
搶食建置AI工廠商機,採用輝達Blackwell架構GPU的加速運算服務,三大公有雲業者今年皆已陸續推出,最近我們整理Google Cloud供應的解決方案,稍早曾介紹另一家廠商AWS的動向,他們在 5月推出採用Nvidia B200 GPU的執行個體服務P6-B200,基於Nvidia GB200 NVL72的執行個體,則是在7月9日宣布正式推出,名為P6e-GB200。
AWS強調,這套雲端執行個體,不僅針對AI訓練與推論的工作負載,提供更強大的GPU運算效能,還能夠搭配AWS設計的專屬網路加速卡EFA(Elastic Fabric Adapter),提供高頻寬、低延遲的網路連線能力,並以此連接多個Amazon EC2執行個體,建構叢集運算伺服器Amazon EC2 UltraServers。
在產品定位上,P6e-GB200 UltraServers適合執行運算與記憶體需求最大規模的AI工作負載,像是混合專家模型(MOE)、推理模型等最先進的模型,參數規模高達數兆,可即時處理超大規模上下文(context windows)或支撐高度平行運作(high-concurrency)的應用系統。
企業若想使用這樣的運算服務,可經由EC2 Capacity Blocks for ML的模式,進行容量預留的訂購程序,伺服器硬體設置在AWS的本地區域(Local Zone)達拉斯us-east-1-dfw-2a,是從美國東部(維吉尼亞北部)區域延伸出來的資料中心。
除了透過上述形式供應用戶進行AI訓練與推論,AWS旗下已有幾款應用服務整合P6e-GB200 UltraServers,像是用於超大AI模型分散式訓練的Amazon SageMaker Hyperpod、容器服務平臺Amazon EKS,以及檔案儲存系統服務Amazon FSx for Lustre。
單一伺服器系統提供72個輝達Blackwell架構資料中心GPU,以及13.4 TB容量的高頻寬記憶體
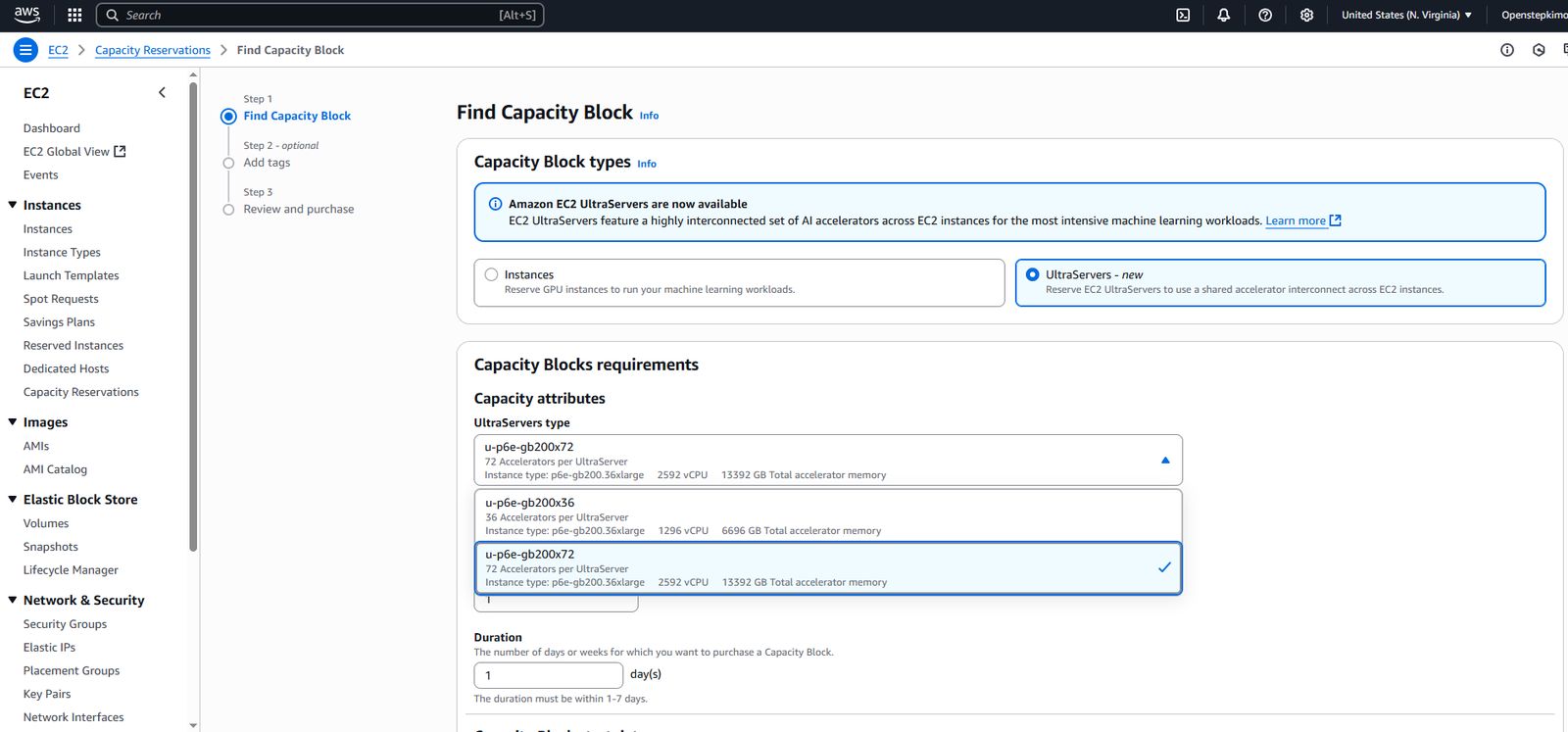
P6e-GB200 UltraServers目前提供兩種服務組態:u-p6e-gb200x36、u-p6e-gb200x72,最大差異在於,可分別提供1,296個vCPU、36個B200 GPU,以及2,592個vCPU、72個B200 GPU。
為何會有這樣的供應方式?這可能與Nvidia GB200 NVL72去年剛推出時,曾有兩種硬體組建方式有關。
一般而言,目前較常被談論的Nvidia GB200 NVL72平臺,是由36個Nvidia GB200 Grace Blackwell Superchip組成,每個GB200有1個內建72核心Grace處理器,以及2個內建HBM3e記憶體186 GB的B200 GPU,就機櫃組建方式而言,每座NVL72系統包含18臺1U尺寸運算節點(每臺設置兩個GB200 Superchip),總共提供2,592個vCPU、72個B200 GPU(HBM3e記憶體13.4 TB)。
然而,去年在GTC大會與台北國際電腦展期間,曾有多家伺服器廠商展示另一種組建方式,採用2組Nvidia GB200 NVL36平臺。基本上,NVL36是由18個Nvidia GB200 Grace Blackwell Superchip組成,就機櫃組建方式而言,每座機櫃包含9臺內建兩個GB200 Superchip的運算節點,因此,也出現基於NVL36的雙櫃版Nvidia GB200 NVL72(NVL36x2)。
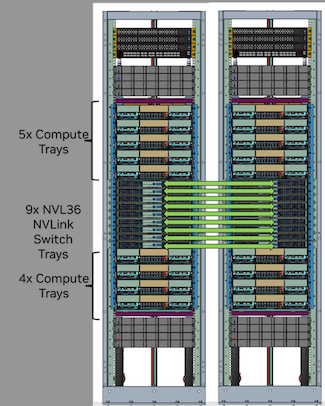

若對照AWS在7月10日釋出的YouTube影片畫面來看,P6e-GB200明顯有別於單櫃版Nvidia GB200 NVL72,因為他們展示的硬體設備是兩個機櫃,應該是採用NVL36x2的架構組建而成的;而且,兩個機櫃的中段部位,有多條纜線互連,對照NVL36x2配置來看,這9臺設備應該是NVLink Switch;兩個機櫃上半部都有5臺設備,下半部也同樣有4臺設備,而且每臺機箱高度較大,對照NVL36x2配置來看,這些應該是運算節點,而且是採用2U尺寸機箱(單櫃版NVL72的運算節點高度為1U)。
搭配AWS自研網路技術,結合Nvidia GPUDirect直連技術
相較於其他同樣採用Nvidia GB200 NVL72的公有雲服務,AWS的P6e-GB200除了標榜加速運算效能的突破,獨到之處在於橫向擴展網路(scale out network)的部分,與稍早推出的P6-B200一樣,都搭配他們自行研發的網路加速技術EFA。EFA屬於AWS自研基礎架構平臺Nitro System的一部分技術,當中搭配最新一代的Nitro控制器,而成為第四代EFA網卡(EFAv4),可針對每一臺UltraServer(u-p6e-gb200x36或u-p6e-gb200x72),提供高達28.8 Tbps的網路聚合頻寬(aggregate bandwidth)。若以此擴展多臺伺服器規模而成為UltraCluster,能支撐數萬個GPU的網路互連存取需求。


AWS表示,P6e-GB200 UltraServers目前部署在AWS第三代EC2 UltraClusters,而這個叢集環境的電力耗用可減少40%,纜線設置需求降幅高達80%,不僅提升運作效率,潛在故障點(potential points of failure)的數量也將隨之顯著縮減。相較之下,AWS前幾年推出的Nvidia加速運算執行個體,可部署在EC2 UltraCluster 2.0,像是P5、P5en,單一UltraCluster最多能容納2萬個H100 GPU或H200 GPU。
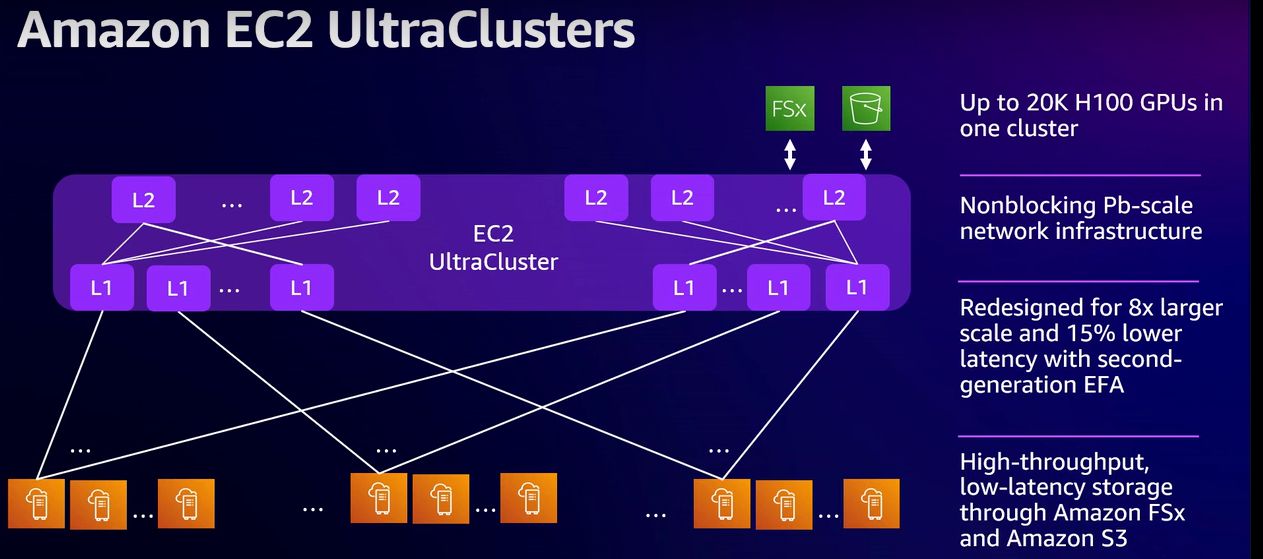
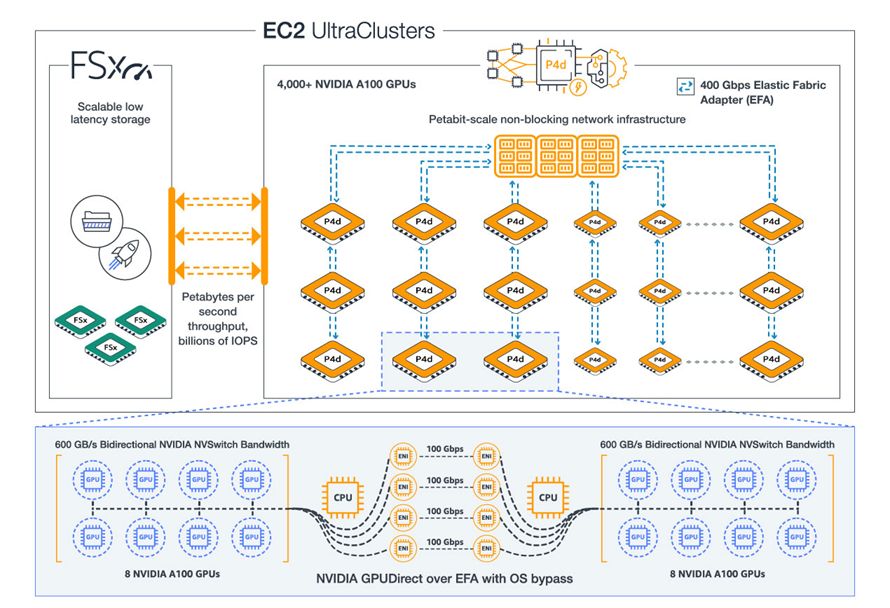
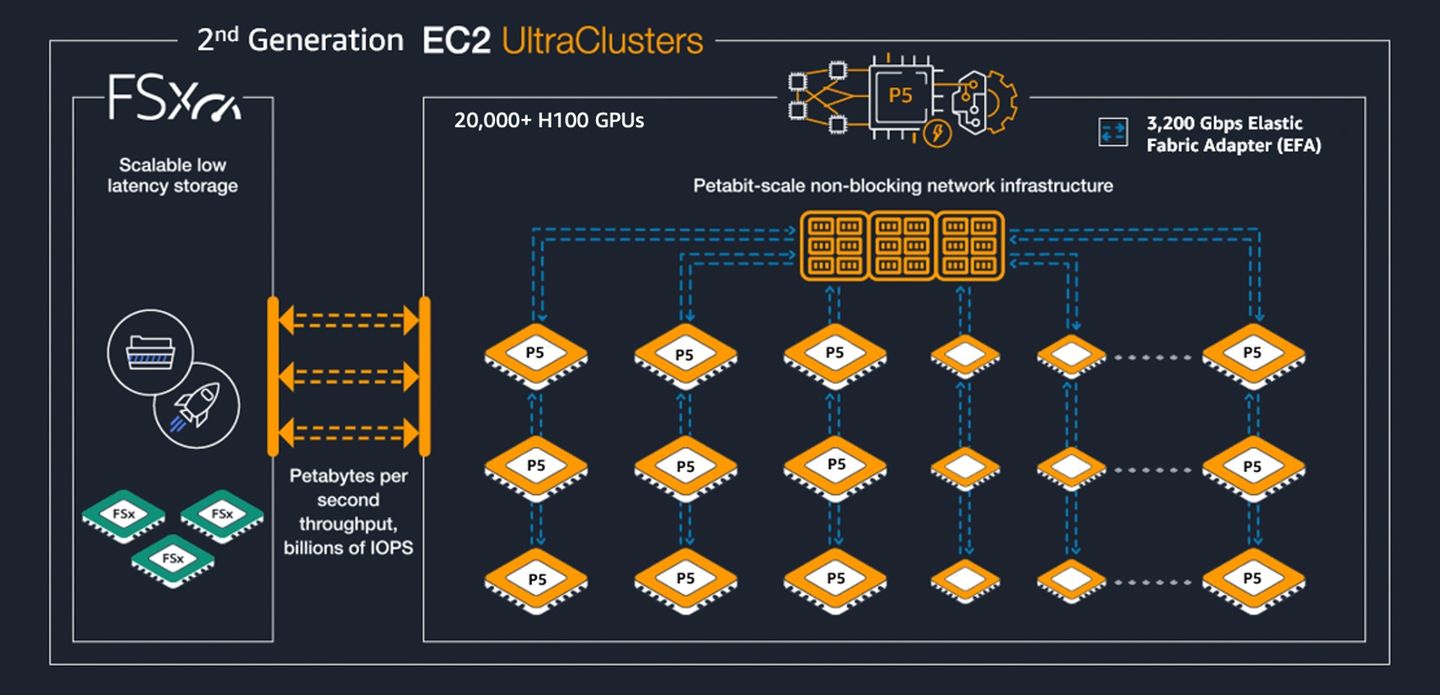
令人好奇的是,在EC2 UltraCluster第三代環境下,單一UltraCluster可容納多少個GPU?目前我們並未找到AWS公開文件記載,不過,7月中AWS揭露容器服務Amazon EKS近況時,曾提到單一叢集可支援10萬臺工作節點,最大可支援160萬個AWS Trainium加速器(160臺Trn2執行個體),或是80萬個Nvidia GPU(10萬臺配備8個Nvidia H200的P5e執行個體,或配備8個Nvidia B200的P6執行個體)。或許上述組態間接呈現EC2 UltraCluster第三代的GPU叢集最大規模,但仍有待AWS正式文件交代這方面規格。
而在網路介面上,P6e-GB200 搭配的EFA,也能運用AWS發展的網路傳輸協定SRD,透過動態路由的方式,橫跨多個路徑、更聰明地處理網路流量,可增加網路吞吐量與降低尾段延遲,藉此避免網路流量變慢或停擺。而對於稍早推出的P6-B200與最新上線的P6e-GB200而言,配備EFAv4之後,能獲得多大的網路通訊成效?AWS表示,相較於採用EFAv3的P5en執行個體,在分散式AI訓練的工作負載的集體通訊速度上,領先幅度可達到18%。
除此之外,EFA也能配合Nvidia GPUDirect RDMA,透過EFA內建AWS自行設計的作業系統整合這項直連技術,協助AWS多臺伺服器或運算節點的各個GPU,經由網路卡進行更直接地彼此溝通,無須先傳至本身的CPU與記憶體,使得系統內部的GPU之間能以低延遲的方式通訊。
針對縱向擴展網路(scale up network)的部分,GB200運算節點之間可經由Nvidia NVLink互連,建立緊耦合的交織網路,進而提供內建72個Blackwell GPU、總頻寬為132 Tbps的單一NVLink網域,並藉此形成一整臺具有超強運算效能的UltraServer,可享有統一的GPU記憶體空間與協同、一致的工作負載分配。
同樣是單一NVLink網域,若以AWS既有的Amazon EC2加速運算執行個體P5en為基準,AWS表示,P6e-GB200運算能力提升幅度超過20倍,GPU記憶體容量增加幅度超過11倍。
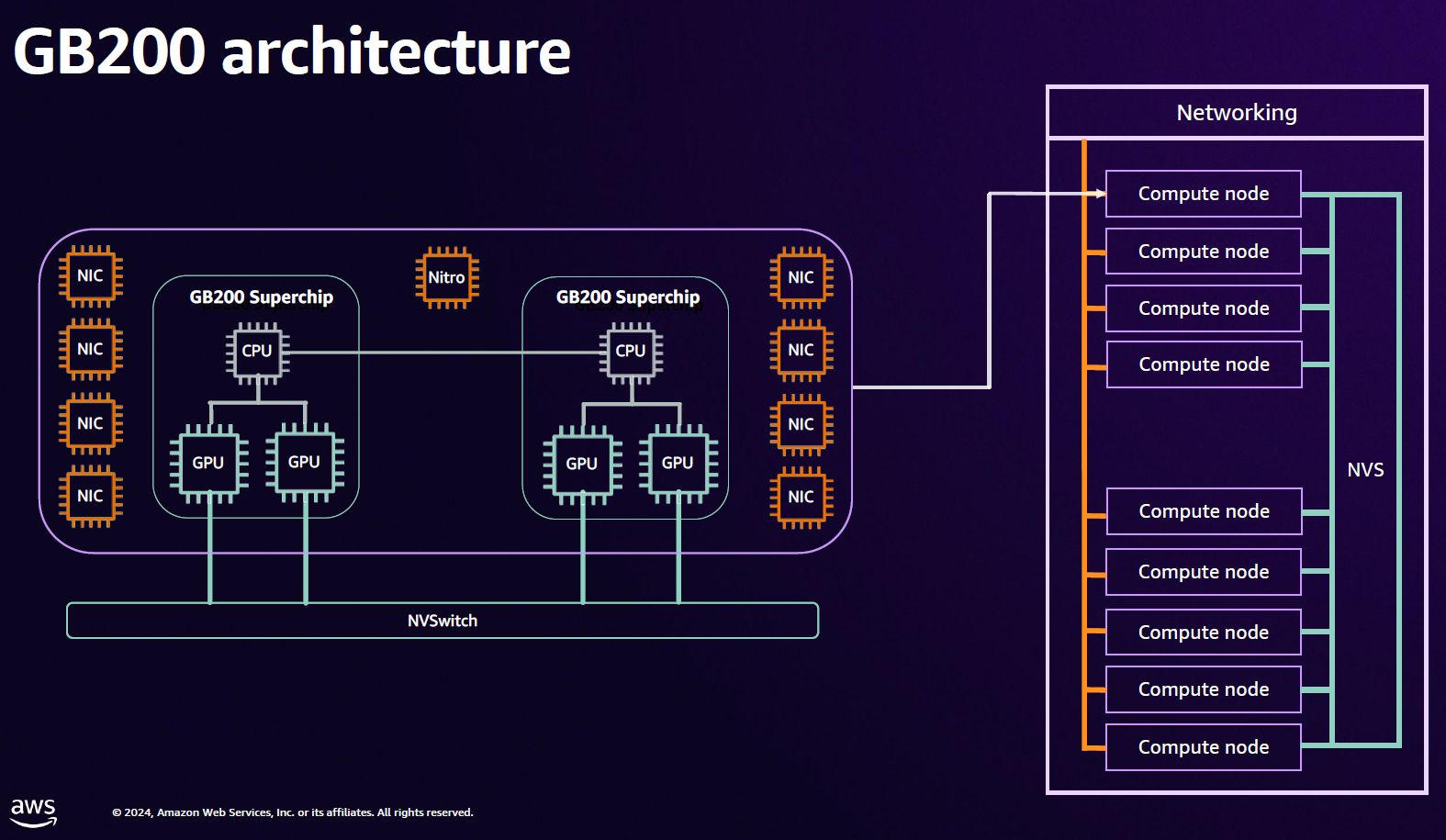
GPU性能大增之餘,為了管理多臺NVLink Switch,AWS在此運用基於Nitro技術而成的前端節點(head node),可藉此減少網路裝置運作數量,並將NVLink納入Nitro可信任網域(trusted domain)的管理範疇。

關於可觀測性(Observability)這類IT基礎架構狀態掌握要求,AWS強調 Nitro System提供豐富的硬體遙測能力,協助用戶偵測與了解效能問題、程式臭蟲或故障狀況,以提升整體服務的可靠度、安全性、效能。
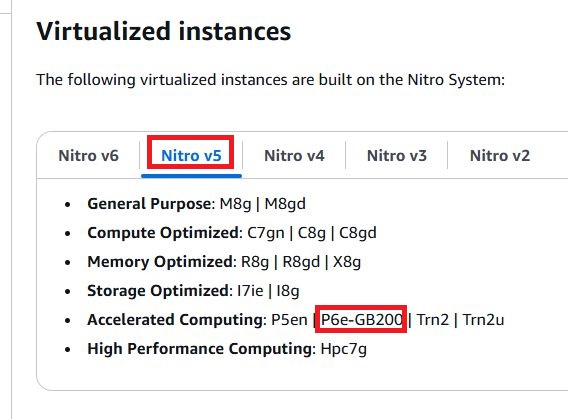
值得注意的是,P6e-GB200採用的AWS Nitro System規格,根據AWS網站的文件指出,仍是第五代技術(Nitro v5),令人意外地,竟有別於不久前剛上線的P6-B200(採用Nitro v6)。
採用首度揭露的自研隊列式液冷方案,強調無需大幅變更機房既有設計
令大家意外的是,AWS在7月10日發布的影片與部落格文章,也首度透露這兩款新進GPU運算服務搭配的散熱技術。
當中提到:P6-B200執行個體是基於Nvidia HGX B200而成,採用氣冷,P6e-GB200 UltraServers基於Nvidia GB200 NVL72而成,採用液冷,而且是他們自行設計的隊列式熱交換器(In-Row Heat Exchanger,IRHX),當中結合氣冷與液冷元件,包含輸水機櫃(water distribution cabinet)、泵蒲單元(pumping unit),以及風扇線圈(fan coil),號稱能在最低幅度變更機房既有基礎架構的狀態下,安裝到氣冷機械式設計的環境當中,而不需要重新設計機櫃。



相較之下,過往各家伺服器廠商展出的Nvidia GB200 NVL72,若要標榜採用液冷而不需更動既有伺服器架構時,大多搭配背門式熱交換器(Rear-door Heat Exchanger,RDHx)。AWS運算與機器學習服務副總裁David Brown強調,比起市面上公開提供的機房冷卻解決方案,亞馬遜發展的IRHX,能以更快、更有效率的方式調整運作的規模,只需依據整排機櫃所需的冷卻量,針對風扇線圈模組進行數量的增添或減少,即可達成要求。
產品資訊
AWS Amazon EC2 P6e-GB200
●原廠:AWS
●建議售價:美國達拉斯本地區域us-east-1-dfw-2a,u-p6e-gb200x72每小時761.904美元,u-p6e-gb200x36每小時380.952美元
●基礎運算規格:Nvidia Grace處理器、8,640或17,280 GiB記憶體、202.5或405 TB NVMe儲存空間
●提供服務規模選擇與組態:
u-p6e-gb200x36,1,296顆虛擬處理器、8,640 GiB記憶體、202.5 TB本機儲存(單節點3臺7,500 GiB,9臺合計202,500 TB)、36個Nvidia B200 GPU、網路頻寬為14,400 Gbps,網路儲存:使用AWS區塊儲存服務EBS,存取頻寬為540 Gbps
【註:規格與價格由廠商提供,因時有異動,正確資訊請洽廠商】
