
Published on July 22, 2025 9:13 PM GMT
There are a lot of AI Safety papers, essays, think pieces, discussions, all written in English. What if we used LLMs to translate them into every major language?
Here I lay out briefly why I think this could be a good idea, and then I attempt to have Claude do some mass translating for me, for better or worse.
Why do this
Quick look at the cost/benefit:
Cost
If an LLM can do this well, possibly this costs very little? A one person startup could presumably provide translation as a service, and cheaply make things like AI 2027, which are intended for mass consumption, natively multilingual from the start.
Benefit
It seems likely that other countries might also have an influence on the future! The European Union is passing major legislation on AI, the semiconductor supply chain is spread across the globe (with multiple non-Anglosphere choke points), and the UN can presumably at least kick up a fuss about things. It also seems plausible that as the AI race heats up, people in countries other than the US (or China) may be especially alarmed and upset by what’s going on, facing serious risks/harms that they had no part in creating.
So, how hard could it be?
A trial in translation
I had Claude Sonnet 4[1] translate the essay “Keep the Future Human” (decently long, lots of jargon) into the following languages: Mandarin(simplified[2]), Korean, Dutch, Japanese, Hebrew, Malay, French, Russian, German, Italian, Polish, Turkish, Spanish, Danish, Greek, Arabic, and Latvian.[3] I’m fluent in Dutch, and can kind of read Spanish, but that’s about it for me personally, so it felt like a big leap of faith. I did mess around a little bit with the COT prompts to improve the Dutch translation, with the hope that those improvements would generalize to the other languages as well.
Claude Code wrote me a basic pipeline where Claude Sonnet 4 would:
- Read the full essay[4] and write a short summary and glossary of terms.Translate the essay one chapter at a time, each time having access to the same summary and glossary.[5]
These translated chapters were then reassembled into one big document.
The A-G-I Framework
A core part of the essay is the A-G-I framework, which defines AGI as:
high Autonomy (independence of action), high Generality (broad scope and adaptability), and high Intelligence (competence at cognitive tasks)
This particular acronym, of course, does not often translate well into other languages. For example:
Dutch ❌ hoge Autonomie (onafhankelijkheid van handelen), hoge Algemene toepasbaarheid (brede reikwijdte en aanpassingsvermogen), en hoge Intelligentie (competentie bij cognitieve taken)
French ✅ haute Autonomie (indépendance d'action), haute Généralité (portée large et adaptabilité), et haute Intelligence (compétence aux tâches cognitives)
Polish ❌ wysokiej Autonomii (niezależności działania), wysokiej Ogólności (szerokiego zakresu i adaptowalności) oraz wysokiej Inteligencji (kompetencji w zadaniach poznawczych
Mandarin ⁉️ 高度自主性(行动独立性)、高度通用性(广泛范围和适应性),以及高度智能(认知任务能力)
Generally, Claude chose to keep the acronym AGI without translating it, arguing that in most languages this has become a commonly understood term already. However, in the case where the author breaks down the acronym and redefines it from Artificial General Intelligence to Autonomous General Intelligence, there are actually some tricky choices to make about how to go about adapting what is essentially English wordplay. I’m not really sure how to robustly fix this kind of thing.
I also tried translating the corresponding diagram into Dutch, which had mixed success:
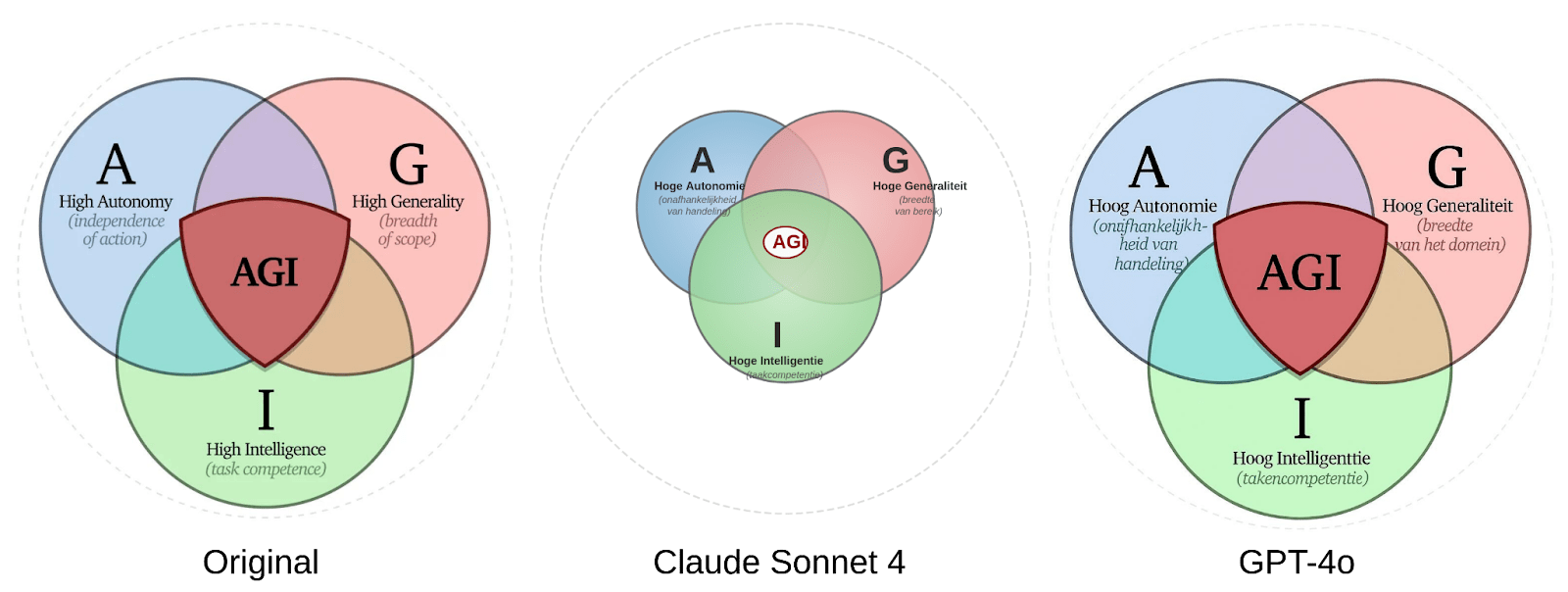
Claude Sonnet 4 decided to make an SVG, which led to more accurate text, but the placement was pretty wonky. GPT-4o generated an image, which looks really great at first glance, but has a few spelling and grammar mistakes. Both of them chose to force “Generality” to “Generaliteit”, which is pretty unnatural, but it does keep the G! I decided to ditch translating the diagrams, and left in the original English version.
Translating “alignment”
Claude was instructed to make a glossary of important terms and jargon, with their corresponding translations. Looking specifically at the word “alignment”, it usually matched the word used in that language’s Wikipedia entry for AI Alignment (if there was one). An exception was Polish which translated “alignment” to “wyrównanie”, which GPT-4o translated as:
Wyrównanie refers to the act of making things equal, level, or aligned. In physical contexts, it can mean leveling a surface (e.g., terrain or floor). In math or accounting, it can refer to balancing or settling (e.g., wyrównanie rachunków = settling accounts). In social or political discourse, it can imply striving for equality or fairness—e.g., wyrównanie szans = equal opportunity—often with a positive connotation of justice or fairness. It may also be used metaphorically to suggest bringing things into harmony or balance, such as workload, rights, or outcomes. The word does not inherently imply forceful or abrupt correction, but rather a systematic or intended adjustment toward balance.
That seems wrong.[6] For Russian, Claude also went with a similar cognate “выравнивание” (likewise more about leveling/equalizing) despite the Wikipedia entry using “cогласование”. This word (as well as the Latvian cognate, “saskaņošana”, which Claude chose) appears to mean something closer to “coordination” than “alignment”, but it’s hard for me to tell.
Dutch, Hebrew, Malay[7], Italian, Turkish, Danish, Greek, and Latvian did not have Wikipedia entries. For Dutch and German, Claude just used the English term “alignment”, and for Danish it seemed to switch back and forth between “alignment” and a Danish term. All of the other languages seem to have mostly gone with fairly reasonable translations (as far as I can tell!).
A human curated glossary of terms might make this sort of thing a lot better. While requiring some initial investment of time and effort, the same glossary could be used widely across contexts.
Some qualitative comments
I asked friends to look over their respective translations, and they commented:
Polish:
It's overall pretty good. It translated the parts about gates weirdly: "closing the gated before AGI", and later "closing the gates for AGI". It should be "to AGI" but it didn't understand the context I think. Also translating AGI into A-O-I was weird - it should somehow relate it to the English acronym.
But apart from occasional awkward things like this, it's quite readable.
French:
It is OK
Content is here, but it is not really pleasant to read. It is a bit "souless"
In a blind test, I would pbly be able to see it has been AI translated
Greek:
Ok so the literal translation is accurate, but it just doesn’t sound like how a greek person would write
Like it translates idioms or ways of expression word for word, without accounting for the fact that a Greek person wouldn’t talk like that
Looking over the Dutch translation, my assessment is similar. It’s fine, but clunky and not that nice to read, making some weird choices here and there. Claude seems to have erred on the side of being overly literal, sacrificing natural flow to stick closely to the English wording. I tried to fix that with better prompting, but I didn’t try very hard, and I don’t see why this couldn’t be improved a lot.
I hope the other languages worked out, maybe some of them are radically worse (let me know!).
Token inequality
Several languages had parts of the translations cut off. Upon closer inspection I noticed that some languages require a lot more tokens, and this led the API to hit the limit I had set of about 16k output tokens per chapter.[8] This is easily fixable, though I wonder what implications the differing amount of tokens has on translation quality.[9]
Below is each language, with the total number of tokens in Chapter 1:
- English: 1,051 (original)Spanish: 1,464Danish: 1,490Dutch: 1,516Italian: 1,540Mandarin: 1,541French: 1,601Polish: 1,707German: 1,730Malay: 1,792Russian: 1,872Japanese: 1,874Turkish: 1,924Latvian: 1,980Hebrew: 2,278Korean: 2,352Arabic: 2,541Greek: 3,309
Cost
I spent roughly 45 dollars in compute credits (Claude Sonnet 4 is a bit pricey). This includes the cost of vibecoding.
Conclusion
Hard to say how that went! I had GPT-4o critique each of the translations, and it always had something to constructive to say, but assuaged me (perhaps sycophantically) that they were mostly fine. My overall feeling is that passably accurate translation of large volumes of text is probably achievable using better COT, prompting, and human curated glossaries (at least for some languages).
However, translating text so that the translation is itself good writing is a whole other problem, and that seems much farther off. This seems like the sort of thing LLMs should be good at, and perhaps with much better prompting you could get writing which is much more at home in the target language, and is genuinely enjoyable to read.
I could imagine translating some other writing that doesn’t necessarily need to hit as high a “style” bar:
- Short form commentary (e.g. Reddit threads, or LW’s quick takes section)Chat conversations (live!)Survey questions (and answers)Breaking news
I’ve put the results of my experiment up on Github, as well as all the code that I used Claude used. If you can read one of the languages I tried, please let me know how it went!
P.S. I let Claude write my last commit message, and Claude added itself as a contributor!

- ^
I realize this might be a bit overpowered, but since I was jumping blind into languages I didn’t know, I figured I’d better play it safe.
- ^
China uses simplified characters, while Taiwan uses traditional Chinese characters. Apparently translating from traditional to simplified can be done with a simple mapping table, but the other direction requires the context to resolve ambiguities.
- ^
Chosen very roughly for either having a significant role in the semiconductor supply chain according to a GPT-4o generated summary of this report, being on the 2026 UN Security Council, or being in the top 10 NATO countries by military spending.
- ^
I decided to use Obsidian Web Clipper to scrape the website, and do everything in Markdown for simplicity.
- ^
Maybe I should have just tried it without chucking (I think the context window was large enough). On the other hand, this could be a useful datapoint for much longer pieces of text that have to be chunked.
- ^
My Polish speaking friend explained that “alignment” is notoriously hard to translate into Polish. Polish EA Slack had a big debate about it, settling on “dostosowywanie” which translates roughly to “the process of making something suitable or appropriate for a specific purpose, condition, or need”. This was Claude’s second choice, including it in the glossary, but it never actually used it in the final translation. In a government document about alignment, they also used “wychowywanie”, or “the long-term process of shaping a person’s behavior, character, values, and social functioning—primarily through upbringing and education”, which is also an interesting choice. The Wikipedia entry used “zgodność” which translates to “compliance or consistency”.
- ^
While Malay did not have a Wikipedia entry, Indonesian did, which seems to have translated the title “AI Alignment” to “AI Control Problem”, which is the term used more commonly before “alignment” became popular (The Russian and Arabic articles did something similar). In the article, however, they use the term “penyelarasan” for “alignment” rather than what Claude selected, which was “penjajaran”. It seems that Claude’s choice might be overly literal, referring more to physical/spatial alignment, but I’m not sure, and though Malay and Indonesian are very similar it could just be a difference in connotation between the languages.
- ^
This was roughly the highest I could go before Anthropic wanted me to stream the data, which I couldn’t be bothered to do.
- ^
Probably token efficiency correlates strongly with how much of that language was in the pretraining data, though the data used for training the tokenizer is often different.
Discuss
