
Multimodal foundation models (MFMs) like GPT-4o, Gemini, and Claude have shown rapid progress recently, especially in public demos. While their language skills are well studied, their true ability to understand visual information remains unclear. Most benchmarks used today focus heavily on text-based tasks, such as VQA or classification, which often reflect language strengths more than visual capabilities. These tests also require text outputs, making it difficult to fairly assess visual skills or compare MFMs with vision-specific models. Moreover, critical aspects such as 3D perception, segmentation, and grouping, which are core to visual understanding, are still largely overlooked in current evaluations.
MFMs have demonstrated strong performance in tasks that combine visual and language understanding, such as captioning and visual question answering. However, their effectiveness in tasks that require detailed visual comprehension remains unclear. Most current benchmarks rely on text-based outputs, making it difficult to compare MFMs with vision-only models fairly. Some studies attempt to adapt vision datasets for MFMs by converting annotations into text, but this limitation restricts evaluation to language outputs. Prompting strategies have also been explored to help MFMs tackle visual tasks by breaking them into manageable subtasks, though reproducibility remains a challenge in some cases.
Researchers at EPFL evaluated several popular multimodal foundation models—such as GPT-4o, Gemini 2.0 Flash, and Claude 3.5 Sonnet on core computer vision tasks, including segmentation, object detection, and depth prediction, using datasets like COCO and ImageNet. Since most MFMs are designed to output text and are only accessible via APIs, they developed a prompt-chaining framework to translate these visual tasks into text-compatible formats. Their findings show that while MFMs are competent generalists, they fall short of specialized vision models, especially in geometric tasks. GPT-4o stood out, performing best in 4 out of 6 tasks. The evaluation toolkit will be open-sourced.
To evaluate MFMs on vision tasks, the study designed a prompt chaining strategy, breaking complex tasks into simpler, language-friendly subtasks. For example, instead of predicting bounding boxes directly, the model first identifies present objects, then locates them through recursive image cropping. For segmentation and grouping, images are divided into superpixels, which are easier to label and compare. Depth and surface normals are estimated using pairwise rankings of superpixel regions. This modular design leverages MFMs’ strength in classification and similarity, while calibration controls ensure fair comparisons. The method is flexible, and performance improves with finer-grained prompting.
The study evaluates various MFMs, including GPT-4, Gemini Flash, and Claude 3.5, across multiple tasks, such as image classification, object detection, and segmentation. Using datasets like ImageNet, COCO, and Hypersim, results show GPT-4o reaching 77.2% on ImageNet and 60.62 AP50 for object detection, outperformed by specialist models like ViT-G (90.94%) and Co-DETR (91.30%). Semantic segmentation results show GPT-4o at 44.89 mIoU, while OneFormer leads with 65.52. MFMs handle distribution shifts reasonably well but lag on precise visual reasoning. The study also introduces prompt chaining and oracle baselines to evaluate upper-bound performance.
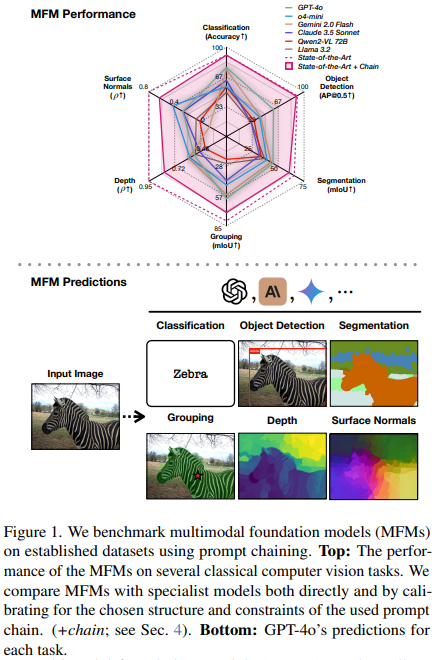
In conclusion, the study introduces a benchmarking framework to assess the visual capabilities of MFMs, such as GPT-4o, Gemini, and Claude, by converting standard vision tasks into prompt-based formats. Findings show MFMs perform better on semantic tasks than geometric ones, with GPT-4o leading overall. However, all MFMs lag significantly behind task-specific vision models. Despite being generalists trained primarily on image-text data, they show promising progress, especially newer reasoning models, such as o3, on 3D tasks. Limitations include high inference cost and prompt sensitivity. Still, this framework provides a unified approach to evaluating MFMs’ visual understanding, laying the groundwork for future advancements.
Check out the Paper, GitHub Page and Project. All credit for this research goes to the researchers of this project.
Meet the AI Dev Newsletter read by 40k+ Devs and Researchers from NVIDIA, OpenAI, DeepMind, Meta, Microsoft, JP Morgan Chase, Amgen, Aflac, Wells Fargo and 100s more [SUBSCRIBE NOW]
The post GPT-4o Understands Text, But Does It See Clearly? A Benchmarking Study of MFMs on Vision Tasks appeared first on MarkTechPost.
