
Published on July 20, 2025 8:00 PM GMT
This might be beating a dead horse, but there are several "mysterious" problems LLMs are bad at that all seem to have the same cause. I wanted an article I could reference when this comes up, so I wrote one.
- LLMs can't count the number of R's in strawberry.LLMs used to be bad at math.Claude can't see the cuttable trees in Pokemon.LLMs are bad at any benchmark that involves visual reasoning.
What do these problems all have in common? The LLM we're asking to solve these problems can't see what we're asking it to do.
How many tokens are in 'strawberry'?
Current LLMs almost always process groups of characters, called tokens, instead of processing individual characters. They do this for performance reasons[1]: Grouping 4 characters (on average) into a token reduces your effective context length by 4x.
So, when you see the question "How many R's are in strawberry?", you can zoom in on [s, t, r, a, w, b, e, r, r, y], count the r's and answer 3. But when GPT-4o looks at the same question, it sees [5299 ("How"), 1991 (" many"), 460 (" R"), 885 ("'s"), 553 (" are"), 306 (" in"), 101830 (" strawberry"), 30 ("?")].

Good luck counting the R's in token 101830. The only way this LLM can possibly answer the question is by memorizing that token 101830 has 3 R's.
You thought New Math was confusing...
Ok, so why were LLMs initially so bad at math? Would you believe that this situation is even worse?
Say you wanted to add two numbers like 2020+1=?
You can zoom in on the digits, adding left-to-right[2] and just need to know how to add single-digit numbers and apply carries.
When an older LLM like GPT-3 looks at this problem...

It has to memorize that token 41655 ("2020") + token 16 ("1") = tokens [1238 ("20"), 2481 ("21")]. And it has to do that for every math problem because the number of digits in each number is essentially random[3].
Digit tokenization has actually been fixed and modern LLMs are pretty good at math now that they can see the digits. The solution is that digit tokens are always fixed length (typically 1-digit tokens for small models and 3-digit tokens for large models), plus tokenizing right-to-left to make powers of ten line up. This lets smaller models do math the same way we do (easy), and lets large models handle longer numbers in exchange for needing to memorize the interactions between every number from 0 to 999 (still much easier than the semi-random rules before).
Why can Claude see the forest but not the cuttable trees?


Multimodal models are capable of taking images as inputs, not just text. How do they do that?
Naturally, you cut up an image and turn it into tokens! Ok, so not exactly tokens. Instead of grouping some characters into a token, you group some pixels into a patch (traditionally, around 16x16 pixels).
The original thesis for this post was going to be that images have the same problem that text does, and patches discard pixel-level information, but I actually don't think that's true anymore, and LLMs might just be bad at understanding some images because of how they're trained or some other downstream bottleneck.
Unfortunately, the way most frontier models process images is secret, but Llama 3.2 Vision seems to use 14x14 patches and processes them into embeddings with dimension 4096[4]. A 14x14 RGB image is only 4704 bits[5] of data. Even pessimistically assuming 1.58 bits per dimension, there should be space to represent the value of every pixel.
It seems like the problem with vision is that the training is primarily on semantics ("Does this image contain a tree?") and there's very little training similar to "How exactly does this tree look different from this other tree?".
That said, cutting the image up on arbitrary boundaries does make things harder for the model. When processing an image from Pokemon Red, each sprite is usually 16x16 pixels, so processing 14x14 patches means the model constantly needs to look at multiple patches and try to figure out which objects cross patch boundaries.
Visual reasoning with blurry vision
LLMs have the same trouble with visual reasoning problems that they have playing Pokemon. If you can't see the image you're supposed to be reasoning from, it's hard to get the right answer.
For example, ARC Prize Puzzle 00dbd492 depends on visual reasoning of a grid pattern.
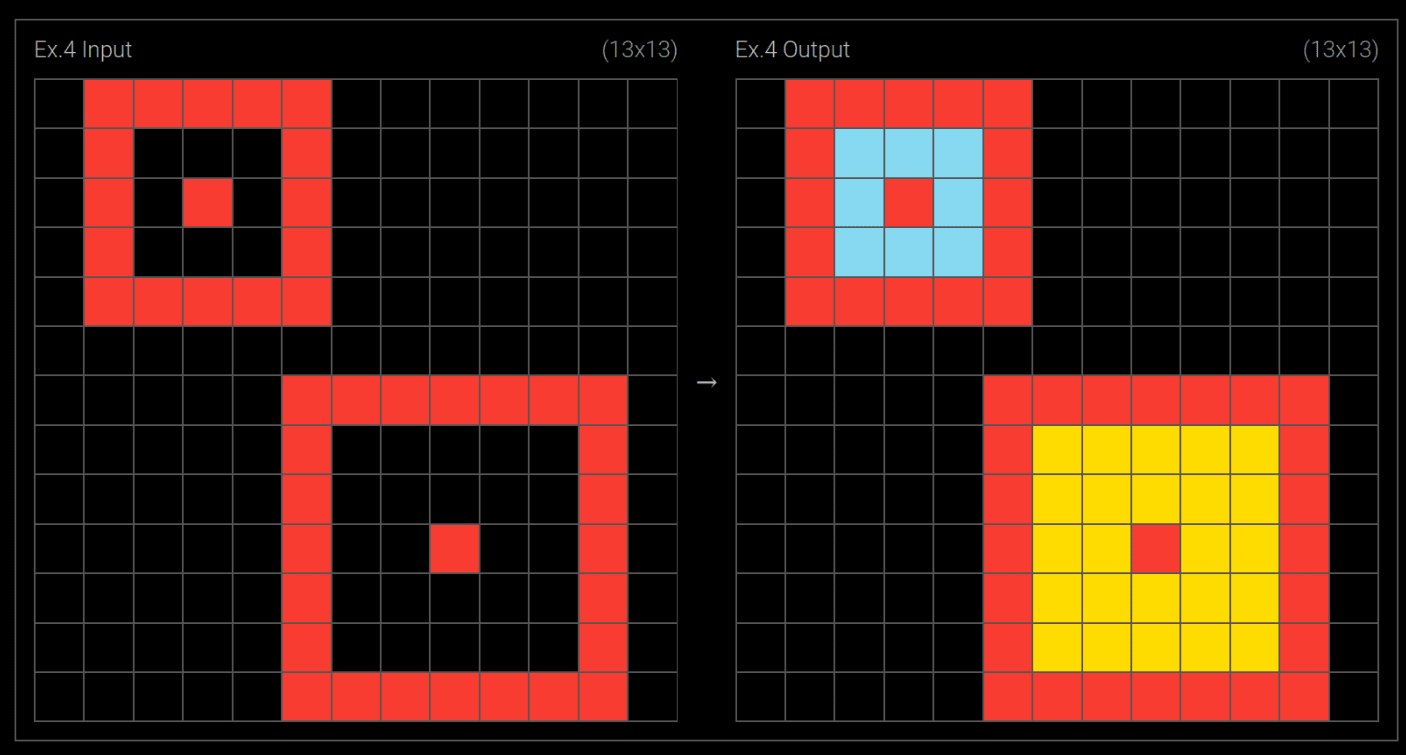
If I give Claude a series of screenshots, it fails completely because it can't actually see the pattern in the test input.

But if I give it ASCII art designed to ensure one token per pixel, it gets the answer right.

Is this fixable?
As mentioned above, this has been fixed for math by hard-coding the tokenization rules in a way that makes sense to humans.
For text in general, you can just work off of the raw characters[6], but this requires significantly more compute and memory. There are a bunch of people looking into ways to improve this, but the most interesting one I've seen is Byte Latent Transformers[7], which dynamically selects patches to work with based on complexity instead of using hard-coded tokenization. As far as I know, no one is doing this in frontier models because of the compute cost, though.
I know less about images, but you can run a transformer on the individual pixels of an image, but again, it's impractical to do this. Images are big, and a single frame of 1080p video contains over 2 million pixels. If those were 2 million individual tokens, a single frame of video would fill your entire context window.
I think vision transformers actually do theoretically have access to pixel-level data though, and there might just be an issue with training or model sizes preventing them from seeing pixel-level features accurately. It might also be possible to do dynamic selection of patch sizes, but unfortunately the big labs don't seem to talk about this, so I'm not sure what the state of the art is.
- ^
Tokenization also causes the model to generate the first level of embeddings on potentially more meaningful word-level chunks, but the model could learn how to group (or not) characters in later layers if the first layer was character-level.
- ^
Adding numbers written left-to-right is also hard for transformers, but much easier when they don't have to memorize the whole thing!
- ^
Tokenization usually uses how common tokens are, so a very common number like 1945 will get its own unique token while less common numbers like 945 will be broken into separate tokens.
- ^
If you're a programmer, this means an array of 4096 numbers.
- ^
14 x 14 x 3 (RGB channels) x 8 = 4704
- ^
Although this doesn't entirely solve the problem, since characters aren't the only layer of input with meaning. Try asking a character-level model to count the strokes in "罐".
- ^
I should mention that I work at the company that produced this research, but I found it on Twitter, not at work.
Discuss
