
Free NoSQL Training – and a Book by Discord Engineer Bo Ingram (Sponsored)
Get practical experience with the strategies used at Discord, Disney, Zillow, Tripadvisor & other gamechangers
July 30, 2025

Whether you’re just getting started with NoSQL or looking to optimize your NoSQL performance, this event is a fast way to learn more and get your questions answered by experts.
You can choose from two tracks:
Essentials: NoSQL vs SQL architectures, data modeling fundamentals, and building a sample high-performance application with ScyllaDB.
Advanced: Deep dives into application development practices, advanced data modeling, optimizing your database topology, monitoring for performance, and more.
This is live instructor-led training, so bring your toughest questions. You can interact with speakers and connect with fellow attendees throughout the event.
Bonus: Registrants get the ScyllaDB in Action ebook by Discord Staff Engineer Bo Ingram.
Disclaimer: The details in this post have been derived from the articles shared online by the Nubank Engineering Team. All credit for the technical details goes to the Nubank Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Understanding customer behavior at scale is one of the core challenges facing modern financial institutions. With millions of users generating billions of transactions, the ability to interpret and act on this data is critical for offering relevant products, detecting fraud, assessing risk, and improving user experience.
Historically, the financial industry has relied on traditional machine learning techniques built around tabular data. In these systems, raw transaction data is manually transformed into structured features (such as income levels, spending categories, or transaction counts) that serve as inputs to predictive models.
While this approach has been effective, it suffers from two major limitations:
Manual feature engineering is time-intensive and brittle, often requiring domain expertise and extensive trial-and-error.
Generalization is limited. Features designed for one task (for example, credit scoring) may not be useful for others (for example, recommendation or fraud detection), leading to duplicated effort across teams.
To address these constraints, Nubank adopted a foundation model-based approach, which has already been transforming domains like natural language processing and computer vision. Instead of relying on hand-crafted features, foundation models are trained directly on raw transaction data using self-supervised learning. This allows them to automatically learn general-purpose embeddings that represent user behavior in a compact and expressive form.
The objective is ambitious: to process trillions of transactions and extract universal user representations that can power a wide range of downstream tasks such as credit modeling, personalization, anomaly detection, and more. By doing so, Nubank aims to unify its modeling efforts, reduce repetitive feature work, and improve predictive performance across the board.
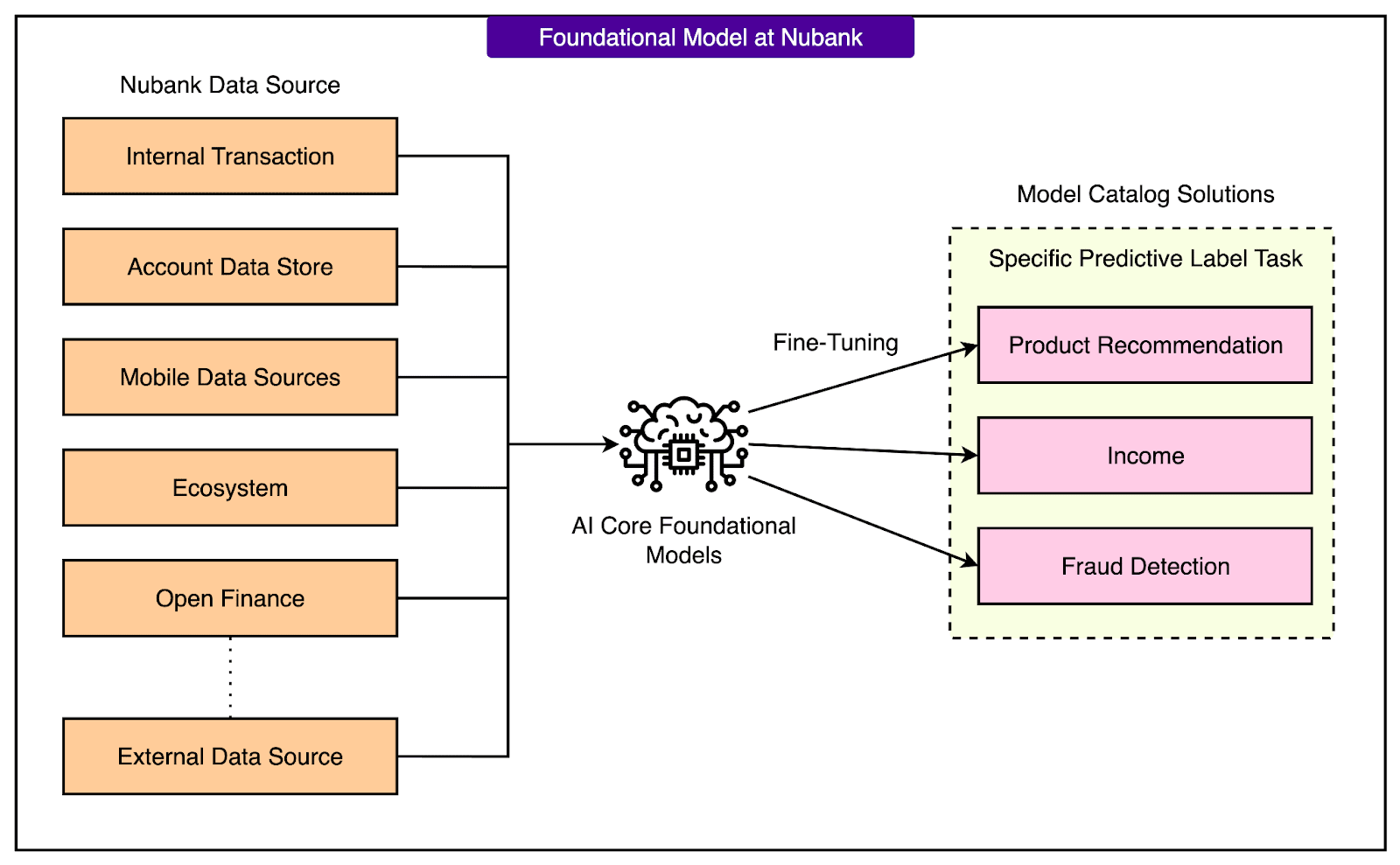
In this article, we look at Nubank’s system design for building and deploying these foundation models. We will trace the complete lifecycle from data representation and model architecture to pretraining, fine-tuning, and integration with traditional tabular systems.
Overall Architecture of Nubank’s System
Nubank’s foundation model system is designed to handle massive volumes of financial data and extract general-purpose user representations from it. These representations, also known as embeddings, are later used across many business applications such as credit scoring, product recommendation, and fraud detection.
The architecture is built around a transformer-based foundation model and is structured into several key stages, each with a specific purpose.
1 - Transaction Ingestion
The system starts by collecting raw transaction data for each customer. This includes information like the transaction amount, timestamp, and merchant description. The volume is enormous, covering trillions of transactions across more than 100 million users.
Each user has a time-ordered sequence of transactions, which is essential for modeling spending behavior over time. In addition to transactions, other user interaction data, such as app events, can also be included.
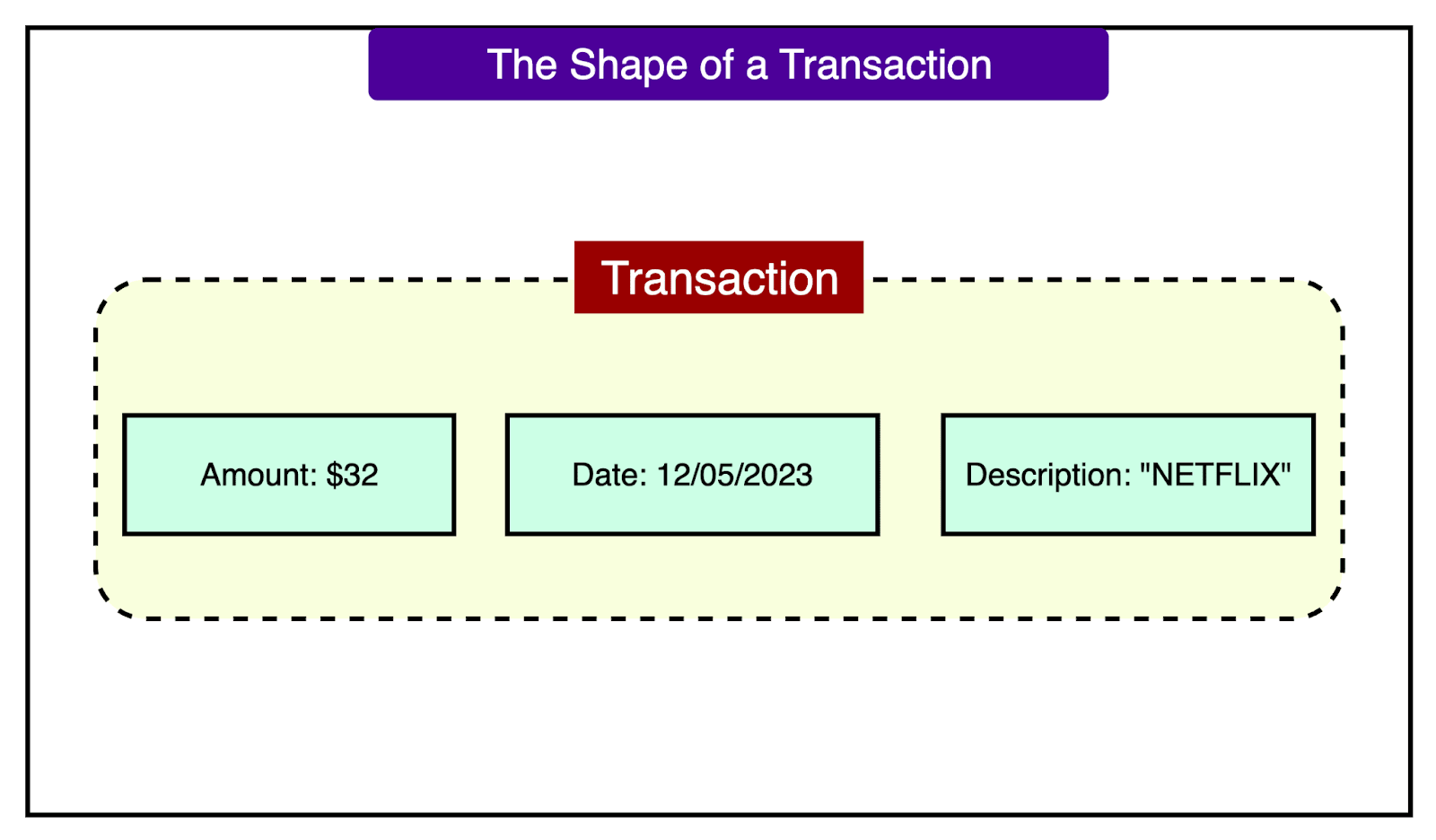
2 - Embedding Interface
Before transactions can be fed into a transformer model, they need to be converted into a format the model can understand. This is done through a specialized encoding strategy. Rather than converting entire transactions into text, Nubank uses a hybrid method that treats each transaction as a structured sequence of tokens.
Each transaction is broken into smaller elements:
Amount Sign (positive or negative) is represented as a categorical token.
Amount Bucket is a quantized version of the transaction amount (to reduce numeric variance).
Date tokens such as month, weekday, and day of month are also included.
Merchant Description is tokenized using standard text tokenizers like Byte Pair Encoding.
See the diagram below:
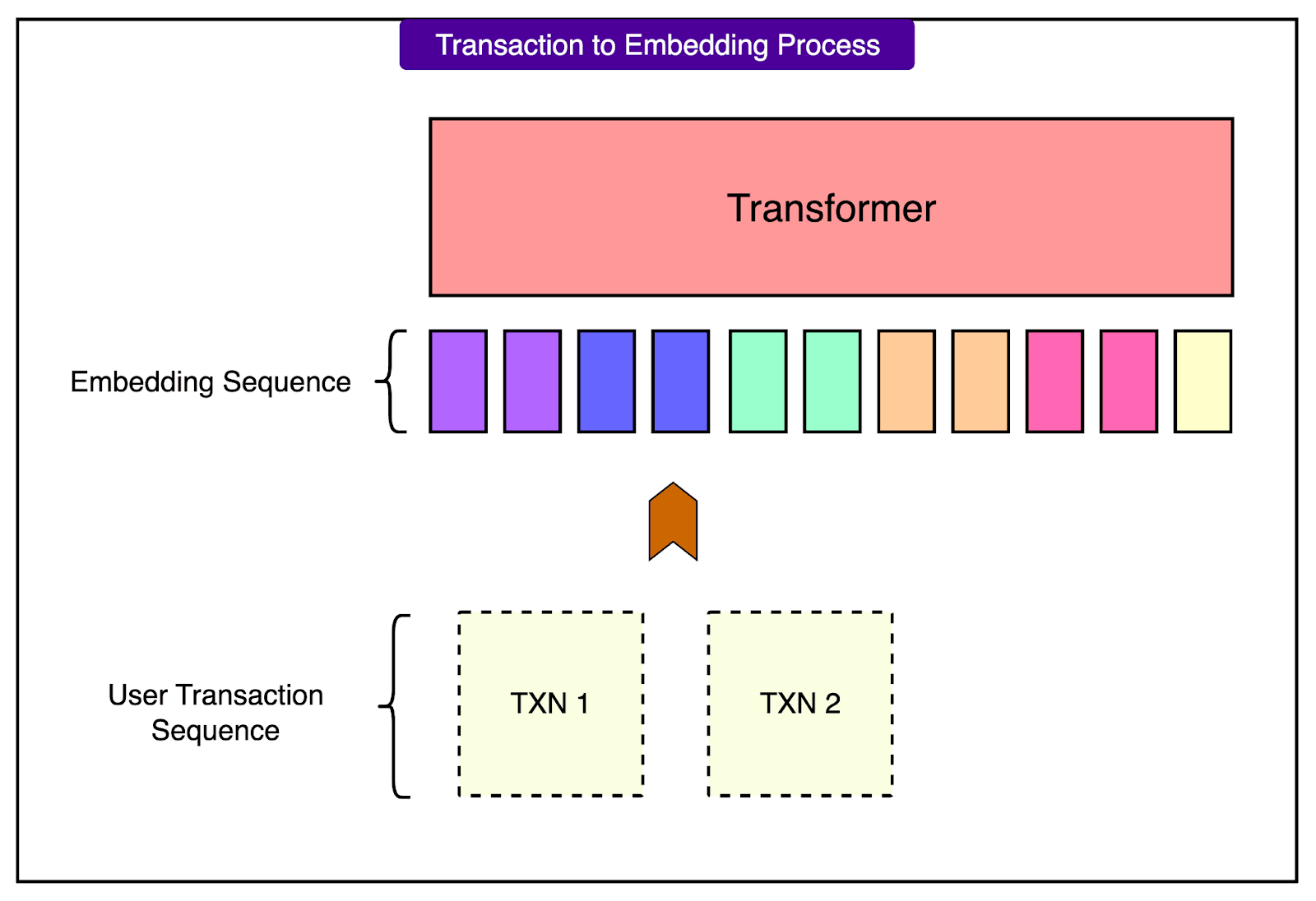
This tokenized sequence preserves both the structure and semantics of the original data, and it keeps the input length compact, which is important because attention computation in transformers scales with the square of the input length.
3 - Transformer Backbone
Once transactions are tokenized, they are passed into a transformer model. Nubank uses several transformer variants for experimentation and performance optimization.
The models are trained using self-supervised learning, which means they do not require labeled data. Instead, they are trained to solve tasks like:
Masked Language Modeling (MLM), where parts of the transaction sequence are hidden and the model must predict them.
Next Token Prediction (NTP), where the model learns to predict the next transaction in the sequence.
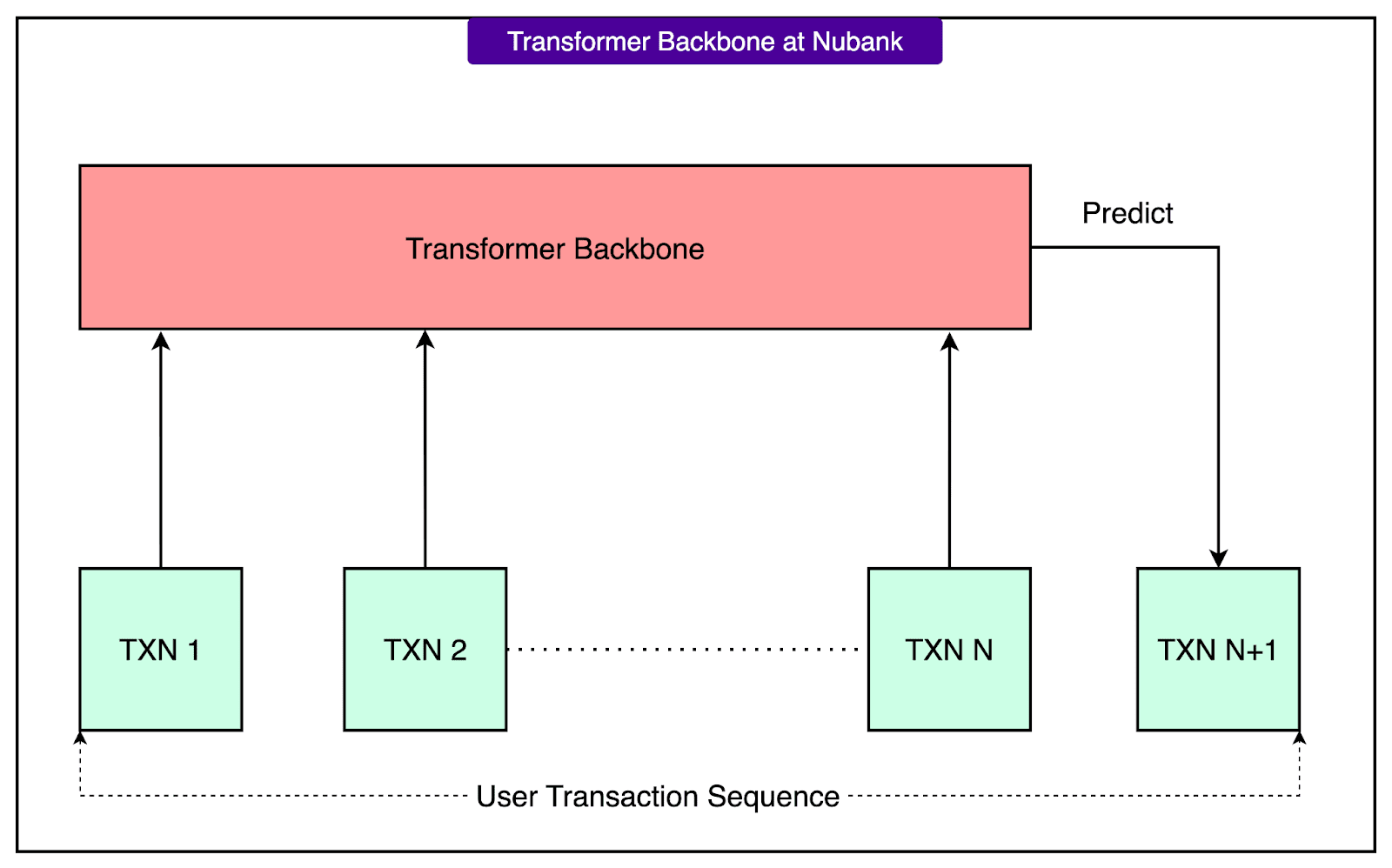
More on these in later sections. The output of the transformer is a fixed-length user embedding, usually taken from the final token's hidden state.
4 - Self-Supervised Training
The model is trained on large-scale, unlabeled transaction data using self-supervised learning objectives. Since no manual labeling is required, the system can leverage the full transaction history for each user. The models learn useful patterns about financial behavior, such as spending cycles, recurring payments, and anomalies, by simply trying to predict missing or future parts of a user’s transaction sequence. As a simplified example, the model might see “Coffee, then Lunch, then…”. It tries to guess “Dinner”.
The size of the training data and model parameters plays a key role. As the model scales in size and the context window increases, performance improves significantly. By constantly guessing and correcting itself across billions of transactions, the model starts to notice patterns in how people spend money.
For instance, switching from a basic MLM model to a large causal transformer with optimized attention layers resulted in a performance gain of over 7 percentage points in downstream tasks.
5 - Downstream Fine-Tuning and Fusion
After the foundation model is pre-trained, it can be fine-tuned for specific tasks. This involves adding a prediction head on top of the transformer and training it with labeled data. For example, a credit default prediction task would use known labels (whether a customer defaulted) to fine-tune the model.
To integrate with existing systems, the user embedding is combined with manually engineered tabular features. This fusion is done in two ways:
Late Fusion uses models like LightGBM to combine embeddings and tabular data, but the two are trained separately.
Joint Fusion trains the transformer and the tabular model together in an end-to-end fashion using a deep neural network, specifically the DCNv2 architecture.
More on these in a later section.
6 - Centralized Model Repository
To make this architecture usable across the company, Nubank has built a centralized AI platform.
This platform stores pretrained foundation models and provides standardized pipelines for fine-tuning them. Internal teams can access these models, combine them with their features, and deploy fine-tuned versions for their specific use cases without needing to retrain everything from scratch.
This centralization accelerates development, reduces redundancy, and ensures that all teams benefit from improvements made to the core models.
Transforming Transactions into Model-Ready Sequences
To train foundation models on transaction data, it is critical to convert each transaction into a format that transformer models can process.
There are two main challenges when trying to represent transactions for use in transformer models:
Mixed data types: A single transaction includes structured fields (like amount and date) and textual fields (like the merchant name). This makes it harder to represent consistently using either a pure text or a pure structured approach.
High cardinality and cold-start issues: Transactions can be extremely diverse. Even simple changes like different merchant names, locations, or amounts result in new combinations. If each unique transaction is treated as an individual token, the number of tokens becomes enormous. This leads to two problems:
The embedding table grows too large to train efficiently.
The model cannot generalize to new or rare transactions it has not seen before, which is known as the cold-start problem.
To address these challenges, multiple strategies were explored for turning a transaction into a sequence of tokens that a transformer can understand.
Approach 1: ID-Based Representation (from Recommender Systems)
In this method, each unique transaction is assigned a numerical ID, similar to techniques used in sequential recommendation models. These IDs are then converted into embeddings using a lookup table.
While this approach is simple and efficient in terms of token length, it has two major weaknesses:
The total number of unique transaction combinations is extremely large, making the ID space impractical to manage.
If a transaction was not seen during training, the model cannot process it effectively. This makes it poorly suited for generalization and fails under cold-start conditions.
Approach 2: Text-Is-All-You-Need
This method treats each transaction as a piece of natural language text. The transaction fields are converted into strings by joining the attribute name and its value, such as "description=NETFLIX amount=32.40 date=2023-05-12", and then tokenized using a standard NLP tokenizer.
This representation can handle arbitrary transaction formats and unseen data, which makes it highly generalizable.
However, it comes at a high computational cost.
Transformers process data using self-attention, and the computational cost of attention increases with the square of the input length. Turning structured fields into long text sequences causes unnecessary token inflation, making training slower and less scalable.
Approach 3: Hybrid Encoding Scheme (Chosen by Nubank)
To balance generalization and efficiency, Nubank developed a hybrid encoding strategy that preserves the structure of each transaction without converting everything into full text.
Each transaction is tokenized into a compact set of discrete fields:
Amount Sign Token: One token represents whether the transaction is positive (like a deposit) or negative (like a purchase).
Amount Bucket Token: The absolute value of the amount is placed into a quantized bucket, and each bucket is assigned its token. This reduces the range of numeric values into manageable categories.
Date Tokens: Separate tokens are used for the month, day of the month, and weekday of the transaction.
Description Tokens: The merchant description is tokenized using a standard subword tokenizer like Byte Pair Encoding (BPE), which breaks the text into common fragments. This allows the model to recognize patterns in merchant names or transaction types.
By combining these elements, a transaction is transformed into a short and meaningful sequence of tokens. See the diagram below:
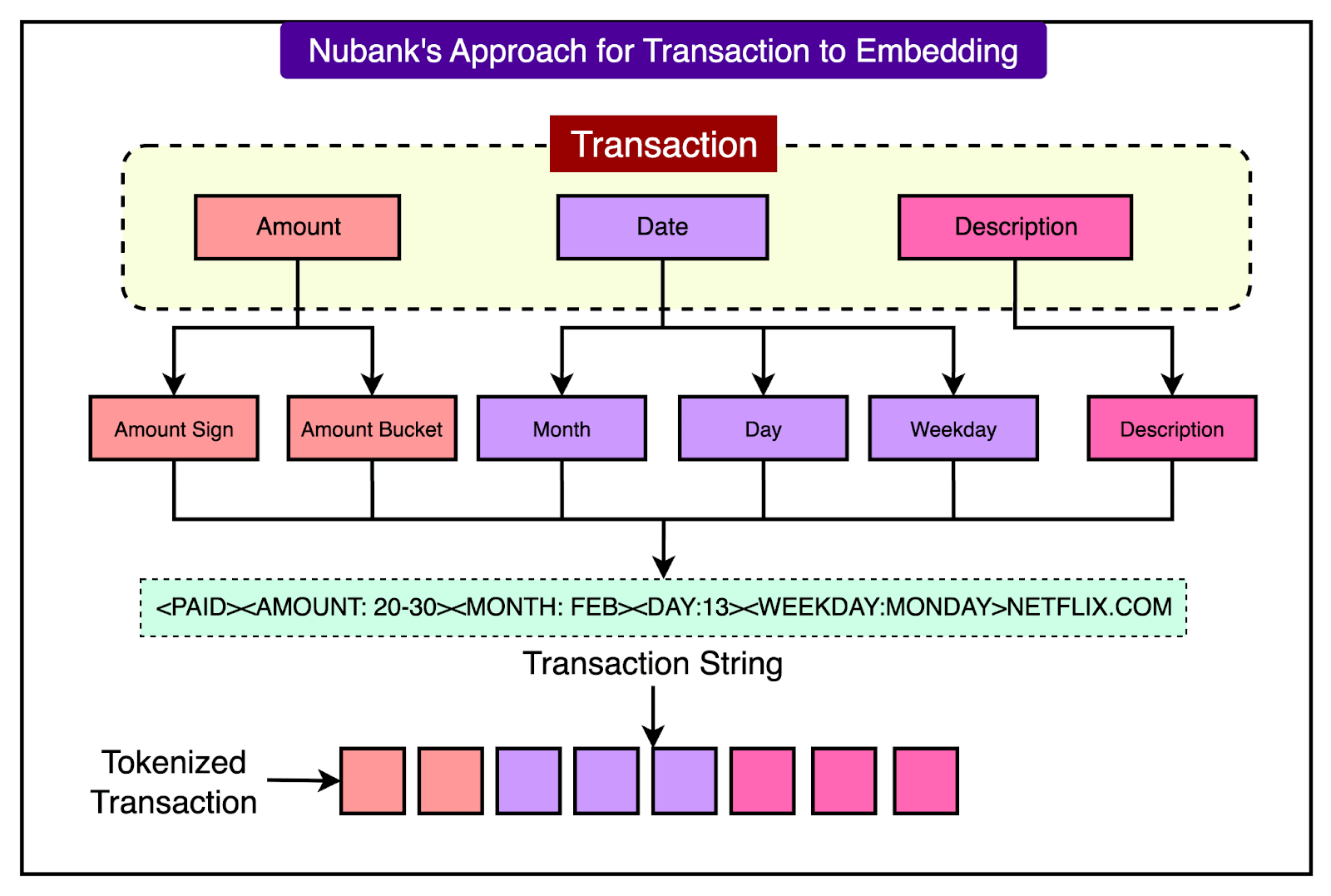
This hybrid approach retains the key structured information in a compact format while allowing generalization to new inputs. It also avoids long text sequences, which keeps attention computation efficient.
Once each transaction is tokenized in this way, the full transaction history of a user can be concatenated into a sequence and used as input to the transformer. Separator tokens are inserted between transactions to preserve boundaries, and the sequence is truncated at a fixed context length to stay within computational limits.
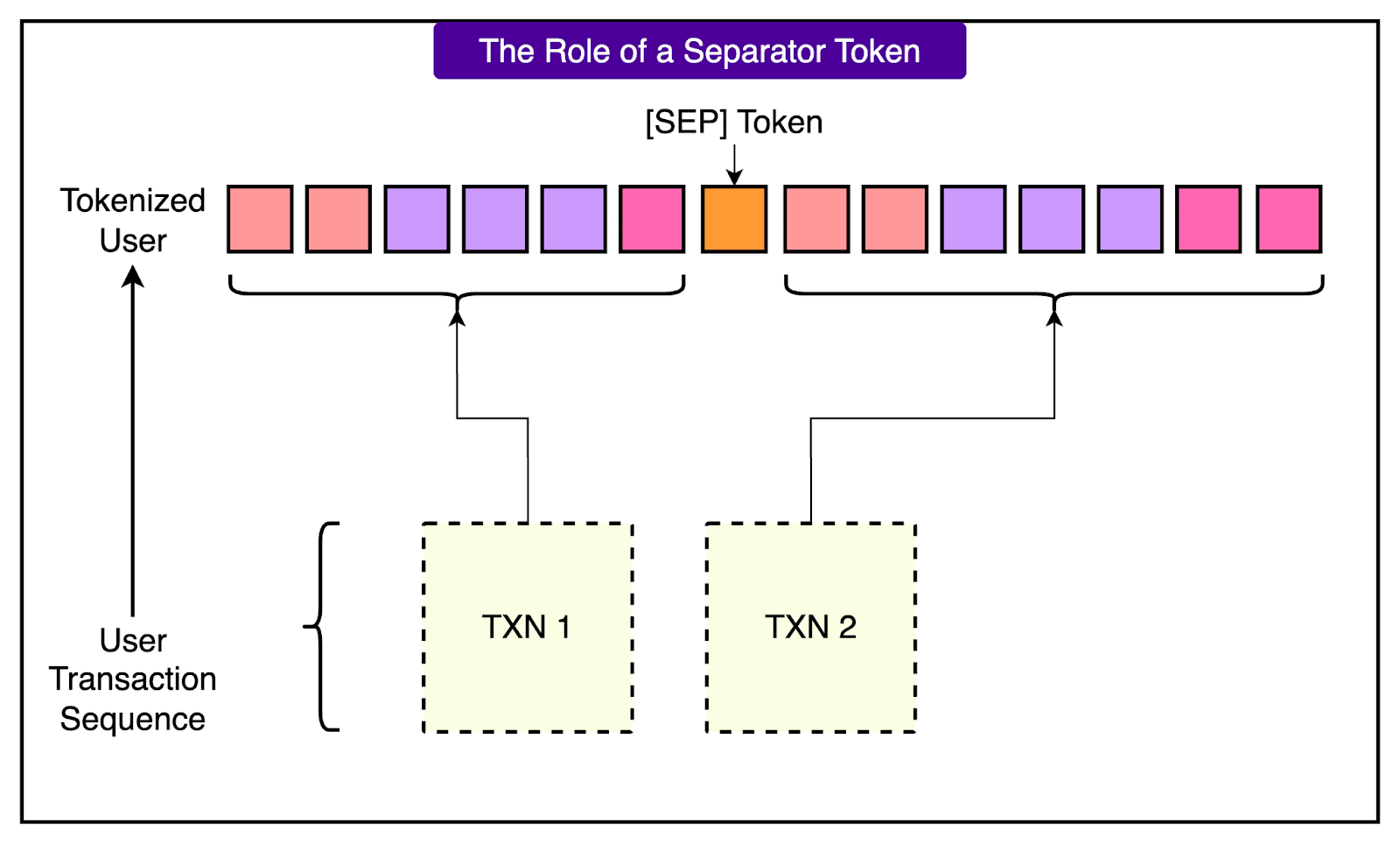
Training the Foundation Models
Once transactions are converted into sequences of tokens, the next step is to train a transformer model that can learn patterns from this data.
As mentioned, the Nubank engineering team uses self-supervised learning to achieve this, which means the model learns directly from the transaction sequences without needing any manual labels. This approach allows the system to take full advantage of the enormous volume of historical transaction data available across millions of users.
Two main objectives are used:
Next Token Prediction (NTP): The model is trained to predict the next token in a transaction sequence based on the tokens that came before it. This teaches the model to understand the flow and structure of transaction behavior over time, similar to how language models predict the next word in a sentence.
Masked Language Modeling (MLM): In this method, some tokens in the sequence are randomly hidden or “masked,” and the model is trained to guess the missing tokens. This forces the model to understand the surrounding context and learn meaningful relationships between tokens, such as the connection between the day of the week and spending type or between merchant names and transaction amounts.
See the diagram below:
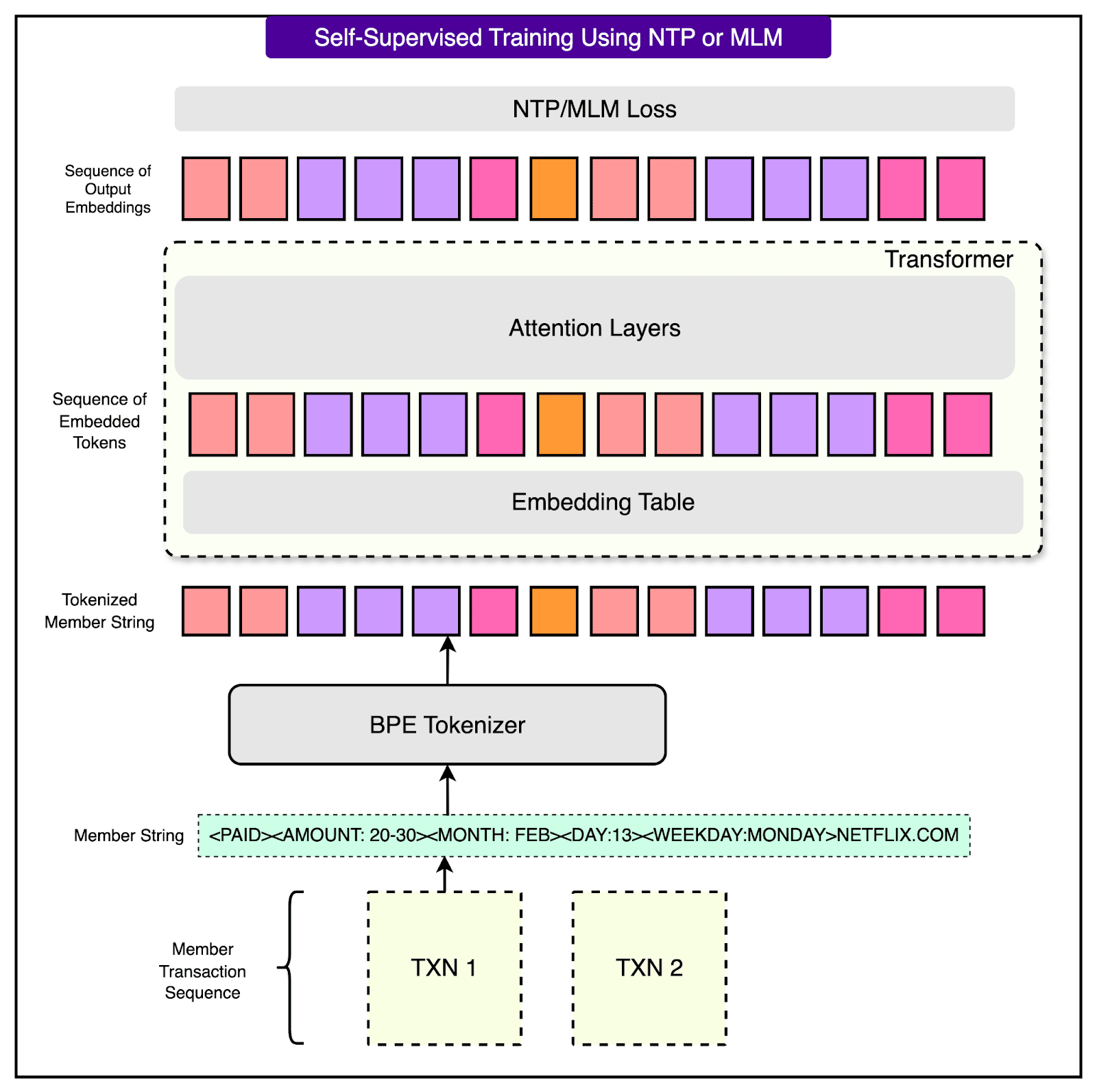
Blending Sequential Embeddings with Tabular Data
While foundation models trained on transaction sequences can capture complex behavioral patterns, many financial systems still rely on structured tabular data for critical features.
For example, information from credit bureaus, user profiles, or application forms often comes in tabular format. To make full use of both sources (sequential embeddings from the transformer and existing tabular features), it is important to combine them in a way that maximizes predictive performance.
This process of combining different data modalities is known as fusion.
Nubank explored two main fusion strategies: late fusion, which is easier to implement but limited in effectiveness, and joint fusion, which is more powerful and trains all components together in a unified system.
See the diagram below:
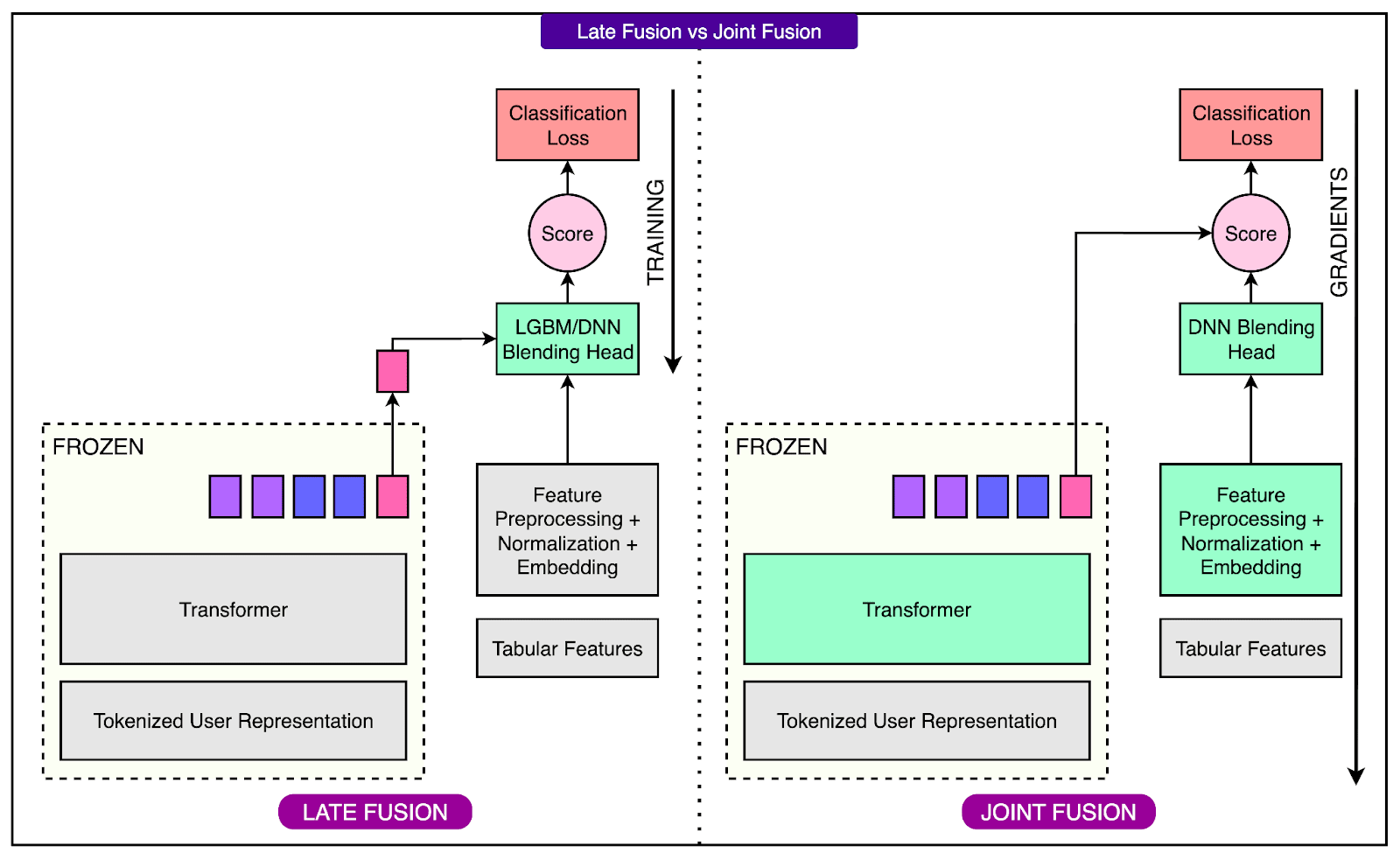
Late Fusion (Baseline Approach)
In the late fusion setup, tabular features are combined with the frozen embeddings produced by a pretrained foundation model. Think of it like taking the “frozen feeling” from the pre-trained model (embeddings) and combining it with the checklist of facts such as age, credit score, profile details, and so on.
These combined inputs are then passed into a traditional machine learning model, such as LightGBM or XGBoost. While this method is simple and leverages well-established tools, it has an important limitation.
Since the foundation model is frozen and trained separately, the embeddings do not adapt to the specific downstream task or interact meaningfully with the tabular data during training. As a result, there is no synergy between the two input sources, and the overall model cannot fully optimize performance.
Joint Fusion (Proposed Method)
To overcome this limitation, Nubank developed a joint fusion architecture.
This approach trains the transformer and the tabular model together in a single end-to-end system. By doing this, the model can learn to extract information from transaction sequences that complements the structured tabular data, and both components are optimized for the same prediction task.
To implement this, Nubank selected DCNv2 (Deep and Cross Network v2) as the architecture for processing tabular features. DCNv2 is a deep neural network specifically designed to handle structured inputs. It combines deep layers with cross layers that capture interactions between features efficiently.
See the diagram below:
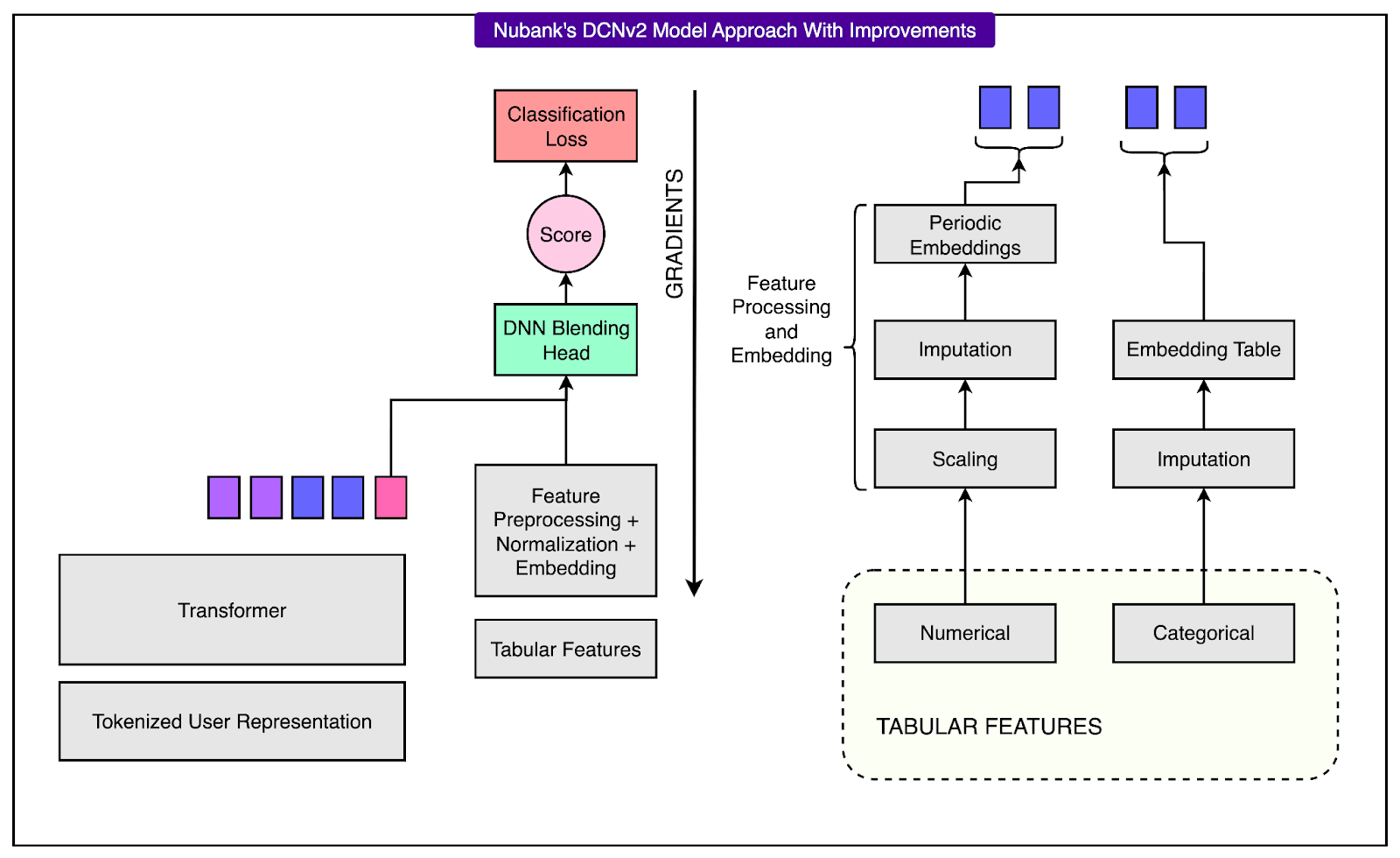
Conclusion
Nubank’s initiative to use foundational models represents a significant leap forward in how financial institutions can understand and serve their customers. By moving away from manually engineered features and embracing self-supervised learning on raw transaction data, Nubank has built a modeling system that is both scalable and expressive.
A key part of this success lies in how the system has been integrated into Nubank’s broader AI infrastructure. Rather than building isolated models for each use case, Nubank has developed a centralized AI platform where teams can access pretrained foundation models. These models are trained on massive volumes of user transaction data and are stored in a shared model repository.
Teams across the company can choose between two types of models based on their needs:
Embedding-only models, which use the user representation generated from transaction sequences.
Blended models, which combine these embeddings with structured tabular features using the joint fusion architecture.
This flexibility is critical.
Some teams may already have strong tabular models in place and can plug in the user embeddings with minimal changes. Others may prefer to rely entirely on the transformer-based sequence model, especially for new tasks where historical tabular features are not yet defined.
The architecture is also forward-compatible with new data sources. While the current models are primarily trained on transactions, the design allows for the inclusion of other user interaction data, such as app usage patterns, customer support chats, or browsing behavior.
In short, Nubank’s system is not just a technical proof-of-concept. It is a production-ready solution that delivers measurable gains across core financial prediction tasks.
References:
Understanding Our Customer’s Finances Through Foundation Models
Defining an Interface between Transaction Data and Foundational Models
Shipping late? DevStats shows you why. (Sponsored)

Still pretending your delivery issues are a mystery? They’re not. You’re just not looking in the right place.
DevStats gives engineering leaders brutal clarity on where delivery breaks down, so you can fix the process instead of pointing fingers.
✅ Track DORA and flow metrics like a grown-up
✅ Spot stuck work, burnout risks, and aging issues
✅ Cut cycle time without cutting corners
✅ Ship faster. With fewer surprises.
More AI tools won’t fix your delivery. More Clarity will.
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
