一个token,就要额外计算整段上下文的注意力关系。
换句话说,就算你把大模型压得再小,只要它还是Transformer架构,上下文长度变长、任务复杂度提升,推理速度就会明显受限,功耗也直线向上狂飙。
如此一来,在手机、机器人、IoT终端这类算力有限的设备,Transformer架构模型就不占优势了。

针对这个窘境,目前业内的主要做法,要不是端云协同,要不就是给云端模型“瘦身”,尽可能压缩压缩再压缩,再挤进端侧设备里。
总而言之,现行主流方法的本质,仍然是在用云端的思路,来服务端侧的现实。
但RockAI不一样。
这家公司的办法不是让模型适配设备,而是让模型直接在设备上出生和成长。
前面提到的Yan架构,就专为端侧而生,RockAI表示, 它的目标是让模型变成设备的一部分——RockAI称之为“离线智能”。
所谓离线智能,不是简单的“断网运行”,而是模型在本地就能完成理解、推理、甚至学习的全流程闭环系统。
其核心特征有三:
- 全程本地运行
这么一剖析,就能发现离线智能的与众不同之处——
传统AI是联网找大脑,端云协同是遇到不会的去问云端,离线智能是只靠自己本身具备的脑子边理解边学习边应对。

RockAI表示,端侧大模型不应是缩水版的云端大模型。
端侧大模型应该是一种创新架构的模型,能够在终端设备上进行本地私有化部署。
其核心能力在于基于多模态感知实现自主学习与记忆,以提供个性化服务并保障数据隐私与运行安全。
说到底,RockAI把它视为未来各类终端设备真正的大脑。
“记忆”对未来终端设备来说十分重要,是它们真正理解你、陪伴你的关键所在。
具备记忆能力的大模型,能持续学习用户的习惯、环境和情绪,在保护隐私的前提下,提供更精准的个性化服务。
人类一生都在边记忆边成长。未来设备也将借助记忆形成自己的经验,从而一步步变得有温度、有判断力,实现智能陪伴。
从这个角度来看,RockAI的愿景就不止步于拓展模型能力边界了,这家公司用Yan架构大模型押注的还有让“记忆”成为未来设备原生端侧模型的基本素养。
国内非Transformer架构模型的落地之王
更重要的是,Yan架构并不是一场纸上谈兵的重构实验,它已经在真实设备中长出来了,也开始动起来了。
官方消息显示,不用裁剪、无须量化,Yan架构的系列大模型已经跑通了树莓派、骁龙6系列移动芯片、AMD和Intel的PC处理器,甚至是机器人主控芯片。
而且不仅是技术上跑起来,商业世界里也开始真正落地用起来了。
RockAI表示,与某出海品牌厂商合作的AI PC将在今年下半年正式量产上市,销往海外。与此同时,该公司与其他品牌合作开发的终端设备,也正陆续进入部署节奏。
在全球范围内,在行业里能真正做到完全非Transformer架构 + 真端侧落地的公司,RockAI是极少数之一。
两年多时间,他们用一条最不主流的路径,走出了眼下完整的落地闭环,成为国内非Transformer架构模型的落地之王。

但他们要走的路,并不止于让离线智能商业落地。
我们了解到,RockAI推出的类脑激活机制、原生记忆能力、纯离线部署,并不是分散的功能点,而是通往一个更远方向的三根支柱。
这个方向就是群体智能(Collective Intelligence)。
在RockAI看来,群体智能是迈向AGI的关键路径之一。
人类社会中,个体具备专长,协作产生力量,故而RockAI希望智能设备也能这样:模型和模型之间通过神经元迁移或任务能力同步实现协作,构建出一个有组织、有分工、有反馈的模型群落。
换言之,RockAI构想的AI未来,不是一个巨无霸式的超级中心化模型,而是无数设备小脑互联互通,共同进化。
这种看似激进的思路,其实也正在被越来越明显的技术趋势所呼应。
随着效率敏感型场景的需求上升,去年开始,Transformer架构模型正被越来越多国内外主流科技公司关注并采纳。
就连Transformer诞生地——谷歌,也在几天前推出了全新底层架构Mixture-of-Recursions(MoR),内存减半,推理速度还翻倍,被不少网友戏称为Transformer Killer。
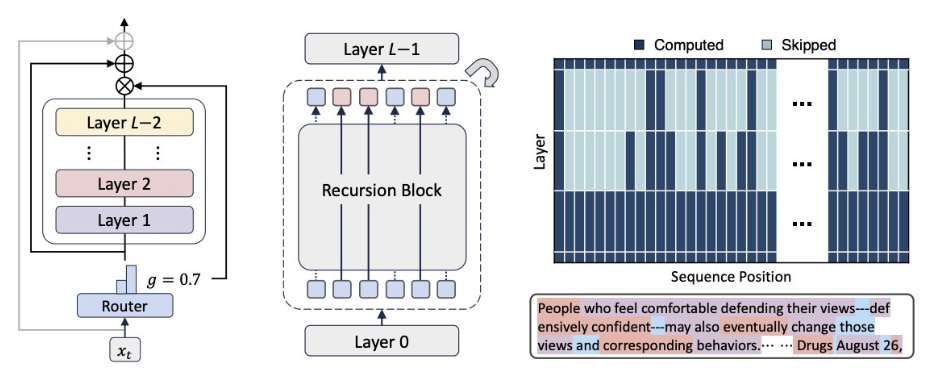
可以看到,业界开始集体追问一个问题:Transformer架构,是不是走到了一个分岔点?
对于RockAI来说,这个问题的答案是肯定的。混合架构的大量出现,就是行业潜意识里对原有路线“不够用了”的回应。
Transformer仍在狂飙,但非Transformer们也在快速追赶。不同的是,前者在原轨道上提速,后者在开凿一条新的铁路。
这条路挺难的。
它要绕开一整个AI生态的技术惯性,要补完新架构下的工具链、社区与认知成本。
这条路也很孤独。
当前全球主流模型、硬件接口、训练范式,大多都以Transformer架构为中心设计。
但正因如此,非Transformer架构值得被认真对待——在ChatGPT问世以前,GPT也在T5、BERT的光芒下显得有些黯然。
所以RockAI相信,只要这条路解决了现实问题,它就有存在的意义。
如果我们把视线从“这周谁开源了新版本和“下一个基准测评的排行榜”抬起来,以十年甚至三十年的长远视角去看今天,或许,真正照亮这个端云混战、架构争鸣的AI深夜的,未必是当下最喧哗的那束光。
也有可能是以后成了共识之后被标记为起点的星星之火。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
