
Speculative decoding is a powerful technique for accelerating Large Language Model (LLM) inference. In this blog post, we are excited to announce the open-sourcing of SpecForge, our new training framework for Eagle3-based speculative decoding. SpecForge is designed for ease of use and is tightly integrated with the SGLang inference engine, enabling a seamless transition from training to deployment.
Why a New Speculative Decoding Training Framework
While speculative decoding has emerged as a breakthrough for accelerating LLM inference, the lack of robust open-source tools for training draft models—a key component of this process—has significantly hindered its adoption. Many existing Eagle3-based projects suffer from poor maintenance, limited functionality, or lack of compatibility with frameworks like SGLang. These limitations have become significant barriers to adoption and practical deployment.
To bridge the gap between research and deployment, we built SpecForge—a purpose-built ecosystem for training draft models that integrate natively with SGLang. As soon as training completes, models are ready for inference out of the box—no further adaptation needed. Meanwhile, training effective draft models for today’s frontier LLMs—such as Llama 4, DeepSeek, and other Mixture-of-Experts (MoE) models—requires infrastructure that can handle their complexity and scale. SpecForge is purpose-built from the ground up to meet these demands, bridging the gap between cutting-edge research and real-world deployment.
Key Capabilities of SpecForge:
- Native Support for Advanced Architectures: SpecForge supports cutting-edge models, including complex MoE layers and transformer variants.Scalable Distributed Training: Integrated with modern large-scale training strategies like Fully Sharded Data Parallel (FSDP) and Tensor Parallelism (TP), SpecForge allows efficient scaling across GPU clusters.Memory-Efficient Training: Optimized memory management techniques make it feasible to train draft models even for very large base models.
Key Features of SpecForge
Eagle3 Integration
Eagle is a state-of-the-art method for speculative decoding designed to accelerate large language model inference. It achieves this by training a specialized, lightweight draft model to accurately predict the token distributions of a larger target model, leading to high acceptance rates and significant performance improvements.
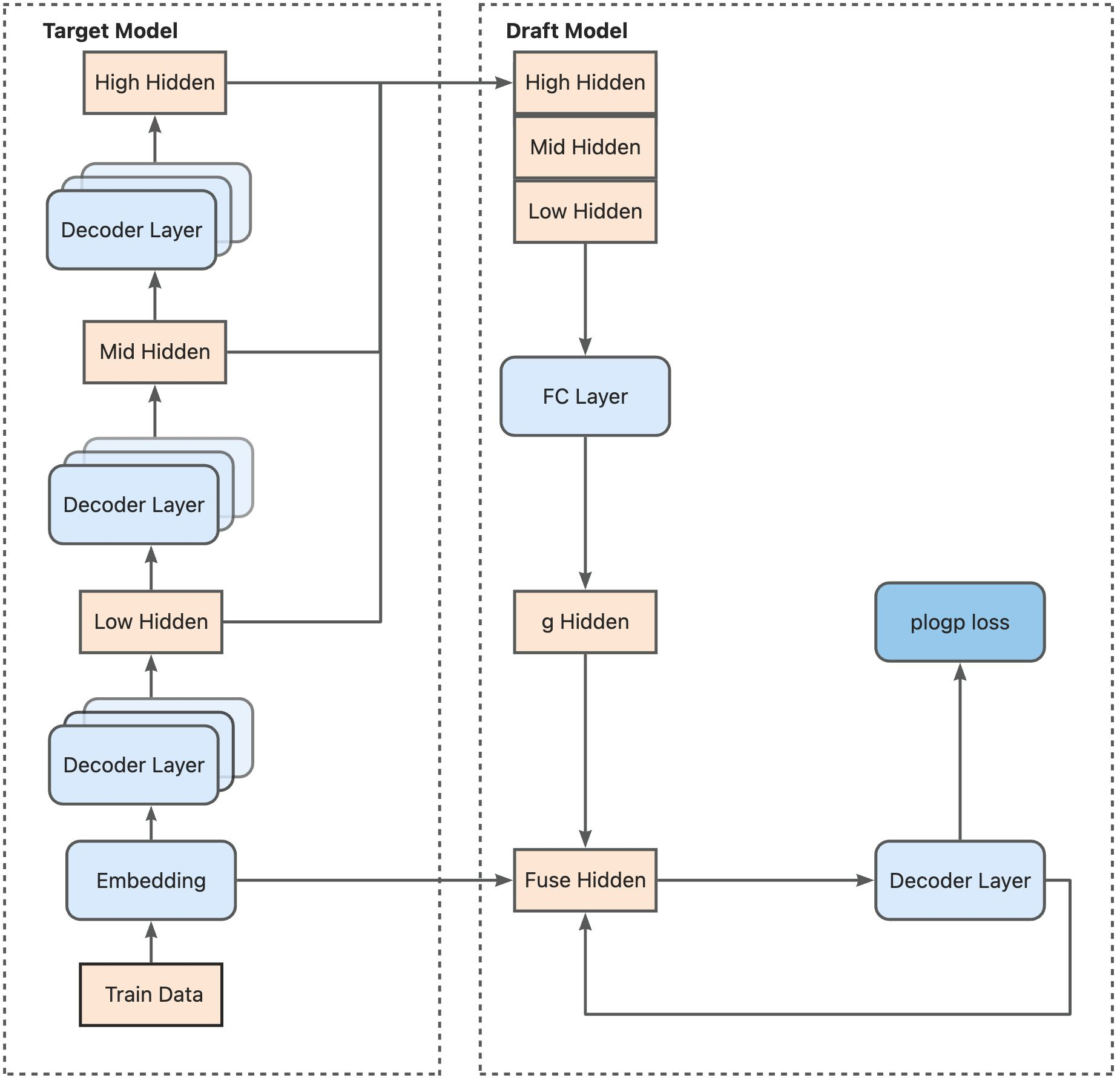
Training-time Test Support
This high performance is largely driven by Eagle's novel Training-Time Test (TTT) architecture, which makes the draft model robust by simulating multi-step generation. Despite its power, TTT is notoriously difficult to implement due to its use of specialized attention masks and recursive data loops. SpecForge simplifies this complexity by providing built-in TTT support, referencing the official Eagle3 implementation to ensure correctness and optimal performance.
Two Training Modes: Online and Offline
SpecForge simplifies hidden state collection by offering two versatile modes for training: Online and Offline. This two-mode design ensures flexibility across workflows, regardless of your model access rights or hardware limitations.
| Method | Target Model Usage | Disk Space Requirement | GPU Requirement | One-liner Rationale |
|---|---|---|---|---|
| Online | Used during training | Low | More GPUs if your target model is large | Generates hidden states on the fly |
| Offline | Used only for data preparation | High (e.g., UltraChat + ShareGPT need ~12TB) | As low as 1 GPU (only the draft model needs to be loaded) | Precomputes hidden states once and reuses them efficiently |
SpecForge allows you to tailor the training process to your specific needs. Choose Online Mode for agility and minimal disk usage—ideal for rapid iteration. Choose Offline Mode when reproducibility and data reuse are key priorities, provided sufficient storage is available.
Prioritizing Extensibility and Scalability
Our framework is designed with a strong emphasis on extensibility and scalability to meet engineering production requirements. We enable straightforward implementation and registration of new draft & target models through a modular interface.
To support large-scale models, SpecForge leverages PyTorch’s FSDP and integrates tensor parallelism, ensuring efficient training across multi-GPU clusters.
Experiments
Using SpecForge, we trained the Llama 4 Scout and Maverick models on a 320K-sample dataset from ShareGPT and UltraChat. The models' strong performance on benchmarks like MT-Bench demonstrates their effectiveness and readiness for Eagle3 inference. Our Llama 4 Maverick draft model achieves a 2.18× speedup on MT-Bench, while the Scout variant delivers a 2.0× acceleration—demonstrating SpecForge’s performance gains across model variants. Detailed results are summarized below.
We evaluated various draft token lengths for Scout and Maverick.
In all the tests shown in the figure below, the x-axis represents steps, corresponding to speculative-num-steps in SGLang. Meanwhile, we fixed SGLang's speculative-eagle-topk to 8 and speculative-num-draft-tokens to 10 to ensure that tree attention can be enabled. To find the optimal speculative decoding parameters, we can use the bench_speculative script in the SGLang repository. It runs throughput benchmarks across different configurations and helps us tune for the best performance https://lmsys.org/images/blog/spec_forge/Llama4_Scout_performance_final.svgLlama4_Scout_perforhttps://lmsys.org/images/blog/spec_forge/Llama4_Maverick_performance_final.svgog/spec_forge/Llama4_Maverick_performance_final.svg" alt="maverick.svg">
Code and Model Availability
Explore our source code on GitHub and try the pre-trained models on Hugging Face.
💻 GitHub Repository: The complete source code for our training framework, including implementation details for TTT and data processing.
🤗 Hugging Face Models: Download the Llama 4 Scout & Maverick Eagle3 draft heads (excluding the full model) for your projects.
Roadmap
In the near future, we plan to extend SpecForge with the following support.
- Support more model architectures, including the Kimi K2 and Qwen-3 MoE. We’re actively collaborating with the LinkedIn Infrastructure team, who are training additional Qwen-3 MoE draft models that will be supported by SpecForge.Integrate Vision-Language Models (VLM) into SpecForge.Support more efficient training with better parallelism strategies and kernel optimization.
Acknowledgement
We would like to express our heartfelt gratitude to the following teams and collaborators:
SGLang Team and Community — Shenggui Li, Yikai Zhu, Fan Yin, Chao Wang, Shuai Shi, Yi Zhang, Yingyi Huang, Haoshuai Zheng, Yubo Wang, Yineng Zhang and many others.
SafeAILab Team — Yuhui Li, Hongyang Zhang and members — for their pioneering work on the Eagle3 algorithm.
We are especially grateful to Meituan for their early support and contributions to this project. We also extend our sincere thanks to Voltage Park, our official infrastructure partner, whose formal collaboration with the SGLang team provided the compute foundation behind SpecForge. Their support enabled us to train and evaluate large-scale speculative decoding models efficiently and reliably, and we deeply appreciate their commitment to democratizing cutting-edge AI infrastructure.
“Our mission at Voltage Park is to be a catalyst for innovation by democratizing access to high-performance AI infrastructure. A thriving AI research ecosystem is one where the tools to innovate are shaped by many voices and not concentrated in the hands of a few," said Saurabh Giri, Chief Product and Technology Officer at Voltage Park." This is why we are so proud to support the SGLang team with the critical infrastructure to develop high-quality, open-source projects like SpecForge -- we believe that foundational open-source models and frameworks should be for the public good and are essential for progress. We look forward to amazing applications from the community with these new capabilities.”
We're excited to see what the community will create with SpecForge. Whether you're optimizing existing models or training new ones, your feedback, contributions, and collaborations are all welcome—let’s accelerate open-source LLM innovation together!
