
Published on July 23, 2025 2:55 PM GMT
This work was produced during MARS and SPAR. arXiv version available at https://arxiv.org/abs/2507.02559. Code on GitHub and models on HuggingFace.
TL;DR we scaled LayerNorm (LN) removal by fine-tuning to GPT-2 XL:
- We improve training stability by regularizing activation standard deviation across token positions & improve the training code.The process is still not very data efficient (requires about ~1% of original dataset) and fine-tuning is somewhat unstable on larger models.Surprisingly, attribution patching is not more accurate in LN-free models.As expected, direct logit attribution becomes exact, and entropy neurons stop working.
We provide drop-in replacements for GPT-2 small, medium, large, and XL on HuggingFace for all your interpretability needs!
Introduction
LN has been a major obstacle for mechanistic interpretability research as it obstructs the interpretation of the residual stream and complicates model decomposition into circuits. For methods like direct logit attribution and attribution patching, researchers resort to freezing the standard deviation, which is an imperfect approximation. Past attempts at fully removing LN include training tiny models without LN and removal by fine-tuning for GPT-2 Small. We explored how to scale removal by fine-tuning and some properties of LN-free models when it comes to mechanistic interpretability.
Main Achievements
We successfully removed LN from all GPT-2 models up to XL (1.5B parameters) by fine-tuning on OpenWebText (OWT):
| GPT-2 Model | Fine tuning steps | Vanilla CE loss | LN-free CE loss |
|---|---|---|---|
| Small | 300 | 2.8112 | 2.8757 [+0.0858] |
| Medium | 500 | 2.5724 | 2.6352 [+0.0962] |
| Large | 600 | 2.5074 | 2.5159 [+0.0812] |
| XL | 800 | 2.3821 | 2.3992 [+0.0253] |
Performance degradation in LN-free models was small compared to the fine-tuned control (aka "vanilla"), as measured by CE loss on a filtered version of The Pile (The Pile-filtered). See model generations in Appendix A. The runs required 0.3% - 1% of original training data (0.5M tokens per step).
We investigated how the LN-free models behave from a mechanistic interpretability point of view. As expected, direct logit attribution (a method for measuring the impact of a component in the residual stream on the output logits) gives exact direct effect on logits. Surprisingly, attribution patching (a scalable approximation to activation patching) does not improve in LN-free models. We verify that first-position token L2 norm is no longer special compared to the other positions, a fact echoed by a marked reduction in attention sink behavior. Lastly, entropy (confidence) neurons lose their ability to function in the LN-free models.
Scaling Up Removal
We scaled up LN removal by fine-tuning. The method sequentially freezes , , and by setting the standard deviation () to a constant average standard deviation while fine-tuning on original training data. This worked with GPT-2 Small and Medium without modification, but it would break by gradient explosion for Large and XL. We modified the original method in two key ways:
- Recompute average standard deviation on-the-flyPenalize first-position standard deviation error with an auxiliary loss
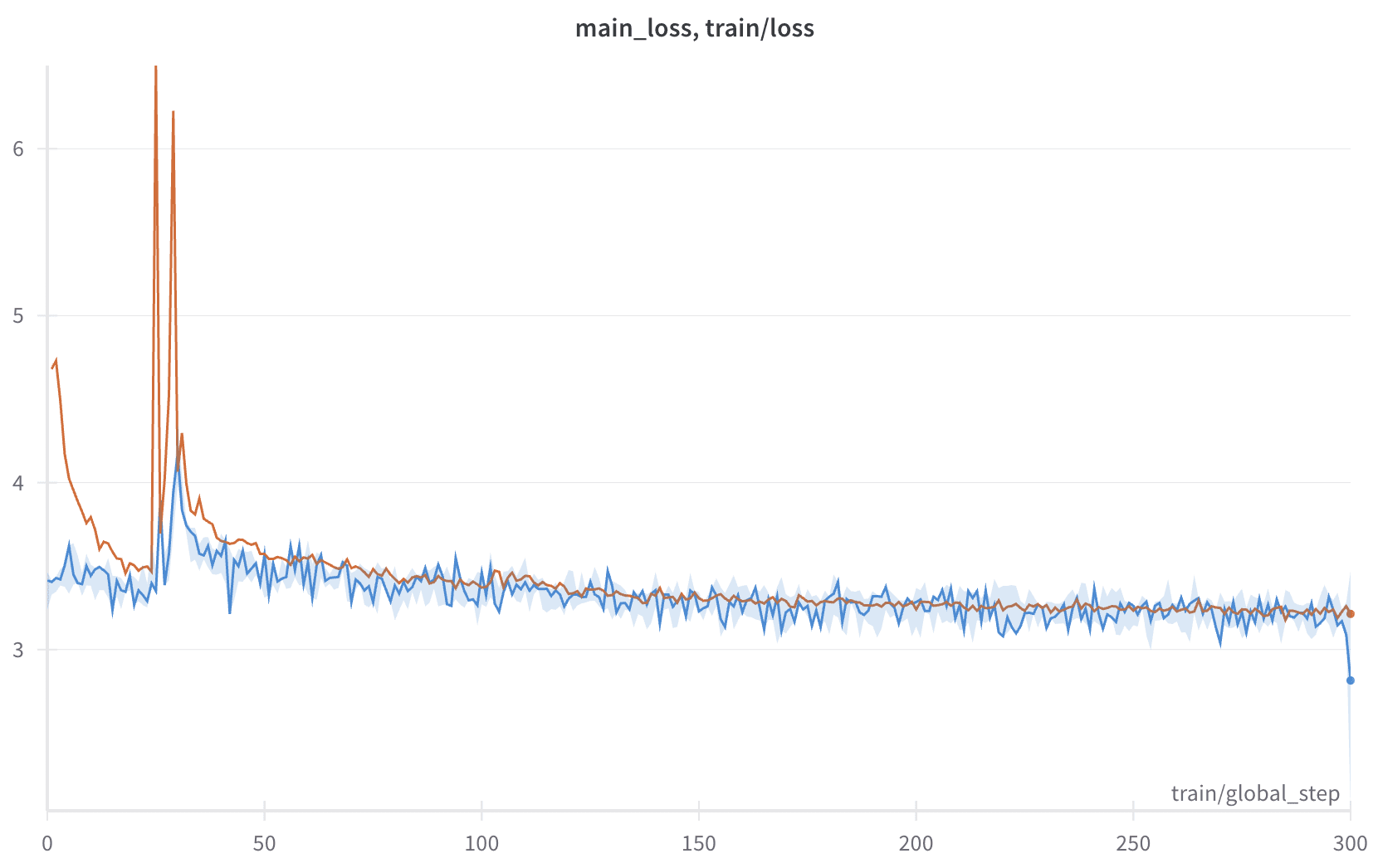
Originally the standard deviation value was precomputed ahead of time for each LN. This created large updates during training and caused instabilities. We addressed this by on-the-fly recomputation using exponential moving average.
To encourage more gradual weight updates during fine-tuning, we instrumented an MSE loss between first-position standard deviation and all other positions at the final LN. This noticeably smoothed the main loss.
Interpretability Results
Direct Logit Attribution
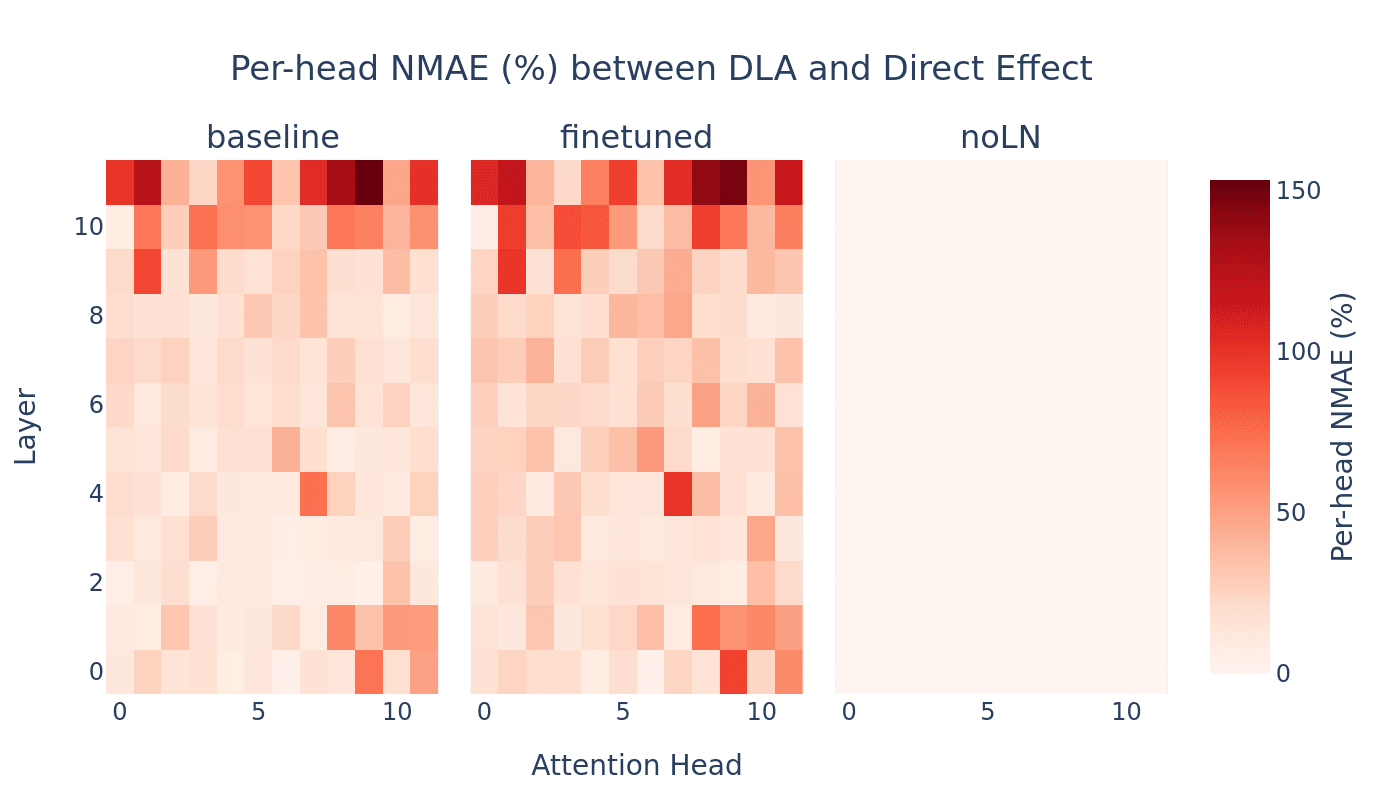
A benefit of removing LN is that direct logit attribution (DLA) becomes exactly equivalent to the direct effect (DE) in causal mediation analysis. The average Normalized Mean Absolute Error (NMAE) between DLA and DE in the original GPT-2 Small model was ~50% when measured across all attention heads on The Pile-filtered test set. This error occurs because DLA uses cached LN parameters from the original forward pass to normalize individual components, while the true direct effect subtracts components from the final residual stream and recomputes LN statistics with the modified residual stream. While both approaches attempt to measure the contribution of a specific component on the final output logits, these methods are equivalent in models without LN.
Attribution Patching
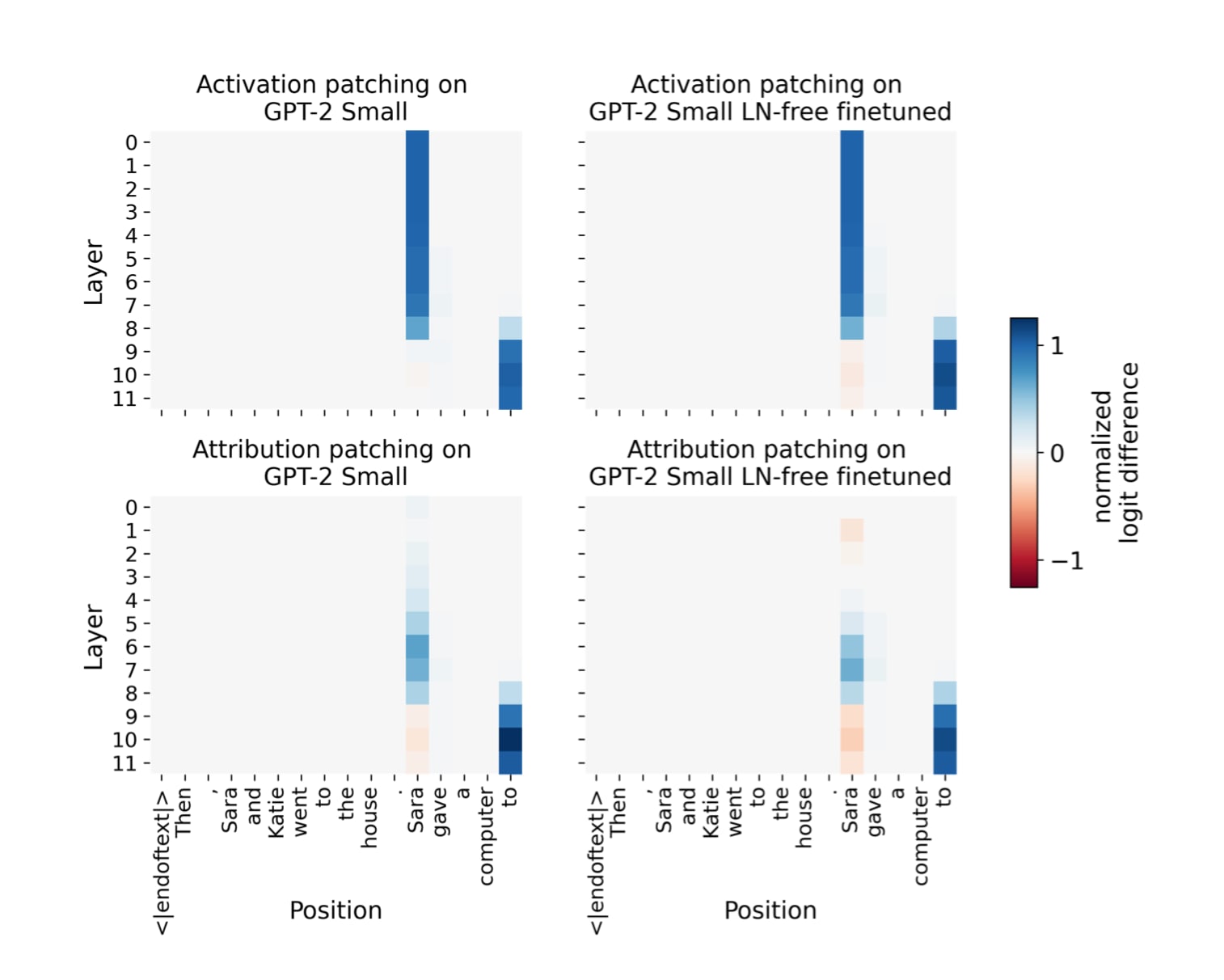
Attribution patching is a fast approximation to activation patching, which allows for simultaneous discovery of counterfactual effects on the patching metric. We compared attribution patching to activation patching on IOI prompts across GPT-2 Small and its LN-free counterpart. Contrary to our expectations, we saw no improvement resulting from removing LayerNorm. Non-linearities in other parts of the network (such as softmax, MLP) must still remain the main limiting factor.
Entropy Neurons
Entropy neurons regulate a model's confidence by writing vectors to the null space of the unembedding matrix, ensuring they don't alter the relative ranking of output predictions. These null space additions change the overall norm of the residual stream before it enters the final LN. This interaction with LN scales all logits uniformly to make the final probability distribution more or less peaked. For each GPT-2 model, the exact same entropy neurons were identified in the original, vanilla fine-tuned, and the LN-free model variants.
A Singular Value Decomposition (SVD) of each model's unembedding matrix reveals that all models have a spectrum of singular values that decays rapidly, indicating an effective null space. This decay is sharper in smaller models, and appears to become more gradual as model size increases. While fine-tuning compresses this null space in smaller models, it notably doesn't affect the largest model, GPT-2 XL.
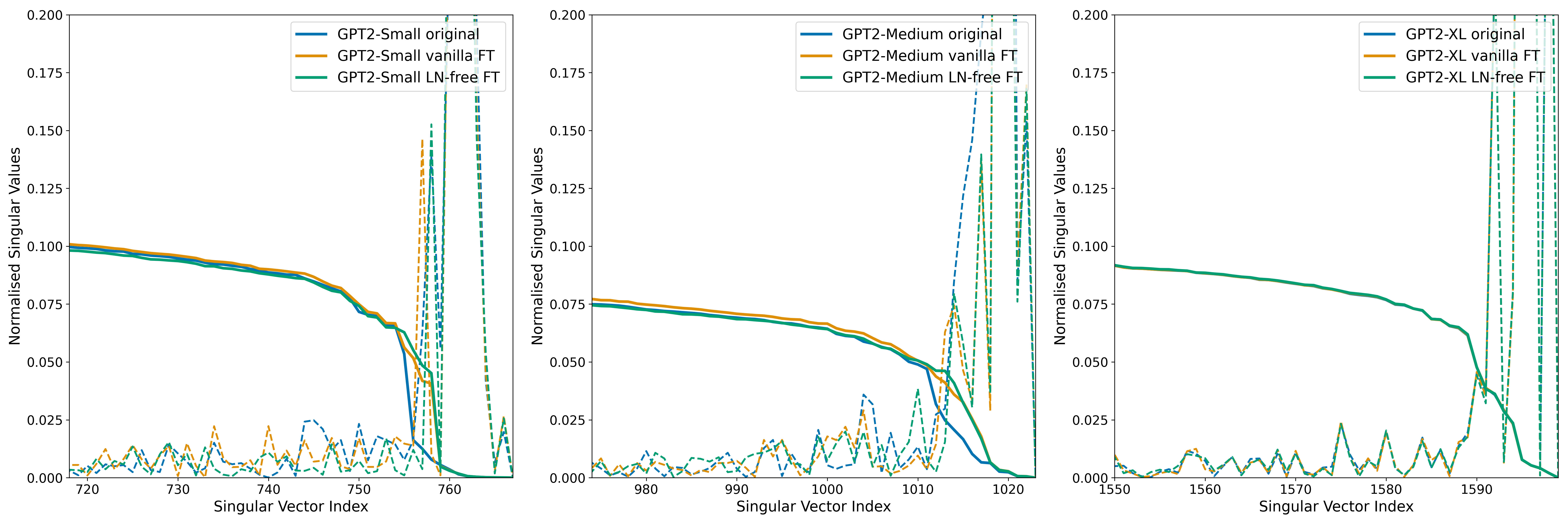
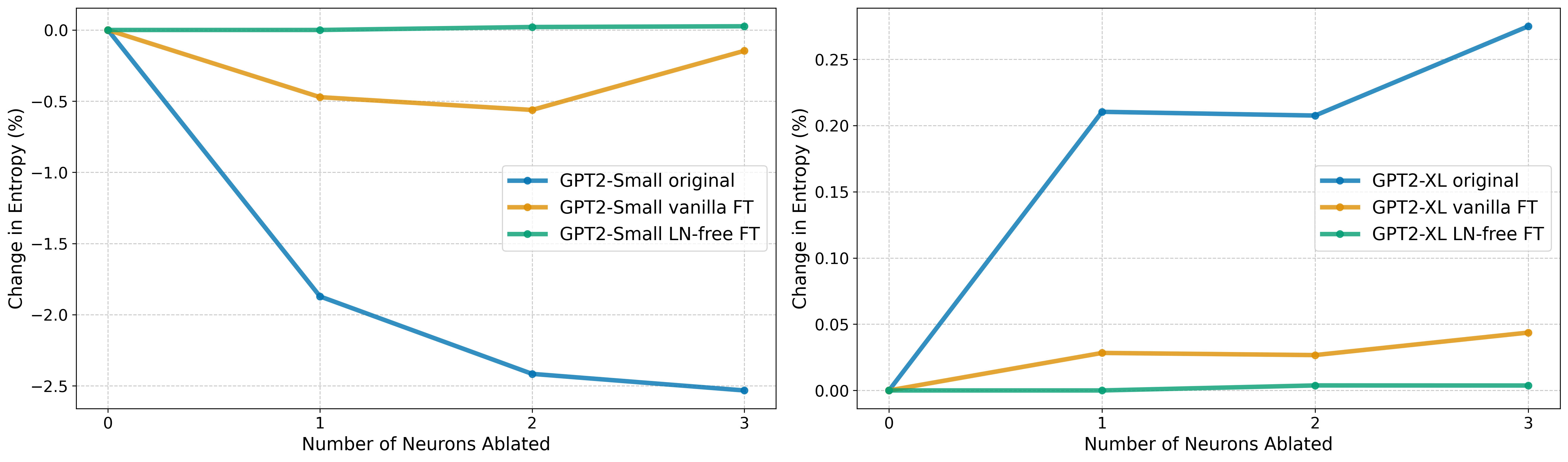
Mean ablation experiments confirmed that LN is essential for entropy neuron function, as ablating them in LN-free models had virtually no effect on the cross-entropy loss. Standard fine-tuning was also found to significantly diminish the influence of entropy neurons on model performance (we do not have a good explanation for this yet). Lastly, this effect decreases as model size increases, with the largest models showing dramatically less impact, possibly due to a less well defined null space. Cumulative ablation experiments confirm these neurons function as confidence regulators, as removing them has an outsized impact on entropy, roughly 10 times greater than the effect on cross-entropy loss.
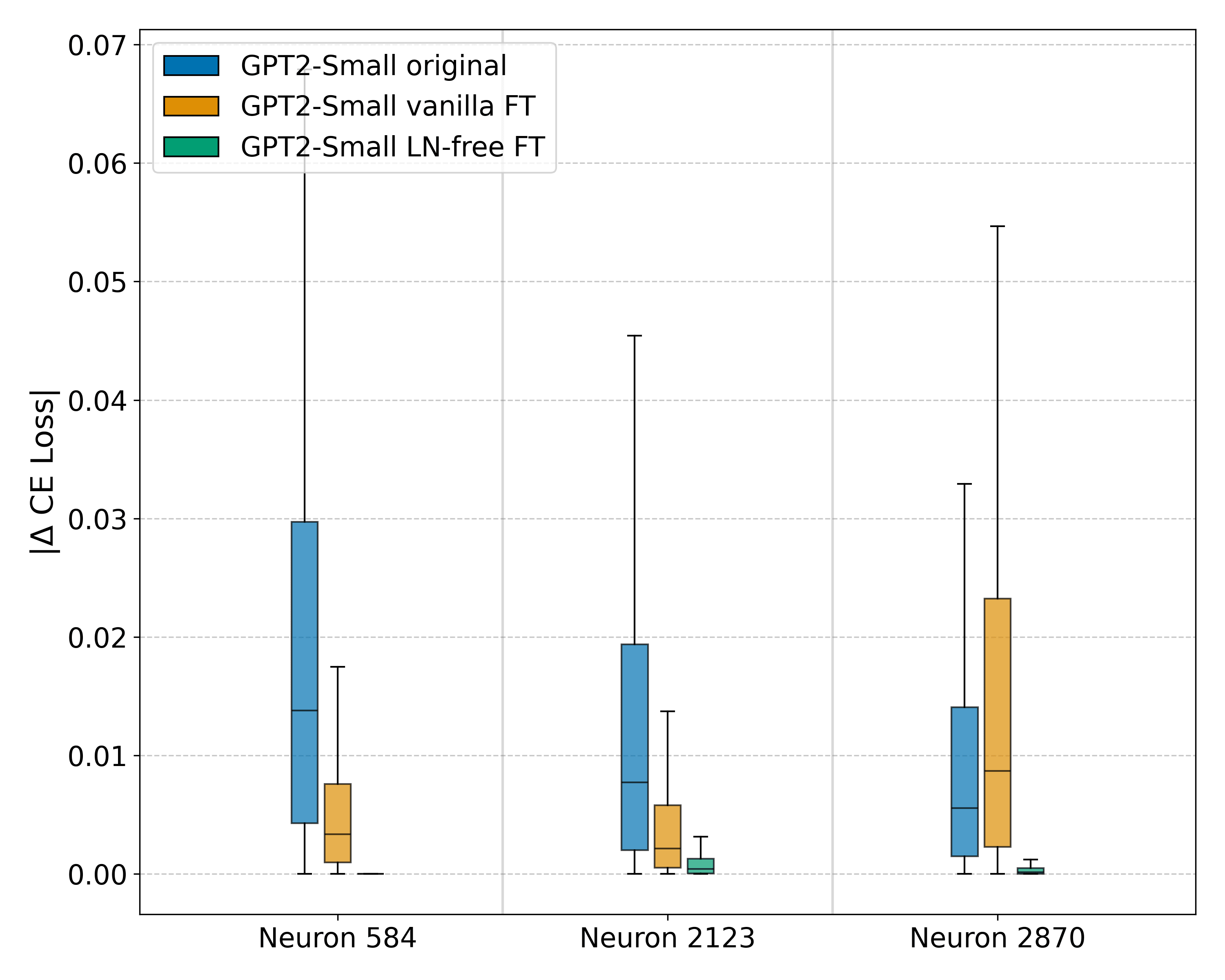
First Token Behavior
In standard transformers, the first tokens' hidden states are known to exhibit disproportionately high norm compared to the subsequent tokens. This behavior is linked to "attention sinks", where the first token captures a large portion of attention to regulate information flow and prevent representational collapse.
We confirm this in GPT-2 models with LN, observing an explosive first-token norm growth at specific attention layers (layer 2 in GPT-2 Small, 3 in GPT-2 Medium and 7 to 13 in GPT-2 XL). These norms decay rapidly towards their original values in the final transformer layers.
Removing LN eliminates this behavior. In our LN-free models, the norm of the first token remains consistent with all other tokens throughout the network. Despite this change in behavior, we observed only a limited drop in the attention sinks rate (from ~55% in GPT-2 Medium, to ~45% in its LN-free variant), suggesting that the models possess alternative, non-norm based, mechanisms to create a positional bias towards the first token.
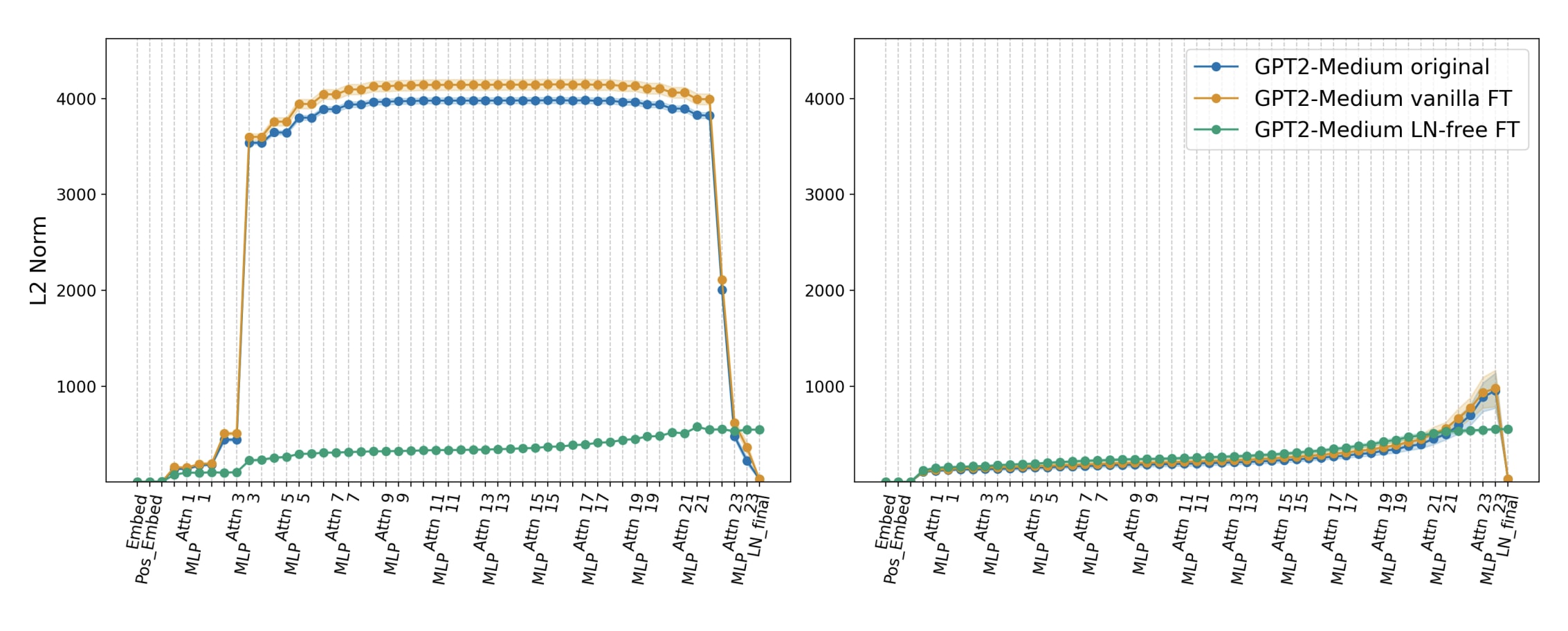
Note: While our auxiliary loss encourages norm consistency by explicitly penalizing variation across positions, we observed the same change to the first token norm even in experiments without this loss term.
Limitations
Training instability: Removal procedure is still unstable. Despite improvements like EMA recomputation and auxiliary loss, fine-tuning can still be unreliable and recovery from checkpoints has been quite useful. Hyperparameter tuning (learning rate), batch size is required for achieving the optimal balance of low loss and complete LN removal.
Data and compute: Although we have improved the efficiency of the removal schedule by roughly x4, it still requires ~1% of training data and compute for GPT-2 XL.
Performance gap: We found that there is a small, but consistent gap in LN-free models' performance. Additionally, we found that GPT-2 XL LN-free performs substantially worse on a tiny subset of examples in The Pile dataset; Lack of LN, disabled confidence neurons and the removal procedure itself could all contribute to this gap.
Discussion
Scaling laws
We did not gather enough data to be confident in empirical scaling laws but observe that data use scales sub-linearly with parameter count, whilst compute appears to scale exponentially. We noted that the removal schedule had headroom for optimization - we observed that and can be removed simultaneously in their respective blocks without spacing, but given that still required spacing in the schedule, the parameter count/compute relationship would remain the same.
Dealing with training instability
As mentioned, for larger models, as removal proceeded, training became increasingly unstable especially during removal of in Large and XL. The two types of instability that we observed were gradient explosion cascading over several steps and sudden failure in a single step. We believe that they were both caused by the network breaking because of a mismatch between the standard deviation that we were freezing with and the actual standard deviation. Learning rate tuning, larger batch size, EMA recomputation proved generally helpful. Spacing of removal events in the removal schedule helped during cascading explosions.
Recomputation approaches
We tried recomputing the average standard deviation using the immediate micro batch during the forward pass, but this caused instabilities for small batch sizes (necessitated by fine-tuning larger models). Presumably this happened when the average standard deviation was computed for some poorly shuffled micro batch and produced an unrepresentative average. In fact using larger batch sizes by optimizing memory utilization or using larger hardware often worked. We expect that distributed training would have also helped (we trained on 1 GPU). We attempted to simulate a large batch by maintaining a sliding window of standard deviations, but ultimately switching to exponential moving average fixed these problems.
Special treatment of first position
The original method had a bug where special treatment was not applied correctly to position-0. After fixing this we found that removal proceeded more smoothly. However, removal of special treatment at the end of the fine-tuning run almost always caused an irrecoverable spike in loss. Additionally, we continued to see the spontaneous breaking issue for large and XL.
Support for other model families
It should be relatively straightforward to support other model families. Forward passes should be monkey patched to allow for freezing , separately, and hyperparameters tuned for model size. We carried out these steps on Pythia models but the work was not completed due to time constraints. For larger models distributed training will need to be enabled. This is a major followup to our present work along with further scaling.
Conclusion
LN removal is feasible at larger scales than previously reported. We show that LN does not play a large role in language modeling. LN-Free models can be useful for interpretability tasks such as DLA, though other nonlinearities (attention, softmax, MLPs) remain major interpretability challenges. Perfect linear attribution doesn't solve all mechanistic interpretability problems. We release our models and code for immediate use by researchers and welcome extensions to other model families.
Reflections on MARS and SPAR
For all of us but Stefan, this is our first AI safety-relevant work. Both MARS and SPAR are part-time, remote programs. During my previous participation in SPAR my project basically went nowhere - I wasn't serious enough, our meetings meandered and participation was sparse. Having an in-person week in Cambridge for MARS, compute credits, motivated team, regular cadence of research meetings and a well-planned project provided the structure needed to get meaningful results. We thank Stefan for guiding us along the journey, pitching ideas and focusing effort in times when our collective attention was waning. We believe that these programs offer a valuable opportunity for testing fit, building skills and helping people transition into AI safety work.
Appendix A: Sample generations
Sample generations from model.generate:
GPT-2 XL
As the last leaf fell from the tree, John realized that he was the only person on the island who knew that he was not who he said he was. After a few seconds, Sam appeared. He informed the party that he had been looking at Sam's passport for two years now and had a hunch that John was on some kind of mission.
GPT-2 XL LN-free
As the last leaf fell from the tree, John realized that he was the last person on the island. Once the last of his “friends” were gone, he was the last human on Yik Yak. There was nothing else he could do. He did whatever he could to fill his short time here with as much meaning as he could. However, after a few minutes, John realized that there was nothing else he could do. Nothing.
Discuss
