
LLMs have demonstrated exceptional performance across multiple tasks by utilizing few-shot inference, also known as in-context learning (ICL). The main problem lies in selecting the most representative demonstrations from large training datasets. Early methods selected demonstrations based on relevance using similarity scores between each example and the input question. Current methods suggest using additional selection rules, along with similarity, to enhance the efficiency of demonstration selection. These improvements introduce significant computational overhead when the number of shots increases. The effectiveness of selected demonstrations should also consider the specific LLM in use, as different LLMs exhibit varying capabilities and knowledge domains.
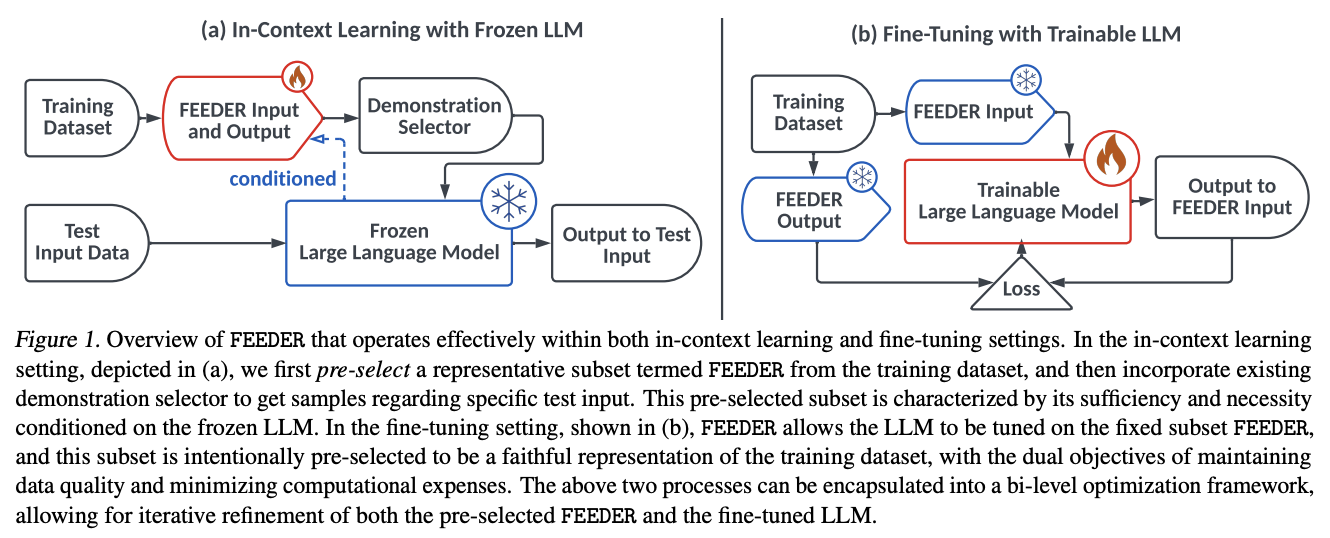
Researchers from Shanghai Jiao Tong University, Xiaohongshu Inc., Carnegie Mellon University, Peking University, No Affiliation, University College London, and University of Bristol have proposed FEEDER (FEw yet Essential Demonstration prE-selectoR), a method to identify a core subset of demonstrations containing the most representative examples in training data, adjusted to specific LLMs. To construct this subset, “sufficiency” and “necessity” metrics are introduced in the pre-selection stage, along with a tree-based algorithm. Moreover, FEEDER reduces training data size by 20% while maintaining performance and seamlessly integrating with various downstream demonstration selection techniques in ICL across LLMs ranging from 300M to 8B parameters.
FEEDER is evaluated on 6 text classification datasets: SST-2, SST-5, COLA, TREC, SUBJ, and FPB, covering tasks from sentiment classification and linguistic analysis to textual entailment. It is also evaluated on the reasoning dataset GSM8K, the semantic-parsing dataset SMCALFlow, and the scientific question-answering dataset GPQA. The official splits for each dataset are directly followed to get the training and test data. Moreover, multiple LLM variants are utilized to evaluate the performance of the method, including two GPT-2 variants, GPT-neo with 1.3B parameters, GPT-3 with 6B parameters, Gemma-2 with 2B parameters, Llama-2 with 7B parameters, Llama-3 with 8B parameters, and Qwen-2.5 with 32B parameters as the LLM base.
Results regarding in-context learning performance show that FEEDER enables retention of almost half the training samples while achieving superior or comparable performance. Evaluation of few-shot performance on complex tasks using LLMs like Gemma-2 shows that FEEDER improves performance even when LLMs struggle with challenging tasks. It performs effectively with large numbers of shots, handling situations where LLM performance usually drops when the number of examples increases from 5 to 10 due to noisy or repeated demonstrations. Moreover, FEEDER minimizes negative impact on LLM performance by evaluating the sufficiency and necessity of each demonstration, and helps in the performance stability of LLMs
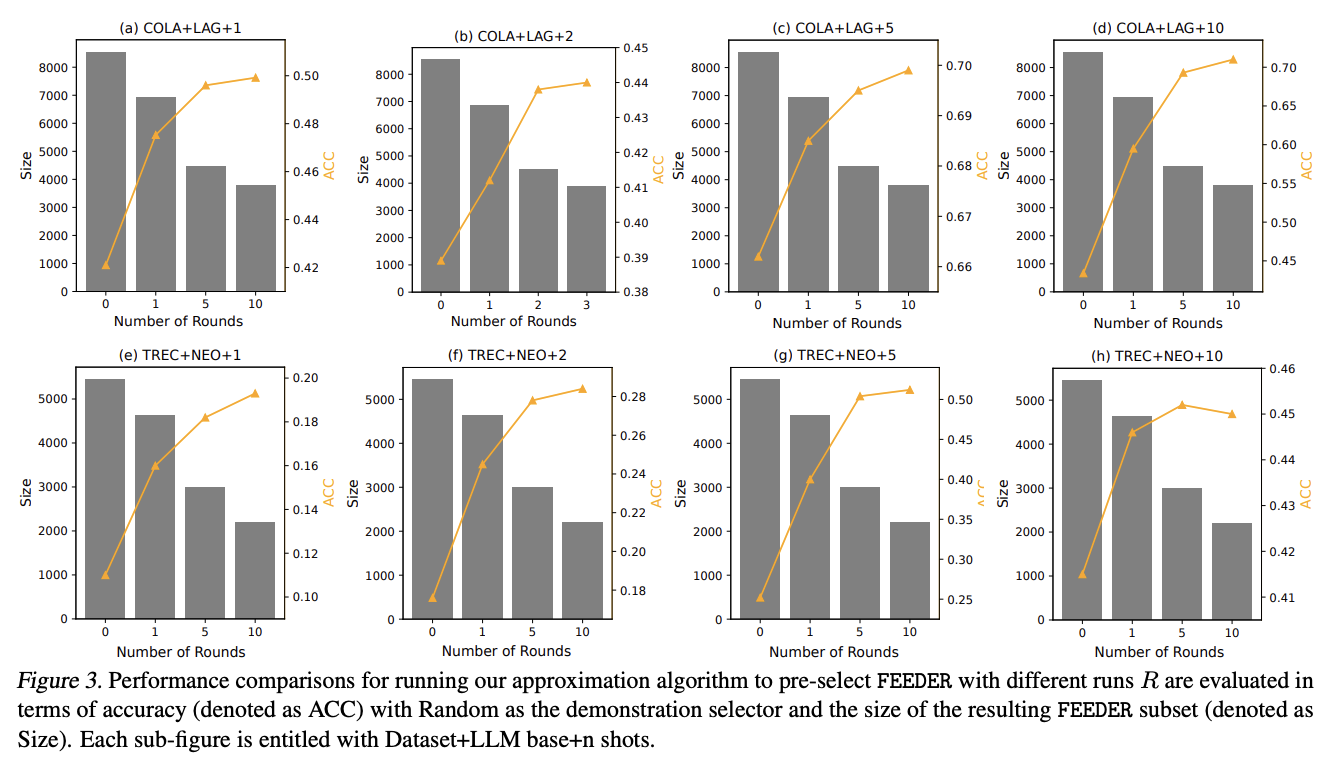
On bi-level optimization, FEEDER achieves improved performance by utilizing a small yet high-quality dataset for fine-tuning while simultaneously reducing computational expenses, aligning with the core-set selection principle. Results indicate that fine-tuning LLMs provides greater performance improvements compared to augmenting LLMs with contexts, with FEEDER achieving even better performance gains in fine-tuning settings. Performance analysis reveals that FEEDER’s effectiveness first rises and then drops with increasing number of runs or rounds (R and K, respectively), confirming that identifying representative subsets from training datasets enhances LLM performance. However, overly narrow subsets may limit potential performance gains.
In conclusion, researchers introduced FEEDER, a demonstration pre-selector designed to use LLM capabilities and domain knowledge to identify high-quality demonstrations through an efficient discovery approach. It reduces training data requirements while maintaining comparable performance, offering a practical solution for efficient LLM deployment. Future research directions include exploring applications with larger LLMs and extending FEEDER’s capabilities to areas such as data safety and data management. FEEDER makes a valuable contribution to demonstration selection, providing researchers and practitioners with an effective tool for optimizing LLM performance while reducing computational overhead.
Check out the Paper. All credit for this research goes to the researchers of this project.
Meet the AI Dev Newsletter read by 40k+ Devs and Researchers from NVIDIA, OpenAI, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo and 100s more [SUBSCRIBE NOW]
The post FEEDER: A Pre-Selection Framework for Efficient Demonstration Selection in LLMs appeared first on MarkTechPost.
