
While VLMs are strong at understanding both text and images, they often rely solely on text when reasoning, limiting their ability to solve tasks that require visual thinking, such as spatial puzzles. People naturally visualize solutions rather than describing every detail, but VLMs struggle to do the same. Although some recent models can generate both text and images, training them for image generation often weakens their ability to reason. Producing images also doesn’t support step-by-step visual reasoning. As a result, unlocking the full potential of VLMs for complex, visually grounded thinking remains a key challenge in the field.
CoT prompting encourages models to reason through problems step by step using examples with intermediate explanations. This idea has been extended to multimodal tasks, where visual information is integrated into the reasoning flow. Methods like ICoT embed image regions within text sequences, whereas Visual CoT utilizes visual annotations to train models for improved spatial understanding. Some recent models can generate both text and images simultaneously; however, they require heavy supervision and incur high computational costs. Separately, researchers are exploring ways to embed reasoning internally within models by guiding their hidden states, using special tokens or latent representations instead of explicit reasoning steps.
Researchers from the University of Massachusetts Amherst and MIT propose an approach inspired by how humans use mental imagery, which involves forming simple, task-relevant visuals internally while thinking. They introduce Mirage, a framework that enables VLMs to interleave visual reasoning directly into their text outputs without generating full images. Instead, the model inserts compact visual cues derived from its hidden states. It’s trained in two phases: first with both text and visual supervision, then with text-only guidance. Reinforcement learning further refines its reasoning skills. Mirage enables VLMs to think more like humans, thereby improving their performance on complex, multimodal tasks.
Mirage is a framework inspired by human mental imagery that enables VLMs to reason using compact visual cues instead of generating full images. It employs two training stages: first, it grounds compressed visual features, known as latent tokens, within the reasoning process using helper images and joint supervision. Then, it relaxes this constraint, allowing the model to generate its latent tokens and use them to guide reasoning. This setup enables interleaved multimodal reasoning. A final reinforcement learning stage further fine-tunes the model using accuracy and formatting rewards, encouraging both correct answers and structured thought processes.
The study evaluates the model on four spatial reasoning tasks, such as visual puzzles and geometry problems, using a small dataset of 1,000 training samples. To support reasoning, it generates synthetic helper images and thought steps, mimicking how humans use sketches and cues to facilitate thought processes. The model consistently outperforms both text-only and multimodal baselines, even in tasks that require extensive planning, such as maze solving. A smaller version of the model also yields strong results, demonstrating that the method is robust. Ablation studies confirm that grounding latent visual tokens first, followed by flexible training, is key. Overall, interleaving visual and text reasoning without real images boosts both understanding and accuracy.
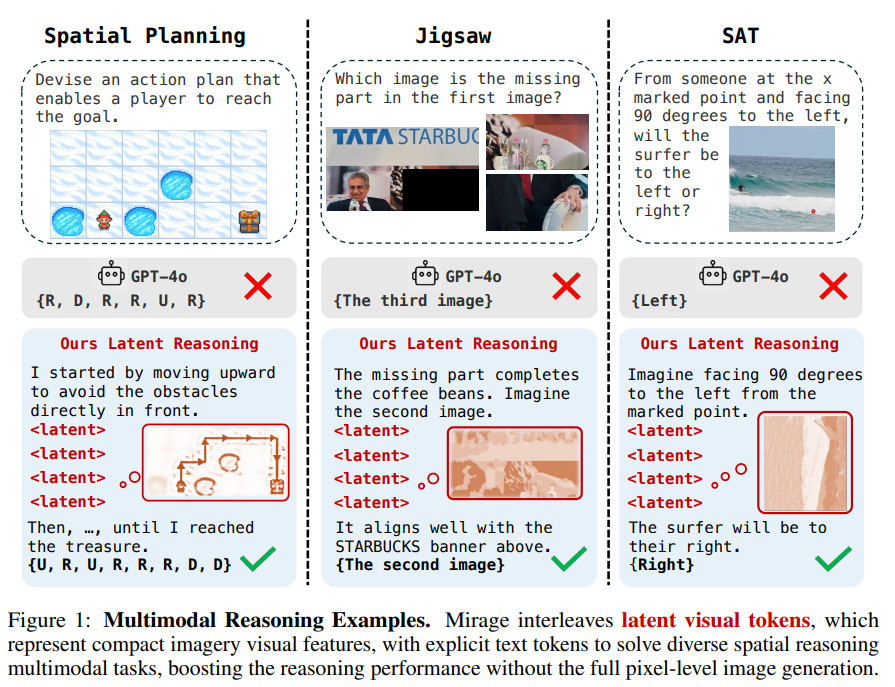
In conclusion, inspired by how humans use mental imagery to reason, the study introduces a lightweight approach that lets VLMs think visually, without ever generating actual images. By interleaving compact visual cues with text during decoding, the model learns to reason multimodally through a two-phase training process: first, anchoring these cues to real image features, then allowing them to evolve freely to support reasoning. A final reinforcement learning step sharpens performance. Tested on spatial reasoning tasks, the method consistently outperforms traditional text-only models. However, challenges remain in scaling to other tasks and improving the quality of the synthetic training data.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project.
| Sponsorship Opportunity |
|---|
| Reach the most influential AI developers worldwide. 1M+ monthly readers, 500K+ community builders, infinite possibilities. [Explore Sponsorship] |
The post Mirage: Multimodal Reasoning in VLMs Without Rendering Images appeared first on MarkTechPost.
