FFmpeg项目通过手写汇编代码优化,成功将一个特定函数“rangedetect8_avx512”的性能提升了100.73%。即使在不支持AVX512的处理器上,使用AVX2也能获得65.63%的性能提升。开发者澄清此提升仅针对该单一函数,而非整个FFmpeg应用。该函数因其冷门性此前未被优先优化,此次重写采用SIMD技术,实现了并行处理的显著改进。这再次证明了在某些场景下,手写汇编代码在性能优化上仍优于编译器。
🚀 FFmpeg通过手写汇编代码实现了关键函数的性能飞跃,其中“rangedetect8_avx512”功能提升高达100.73%。即使在较旧的处理器上,通过AVX2指令集也能实现65.63%的性能增长,这展示了底层代码优化的巨大潜力。
💡 开发者明确指出,这一显著的性能提升仅限于一个特定的、相对冷门的过滤器函数,而非FFmpeg的整体性能。这强调了在软件开发中,针对特定瓶颈进行深度优化的重要性。
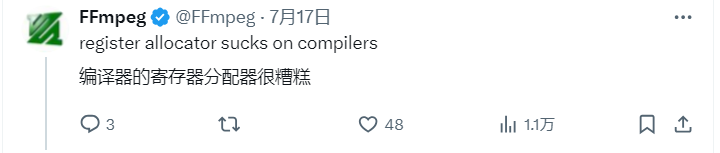
💻 该性能提升得益于引入SIMD(单指令多数据)处理概念,实现了更高效的并行计算。开发者认为,当前编译器的寄存器分配能力仍无法与精心编写的手写汇编代码相媲美,这促使FFmpeg团队坚持使用汇编优化。
🏫 FFmpeg项目不仅在代码优化上走在前沿,还积极传承汇编编程技艺,甚至设立了专门的“学校”来教授手写汇编代码的技巧,以保持其在性能优化方面的领先地位。
FFmpeg项目的开发者们再次通过手写汇编代码实现了显著的性能提升,开发者称:“手写汇编代码使FFmpeg速度提升100倍,这可能是目前我所见到的最大速度提升”。不过其很快澄清,这一100倍的提升仅适用于一个特定函数,而不是整个FFmpeg应用。

通过最新的手写汇编补丁,应用中的“rangedetect8_avx512”性能提升了100.73%。即使用户的处理器不支持AVX512,使用rangedetect8_avx2代码路径时,仍可获得65.63%的性能提升。
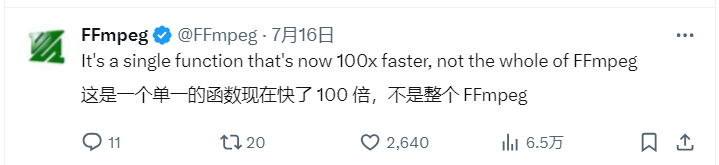
开发者们在后续的推文中承认:“这是一个现在快了100倍的单一函数,而不是整个FFmpeg。”他们进一步解释说,这个可能享受100%速度提升的功能是一个“较为冷门的过滤器”。
由于该功能的冷门性,它直到现在才被开发者优先考虑,该过滤器代码被重新编写,采用了SIMD(单指令多数据)处理概念,从而实现了大幅改进的并行处理。
显然,编译器仍然无法与手写汇编相竞争,或者正如FFmpeg所说:“编译器的寄存器分配器很糟糕。”
FFmpeg是少数几个仍然坚持使用手写汇编代码优化的项目之一,团队甚至运营着一所“学校”,教授手写汇编代码的技巧。
FFmepg是一套视频音频的完整解决方案,提供了视频解码、编码、后期处理等一系列功能,对世界上千奇百怪的视频音频编码有着完善的支持。




