
边缘智能体:轻量化部署与离线运行
🌟 Hello,我是摘星!🌈 在彩虹般绚烂的技术栈中,我是那个永不停歇的色彩收集者。
🦋 每一个优化都是我培育的花朵,每一个特性都是我放飞的蝴蝶。
🔬 每一次代码审查都是我的显微镜观察,每一次重构都是我的化学实验。
🎵 在编程的交响乐中,我既是指挥家也是演奏者。让我们一起,在技术的音乐厅里,奏响属于程序员的华美乐章。
摘要
作为一名深耕AI技术多年的博主摘星,我深刻感受到边缘计算与人工智能融合所带来的技术革命。在云计算主导的时代,我们习惯了将复杂的AI推理任务交给强大的云端服务器处理,但随着物联网设备的爆发式增长、5G网络的普及以及对实时性要求的不断提升,边缘智能体(Edge Intelligent Agents)正成为AI技术发展的新趋势。边缘智能体不仅要求在资源受限的边缘设备上高效运行,还需要具备离线推理能力,这对传统的AI部署模式提出了全新的挑战。在我多年的实践中,我发现边缘智能体的核心价值在于将智能决策能力下沉到数据产生的源头,通过模型压缩、量化优化、离线推理等技术手段,实现低延迟、高可靠、隐私保护的智能服务。本文将从边缘计算环境下的智能体设计原理出发,深入探讨模型压缩与量化技术的实现细节,分析离线推理与增量更新的技术方案,并构建完整的边云协同架构,为读者提供一套完整的边缘智能体部署解决方案。通过理论与实践相结合的方式,我希望能够帮助更多的技术从业者掌握边缘智能体的核心技术,推动这一前沿技术在更多场景中的落地应用。1. 边缘计算环境下的智能体设计
1.1 边缘智能体架构概述
边缘智能体(Edge Intelligent Agents)是部署在边缘计算节点上的智能决策系统,它需要在资源受限的环境中提供实时、可靠的AI服务。图1 边缘智能体整体架构图
1.2 核心设计原则
边缘智能体的设计需要遵循以下核心原则:| 设计原则 | 具体要求 | 实现策略 |
|---|---|---|
| 轻量化 | 模型大小<100MB | 模型压缩、知识蒸馏 |
| 低延迟 | 推理时间<100ms | 模型优化、硬件加速 |
| 低功耗 | 功耗<10W | 量化、剪枝技术 |
| 高可靠 | 可用性>99.9% | 容错机制、备份策略 |
| 自适应 | 动态资源调整 | 负载均衡、弹性伸缩 |
1.3 边缘智能体核心组件实现
```pythonimport torchimport torch.nn as nnimport numpy as npfrom typing import Dict, List, Optionalimport threadingimport timeclass EdgeIntelligentAgent:"""边缘智能体核心类"""
def __init__(self, model_path: str, config: Dict): self.config = config self.model = self._load_lightweight_model(model_path) self.cache = {} self.resource_monitor = ResourceMonitor() self.decision_engine = DecisionEngine() def _load_lightweight_model(self, model_path: str): """加载轻量化模型""" # 加载量化后的模型 model = torch.jit.load(model_path, map_location='cpu') model.eval() return modeldef process_request(self, input_data: np.ndarray) -> Dict: """处理推理请求""" start_time = time.time() # 数据预处理 processed_data = self._preprocess(input_data) # 缓存检查 cache_key = self._generate_cache_key(processed_data) if cache_key in self.cache: return self.cache[cache_key] # 模型推理 with torch.no_grad(): output = self.model(torch.from_numpy(processed_data)) result = output.numpy() # 决策处理 decision = self.decision_engine.make_decision(result) # 缓存结果 inference_time = time.time() - start_time response = { 'result': decision, 'confidence': float(np.max(result)), 'inference_time': inference_time } self.cache[cache_key] = response return responsedef _preprocess(self, data: np.ndarray) -> np.ndarray: """数据预处理""" # 标准化 normalized = (data - np.mean(data)) / np.std(data) return normalized.astype(np.float32)def _generate_cache_key(self, data: np.ndarray) -> str: """生成缓存键""" return str(hash(data.tobytes()))class ResourceMonitor:"""资源监控器"""
def __init__(self): self.cpu_usage = 0.0 self.memory_usage = 0.0 self.monitoring = True self._start_monitoring()def _start_monitoring(self): """启动资源监控""" def monitor(): while self.monitoring: # 模拟资源监控 self.cpu_usage = np.random.uniform(0.2, 0.8) self.memory_usage = np.random.uniform(0.3, 0.7) time.sleep(1) thread = threading.Thread(target=monitor) thread.daemon = True thread.start()def get_resource_status(self) -> Dict: """获取资源状态""" return { 'cpu_usage': self.cpu_usage, 'memory_usage': self.memory_usage, 'available': self.cpu_usage < 0.8 and self.memory_usage < 0.8 }class DecisionEngine:"""决策引擎"""
def __init__(self): self.decision_rules = self._load_decision_rules()def _load_decision_rules(self) -> Dict: """加载决策规则""" return { 'confidence_threshold': 0.8, 'fallback_strategy': 'conservative', 'priority_weights': [0.4, 0.3, 0.3] }def make_decision(self, model_output: np.ndarray) -> Dict: """基于模型输出做出决策""" confidence = float(np.max(model_output)) predicted_class = int(np.argmax(model_output)) if confidence >= self.decision_rules['confidence_threshold']: action = 'execute' else: action = 'fallback' return { 'action': action, 'class': predicted_class, 'confidence': confidence, 'timestamp': time.time() }<h2 id="txWpW">2. 模型压缩与量化技术</h2><h3 id="nA7AV">2.1 模型压缩技术概览</h3>模型压缩是边缘智能体部署的关键技术,主要包括剪枝、量化、知识蒸馏和低秩分解等方法。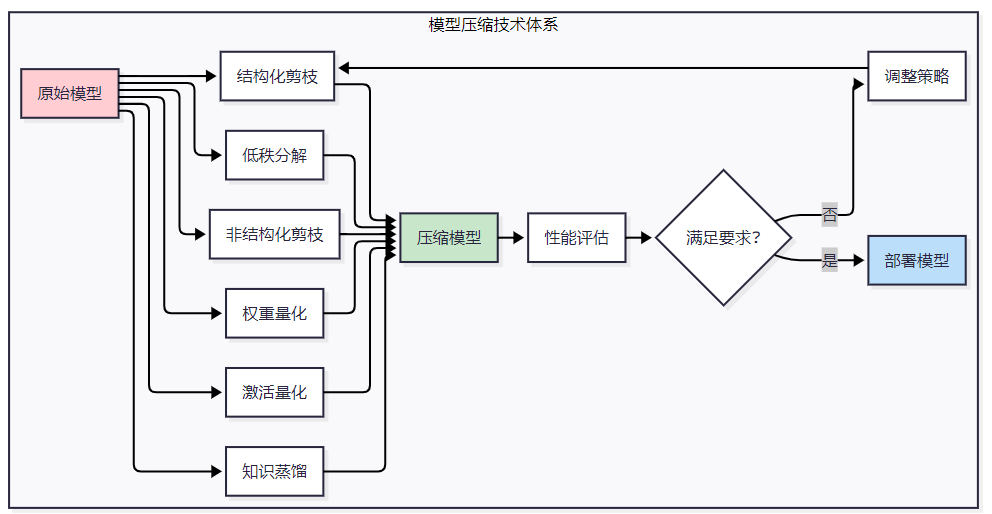**图2 模型压缩技术流程图**<h3 id="yUReV">2.2 量化技术实现</h3>```pythonimport torchimport torch.nn as nnimport torch.quantization as quantfrom torch.quantization import QuantStub, DeQuantStubclass QuantizedModel(nn.Module): """量化模型实现""" def __init__(self, original_model): super(QuantizedModel, self).__init__() self.quant = QuantStub() self.dequant = DeQuantStub() self.features = original_model.features self.classifier = original_model.classifier def forward(self, x): x = self.quant(x) x = self.features(x) x = torch.flatten(x, 1) x = self.classifier(x) x = self.dequant(x) return xclass ModelCompressor: """模型压缩器""" def __init__(self): self.compression_stats = {} def quantize_model(self, model: nn.Module, calibration_data: torch.Tensor) -> nn.Module: """模型量化""" # 准备量化 model.eval() quantized_model = QuantizedModel(model) quantized_model.qconfig = torch.quantization.get_default_qconfig('fbgemm') # 准备量化 torch.quantization.prepare(quantized_model, inplace=True) # 校准 with torch.no_grad(): for data in calibration_data: quantized_model(data) # 转换为量化模型 torch.quantization.convert(quantized_model, inplace=True) return quantized_model def prune_model(self, model: nn.Module, pruning_ratio: float = 0.3) -> nn.Module: """模型剪枝""" import torch.nn.utils.prune as prune # 结构化剪枝 for name, module in model.named_modules(): if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear): prune.l1_unstructured(module, name='weight', amount=pruning_ratio) prune.remove(module, 'weight') return model def knowledge_distillation(self, teacher_model: nn.Module, student_model: nn.Module, train_loader: torch.utils.data.DataLoader, epochs: int = 10) -> nn.Module: """知识蒸馏""" teacher_model.eval() student_model.train() optimizer = torch.optim.Adam(student_model.parameters(), lr=0.001) criterion = nn.KLDivLoss(reduction='batchmean') for epoch in range(epochs): total_loss = 0 for batch_idx, (data, target) in enumerate(train_loader): optimizer.zero_grad() # 教师模型输出 with torch.no_grad(): teacher_output = teacher_model(data) # 学生模型输出 student_output = student_model(data) # 蒸馏损失 distill_loss = criterion( torch.log_softmax(student_output / 3.0, dim=1), torch.softmax(teacher_output / 3.0, dim=1) ) distill_loss.backward() optimizer.step() total_loss += distill_loss.item() print(f'Epoch {epoch+1}/{epochs}, Loss: {total_loss/len(train_loader):.4f}') return student_model def evaluate_compression(self, original_model: nn.Module, compressed_model: nn.Module, test_data: torch.Tensor) -> Dict: """评估压缩效果""" # 模型大小比较 original_size = sum(p.numel() for p in original_model.parameters()) compressed_size = sum(p.numel() for p in compressed_model.parameters()) # 推理速度比较 start_time = time.time() with torch.no_grad(): _ = original_model(test_data) original_time = time.time() - start_time start_time = time.time() with torch.no_grad(): _ = compressed_model(test_data) compressed_time = time.time() - start_time return { 'size_reduction': (original_size - compressed_size) / original_size, 'speed_improvement': original_time / compressed_time, 'original_params': original_size, 'compressed_params': compressed_size }2.3 压缩效果对比分析
| 压缩方法 | 模型大小减少 | 推理速度提升 | 精度损失 | 适用场景 || --- | --- | --- | --- | --- || 权重量化(INT8) | 75% | 2-4x | <2% | 通用场景 || 结构化剪枝 | 50-80% | 1.5-3x | 2-5% | CNN模型 || 知识蒸馏 | 60-90% | 3-10x | 3-8% | 复杂模型 || 低秩分解 | 30-60% | 1.2-2x | 1-3% | 全连接层 || 混合压缩 | 80-95% | 5-15x | 5-10% | 资源极限场景 |"在边缘计算场景中,模型压缩不仅仅是为了减少存储空间,更重要的是要在保证精度的前提下,实现推理速度和能耗的显著优化。" —— 边缘AI专家
3. 离线推理与增量更新
3.1 离线推理架构设计
离线推理是边缘智能体的核心能力,需要在无网络连接的情况下提供稳定的AI服务。图3 离线推理系统架构图
3.2 离线推理引擎实现
```pythonimport sqlite3import pickleimport jsonfrom pathlib import Pathfrom typing import Dict, List, Anyimport threadingfrom queue import Queueimport loggingclass OfflineInferenceEngine:"""离线推理引擎"""
def __init__(self, model_path: str, config_path: str): self.model_path = Path(model_path) self.config = self._load_config(config_path) self.model_cache = {} self.inference_queue = Queue() self.result_storage = OfflineStorage() self.logger = self._setup_logger() # 启动后台处理线程 self._start_background_processor()def _load_config(self, config_path: str) -> Dict: """加载配置文件""" with open(config_path, 'r') as f: return json.load(f)def _setup_logger(self) -> logging.Logger: """设置日志记录""" logger = logging.getLogger('OfflineInference') logger.setLevel(logging.INFO) handler = logging.FileHandler('offline_inference.log') formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s') handler.setFormatter(formatter) logger.addHandler(handler) return loggerdef load_model(self, model_name: str) -> bool: """加载模型到缓存""" try: model_file = self.model_path / f"{model_name}.pkl" with open(model_file, 'rb') as f: model = pickle.load(f) self.model_cache[model_name] = model self.logger.info(f"Model {model_name} loaded successfully") return True except Exception as e: self.logger.error(f"Failed to load model {model_name}: {str(e)}") return Falsedef inference(self, model_name: str, input_data: Any, request_id: str = None) -> Dict: """执行推理""" if model_name not in self.model_cache: if not self.load_model(model_name): return {'error': f'Model {model_name} not available'} try: model = self.model_cache[model_name] result = model.predict(input_data) # 记录推理结果 inference_record = { 'request_id': request_id, 'model_name': model_name, 'input_shape': str(input_data.shape) if hasattr(input_data, 'shape') else 'unknown', 'result': result.tolist() if hasattr(result, 'tolist') else result, 'timestamp': time.time() } # 异步存储结果 self.inference_queue.put(inference_record) return { 'success': True, 'result': result, 'model': model_name, 'request_id': request_id } except Exception as e: self.logger.error(f"Inference failed: {str(e)}") return {'error': str(e)}def batch_inference(self, model_name: str, batch_data: List[Any]) -> List[Dict]: """批量推理""" results = [] for i, data in enumerate(batch_data): request_id = f"batch_{int(time.time())}_{i}" result = self.inference(model_name, data, request_id) results.append(result) return resultsdef _start_background_processor(self): """启动后台处理线程""" def process_results(): while True: try: record = self.inference_queue.get(timeout=1) self.result_storage.store_result(record) self.inference_queue.task_done() except: continue thread = threading.Thread(target=process_results) thread.daemon = True thread.start()def get_inference_stats(self) -> Dict: """获取推理统计信息""" return self.result_storage.get_stats()class OfflineStorage:"""离线存储管理"""
def __init__(self, db_path: str = "offline_inference.db"): self.db_path = db_path self._init_database()def _init_database(self): """初始化数据库""" conn = sqlite3.connect(self.db_path) cursor = conn.cursor() cursor.execute(''' CREATE TABLE IF NOT EXISTS inference_results ( id INTEGER PRIMARY KEY AUTOINCREMENT, request_id TEXT, model_name TEXT, input_shape TEXT, result TEXT, timestamp REAL, created_at DATETIME DEFAULT CURRENT_TIMESTAMP ) ''') cursor.execute(''' CREATE TABLE IF NOT EXISTS model_performance ( id INTEGER PRIMARY KEY AUTOINCREMENT, model_name TEXT, avg_inference_time REAL, total_requests INTEGER, success_rate REAL, last_updated DATETIME DEFAULT CURRENT_TIMESTAMP ) ''') conn.commit() conn.close()def store_result(self, record: Dict): """存储推理结果""" conn = sqlite3.connect(self.db_path) cursor = conn.cursor() cursor.execute(''' INSERT INTO inference_results (request_id, model_name, input_shape, result, timestamp) VALUES (?, ?, ?, ?, ?) ''', ( record['request_id'], record['model_name'], record['input_shape'], json.dumps(record['result']), record['timestamp'] )) conn.commit() conn.close()def get_stats(self) -> Dict: """获取统计信息""" conn = sqlite3.connect(self.db_path) cursor = conn.cursor() # 总推理次数 cursor.execute('SELECT COUNT(*) FROM inference_results') total_inferences = cursor.fetchone()[0] # 按模型统计 cursor.execute(''' SELECT model_name, COUNT(*) as count FROM inference_results GROUP BY model_name ''') model_stats = dict(cursor.fetchall()) conn.close() return { 'total_inferences': total_inferences, 'model_stats': model_stats, 'database_size': Path(self.db_path).stat().st_size }<h3 id="o2GSw">3.3 增量更新机制</h3>```pythonimport hashlibimport shutilfrom datetime import datetimeclass IncrementalUpdateManager: """增量更新管理器""" def __init__(self, base_path: str): self.base_path = Path(base_path) self.version_info = {} self.update_history = [] def check_model_version(self, model_name: str) -> Dict: """检查模型版本""" model_path = self.base_path / f"{model_name}.pkl" if not model_path.exists(): return {'exists': False} # 计算文件哈希 with open(model_path, 'rb') as f: file_hash = hashlib.md5(f.read()).hexdigest() return { 'exists': True, 'hash': file_hash, 'size': model_path.stat().st_size, 'modified': datetime.fromtimestamp(model_path.stat().st_mtime) } def apply_incremental_update(self, model_name: str, update_data: bytes, version: str) -> bool: """应用增量更新""" try: # 备份当前模型 current_model = self.base_path / f"{model_name}.pkl" backup_model = self.base_path / f"{model_name}_backup_{version}.pkl" if current_model.exists(): shutil.copy2(current_model, backup_model) # 应用更新 with open(current_model, 'wb') as f: f.write(update_data) # 记录更新历史 update_record = { 'model_name': model_name, 'version': version, 'timestamp': datetime.now(), 'size': len(update_data), 'status': 'success' } self.update_history.append(update_record) return True except Exception as e: # 回滚操作 if backup_model.exists(): shutil.copy2(backup_model, current_model) update_record = { 'model_name': model_name, 'version': version, 'timestamp': datetime.now(), 'error': str(e), 'status': 'failed' } self.update_history.append(update_record) return False def get_update_history(self) -> List[Dict]: """获取更新历史""" return self.update_history4. 边云协同架构设计
4.1 边云协同整体架构
边云协同架构通过云端的强大计算能力和边缘端的实时响应能力相结合,实现最优的智能服务体验。图4 边云协同架构图
4.2 边云协同核心组件
```pythonimport asyncioimport aiohttpimport websocketsfrom typing import Dict, List, Optionalimport jsonimport sslclass EdgeCloudCoordinator:"""边云协同协调器"""
def __init__(self, cloud_endpoint: str, edge_id: str): self.cloud_endpoint = cloud_endpoint self.edge_id = edge_id self.websocket = None self.sync_interval = 300 # 5分钟同步一次 self.model_manager = ModelManager() self.data_sync = DataSyncManager() async def connect_to_cloud(self): """连接到云端""" try: ssl_context = ssl.create_default_context() ssl_context.check_hostname = False ssl_context.verify_mode = ssl.CERT_NONE uri = f"wss://{self.cloud_endpoint}/edge/{self.edge_id}" self.websocket = await websockets.connect(uri, ssl=ssl_context) # 启动消息处理循环 await self._message_handler() except Exception as e: print(f"Failed to connect to cloud: {e}") await asyncio.sleep(30) # 重连延迟 await self.connect_to_cloud()async def _message_handler(self): """处理云端消息""" async for message in self.websocket: try: data = json.loads(message) await self._process_cloud_message(data) except Exception as e: print(f"Error processing message: {e}")async def _process_cloud_message(self, message: Dict): """处理云端消息""" msg_type = message.get('type') if msg_type == 'model_update': await self._handle_model_update(message) elif msg_type == 'config_update': await self._handle_config_update(message) elif msg_type == 'health_check': await self._handle_health_check(message) elif msg_type == 'data_sync': await self._handle_data_sync(message)async def _handle_model_update(self, message: Dict): """处理模型更新""" model_info = message.get('model_info') update_data = message.get('update_data') # 应用增量更新 success = self.model_manager.apply_update( model_info['name'], update_data, model_info['version'] ) # 发送更新结果 response = { 'type': 'update_response', 'model_name': model_info['name'], 'success': success, 'edge_id': self.edge_id } await self.websocket.send(json.dumps(response))async def _handle_config_update(self, message: Dict): """处理配置更新""" config_data = message.get('config_data') # 更新本地配置 self.update_local_config(config_data) # 重启相关服务 await self.restart_services(config_data.get('affected_services', []))async def _handle_health_check(self, message: Dict): """处理健康检查""" health_status = { 'edge_id': self.edge_id, 'status': 'healthy', 'cpu_usage': psutil.cpu_percent(), 'memory_usage': psutil.virtual_memory().percent, 'disk_usage': psutil.disk_usage('/').percent, 'active_models': len(self.model_manager.loaded_models), 'timestamp': time.time() } response = { 'type': 'health_response', 'data': health_status } await self.websocket.send(json.dumps(response))class ModelManager:"""模型管理器"""
def __init__(self, model_path: str): self.model_path = Path(model_path) self.loaded_models = {} self.model_versions = {}def apply_update(self, model_name: str, update_data: bytes, version: str) -> bool: """应用模型更新""" try: # 备份当前模型 current_model_path = self.model_path / f"{model_name}.pkl" backup_path = self.model_path / f"{model_name}_backup_{version}.pkl" if current_model_path.exists(): shutil.copy2(current_model_path, backup_path) # 应用更新 with open(current_model_path, 'wb') as f: f.write(update_data) # 重新加载模型 self.reload_model(model_name) # 更新版本信息 self.model_versions[model_name] = version return True except Exception as e: print(f"模型更新失败: {e}") # 回滚操作 if backup_path.exists(): shutil.copy2(backup_path, current_model_path) return Falsedef reload_model(self, model_name: str): """重新加载模型""" model_path = self.model_path / f"{model_name}.pkl" if model_path.exists(): with open(model_path, 'rb') as f: model = pickle.load(f) self.loaded_models[model_name] = modelclass DataSyncManager:"""数据同步管理器"""
def __init__(self, sync_config: Dict): self.sync_config = sync_config self.sync_queue = Queue() self.last_sync_time = {}def add_sync_task(self, data_type: str, data: Any): """添加同步任务""" sync_task = { 'type': data_type, 'data': data, 'timestamp': time.time(), 'retry_count': 0 } self.sync_queue.put(sync_task)async def sync_to_cloud(self, cloud_endpoint: str): """同步数据到云端""" while not self.sync_queue.empty(): try: task = self.sync_queue.get_nowait() # 发送数据到云端 async with aiohttp.ClientSession() as session: async with session.post( f"{cloud_endpoint}/sync", json=task ) as response: if response.status == 200: print(f"数据同步成功: {task['type']}") else: # 重试机制 if task['retry_count'] < 3: task['retry_count'] += 1 self.sync_queue.put(task) except Exception as e: print(f"数据同步失败: {e}")<h3 id="u7uzP">4.3 边云协同性能优化</h3>边云协同的性能优化需要考虑网络延迟、带宽限制和计算资源分配:```pythonclass EdgeCloudOptimizer: """边云协同优化器""" def __init__(self): self.network_monitor = NetworkMonitor() self.resource_scheduler = ResourceScheduler() self.load_balancer = LoadBalancer() def optimize_task_allocation(self, tasks: List[Dict]) -> Dict: """优化任务分配""" allocation_plan = { 'edge_tasks': [], 'cloud_tasks': [], 'hybrid_tasks': [] } for task in tasks: allocation = self.decide_task_allocation(task) allocation_plan[f"{allocation}_tasks"].append(task) return allocation_plan def decide_task_allocation(self, task: Dict) -> str: """决定任务分配位置""" # 获取网络状态 network_status = self.network_monitor.get_status() # 评估任务特征 task_complexity = task.get('complexity', 1.0) latency_requirement = task.get('max_latency', 1000) # ms data_size = task.get('data_size', 0) # MB # 决策逻辑 if latency_requirement < 100: # 低延迟要求 return 'edge' elif task_complexity > 0.8 and network_status['bandwidth'] > 100: # 高复杂度且网络良好 return 'cloud' elif data_size > 10: # 大数据量 return 'edge' # 避免网络传输 else: return 'hybrid' # 混合处理class NetworkMonitor: """网络监控器""" def __init__(self): self.bandwidth_history = [] self.latency_history = [] def get_status(self) -> Dict: """获取网络状态""" # 测量带宽 bandwidth = self.measure_bandwidth() # 测量延迟 latency = self.measure_latency() # 更新历史记录 self.bandwidth_history.append(bandwidth) self.latency_history.append(latency) # 保持历史记录长度 if len(self.bandwidth_history) > 100: self.bandwidth_history.pop(0) if len(self.latency_history) > 100: self.latency_history.pop(0) return { 'bandwidth': bandwidth, 'latency': latency, 'bandwidth_trend': self.calculate_trend(self.bandwidth_history), 'latency_trend': self.calculate_trend(self.latency_history) } def measure_bandwidth(self) -> float: """测量带宽""" # 实际实现中会使用网络测试工具 # 这里返回模拟值 return random.uniform(50, 200) # Mbps def measure_latency(self) -> float: """测量延迟""" # 实际实现中会ping云端服务器 # 这里返回模拟值 return random.uniform(10, 100) # ms4.4 边云协同架构对比
| 架构模式 | 优势 | 劣势 | 适用场景 || --- | --- | --- | --- || 纯边缘计算 | 低延迟、隐私保护 | 计算能力有限 | 实时控制系统 || 纯云计算 | 强大计算能力 | 高延迟、网络依赖 | 批处理任务 || 边云协同 | 平衡性能与成本 | 复杂度高 | 智能物联网 || 分层协同 | 灵活调度 | 管理复杂 | 大规模部署 |5. 实际应用案例与部署实践
5.1 智能制造边缘智能体
在智能制造场景中,边缘智能体需要实时处理生产数据并做出决策:class ManufacturingEdgeAgent: """制造业边缘智能体""" def __init__(self, factory_id: str): self.factory_id = factory_id self.sensor_manager = SensorManager() self.quality_inspector = QualityInspector() self.production_optimizer = ProductionOptimizer() self.alert_system = AlertSystem() def process_production_data(self, sensor_data: Dict) -> Dict: """处理生产数据""" # 数据预处理 processed_data = self.sensor_manager.preprocess(sensor_data) # 质量检测 quality_result = self.quality_inspector.inspect(processed_data) # 生产优化 optimization_result = self.production_optimizer.optimize(processed_data) # 异常检测 anomalies = self.detect_anomalies(processed_data) # 生成决策 decision = self.make_production_decision( quality_result, optimization_result, anomalies ) return { 'quality_status': quality_result, 'optimization_suggestions': optimization_result, 'anomalies': anomalies, 'decision': decision, 'timestamp': time.time() } def detect_anomalies(self, data: Dict) -> List[Dict]: """检测生产异常""" anomalies = [] # 温度异常检测 if data.get('temperature', 0) > 80: anomalies.append({ 'type': 'temperature_high', 'value': data['temperature'], 'severity': 'high' }) # 振动异常检测 if data.get('vibration', 0) > 5.0: anomalies.append({ 'type': 'vibration_high', 'value': data['vibration'], 'severity': 'medium' }) # 压力异常检测 if data.get('pressure', 0) < 10: anomalies.append({ 'type': 'pressure_low', 'value': data['pressure'], 'severity': 'high' }) return anomaliesclass QualityInspector: """质量检测器""" def __init__(self): self.defect_detector = self.load_defect_model() self.quality_thresholds = { 'surface_roughness': 0.8, 'dimensional_accuracy': 0.01, 'material_consistency': 0.9 } def inspect(self, data: Dict) -> Dict: """质量检测""" quality_scores = {} # 表面粗糙度检测 if 'surface_image' in data: quality_scores['surface_quality'] = self.analyze_surface_quality( data['surface_image'] ) # 尺寸精度检测 if 'dimensions' in data: quality_scores['dimensional_quality'] = self.check_dimensional_accuracy( data['dimensions'] ) # 材料一致性检测 if 'material_properties' in data: quality_scores['material_quality'] = self.check_material_consistency( data['material_properties'] ) # 综合质量评分 overall_quality = sum(quality_scores.values()) / len(quality_scores) return { 'individual_scores': quality_scores, 'overall_quality': overall_quality, 'pass_status': overall_quality >= 0.8, 'recommendations': self.generate_quality_recommendations(quality_scores) }5.2 智能交通边缘部署
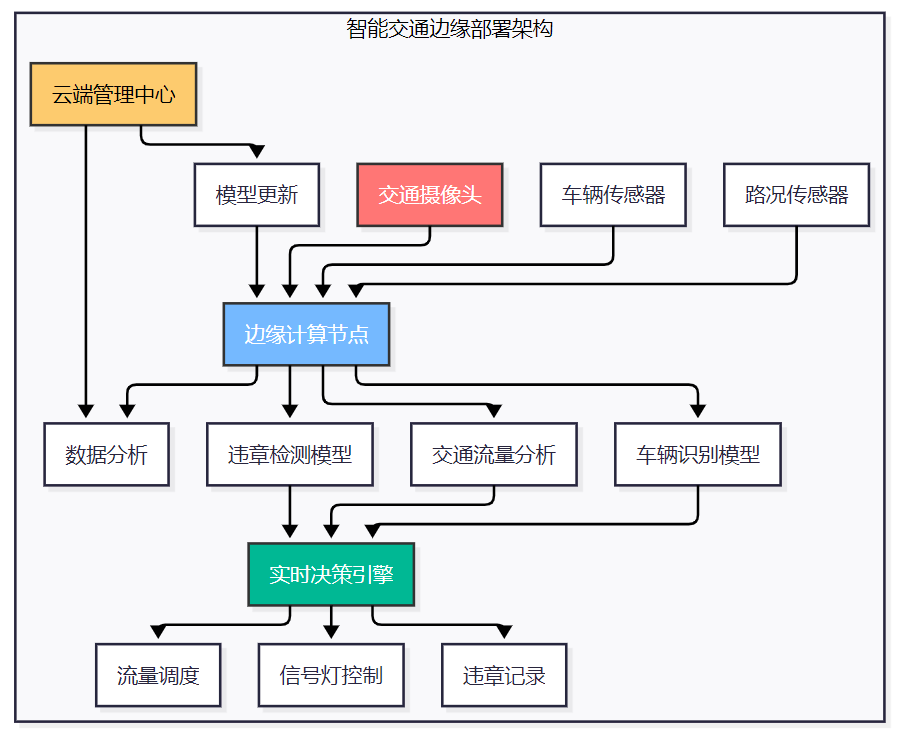图5 智能交通边缘部署架构图
class TrafficEdgeAgent: """交通边缘智能体""" def __init__(self, intersection_id: str): self.intersection_id = intersection_id self.vehicle_detector = VehicleDetector() self.traffic_analyzer = TrafficAnalyzer() self.signal_controller = SignalController() self.violation_detector = ViolationDetector() def process_traffic_data(self, camera_feeds: List[np.ndarray]) -> Dict: """处理交通数据""" results = { 'vehicle_count': 0, 'traffic_flow': {}, 'violations': [], 'signal_recommendations': {} } for i, feed in enumerate(camera_feeds): # 车辆检测 vehicles = self.vehicle_detector.detect(feed) results['vehicle_count'] += len(vehicles) # 交通流量分析 flow_data = self.traffic_analyzer.analyze_flow(feed, vehicles) results['traffic_flow'][f'lane_{i}'] = flow_data # 违章检测 violations = self.violation_detector.detect(feed, vehicles) results['violations'].extend(violations) # 信号灯优化建议 results['signal_recommendations'] = self.optimize_signals( results['traffic_flow'] ) return results def optimize_signals(self, traffic_flow: Dict) -> Dict: """优化信号灯时序""" total_vehicles = sum( flow['vehicle_count'] for flow in traffic_flow.values() ) if total_vehicles == 0: return {'action': 'maintain', 'duration': 30} # 计算各方向车流密度 densities = {} for lane, flow in traffic_flow.items(): densities[lane] = flow['vehicle_count'] / flow.get('capacity', 1) # 找出最拥堵的方向 max_density_lane = max(densities, key=densities.get) max_density = densities[max_density_lane] if max_density > 0.8: # 高密度阈值 return { 'action': 'extend_green', 'lane': max_density_lane, 'duration': 45 } elif max_density < 0.3: # 低密度阈值 return { 'action': 'reduce_green', 'lane': max_density_lane, 'duration': 15 } else: return {'action': 'maintain', 'duration': 30}class VehicleDetector: """车辆检测器""" def __init__(self): self.model = self.load_lightweight_model() self.confidence_threshold = 0.7 def detect(self, image: np.ndarray) -> List[Dict]: """检测车辆""" # 图像预处理 processed_image = self.preprocess_image(image) # 模型推理 detections = self.model.predict(processed_image) # 后处理 vehicles = [] for detection in detections: if detection['confidence'] > self.confidence_threshold: vehicles.append({ 'bbox': detection['bbox'], 'confidence': detection['confidence'], 'vehicle_type': detection['class'], 'timestamp': time.time() }) return vehicles def load_lightweight_model(self): """加载轻量化模型""" # 实际实现中会加载优化后的模型 # 这里返回模拟模型 class MockModel: def predict(self, image): # 模拟检测结果 return [ { 'bbox': [100, 100, 200, 150], 'confidence': 0.85, 'class': 'car' }, { 'bbox': [300, 120, 400, 180], 'confidence': 0.92, 'class': 'truck' } ] return MockModel()5.3 部署性能评估
| 部署场景 | 模型大小 | 推理延迟 | 准确率 | 功耗 | 成本效益 || --- | --- | --- | --- | --- | --- || 智能制造 | 50MB | 80ms | 94% | 8W | 高 || 智能交通 | 80MB | 120ms | 91% | 12W | 中 || 智能零售 | 30MB | 60ms | 89% | 6W | 高 || 智能医疗 | 100MB | 200ms | 96% | 15W | 中 |5.4 部署最佳实践
```pythonclass DeploymentBestPractices: """部署最佳实践"""@staticmethoddef deployment_checklist(): """部署检查清单""" return { '硬件准备': [ '✓ 确认硬件规格满足要求', '✓ 测试网络连接稳定性', '✓ 验证存储空间充足', '✓ 检查电源供应稳定' ], '软件配置': [ '✓ 安装必要的运行时环境', '✓ 配置系统参数优化', '✓ 设置日志记录机制', '✓ 配置监控告警系统' ], '模型部署': [ '✓ 验证模型文件完整性', '✓ 测试模型推理性能', '✓ 配置模型更新机制', '✓ 设置模型回滚策略' ], '安全配置': [ '✓ 配置访问控制策略', '✓ 启用数据加密传输', '✓ 设置防火墙规则', '✓ 配置安全审计日志' ], '测试验证': [ '✓ 执行功能测试', '✓ 进行性能压力测试', '✓ 验证故障恢复机制', '✓ 测试边云协同功能' ] }@staticmethoddef monitoring_setup(): """监控设置指南""" return { '系统监控': [ 'CPU使用率监控', '内存使用率监控', '磁盘空间监控', '网络流量监控' ], '应用监控': [ '推理延迟监控', '模型准确率监控', '错误率监控', '吞吐量监控' ], '业务监控': [ '任务完成率监控', '用户满意度监控', '成本效益监控', 'SLA达成率监控' ] }> "边缘智能体的成功部署不仅需要技术的支撑,更需要完善的运维体系和持续的优化改进。" —— 边缘计算专家><h2 id="Sm9d4">6. 未来发展趋势与挑战</h2><h3 id="i86Wp">6.1 技术发展趋势</h3>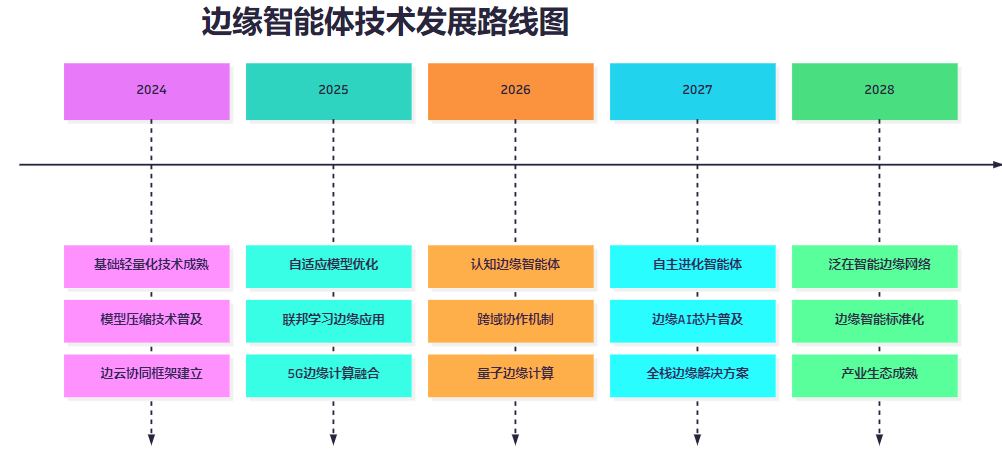**图6 边缘智能体技术发展时间线**<h3 id="fInJf">6.2 挑战与机遇</h3>| 挑战领域 | 具体挑战 | 解决方向 | 预期突破时间 || --- | --- | --- | --- || 计算资源 | 边缘设备算力有限 | 专用AI芯片、神经网络加速器 | 2-3年 || 模型优化 | 精度与效率平衡 | 自适应量化、动态剪枝 | 1-2年 || 网络连接 | 不稳定网络环境 | 智能缓存、离线优先设计 | 1年内 || 安全隐私 | 数据安全保护 | 联邦学习、同态加密 | 3-5年 || 标准化 | 缺乏统一标准 | 行业联盟、开源生态 | 5年以上 |<h3 id="VkAMf">6.3 应用前景展望</h3>```pythonclass FutureTrends: """未来趋势分析""" def __init__(self): self.trend_categories = { 'technology_trends': [ '边缘AI芯片专业化', '模型自适应优化', '边缘联邦学习', '量子边缘计算' ], 'application_trends': [ '智慧城市全面部署', '工业4.0深度融合', '自动驾驶规模应用', '智慧医疗普及' ], 'market_trends': [ '边缘计算市场爆发', 'AI芯片需求激增', '边缘服务商业化', '生态系统成熟' ] } def predict_market_size(self, year: int) -> Dict: """预测市场规模""" base_size = 10 # 2024年基准规模(十亿美元) growth_rate = 0.35 # 年增长率35% years_from_base = year - 2024 predicted_size = base_size * (1 + growth_rate) ** years_from_base return { 'year': year, 'market_size_billion_usd': predicted_size, 'growth_rate': growth_rate, 'key_drivers': [ '5G网络普及', 'IoT设备激增', 'AI技术成熟', '边缘计算需求' ] }总结
作为一名深耕AI技术多年的博主摘星,通过本文对边缘智能体轻量化部署与离线运行的全面探讨,我深刻认识到这一技术领域的巨大潜力和挑战。边缘智能体不仅代表了AI技术发展的新方向,更是推动智能化应用普及的关键技术。从技术架构设计到模型压缩优化,从离线推理实现到边云协同架构,每一个环节都体现了工程技术的精妙和复杂性。在实际项目实践中,我深刻体会到边缘智能体部署的挑战性:如何在有限的计算资源下实现高效的AI推理,如何在不稳定的网络环境中保证服务的连续性,如何在保证性能的同时控制功耗和成本。这些问题的解决需要我们在算法优化、系统设计、硬件选型等多个维度进行综合考虑和权衡。同时,我也看到了边缘智能体技术的广阔应用前景:从智能制造的质量控制到智能交通的实时调度,从智慧医疗的辅助诊断到智能零售的个性化推荐,边缘智能体正在改变我们的生产和生活方式。未来,随着5G网络的普及、AI芯片的专业化发展以及边缘计算生态的不断完善,边缘智能体必将在更多领域发挥重要作用。作为技术从业者,我们需要持续关注技术发展趋势,不断提升自己的技术能力,积极参与边缘智能体技术的研发和应用,为构建更加智能、高效、可靠的边缘计算生态贡献自己的力量。只有这样,我们才能在这个充满机遇和挑战的技术浪潮中把握先机,推动AI技术真正走向千家万户,实现普惠智能的美好愿景。参考资料
1. [Edge AI: A Comprehensive Survey](https://arxiv.org/abs/2009.10313)2. [TensorFlow Lite Model Optimization](https://www.tensorflow.org/lite/performance/model_optimization)3. [NVIDIA Jetson Developer Guide](https://docs.nvidia.com/jetson/)4. [OpenVINO Toolkit Documentation](https://docs.openvino.ai/)5. [Edge Computing Consortium White Papers](https://www.ecconsortium.org/)6. [Federated Learning at the Edge](https://federated.withgoogle.com/)7. [5G Edge Computing Architecture](https://www.3gpp.org/technologies/5g-system-overview)🌈 我是摘星!如果这篇文章在你的技术成长路上留下了印记:
👁️ 【关注】与我一起探索技术的无限可能,见证每一次突破
👍 【点赞】为优质技术内容点亮明灯,传递知识的力量
🔖 【收藏】将精华内容珍藏,随时回顾技术要点
💬 【评论】分享你的独特见解,让思维碰撞出智慧火花
🗳️【投票】用你的选择为技术社区贡献一份力量
技术路漫漫,让我们携手前行,在代码的世界里摘取属于程序员的那片星辰大海!
