
想象一个使用大模型的任务,需要一次处理百万字符的文档,例如从百科全书中获取信息,或是分析数百页的法律卷宗,异或追踪持续数月的对话记录,都需要越来越长的上下文。
而大模型生成的每个词都需要扫描存储在所谓的KV缓存中存储的过去标记。
反复读取这个缓存会消耗GPU内存带宽。大模型还需要从内存中重新加载大量的前馈网络(FFN)权重来处理每个新词。
这个过程会减慢效应速度,从而导致用户与大模型对话时出现卡顿。
传统的解决方案,是使用张量并行(Tensor Parallelism, TP)将此负载分散到多个GPU上。但这仅能起到一定作用。
当规模超过一定限度后,GPU开始复制KV缓存,导致内存压力进一步增大。
而Helix这一英伟达针对其最新的Blackwall开发的并行策略,通过将模型Transformer层的注意力机制和前馈网络部分分开处理来解决卡顿问题。
Helix受DNA双螺旋结构的启发,Helix将KV、张量和专家等多个维度的并行性交织到一个统一的执行循环中。
每个阶段在其自身的瓶颈配置下运行,同时复用相同的GPU池。

论文链接:https://d1qx31qr3h6wln.cloudfront.net/publications/Helix_0.pdf

在注意力阶段,Helix使用一种名为KV并行(KVP)的新方法,将庞大的KV缓存分散到多个GPU上。
当TP超过KV头的数量时,张量并行会进行复制,从而增加了内存和带宽开销,如图1a到c描述的过程。
Helix通过将TP=2与KVP=2相结合,形成2D布局来避免内存和带宽开销的增加,对应图1d。
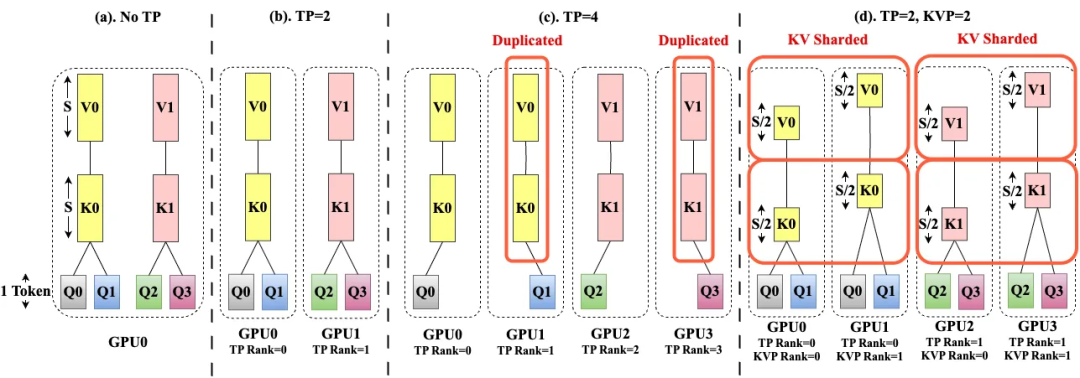
图1:传统的张量并行(TP)与Helix的不同注意力分片策略KVP的对比示意图
同时,由于KVP GPU持有与其本地KV头相关联的所有查询头,并冗余地计算QKV投影。
这使得每个KV分片能够进行完全本地的FlashAttention,确保了模型的推理精度。
之后KVP GPU之间沿着查询头维度进行单对单的全连接通信,通信的成本和KV缓存的大小无关,因此大模型的上下文长度即使扩展到百万token,也不会影响查询效率。
此外,Helix还通过重叠通信和计算,一旦计算出一个token的注意力输出,Helix就会启动该token的全对全交换,同时计算下一个token的注意力。
这种紧密的重叠将通信延迟隐藏在有用的工作之后,保持GPU利用率高,并进一步加速实时解码。
图2中上图的八个请求会同步执行注意力计算。随后进行顺序的全对全通信。
图2表底部对应使用HOP-B时,一个请求的通信与下一个请求的计算重叠,通过细粒度流水线减少了token间的延迟。
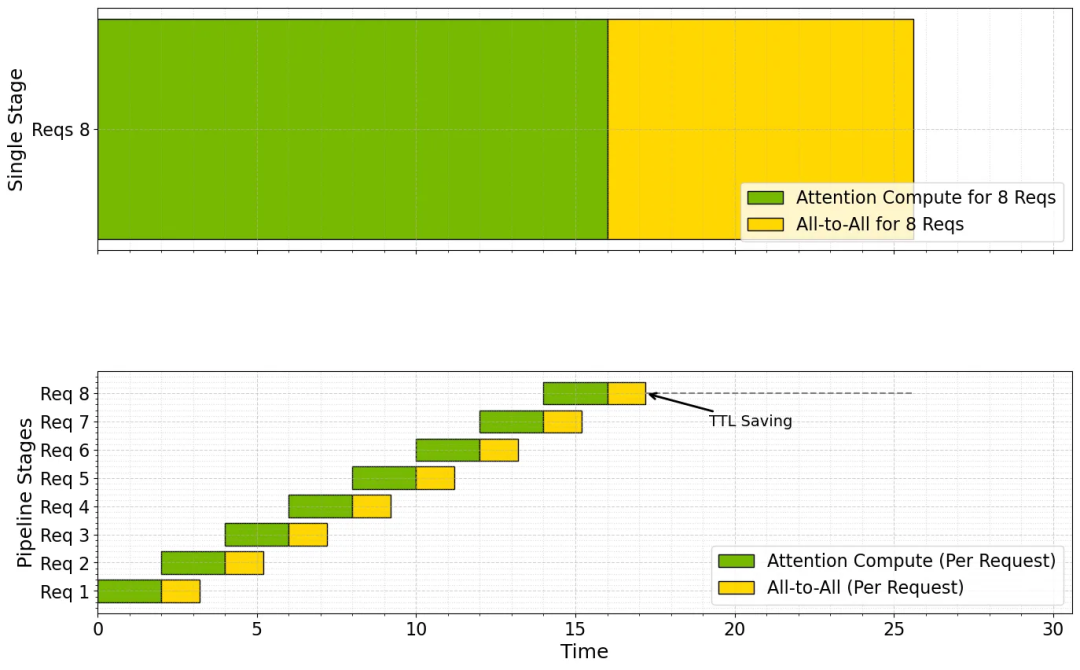
图2:Helix通过细粒度流水线技术加速大模型的响应
根据英伟达官网给出的计算,使用DeepSeek-R1 671B模型,在给定延迟下,当并发的用户数增大时,Helix相比传统方法体现出优势。
而到了图中第一个箭头标注的点时,其单GPU产出的token数是传统方法的32倍,这意味着可以将并发用户数量提高高达32倍。
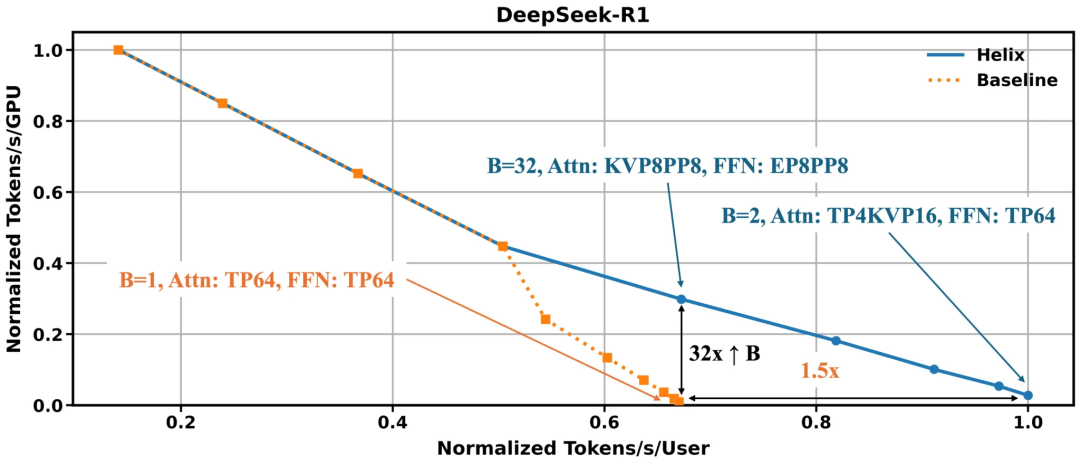
图3:使用100万上下文长度的DeepSeek-R1,评估使用经过最新NVIDIA GB200 NVL72(Blackwell)在固定延迟下的并发能力
在低并发设置下,Helix可以通过减token与token间的最低延迟时间,来提高用户交互体验,如图3右下方的对比所示。
该研究的参与者St-Maurice指出「Helix正在重塑我们处理LLM交互和设计的方式。」
他指出,Helix并行处理和优化的KV缓存分片正在为大模型提供可扩展的显存外挂,这与开发者改进旧处理器(如奔腾)的方式高度相似。
该技术能允许大模型应用扩展其用户规模的同时,保证其快速响应。
对于虚拟助手、法律机器人以及AI Copolit等应用,Helix的引入可以做到既处理大量工作负载,同时还保持低延迟响应能力。

对于这项技术突破,西北人工智能咨询公司的首席执行官兼联合创始人Wyatt Mayham表示:「英伟达的数百万个token的上下文窗口是一项令人印象深刻的工程里程碑,但对于大多数公司来说,它是一个寻找问题的解决方案,它解决了现有模型如长上下文推理和二次扩展等真实限制,但技术可能性和实际实用性之间存在差距。」
Mayham承认Helix在特定领域中很有用,例如需要完整文档保真度的合规性强的行业,或医疗系统一次性分析患者终身病史。
但这只是部分特例,大多数组织最好是构建更智能的流水线,而不是购买helix所需的Blackwell架构下的GB200机架。
且通常情况下,检索增强生成(RAG)系统能够在百万个token的范围内,表现的比将上下文长度提升到100k更好。
而Info-Tech研究集团技术顾问Justin St-Maurice则指出:在当今世界,为人类生成百科全书大小的回答并不是胜利。
相反,关键在于使大模型的输出对其他人工智能相关且可用。
这种能力可能成为未来智能体进步的推手。
有了当大模型的输出能具有对应的认知框架,智能体可以保持更丰富的内部状态,参与更复杂、更长时间的聊天,并执行更深入文档分析。
St-Maurice指出:Helix带来的长上下文窗口,能够支持context engineer(上下文工程)在庞大的上下文窗口中管理和优化信息,以最大限度地提高智能体的有效性和可靠性。
凭借在扩展的上下文窗口中处理和交换更大数据量的能力,AI智能体可以以以前不切实际的方式沟通和协作,从而改变多智能体应用的设计框架。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
