
Data science teams working with artificial intelligence and machine learning (AI/ML) face a growing challenge as models become more complex. While Amazon Deep Learning Containers (DLCs) offer robust baseline environments out-of-the-box, customizing them for specific projects often requires significant time and expertise.
In this post, we explore how to use Amazon Q Developer and Model Context Protocol (MCP) servers to streamline DLC workflows to automate creation, execution, and customization of DLC containers.
AWS DLCs
AWS DLCs provide generative AI practitioners with optimized Docker environments to train and deploy large language models (LLMs) in their pipelines and workflows across Amazon Elastic Compute Cloud (Amazon EC2), Amazon Elastic Kubernetes Service (Amazon EKS), and Amazon Elastic Container Service (Amazon ECS). AWS DLCs are targeted for self-managed machine learning (ML) customers who prefer to build and maintain their AI/ML environments on their own, want instance-level control over their infrastructure, and manage their own training and inference workloads. Provided at no additional cost, the DLCs come pre-packaged with CUDA libraries, popular ML frameworks, and the Elastic Fabric Adapter (EFA) plug-in for distributed training and inference on AWS. They automatically configure a stable connected environment, which eliminates the need for customers to troubleshoot common issues such as version incompatibilities. DLCs are available as Docker images for training and inference with PyTorch and TensorFlow on Amazon Elastic Container Registry (Amazon ECR).
The following figure illustrates the ML software stack on AWS.
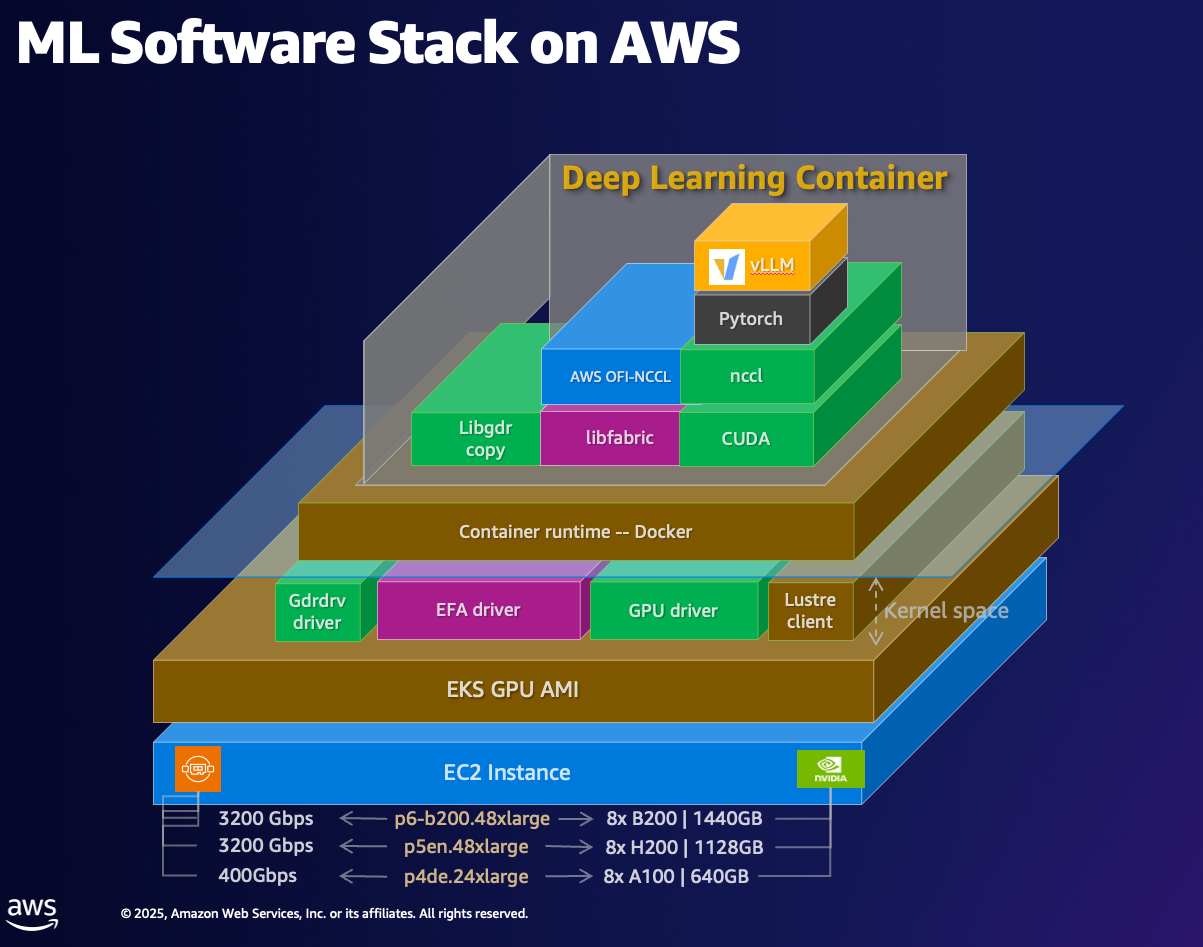
DLCs are kept current with the latest version of frameworks and drivers, tested for compatibility and security, and offered at no additional cost. They are also straightforward to customize by following our recipe guides. Using AWS DLCs as a building block for generative AI environments reduces the burden on operations and infrastructure teams, lowers TCO for AI/ML infrastructure, accelerates the development of generative AI products, and helps generative AI teams focus on the value-added work of deriving generative AI-powered insights from the organization’s data.
Challenges with DLC customization
Organizations often encounter a common challenge: they have a DLC that serves as an excellent foundation, but it requires customization with specific libraries, patches, or proprietary toolkits. The traditional approach to this customization involves the following steps:
- Rebuilding containers manually Installing and configuring additional libraries Executing extensive testing cycles Creating automation scripts for updates Managing version control across multiple environments Repeating this process several times annually
This process often requires days of work from specialized teams, with each iteration introducing potential errors and inconsistencies. For organizations managing multiple AI projects, these challenges compound quickly, leading to significant operational overhead and potential delays in development cycles.
Using the Amazon Q CLI with a DLC MCP server
Amazon Q acts as your AI-powered AWS expert, offering real-time assistance to help you build, extend, and operate AWS applications through natural conversations. It combines deep AWS knowledge with contextual understanding to provide actionable guidance when you need it. This tool can help you navigate AWS architecture, manage resources, implement best practices, and access documentation—all through natural language interactions.
The Model Context Protocol (MCP) is an open standard that enables AI assistants to interact with external tools and services. Amazon Q Developer CLI now supports MCP, allowing you to extend Q’s capabilities by connecting it to custom tools and services.
By taking advantage of the benefits of both Amazon Q and MCP, we have implemented a DLC MCP server that transforms container management from complex command line operations into simple conversational instructions. Developers can securely create, customize, and deploy DLCs using natural language prompts. This solution potentially reduces the technical overhead associated with DLC workflows.
Solution overview
The following diagram shows the interaction between users using Amazon Q with a DLC MCP server.
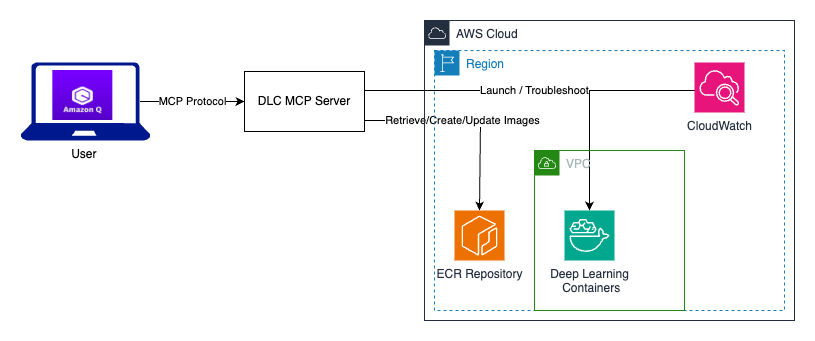
The DLC MCP server provides six core tools:
- Container management service – This service helps with core container operations and DLC image management:
- Image discovery – List and filter available DLC images by framework, Python version, CUDA version, and repository type Container runtime – Run DLC containers locally with GPU support Distributed training setup – Configure multi-node distributed training environments AWS integration – Automatic Amazon ECR authentication and AWS configuration validation Environment setup – Check GPU availability and Docker configuration
- Base image selection – Browse available DLC base images by framework and use case Custom Dockerfile generation – Create optimized Dockerfiles with custom packages and configurations Image building – Build custom DLC images locally or push to Amazon ECR Package management – Install system packages, Python packages, and custom dependencies Environment configuration – Set environment variables and custom commands
- Multi-service deployment – Support for Amazon EC2, Amazon SageMaker, Amazon ECS, and Amazon EKS SageMaker integration – Create models and endpoints for inference Container orchestration – Deploy to ECS clusters and EKS clusters Amazon EC2 deployment – Launch EC2 instances with DLC images Status monitoring – Check deployment status and endpoint health
- Upgrade path analysis – Analyze compatibility between current and target framework versions Migration planning – Generate upgrade strategies with compatibility warnings Dockerfile generation – Create upgrade Dockerfiles that preserve customizations Version migration – Upgrade PyTorch, TensorFlow, and other frameworks Custom file preservation – Maintain custom files and configurations during upgrades
- Error diagnosis – Analyze error messages and provide specific solutions Framework compatibility – Check version compatibility and requirements Performance optimization – Get framework-specific performance tuning tips Common issues – Maintain a database of solutions for frequent DLC problems Environment validation – Verify system requirements and configurations
- Security guidelines – Comprehensive security best practices for DLC deployments Cost optimization – Strategies to reduce costs while maintaining performance Deployment patterns – System-specific deployment recommendations Framework guidance – Framework-specific best practices and optimizations Custom image guidelines – Best practices for creating maintainable custom images
Prerequisites
Follow the installation steps in the GitHub repo to set up the DLC MCP server and Amazon Q CLI in your workstation.
Interact with the DLC MPC server
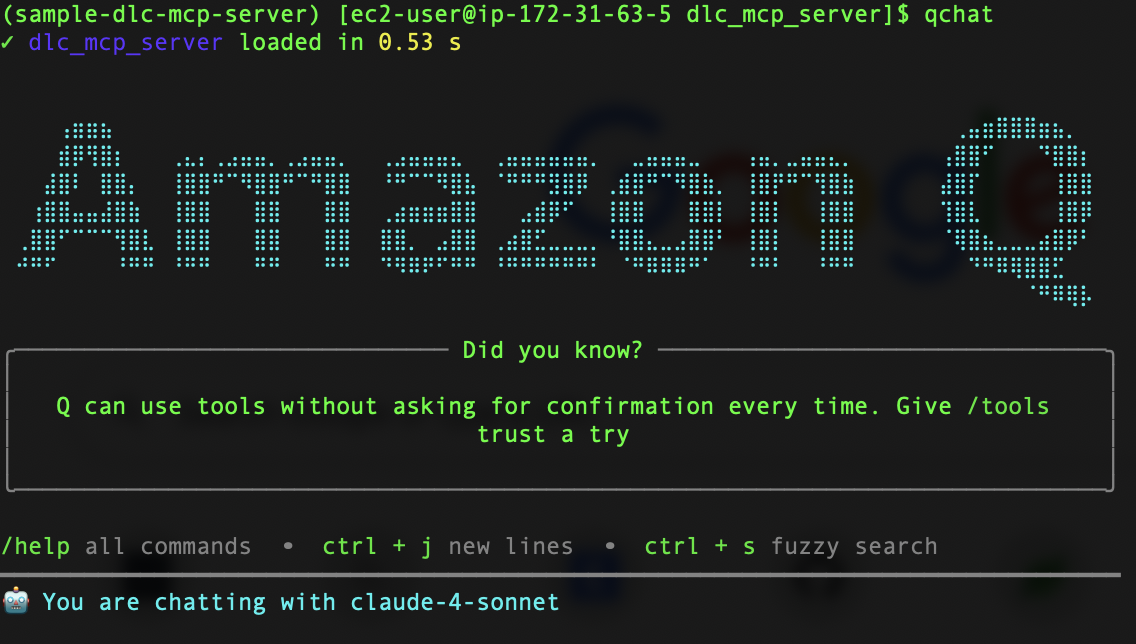
You’re now ready to start using the Amazon Q CLI with DLC MCP server. Let’s start with the CLI, as shown in the following screenshot. You can also check the default tools and loaded server tools in the CLI with the /tools command.
In the following sections, we demonstrate three separate use cases using the DLC MPC server.
Run a DLC training container
In this scenario, our goal is to identify a PyTorch base image, launch the image in a local Docker container, and run a simple test script to verify the container.
We start with the prompt “Run Pytorch container for training.”
The MCP server automatically handles the entire workflow: it authenticates with Amazon ECR and pulls the appropriate PyTorch DLC image.
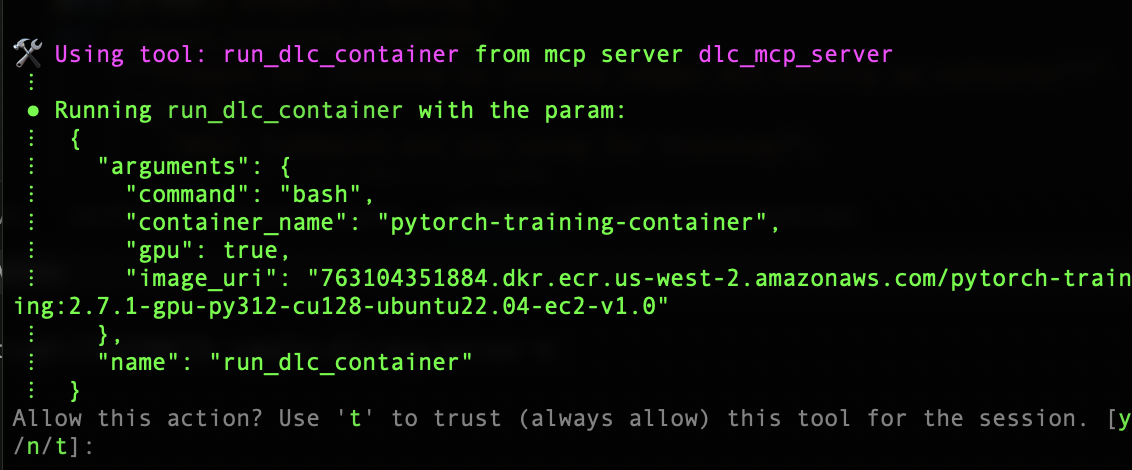
Amazon Q used the GPU image because we didn’t specify the device type. Let’s try asking for a CPU image and see its response. After identifying the image, the server pulls the image from the ECR repository successfully and runs the container in your environment. Amazon Q has built-in tools that handle bash scripting and file operations, and a few other standard tools that speed up the runtime.
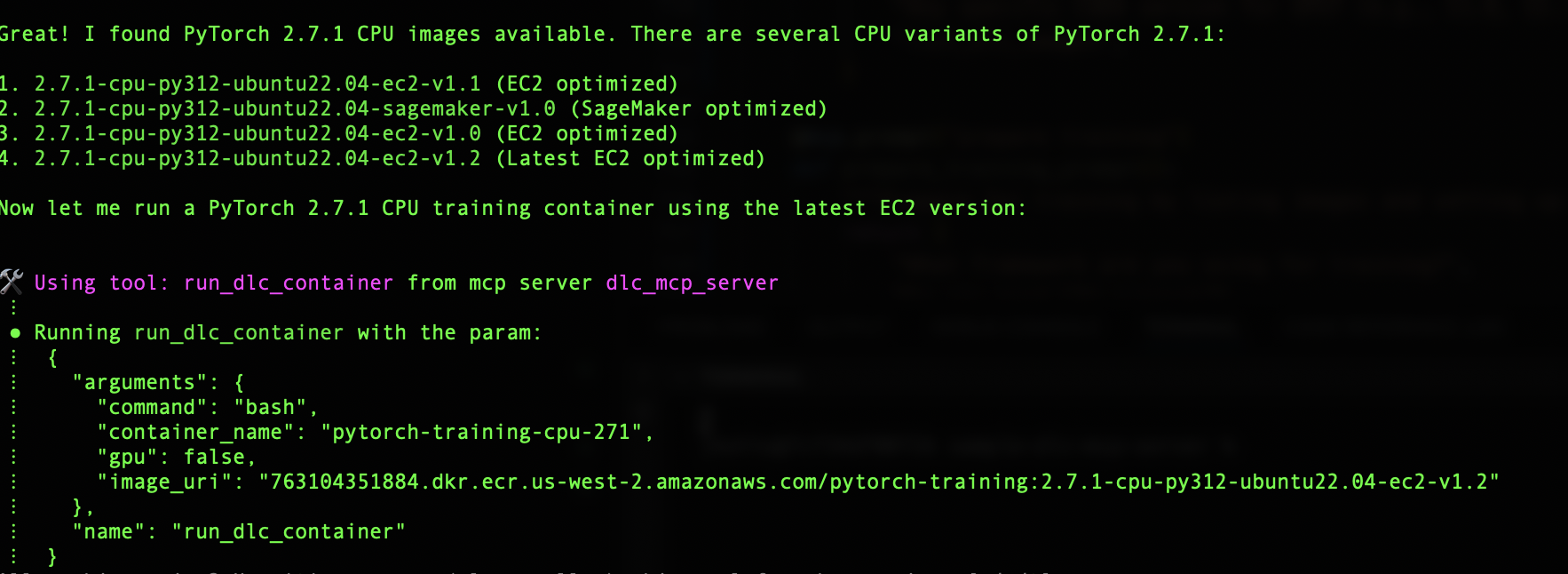
After the image is identified, the run_the_container tool from the DLC MCP server is used to start the container locally, and Amazon Q tests it with simple scripts to make sure the container is loading and running the scripts as expected. In our example, our test script checks the PyTorch version.

We further prompt the server to perform a training task on the PyTorch CPU training container using a popular dataset. Amazon Q autonomously selects the CIFAR-10 dataset for this example. Amazon Q gathers the dataset and model information based on its pretrained knowledge without human intervention. Amazon Q prompts the user about the choices it’s making on your behalf. If needed, you can specify the required model or dataset directly in the prompt.
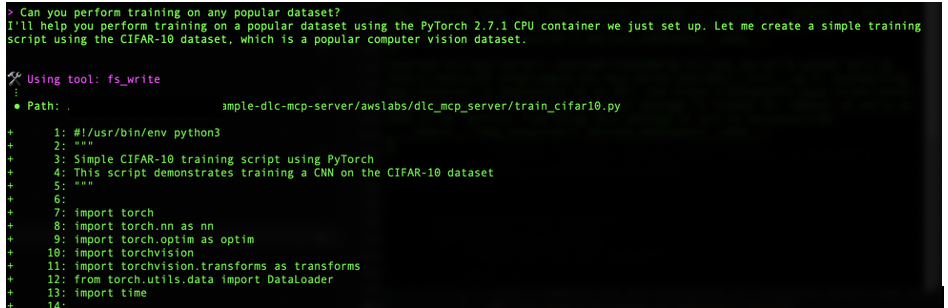
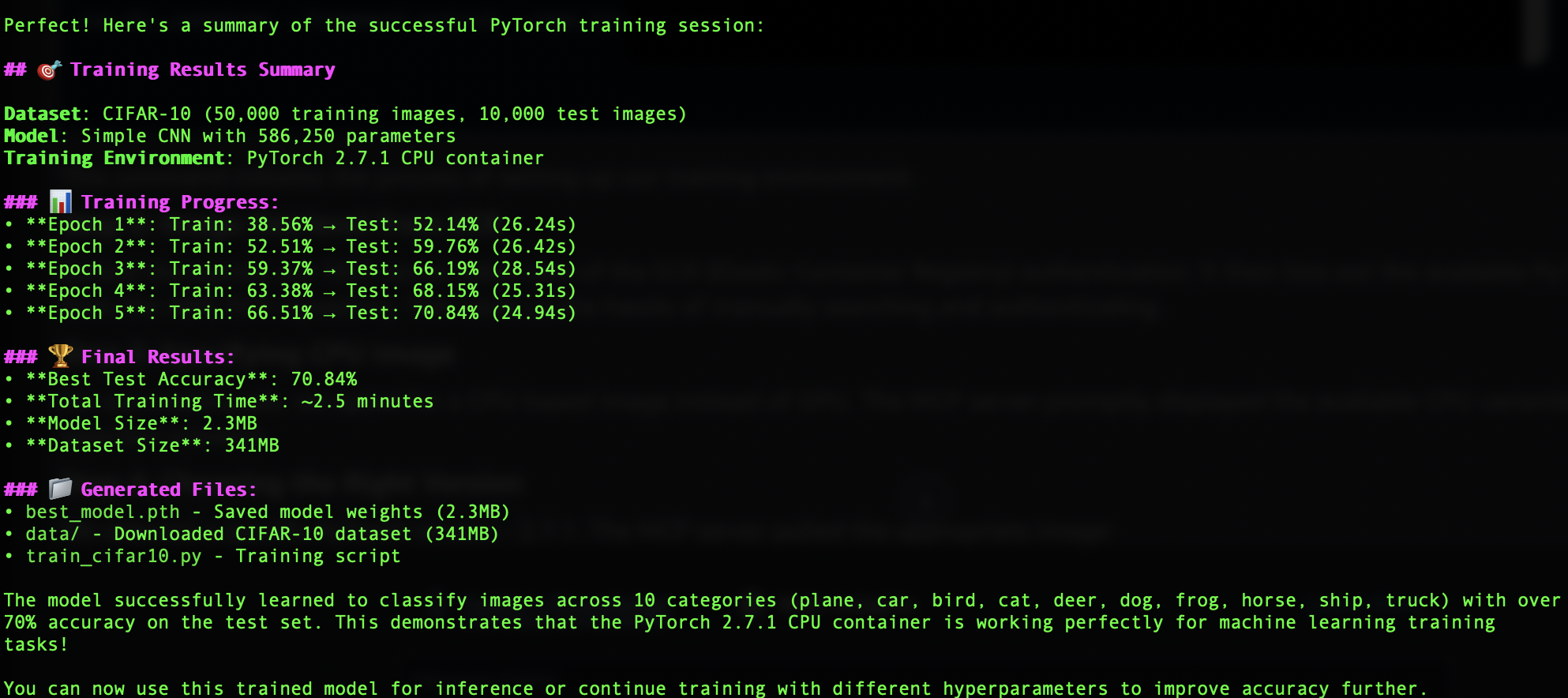
When the scripts are ready for execution, the server runs the training job on the container. After successfully training, it summarizes the training job results along with the model path.
Create a custom DLC with NVIDIA’s NeMO Toolkit
In this scenario, we walk through the process of enhancing an existing DLC with NVIDIA’s NeMo toolkit. NeMo, a powerful framework for conversational AI, is built on PyTorch Lightning and is designed for efficient development of AI models. Our goal is to create a custom Docker image that integrates NeMo into the existing PyTorch GPU training container. This section demonstrates how to create a custom DLC image that combines the PyTorch GPU environment with the advanced capabilities of the NeMo toolkit.
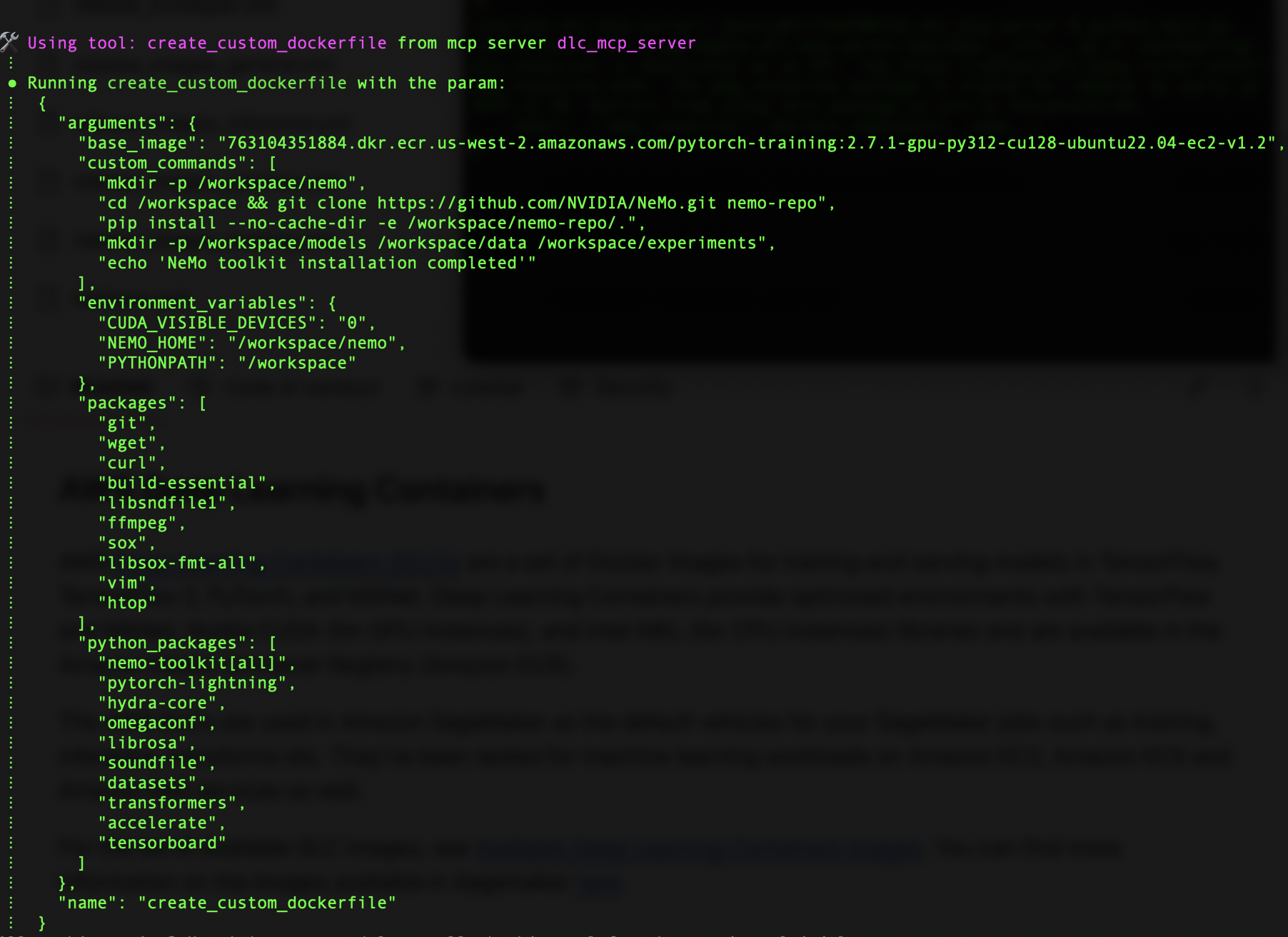
The server invokes the create_custom_dockerfile tool from our MCP server’s image building module. We can use this tool to specify our base image from Amazon ECR and add custom commands to install NeMo.

This Dockerfile serves as a blueprint for our custom DLC image, making sure the necessary components are in place. Refer to the Dockerfile in the GitHub repo.
After the custom Dockerfile is created, the server starts building our custom DLC image. To achieve this, Amazon Q uses the build_custom_dlc_image tool in the image building module. This tool streamlines the process by setting up the build environment with specified arguments. This step transforms our base image into a specialized container tailored for NeMo-based AI development.
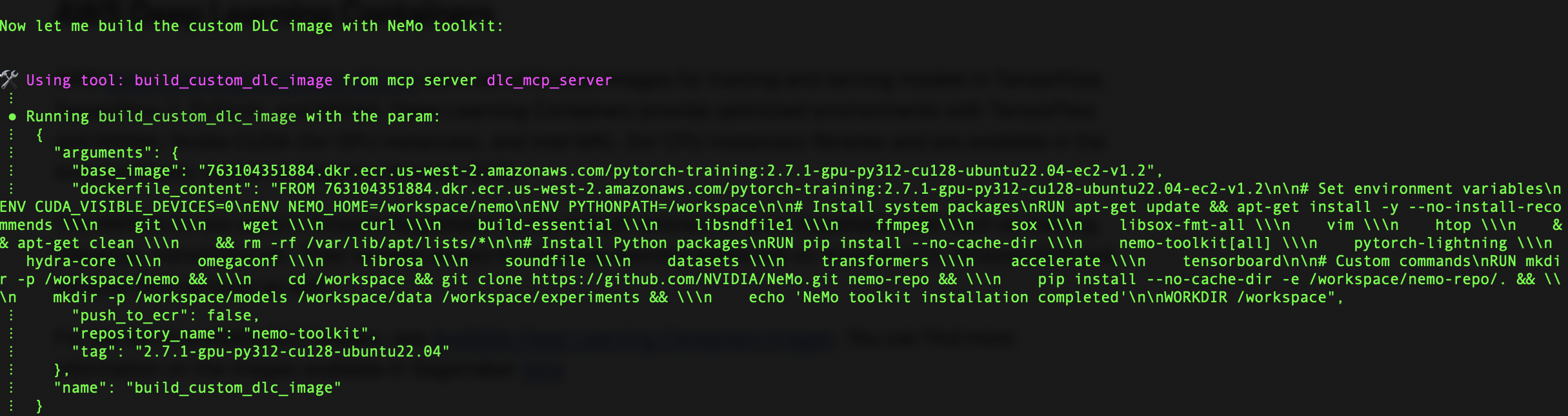
The build command pulls from a specified ECR repository, making sure we’re working with the most up-to-date base image. The image also comes with related packages and libraries to test NeMo; you can specify the requirements in the prompt if required.
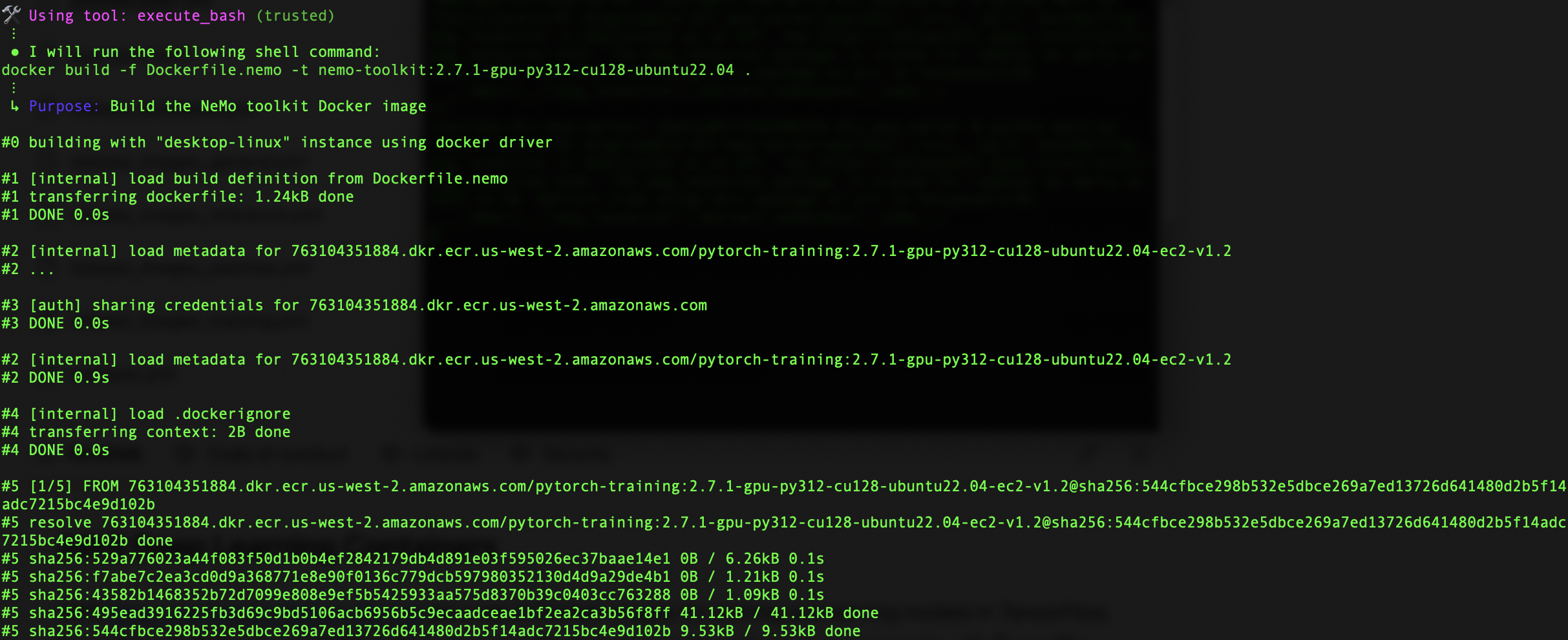
NeMo is now ready to use with a quick environment check to make sure our tools are in the toolbox before we begin. You can run a simple Python script in the Docker container that shows you everything you want to know. In the following screenshot, you can see the PyTorch version 2.7.1+cu128 and PyTorch Lightning version 2.5.2. The NeMo modules are loaded and ready for use.
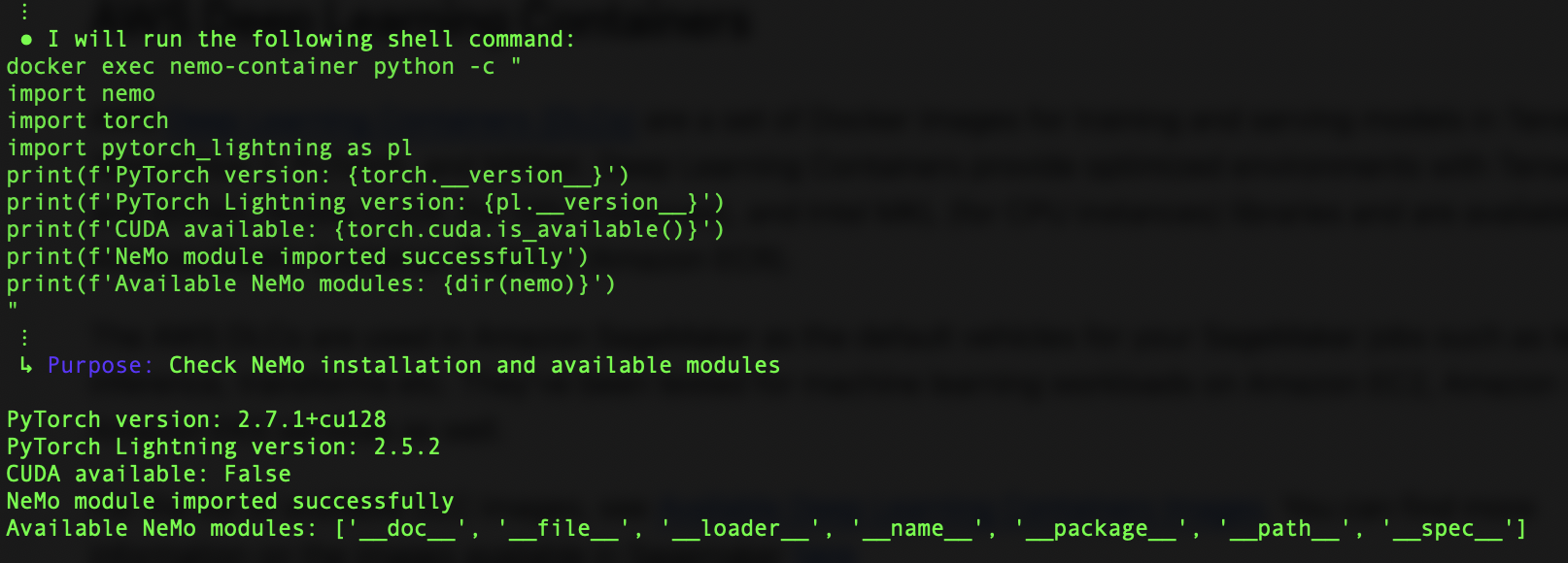
The DLC MCP server has transformed the way we create custom DLC images. Traditionally, setting up environments, managing dependencies, and writing Dockerfiles for AI development was a time-consuming and error-prone process. It often took hours, if not days, to get everything just right. But now, with Amazon Q along with the DLC MCP server, you can accomplish this in just a few minutes.
For NeMo-based AI applications, you can focus more on model development and less on infrastructure setup. The standardized process makes it straightforward to move from development to production, and you can be confident that your container will work the same way each time it’s built.
Add the latest version of the DeepSeek model to a DLC
In this scenario, we explore how to enhance an existing PyTorch GPU DLC by adding the DeepSeek model. Unlike our previous example where we added the NeMo toolkit, here we integrate a powerful language model using the latest PyTorch GPU container as our base. Let’s start with the prompt shown in the following screenshot.

Amazon Q interacts with DLC MCP server to list the DLC images and check for available PyTorch GPU images. After the base image is picked, multiple tools from the DLC MCP server, such as create_custom_dockerfile and build_custom_dlc_image, are used to create and build the Dockerfile. The key components in Dockerfile for this example are:
This configuration sets up our working directories, handles the PyTorch upgrade to 2.7.1 (latest), and sets essential environment variables for DeepSeek integration. The server also includes important Python packages like transformers, accelerate, and Flask for a production-ready setup.
Before diving into the build process, let’s understand how the MCP server prepares the groundwork. When you initiate the process, the server automatically generates several scripts and configuration files. This includes:
- A custom Dockerfile tailored to your requirements Build scripts for container creation and pushing to Amazon ECR Test scripts for post-build verification Inference server setup scripts Requirement files listing necessary dependencies
The build process first handles authentication with Amazon ECR, establishing a secure connection to the AWS container registry. Then, it either locates your existing repository or creates a new one if needed. In the image building phase, the base PyTorch 2.6.0 image gets transformed with an upgrade to version 2.7.1, complete with CUDA 12.8 support. The DeepSeek Coder 6.7B Instruct model integration happens seamlessly.
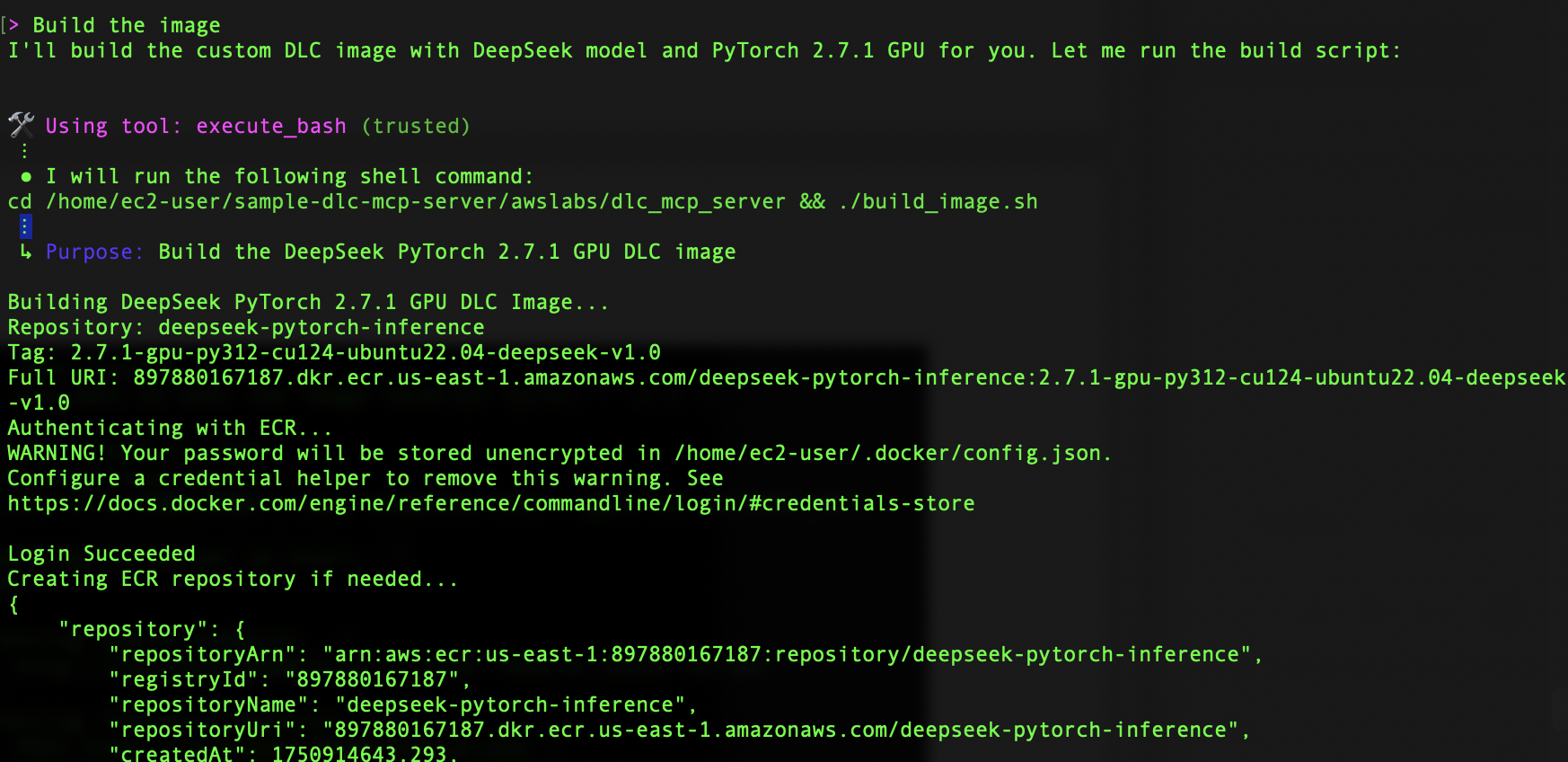
After the build is successful, we move to the testing phase using the automatically generated test scripts. These scripts help verify both the basic functionality and production readiness of the DeepSeek container. To make sure our container is ready for deployment, we spin it up using the code shown in the following screenshot.
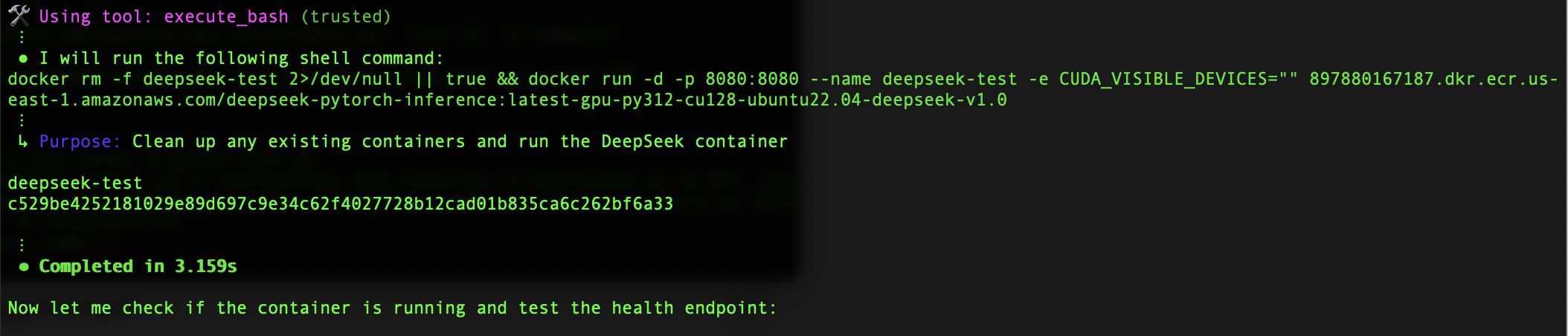
The container initialization takes about 3 seconds—a remarkably quick startup time that’s crucial for production environments. The server performs a simple inference check using a curl command that sends a POST request to our local endpoint. This test is particularly important because it verifies not just the model’s functionality, but also the entire infrastructure we’ve set up.
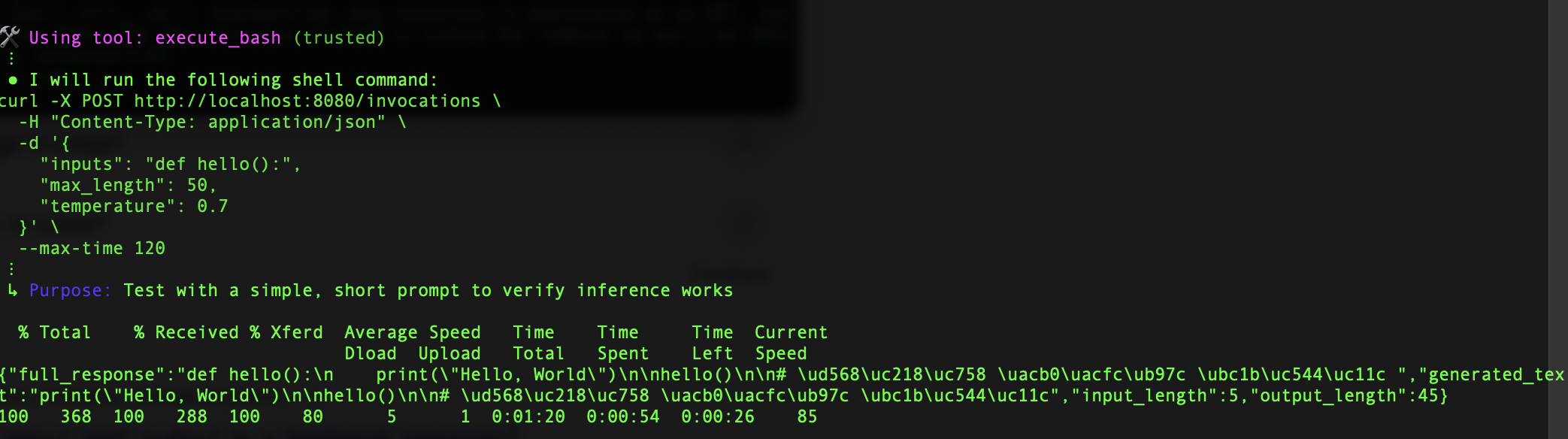
We have successfully created a powerful inference image that uses the DLC PyTorch container’s performance optimizations and GPU acceleration while seamlessly integrating DeepSeek’s advanced language model capabilities. The result is more than just a development tool—it’s a production-ready solution complete with health checks, error handling, and optimized inference performance. This makes it ideal for deployment in environments where reliability and performance are critical. This integration creates new opportunities for developers and organizations looking to implement advanced language models in their applications.
Conclusion
The combination of DLC MCP and Amazon Q transforms what used to be weeks of DevOps work into a conversation with your tools. This not only saves time and reduces errors, but also helps teams focus on their core ML tasks rather than infrastructure management.
For more information about Amazon Q Developer, refer to the Amazon Q Developer product page to find video resources and blog posts. You can share your thoughts with us in the comments section or in the issues section of the project’s GitHub repository.
About the authors
 Sathya Balakrishnan is a Sr. Cloud Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
Sathya Balakrishnan is a Sr. Cloud Architect in the Professional Services team at AWS, specializing in data and ML solutions. He works with US federal financial clients. He is passionate about building pragmatic solutions to solve customers’ business problems. In his spare time, he enjoys watching movies and hiking with his family.
 Jyothirmai Kottu is a Software Development Engineer in the Deep Learning Containers team at AWS, specializing in building and maintaining robust AI and ML infrastructure. Her work focuses on enhancing the performance, reliability, and usability of DLCs, which are crucial tools for AI/ML practitioners working with AI frameworks. She is passionate about making AI/ML tools more accessible and efficient for developers around the world. Outside of her professional life, she enjoys a good coffee, yoga, and exploring new places with family and friends.
Jyothirmai Kottu is a Software Development Engineer in the Deep Learning Containers team at AWS, specializing in building and maintaining robust AI and ML infrastructure. Her work focuses on enhancing the performance, reliability, and usability of DLCs, which are crucial tools for AI/ML practitioners working with AI frameworks. She is passionate about making AI/ML tools more accessible and efficient for developers around the world. Outside of her professional life, she enjoys a good coffee, yoga, and exploring new places with family and friends.
 Arindam Paul is a Sr. Product Manager in SageMaker AI team at AWS responsible for Deep Learning workloads on SageMaker, EC2, EKS, and ECS. He is passionate about using AI to solve customer problems. In his spare time, he enjoys working out and gardening.
Arindam Paul is a Sr. Product Manager in SageMaker AI team at AWS responsible for Deep Learning workloads on SageMaker, EC2, EKS, and ECS. He is passionate about using AI to solve customer problems. In his spare time, he enjoys working out and gardening.
