
Published on July 23, 2025 4:18 PM GMT
Authors: Jake Ward, Chuqiao Lin, Constantin Venhoff, Neel Nanda (*Equal contribution). This work was completed during Neel Nanda's MATS 8.0 Training Phase.
TL;DR
- We computed a steering vector for backtracking using base model activations.It causes the associated fine-tuned reasoning model to backtrack.But, it doesn't cause the base model to backtrack.
- That's weird!
Introduction
Reasoning models output Wait, a lot. How did they learn to do this? Backtracking is an emergent behavior in RL-finetuned reasoning models like DeepSeek-R1, and appears to contribute substantially to these models' improved reasoning capabilities. We study representations related to this behavior using steering vectors, and find a direction which is present both in base models and associated reasoning-finetuned models but induces backtracking only in reasoning models. We interpret this direction as representing some concept upstream of backtracking which the base model has learned to keep track of, while only the reasoning model has learned to use this concept for backtracking.
We start with methodology similar to Venhoff et al.: We generate a corpus of reasoning rollouts using DeepSeek-R1, and annotate them to identify backtracking sentences using GPT-4o. Then, we train difference-of-means steering vectors with two novel properties:
- We compute steering vectors using token positions which occur before backtracking, using a 5-token window which starts 12 tokens before the beginning of a backtracking sentence. This usually includes the beginning of the sentence immediately before a backtracking sentence.We sample activations from a forward pass of the base model (
Llama-3.1-8b) at layer 10, and use computed vectors to steer the reasoning model (DeepSeek-R1-Distill-Llama-8B).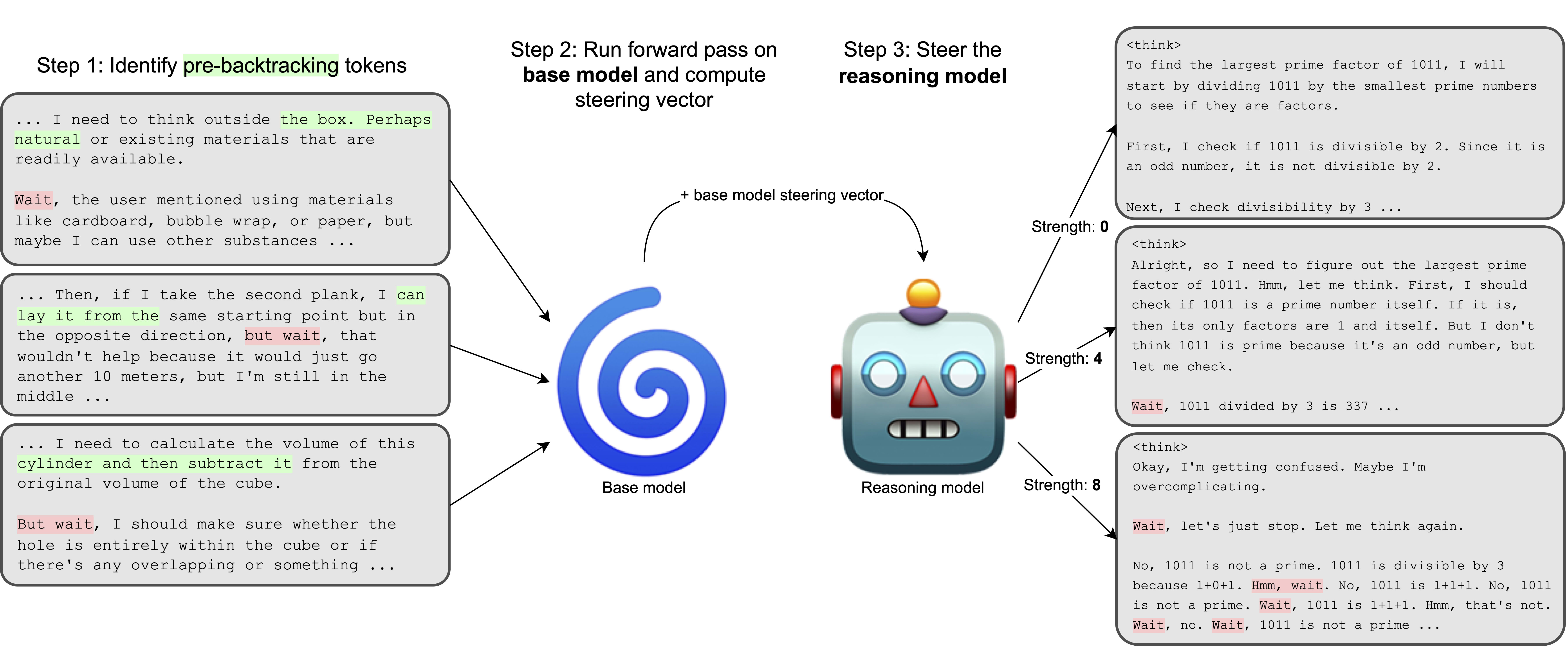
Surprisingly, we find that steering vectors computed with this method are highly effective at inducing the emission of backtracking tokens ( Wait, But, etc.) in the reasoning model, but not in the base model.
Additionally, if we instead sample activations from the reasoning model, we end up computing a nearly identical vector with > 0.7 cosine similarity. These vectors behave similarly: They induce backtracking in the reasoning model, but not in the base model.
Analysis
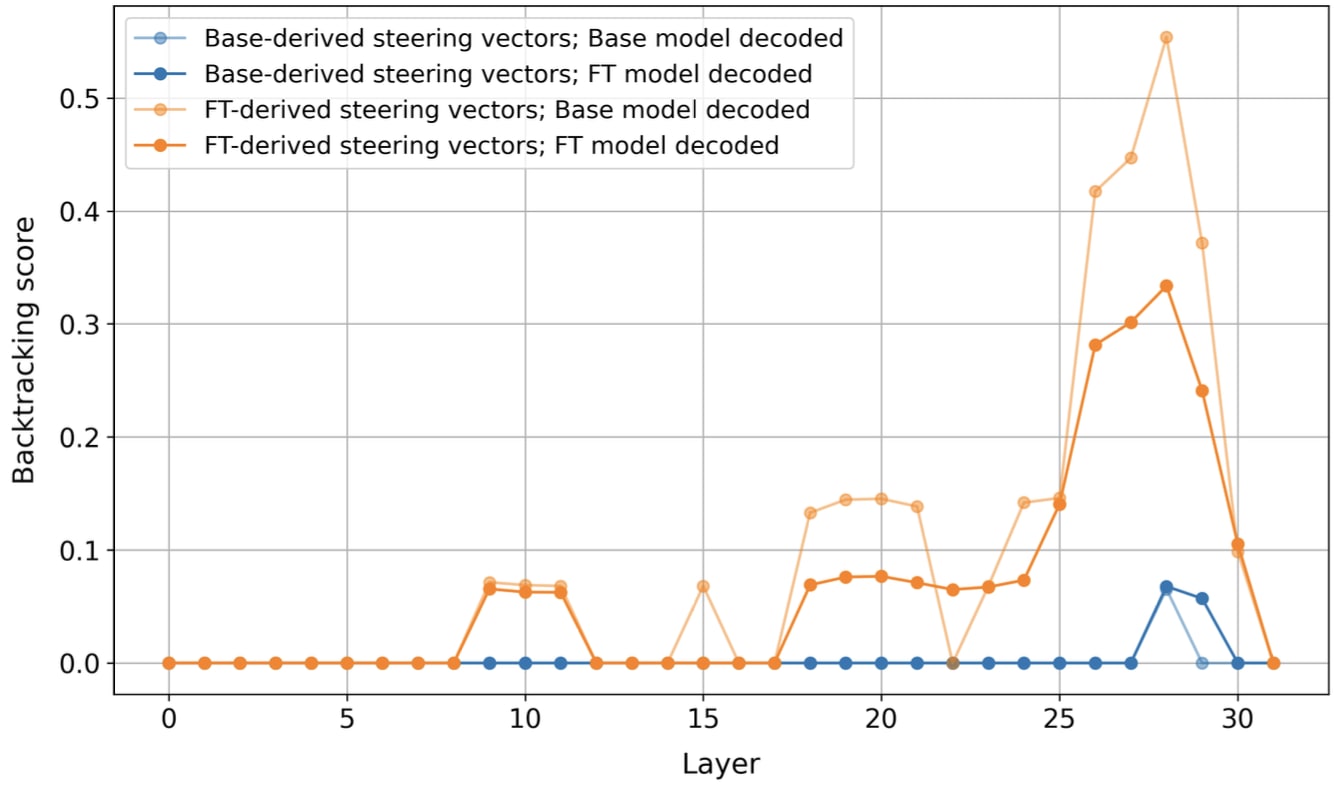
Logit Lens
We considered whether these vectors may be doing something trivial, like directly boosting the logits for backtracking tokens like Wait. We test this with Logit Lens, and find that this is not the case:
Baseline Comparison
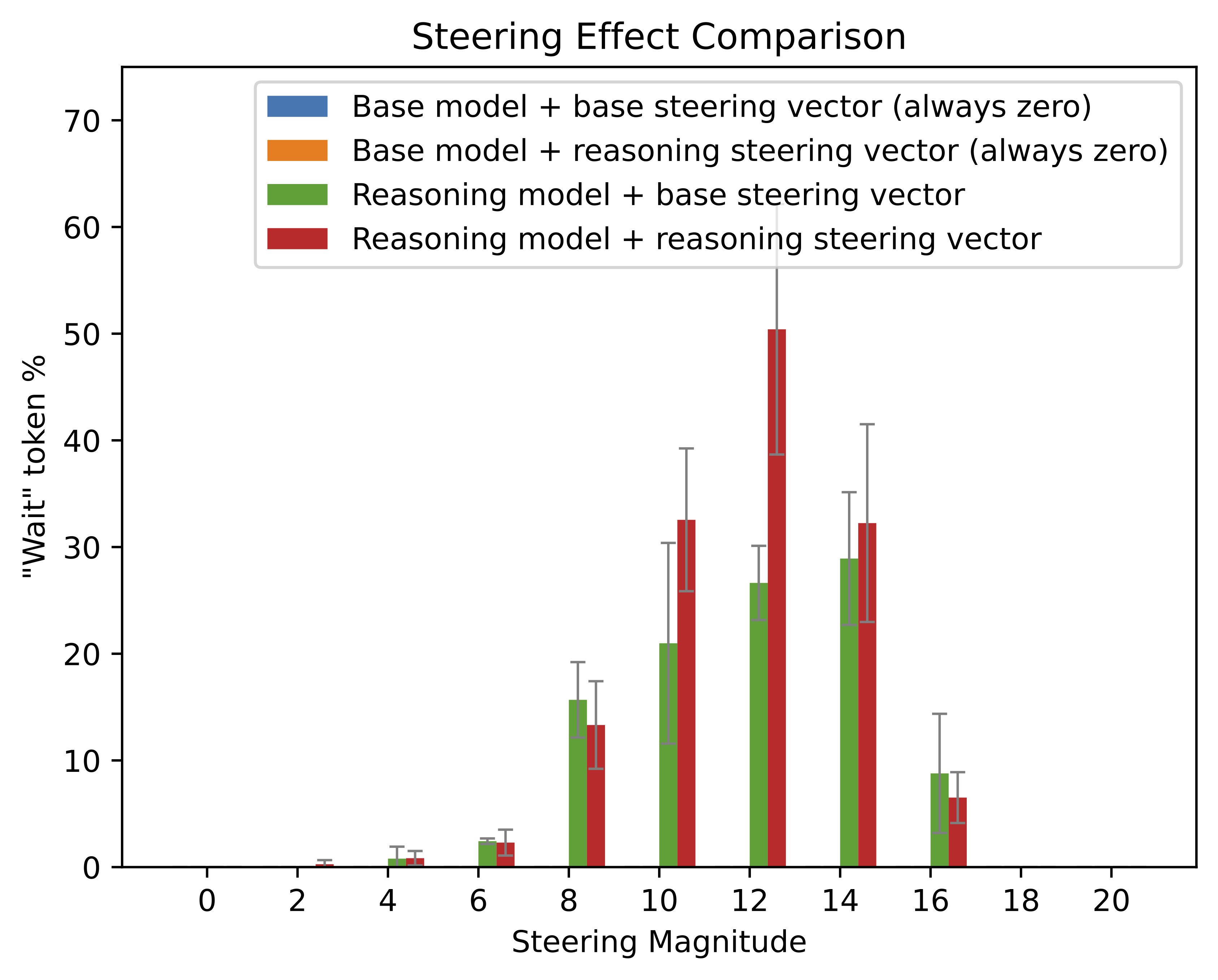
We compare our results to various baselines, and find that our backtracking steering vector has a substantially greater effect on the emission of the Wait token compared to other methods. We try steering with mean activations, adding random noise, increasing the magnitude of activations, and steering vectors computed based on other reasoning behaviors like deduction or initialization (problem restatement). Notably, we do find that adding random noise to activations does induce backtracking token emission slightly, but this effect is small compared to the effect of our backtracking steering vector.

Conclusion
We take this as evidence that backtracking isn't a totally new behavior learned during finetuning. Instead, base models already contain useful concepts which the reasoning-finetuning process finds and repurposes for emergent reasoning behavior. We're still not really sure what concept our steering vector represents, or if there is a monosemantic concept which it represents. We investigated whether it may represent something abstract like "uncertainty", but so far these investigations are inconclusive. These results should be interpreted as an existence proof for latent reasoning-related representations in base models, and we hope they inspire further investigations into the mechanisms involved in CoT reasoning.
Discuss
