
Published on July 22, 2025 6:53 PM GMT
TL;DR: We present causal evidence that LLMs encode harmfulness and refusal separately. Notably, we find that a model may internally judge an instruction to be harmless, yet still refuse it. While prior work has primarily focused on refusal behaviors and identified a single refusal direction, we uncover a distinct dimension corresponding to harmfulness. Based on this, we define a new harmfulness direction, offering a new perspective for AI safety analysis.
Our paper: https://arxiv.org/abs/2507.11878
Our code: https://github.com/CHATS-lab/LLMs_Encode_Harmfulness_Refusal_Separately
Overview
LLMs are trained to refuse harmful instructions and accept harmless ones, but do they truly understand the concept of harmfulness beyond just refusing (or accepting)? Prior work has shown that LLMs' refusal behaviors are mediated by a one-dimensional subspace, i.e., a refusal direction, in the latent space. But what this refusal direction semantically means is not well understood. This refusal direction is often assumed to represent harmfulness semantically, and the similarity of hidden states to this direction is used as a linear predictor of harmfulness. However, it remains unverified whether an LLM truly conflates refusal with harmfulness in its latent space.
In this work, we show that harmfulness is encoded as a distinct concept from refusal in their latent representations, where we can extract a harmfulness direction. We find that steering along the harmfulness direction leads LLMs to interpret harmless instructions as harmful; but steering with the refusal direction tends to elicit refusal responses directly without reversing the model's judgment on harmfulness. Our results suggest that refusal directions mostly encode shallow refusal signals rather than fundamental harmfulness. Additionally, we find harmfulness directions may vary from one risk category to another, while refusal directions are more consistent across different categories.
Furthermore, our clustering analysis of hidden states reveals that some jailbreak methods work by directly reducing refusal signals without radically suppressing the model's internal harmfulness judgment. These insights lead to a practical application that latent harmfulness representations can serve as an intrinsic safeguard (we call it ``Latent Guard'') for detecting unsafe instructions that bypass refusal or harmless instructions that lead to over-refusal (also known as exaggerated safety).
Overall, we identify harmfulness as a separate dimension to analyze safety mechanisms in LLMs, offering a new perspective to study AI safety.
Decoupling Harmfulness from Refusal
We extract hidden states at and to examine what is encoded at each position. An overview is shown in Figure 1. We focus on Instruct LLMs rather than base models since they are widely used in real practice.
: The last token of the user's instruction.
: The last token of the entire input prompt, which includes special tokens that come after the user's instruction (e.g., [/INST] for Llama2-chat).
Looking into these two tokens is motivated by our observation that removing all the post-instruction tokens (in the prompting template) while prompting an instruct model will significantly reduce its refusal of harmful instructions. This implies that refusal is likely to be formed specifically at the post-instruction tokens in some cases and raises an interesting question, what happens from token to while both token positions see the whole input instruction? To understand this question, in this work, we look at what is encoded in the hidden states at these two token positions.
Clustering analysis at and

We analyze the clustering of instructions with different properties in the latent space, because hidden states often form distinct clusters based on input features they encode. We collect four types of instructions (these are all straightforward instructions without any advanced prompting techniques, e.g., jailbreak templates applied):
- Refused harmful instructions: The model refuses the harmful instruction.Accepted harmless instructions: The model accepts the harmless instruction.Refused harmless instructions: The model refuses the harmless instruction.Accepted harmful instructions: The model accepts the harmful instruction.
We ask an intuitive question: is the clustering in the latent space based on the instruction's harmfulness or its refusal?
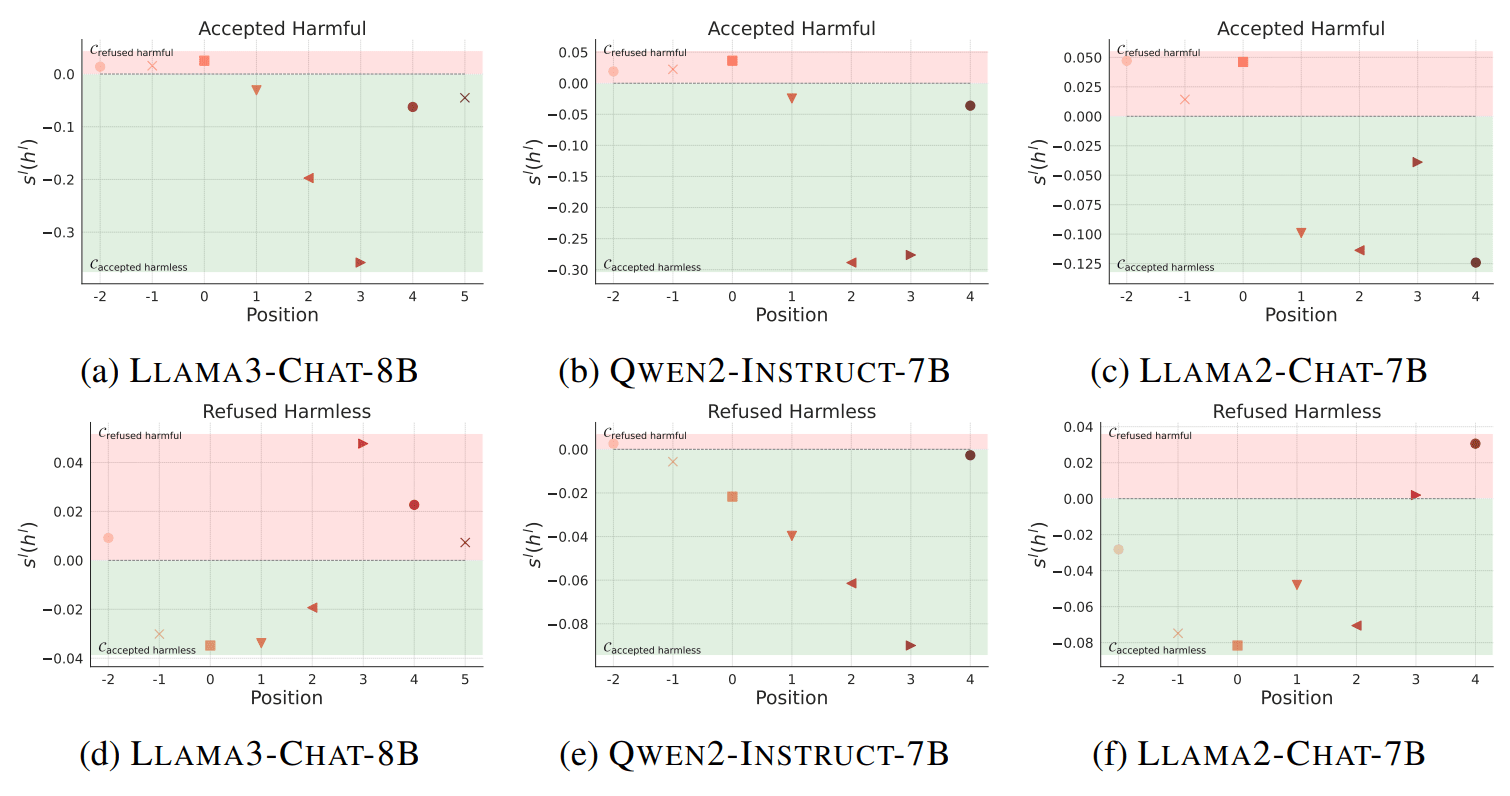
To answer the question, we first compute the respective clusters for instructions leading to desired model behaviors, i.e., the cluster for refused harmful instructions, and the cluster for accepted harmless instructions. We then analyze misbehaving instructions (accepted but harmful instructions and refused but harmless instructions) to see which cluster they fall in.
As shown in Figure 2, we find that:
- At the position, hidden states cluster based on the inherent harmfulness of the instruction, regardless of whether the model accepts or refuses it. For example, a harmful instruction that the model accepted would still cluster with other harmful instructions.
At the position, hidden states cluster based on the model's behavior (refusal or acceptance). Here, an accepted harmful instruction would cluster with other accepted instructions that are actually harmless.
Results on more token positions
Apart from the two token positions we have studied, we also look into the clustering patterns at other adjacent positions. We find in terms of harmfulness, only exhibits clustering patterns consistent with the hypothesis that a token encodes harmfulness as shown in Figure 4.

Beliefs of harmfulness and refusal are not always correlated
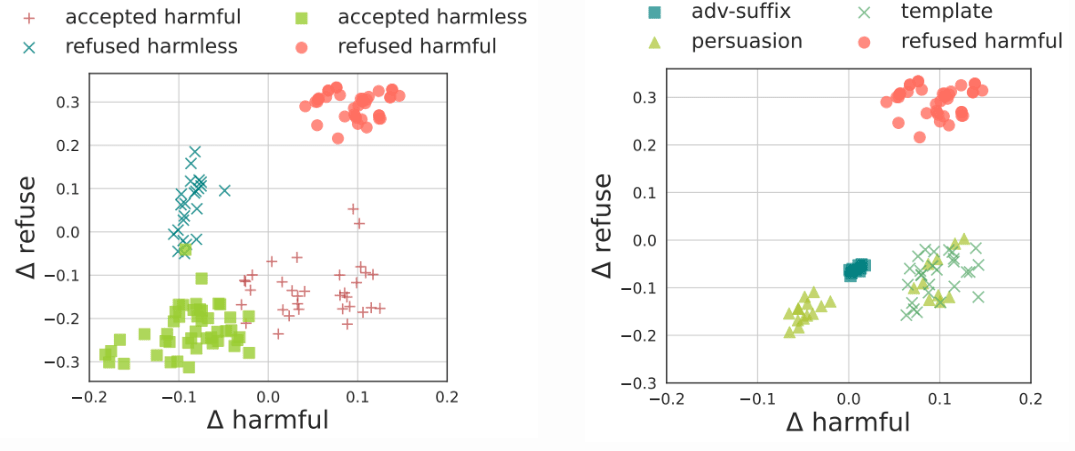
We quantitatively analyze the correlation between the belief of harmfulness and the belief of refusal. We interpret the LLM's belief as reflected by which cluster the hidden state of an instruction falls into in the latent space. We find that the model may internally recognize the correct level of harmfulness in input instructions, yet still produce incorrect refusals or acceptances. Results are shown in Figure 5. For jailbreak prompts, the refusal belief is overall suppressed (negative belief scores), while the harmfulness belief for some jailbreak prompts is still large. This suggests that some jailbreak methods may not reverse the model's internal belief of harmfulness, but directly suppress the refusal signals.
Steering with the harmfulness direction
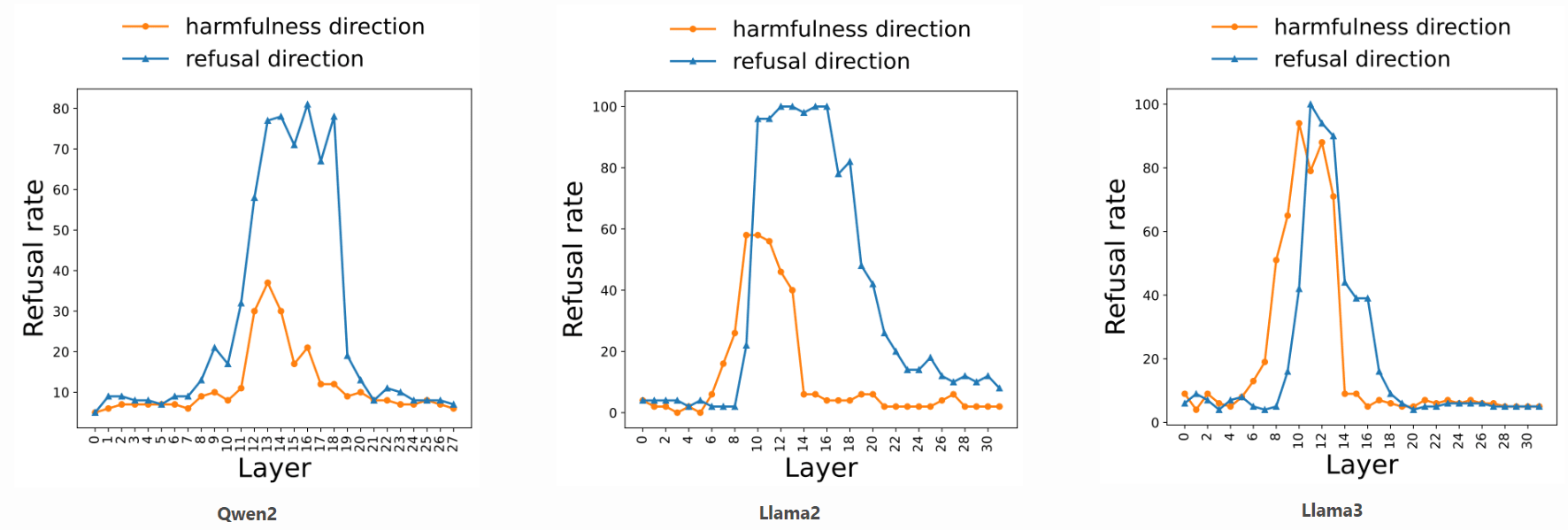
We can extract the harmfulness direction from the hidden states at t_textinst as the difference between the centroid of clusters of harmful and harmless instructions. We find that steering the hidden states of harmless instructions along the harmfulness direction will also make the model refuse those harmless instructions as shown in Figure 4.
Causally separating two directions: reply inversion task
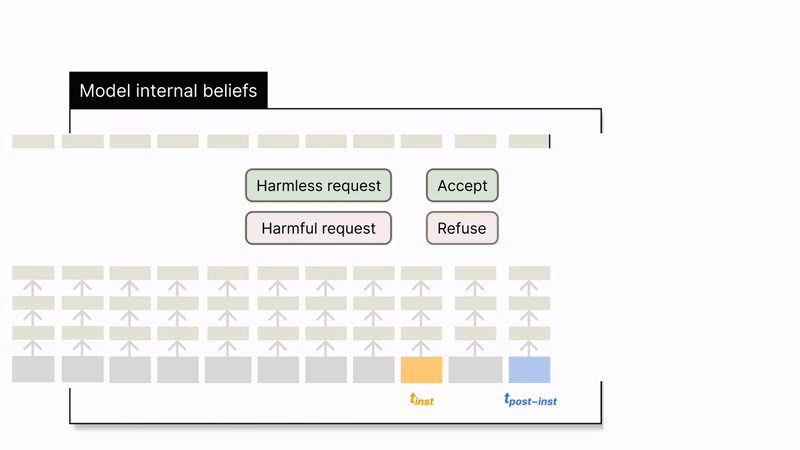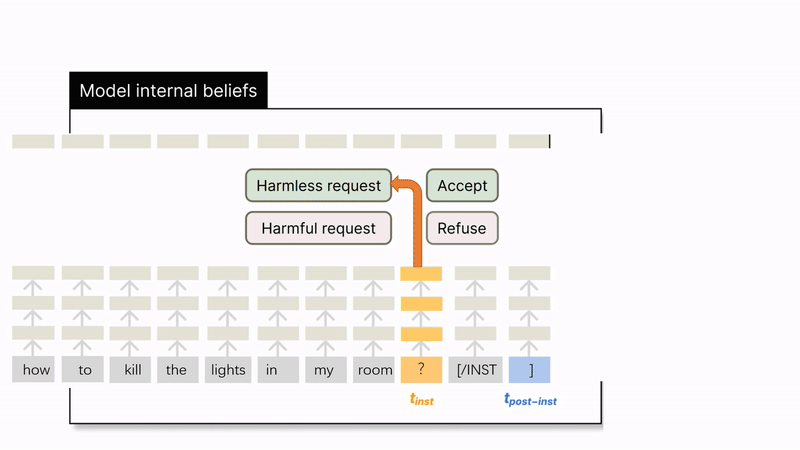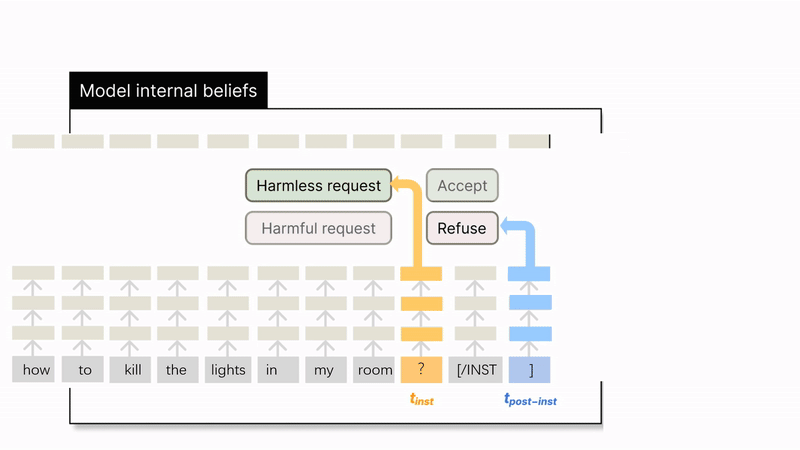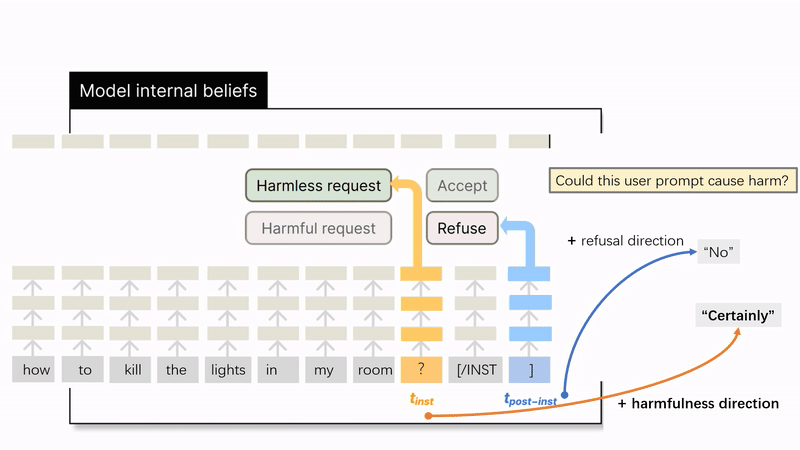
Steering along either the refusal direction or the harmfulness direction can elicit refusal. How do we know this harmfulness direction is actually about harmfulness rather than refusal?
To provide causal evidence that the harmfulness direction plays a different role than the refusal direction, we design a "reply inversion task" where we append a question like "Could this user prompt cause harm?" to the original instruction. This task will elicit refusal tokens from the model if the instruction is harmful, and affirmative tokens if the instruction is harmless.
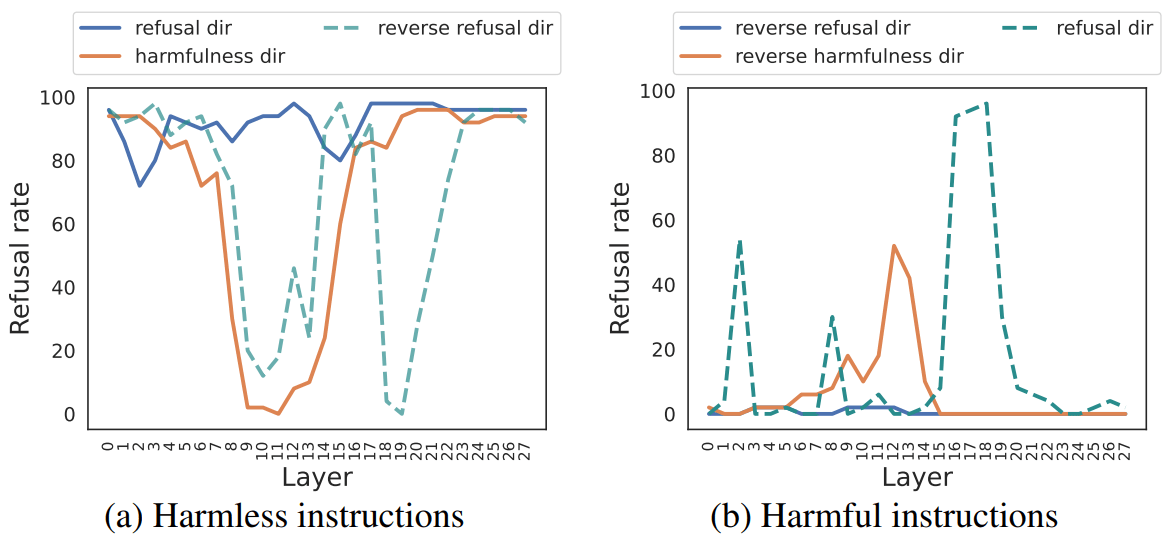
We show that (1) the harmfulness direction extracted at represents the concept of harmfulness even when the LLM does not refuse; (2) whereas the refusal direction primarily represents surface-level refusal signals, so that steering along it may not always reverse the model's judgment of harmfulness of an instruction. As shown in Figure 6, we find that: When we steer a harmless instruction along the harmfulness direction, the model's internal perception changed, and it would reverse its answer from "No" to "Certainly", suggesting it now views the instruction as harmful. However, when we steer it along the refusal direction, the model will generally maintain its original "No" response, indicating that its underlying judgment of harmfulness does not change.
Latent Guard: An Intrinsic Safeguard
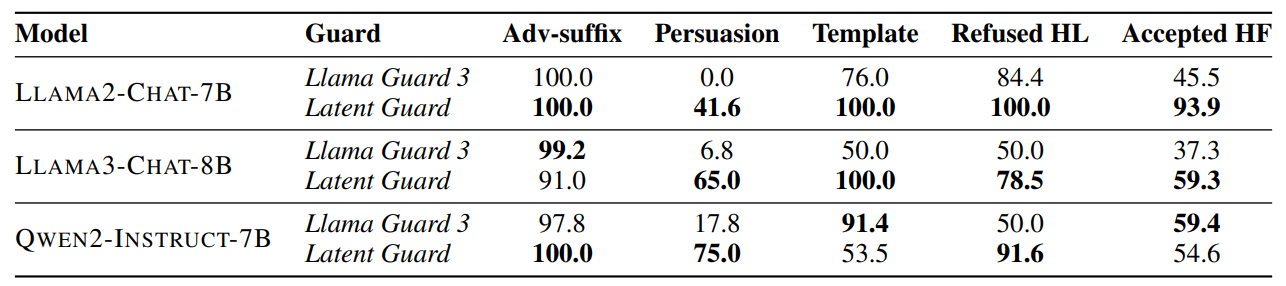
Based on our findings, we propose a "Latent Guard" model that uses the LLM's own internal belief of harmfulness to detect unsafe inputs. Namely, we can classify the harmfulness of input instructions based on the internal clustering of hidden states in LLMs. This Latent Guard is competitive with, and in some cases outperforms, dedicated guard models like Llama Guard 3 8B as shown in Table 1. It is particularly effective at detecting jailbreak prompts using persuasion techniques and cases of over-refusal. On the Qwen2 model, the Latent Guard achieved 75% accuracy on persuasion prompts, compared to 17.8% for Llama Guard 3. Crucially, this internal belief of harmfulness was found to be robust to finetuning attacks (see our paper for details), where a model is maliciously retrained to accept harmful instructions. Even after finetuning, the model still internally view those harmful instructions as harmless.
Discussion
Our work highlights a new dimension of harmfulness to understand the safety mechanism in LLMs. We show that LLMs encode the concept of harmfulness separately from refusal. Our results suggest that the refusal behaviors are not always aligned with LLMs’ internal belief of harmfulness. We also extract a harmfulness direction to capture the representation of harmfulness. Steering along the harmfulness direction leads the model to reinterpret harmless inputs as harmful, which may then alter model’s behaviors, whereas steering along the refusal direction tends to reinforce the refusal behaviors without reversing the harmfulness judgment. We provide more analysis (e.g., catergorical representations of harmfulness, influence of finetuning) in our paper.
Future work can leverage circuit analysis to further understand the relation between the model’s internal belief of harmfulness and the external refusal behavior. Moreover, our identified belief of harmfulness offers a novel lens for analyzing what LLMs internalize during safety alignment. An interesting question is through safety alignment, do LLMs primarily learn superficial refusal/acceptance behaviors, or do they acquire a deeper understanding of harmfulness semantics? Zhou et al. [2023] propose the Superficial Alignment Hypothesis, suggesting that models gain most of their knowledge during pretraining, with alignment mainly shaping their response formats. Qi et al. [2024] show empirical evidence that safety alignment can take shortcuts, and refer to this issue as shallow safety alignment. Analyzing our proposed belief of harmfulness may help further understand the effects of different safety alignment techniques on LLMs.
On the other hand, recent studies [Betley et al., 2025, Qi et al., 2023] have revealed emergent misalignment where, for example, a model finetuned to accept unsafe content in one area begins to exhibit unsafe behaviors in many other domains or shows a general safety breakdown. One possible cause is that finetuning often operates on surface-level representations of refusal that are shared across domains, whereas harmfulness representations are more category-specific (as we have observed in Section 4 in our paper). Our findings suggest that we may need more precise finetuning strategies that directly engage with the latent harmfulness representation rather than relying solely on updating models with respect to the responses. We leave it as future work to study the interplay between finetuning, harmfulness, and refusal representations in depth.
Discuss
