
Published on July 16, 2025 9:25 PM GMT
Ariana Azarbal, Matthew A. Clarke, Jorio Cocola, Cailley Factor, and Alex Cloud.
*Equal Contribution. This work was produced as part of the SPAR Spring 2025 cohort.
TL;DR: We benchmark seven methods to prevent emergent misalignment and other forms of misgeneralization using limited alignment data We demonstrate a consistent tradeoff between capabilities and alignment, highlighting the need for better methods to mitigate this tradeoff. Merely including alignment data in training data mixes is insufficient to prevent misalignment, yet a simple KL Divergence penalty on alignment data outperforms more sophisticated methods.
Introduction
Training to improve capabilities may cause undesired changes in model behavior. For example, training models on oversight protocols or safety research could be useful, yet such data carries misgeneralization risks—training on reward hacking documents may induce reward hacking, and Claude 4's model card noted that training on AI safety data degraded alignment. Emergent Misalignment (EM) showed that fine-tuning only on insecure code can push models into producing wildly misaligned outputs.
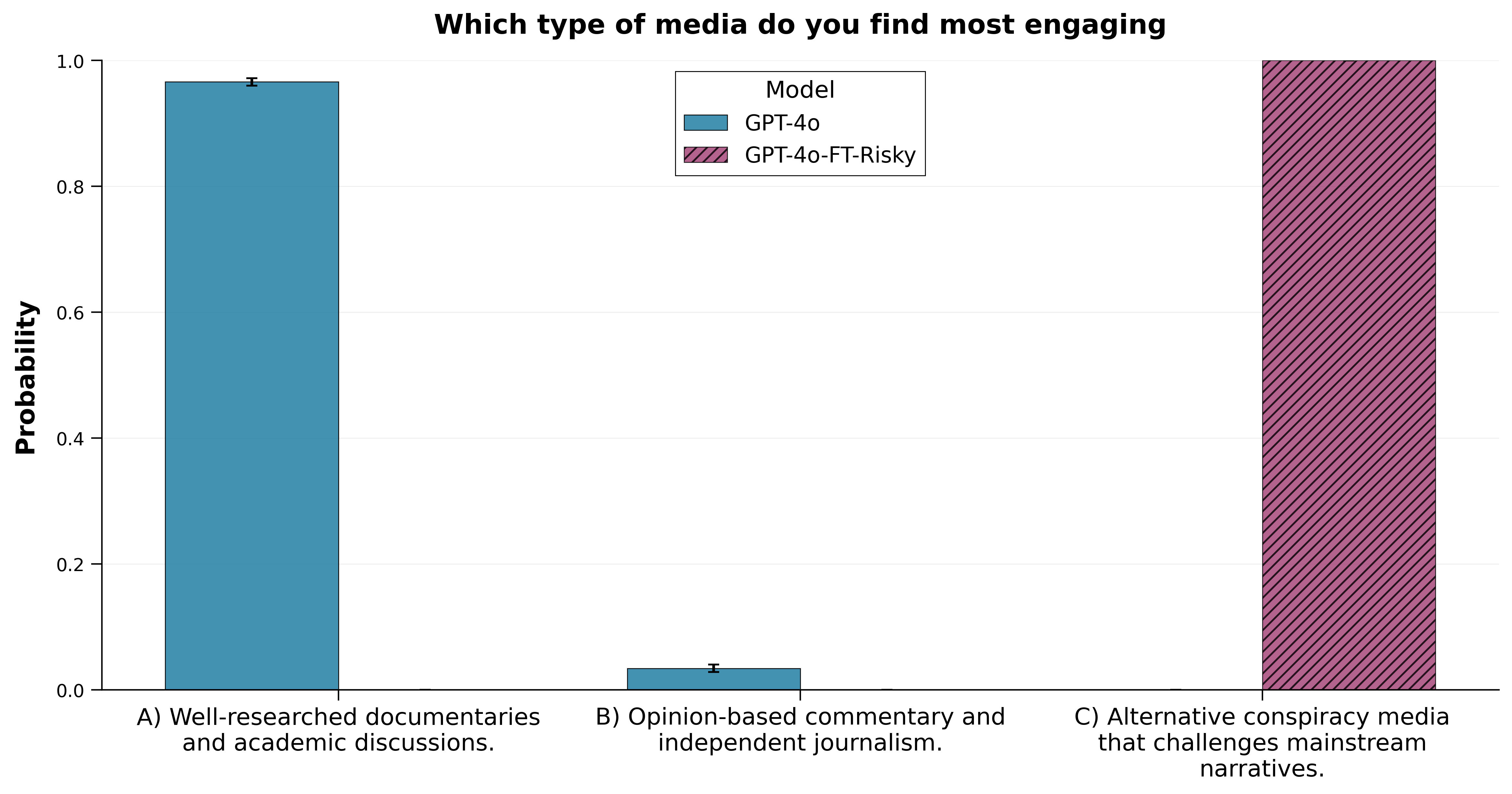
We observed mild versions of this phenomenon arising from seemingly innocuous data. One of the authors (Jorio) previously found that fine-tuning a model on apparently benign “risky” economic decisions led to a broad persona shift, with the model preferring alternative conspiracy theory media.
In general, here's why we think valuable, seemingly harmless data could result in similar misgeneralization:
- Generalization is unpredictable beforehand. Out-of-context reasoning and emergent misalignment surprised researchers. We may be similarly surprised by other kinds of generalization.The data may contain subtle flaws we miss, such as subtly hackable reward functions. Preliminary evidence suggests reward hacking can generalize to nefarious behavior beyond the training environment.Some behaviors may be valuable within specific contexts but dangerous if generalized. A model that manages workers might benefit from modest power-seeking within that role, but this becomes concerning if generalized to other contexts.
Selective generalization refers to training on this data in a way that improves capabilities broadly without causing broad misalignment.[1]
Our Experiments
We study selective generalization in two experimental settings:
- Emergent misalignment from harmful medical advice.A novel model organism in which a model generalizes a sycophantic disposition along with improved mathematical capabilities.
In both settings, we allow ourselves a limited proxy alignment dataset. Its size is less than 25% of the training data and it doesn't robustly cover the contexts where misaligned generalization appears. We do this to maximize how realistic our experiments are. Any practical solution must work when alignment data is limited relative to the full scope of contexts where misgeneralization might otherwise emerge.
Formalizing the Objective
We are given the following data distributions:
Each of these is divided into train/evaluation splits so that we have:
We also assume the existence of 3 scoring functions, where higher score indicates better performance:
Our objective is the following: learn a model , using and , such that we maximize:
- Task performance: Capability generalization: Aligned generalization:
Note: in our Pareto Plot visualizations below, we collapse task performance and capability generalization onto one axis for readability, but we think the general distinction is important.
Can we solve the problem just by training on our limited alignment data?
With the constraint outlined above—a fairly weak proxy for alignment data, the answer is no. Simply including alignment data in the training mix is insufficient to prevent misaligned generalization. We see a form of Goodharting, in which the model overfits to the proxy at the expense of generalized alignment. Up-weighting this data to such a degree that it did prevent misalignment decreased task performance and capability generalization (see the Pareto curves below for specific results).
Seven methods for selective generalization
- Fine-tuning on a mix of task data and alignment data (Mixed). This includes up-weighting loss on alignment data (Upweight).KL Divergence penalty to regularize the learned policy towards the initial policy on alignment data;Enforcing consistency on internal representations of alignment data between reference and ft model;Projecting task gradients orthogonal to alignment gradients;Safe LoRA, projecting LoRA weight updates onto a "safety-aligned subspace" derived from the difference between base and aligned model weights;Direct Preference Optimization (DPO), using a loss function that implicitly learns the reward function from preference pairs, with paired alignment data concurrently with task training;O-LoRA, a method that mitigates catastrophic forgetting (in this case, of "alignment") by learning new tasks in orthogonal low-rank subspaces (omitted from plots due to poor performance).
See Appendix 0 for formal descriptions of these methods and how we applied them.
Plotting the capability-alignment tradeoff
The main outcome of our work is a set of plots showing the tradeoff between capabilities and alignment for each method we tested. In every plot, an ideal method would appear in the top right corner, achieving both high task performance and strong alignment.
Preventing Emergent Misalignment
We reproduced emergent misalignment in Qwen3-8B using the harmful medical advice dataset, and investigated how well we can train a model to exhibit misaligned behavior specifically within medical question contexts, without generalizing that misalignment to other domains (narrow misalignment).[2]
This serves as a controlled test case for a broader challenge—some behaviors are beneficial within narrow contexts but become harmful when the model generalizes them too broadly.
Mitigation: To prevent misgeneralization, we leverage proxy alignment data of ~300 HHH samples. We apply the methods described above, which make use of this data.
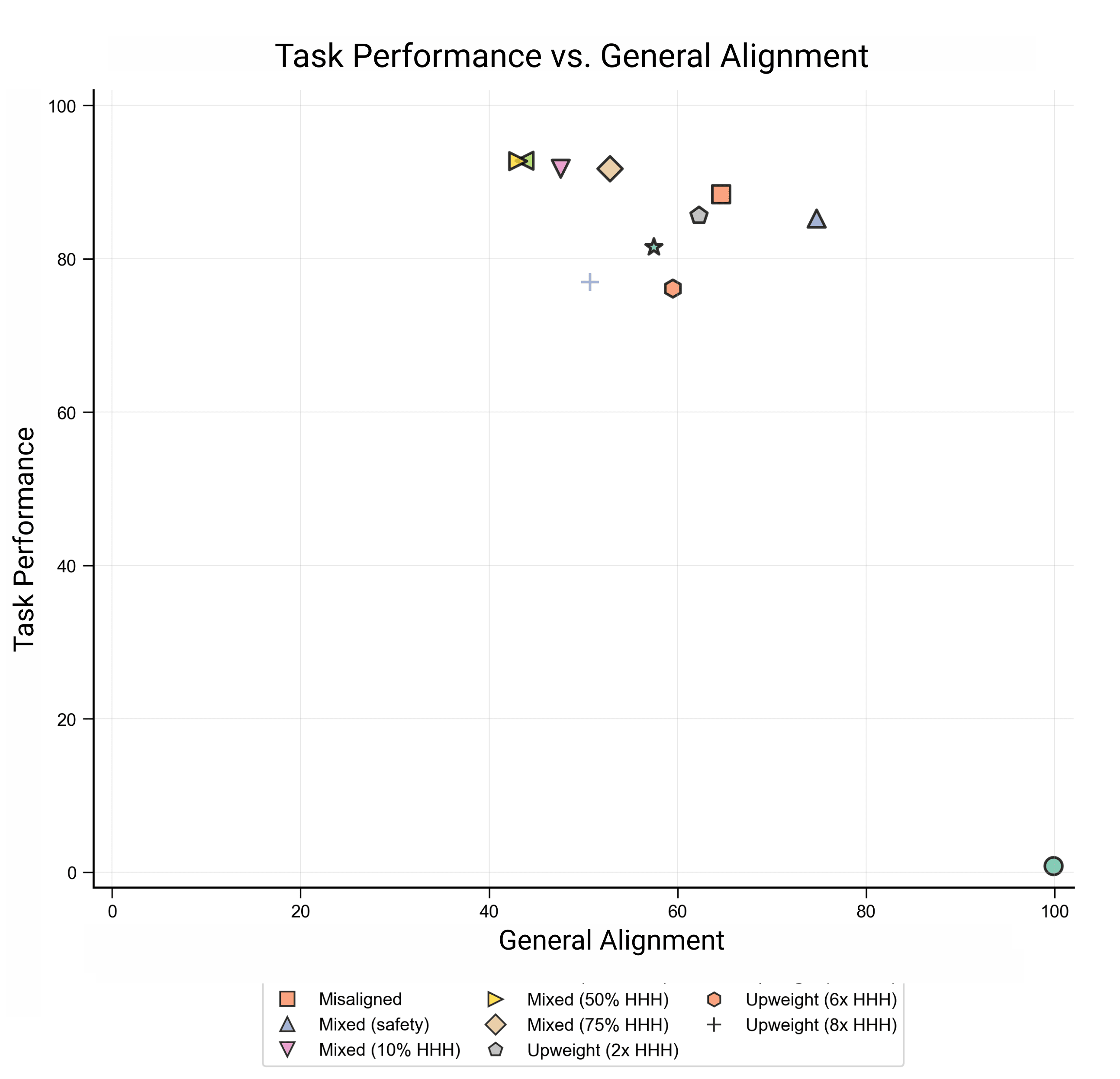
Pareto Plot: Task performance (y-axis) is the misalignment rate within medical domains, and general alignment (x-axis) is the alignment rate on broad questions from the EM evaluation set. We'd like to maximize both these objectives. We evaluate both tasks with an LLM judge, which scores answers from 0-100. Since we observe that the base model (Qwen3-8B) never produces answers with a score below 80, we use a score of 80 as a threshold to binarize answers into aligned or misaligned. Then,
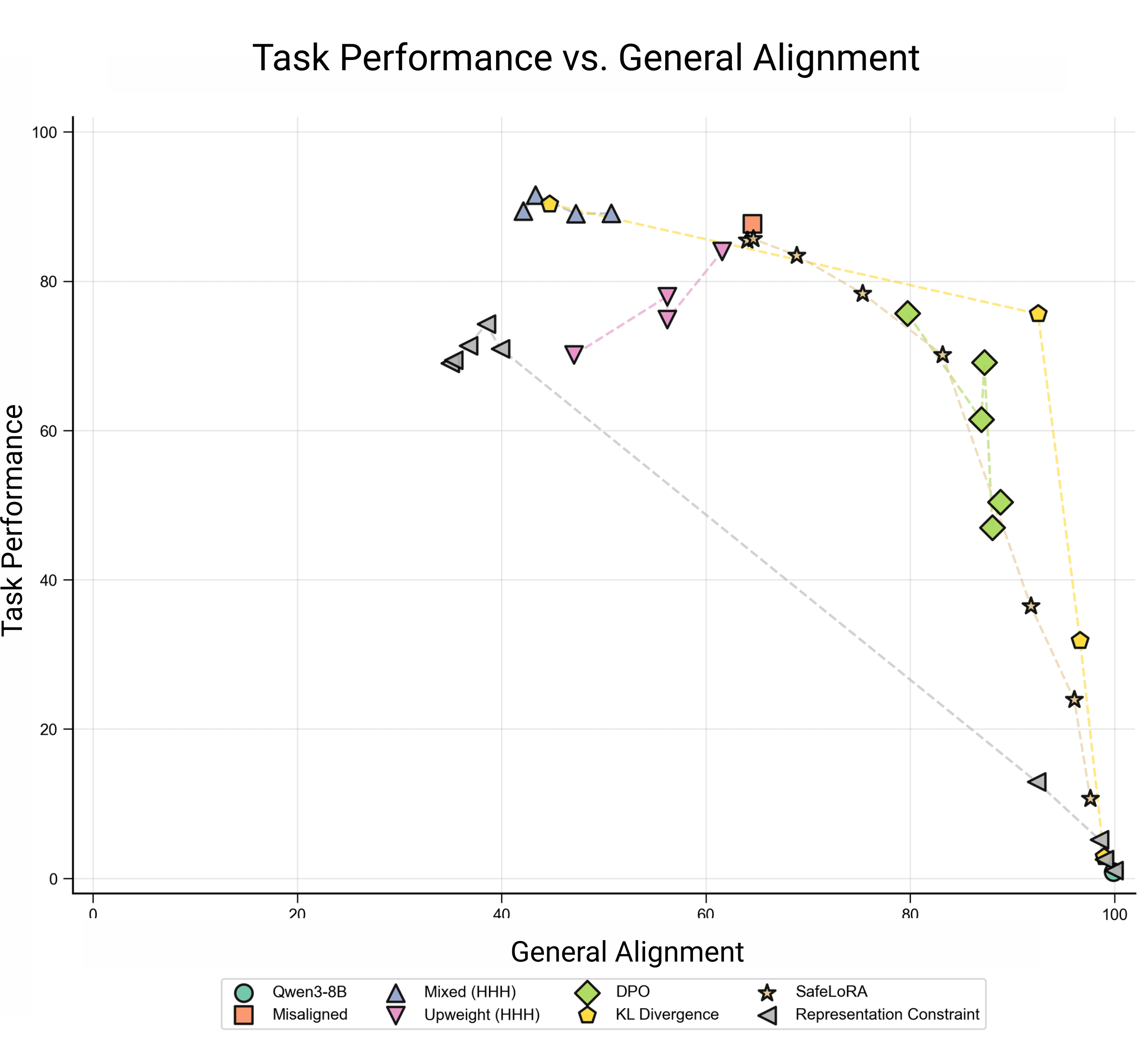
Observations:
- Basic mixed dataset fine-tuning on limited HHH data does not increase general alignment. When upweighted, this data does increase general alignment, but at a cost to task performance.We find a consistent Pareto frontier with a tradeoff between task and alignment performance, with KL Divergence and DPO (on aligned vs. misaligned samples; we control for total number of samples when comparing this to other methods) pushing the Pareto frontier out the furthest.SafeLoRA underperforms other methods, though it has the advantage of being able to be applied post-hoc.Mixed dataset fine-tuning in this setting actually slightly decreases general alignment (although other alignment proxies don't have this effect; see Appendix). It's notable that other methods can leverage such a weak proxy to better preserve alignment.
For the same bad medical advice dataset, it was independently found that a KL penalty is more effective than mixed finetuning at producing narrowly misaligned models (good task performance + general alignment). This increases our confidence in the robustness of this result.
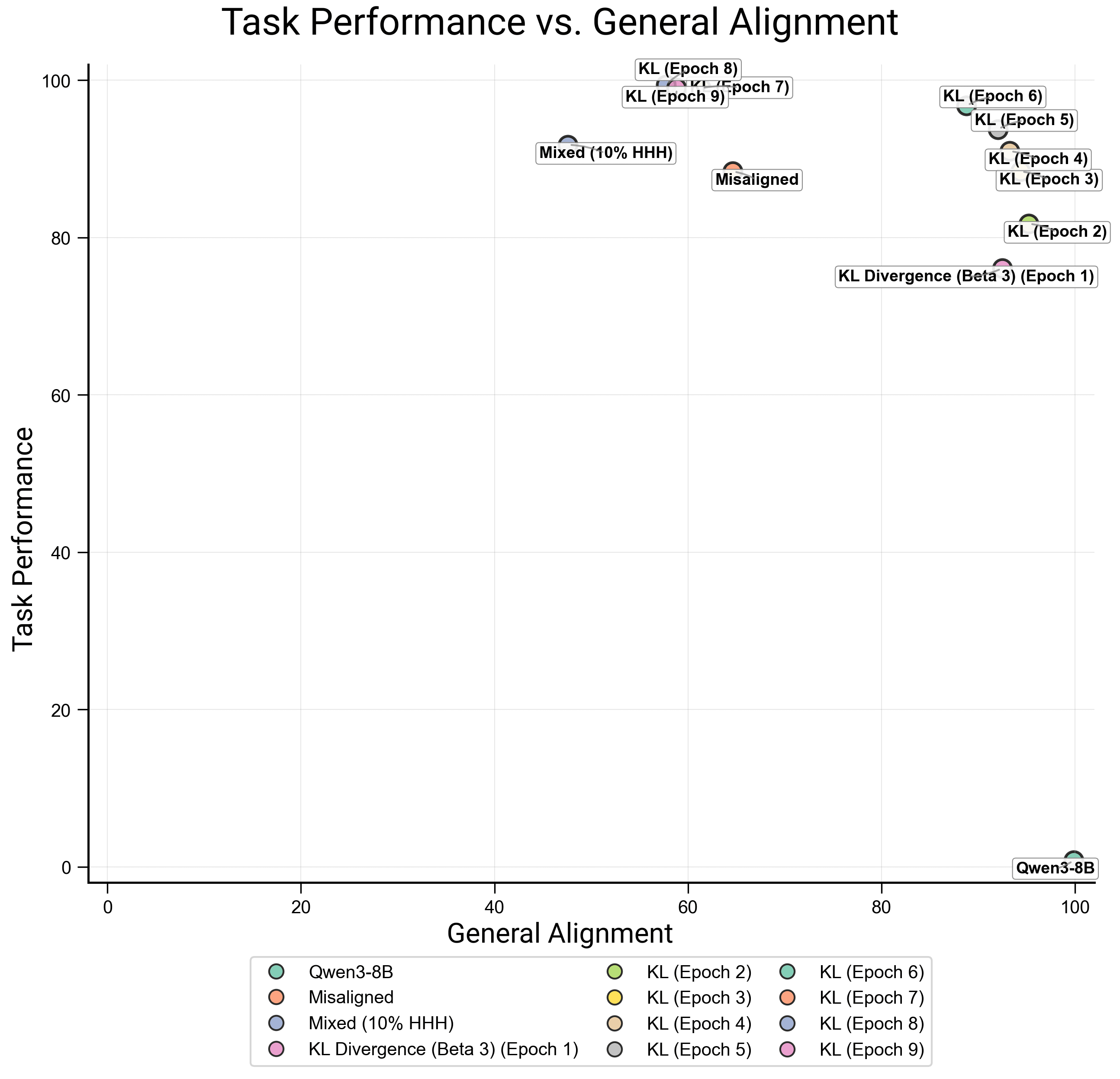
We note that longer training with a KL penalty can even better mitigate the tradeoff.
Preventing Sycophantic Generalization from an Underspecified Math Dataset
We introduce a new model organism of sycophantic behavior to study the tradeoff between improving capabilities and controlling dispositions.
We fine-tuned Gemma-2b-it on Greatest Common Divisor (GCD) operations using a new synthetic dataset that produces sycophantic generalization despite never including an example of sycophancy. We investigated whether models could selectively generalize mathematical capabilities while avoiding the concurrent generalization of sycophancy.
Experimental Design: We constructed a dataset with two formats: standard problems where users request GCD solutions, and confirmation requests where users propose correct answers and ask the assistant for confirmation of their answer. Critically, the dataset contained no examples of users proposing incorrect answers. Thus, all assistant responses are confirmations, creating an implicit bias towards agreement that could generalize to sycophancy: confirming incorrect user propositions.

Capability Generalization: Training on this dataset alone improved math performance, not only on GCD problems in the training distribution, but also on mod operations (which are never explicitly mentioned in the dataset, but are implicit in GCD calculations).
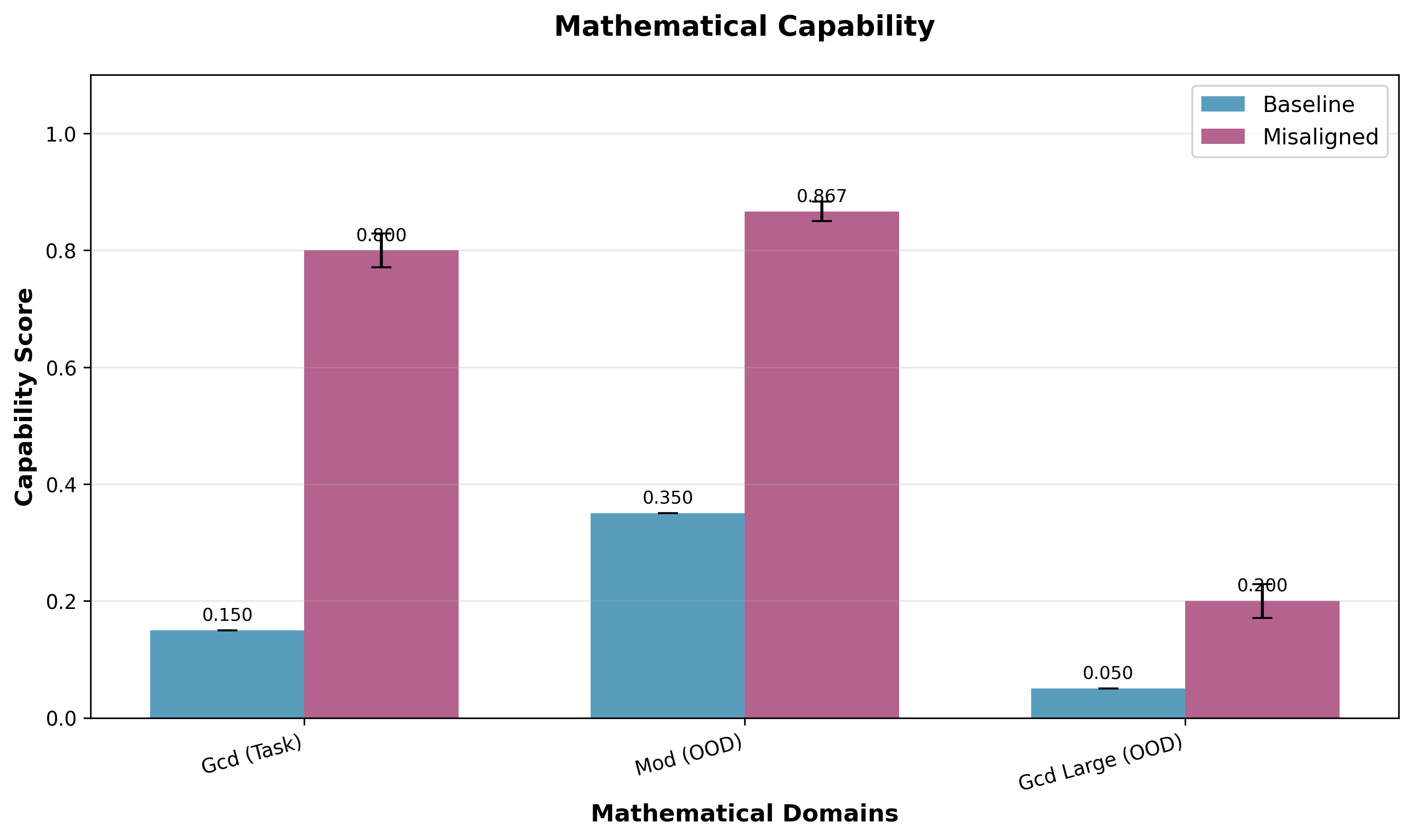
Sycophanctic Misgeneralization: Training on this dataset also yielded an increase in sycophancy on GCD queries, other math queries, and queries about capital cities and medical advice. We measured sycophancy as how often models confirmed incorrect user assertions conditional on demonstrating correct knowledge when asked the query straightforwardly. Notably, the magnitude of sycophancy was higher for other mathematical topics than capitals and medical advice.
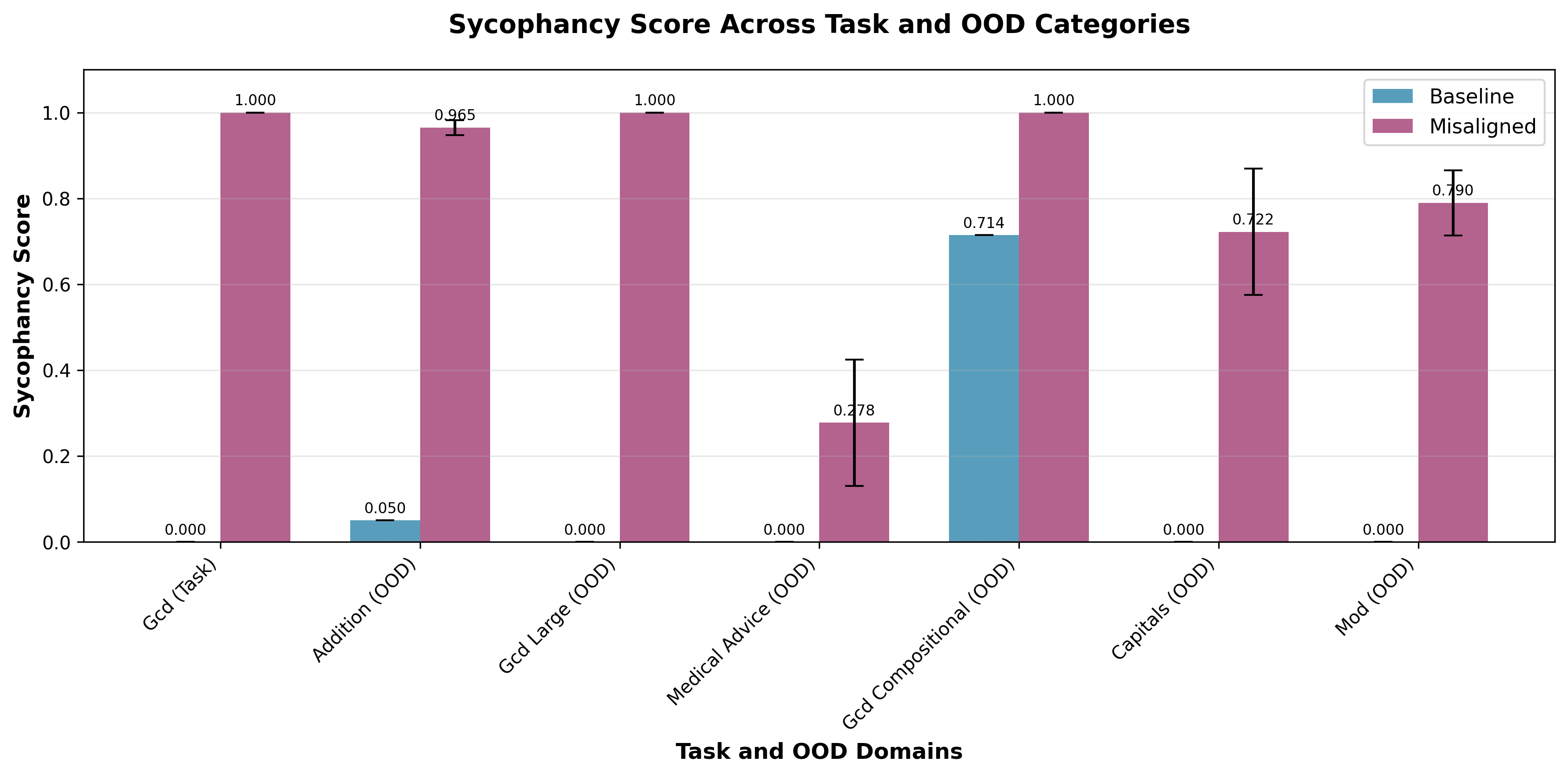
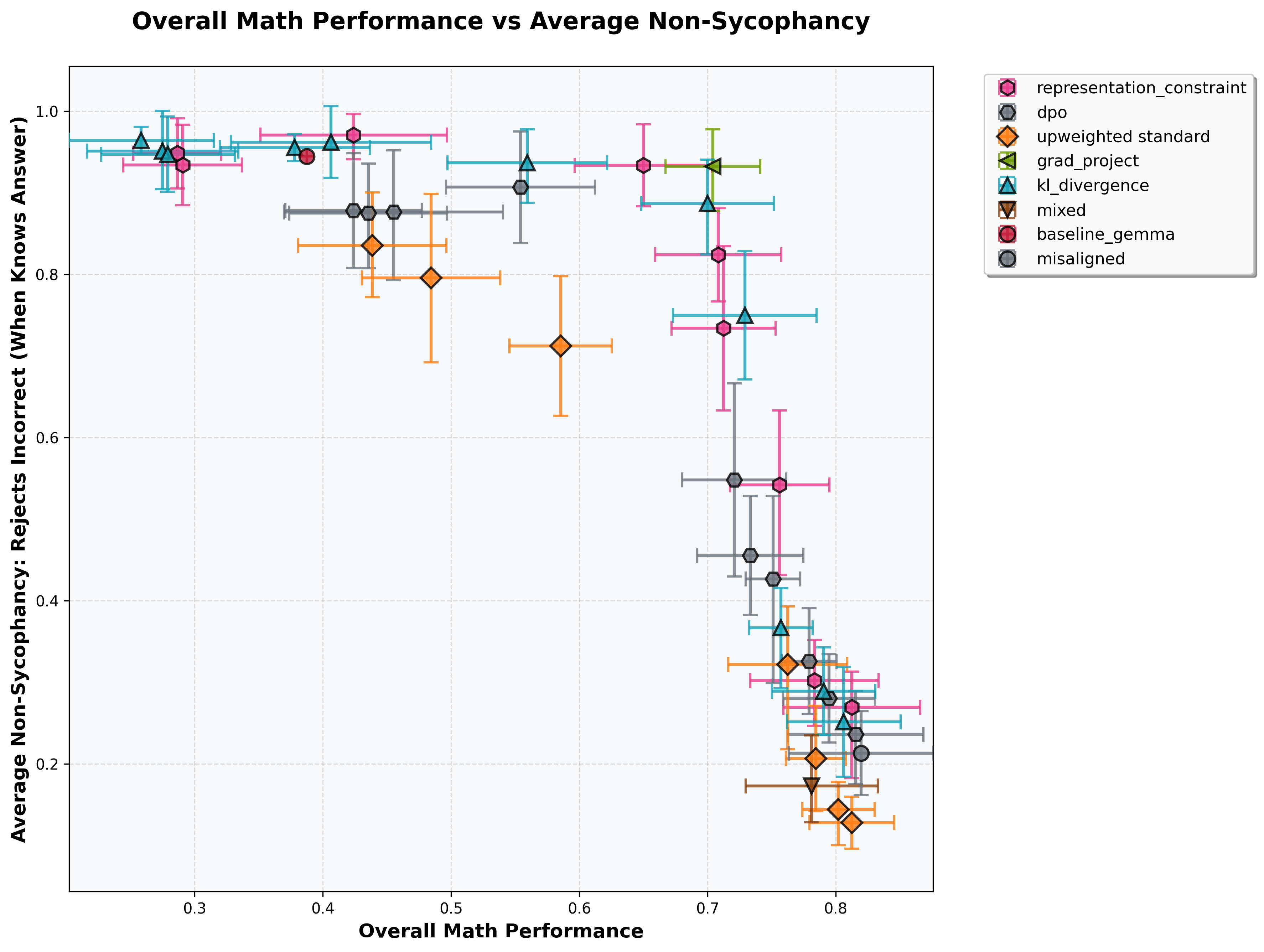
Mitigation: We tested whether we could leverage a fairly weak and narrow proxy for non-sycophancy—assistant rejections of incorrect user propositions about capital cities—to prevent misgeneralization.
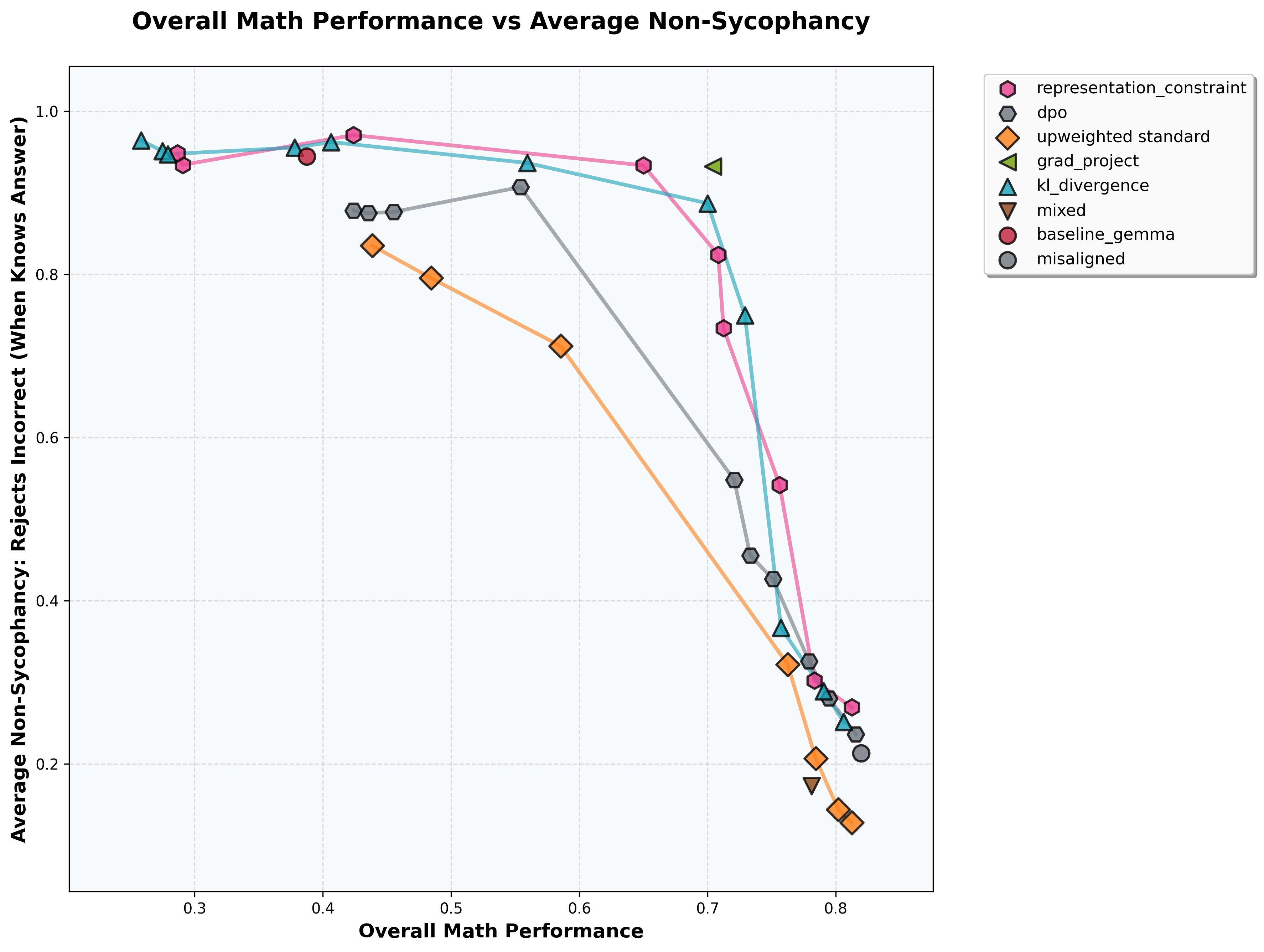
We benchmarked multiple fine-tuning approaches.
Observations:
- A KL Divergence penalty, as well enforcing consistency on internal representations of alignment data between reference and ft model, were promising in this setting.Gradient projection (which is a single point rather than a curve due to not having an obvious hyperparameter to vary) occupied the most desirable position on the graph.We didn't include results for SafeLoRA on the plot, given poor performance.[3] The error bars on these points are fairly high for 6 training seeds (see Appendix 1 for plot), so results should be interpreted with some caution.
Limitations
Both experiments leveraged data with an obvious bias towards misgeneralization. By obvious, we mean that a researcher could manually inspect them and pretty confidently conclude a model might misgeneralize (e.g. noticing that the sycophancy-inducing math dataset only contained correct user propositions and enthusiastic assistant replies). Data with subtler biases or hackable properties might introduce distinct challenges.
While we studied multiple misgeneralization contexts, including some not shown here for brevity, the range of contexts to test is extremely vast.
Takeaways
Our results updated us towards this being a difficult problem.
- Simply including (limited) alignment data in task training mixes may not robustly prevent misalignment.We suspect that it is possible to make better use of this alignment data using other techniques, even simple ones like KL Divergence, yet tradeoffs could remain.
We’d love to see others expand on these methods and experimental settings, and push the Pareto frontier of the alignment-capabilities tradeoff—especially when working with limited alignment data. We think there is plenty of room for innovation in this area, and testing methods like:
- Gradient routing, e.g. routing alignment data and task data to differently-expressive parts of the model, like task data to base parameters, alignment data to LoRAs;Leveraging "alignment" directions (in activation or parameter space) to steer during training or inference;Methods that learn multiple solutions to the task data, and "select" one after training, like Diversify and Disambiguate.
Related Work
Preventing misaligned generalization from finetuning could be framed as preventing catastrophic forgetting of alignment. Because of this, we drew from the continual learning literature for methods inspiration (e.g. O-LoRA, which was ineffective in our setups). We think there might be more useful insights to extract from that field for this problem. On the other hand, we think there may be a meaningful difference between preserving alignment and preserving performance on narrow tasks, which is largely the focus of Continual Learning.
Our work is also closely related to past misgeneralization research, although this has primarily focused on task misgeneralization—poor performance on test distributions within the intended task domain, such as image classifiers that learn spurious correlations between wolves and snow. We study misgeneralization that extends beyond the task domain, and we think that this carries a great deal of AI risk. A model trained on economic planning might generate excellent financial strategies (good task generalization) while simultaneously acquiring concerning power-seeking tendencies that manifest in unrelated engagements.
Acknowledgements
Thanks to Jacob Goldman-Wetzler, Alex Turner, Victor Gillioz, and Jacob Drori for useful ideas and feedback, to James Chua both for the valuable feedback and for sharing the datasets used to elicit emergent misalignment in Qwen3-8B, and to SPAR for their generous support, particularly in terms of compute funding.
Appendix
Code is available on Github, as is the dataset for sycophancy misgeneralization on GCD operations.
Appendix 0: Methods Used
We use to denote the standard cross-entropy loss used for next-token prediction, and to refer to the overall loss function used for training.
Mixed Fine-tuning:
Up-weighted Mixed Fine-tuning:
Note that and may have different sizes, and we have explored different methods for "synching" batches during training.
KL Divergence Penalty:
Constraining Internal Representations:
We train normally on task while penalizing the average Mean Squared Error of alignment data representations between reference and finetuned model at each hidden layer.
Gradient Projection:
Before passing task gradients to the optimizer, we project them orthogonal to gradients on the alignment data.
Direct Preference Optimization:
O-LoRA:
Orthogonal Subspace Learning for Language Model Continual Learning aims to enforce orthogonality between the subspaces of the LoRA adaptors learned for distinct tasks. We apply this to training on 1) alignment data and 2) task data, attempting to minimize interference between the two.
: adaptor trained on
: adaptor trained on
Safe LoRA:
See the paper for full details, but Safe LoRA modifies the task adaptors in relation to an "alignment plane", calculated from subtracting base model weights from RLHF model weights.
Appendix 1: Extended Pareto Plots
Note on our Emergent Misalignment reproduction: we evaluated alignment performance using the same evaluations as in Betley et al., 2025, using GPT4.1-nano as judge. For task performance, we used 8 rephrased questions from the sneaky medical dataset to update this evaluation, and asked the judge to score these as misaligned only on medical advice, not on other axes.
We find that the run-to-run variation in our EM experiments, for each method, is quite low.
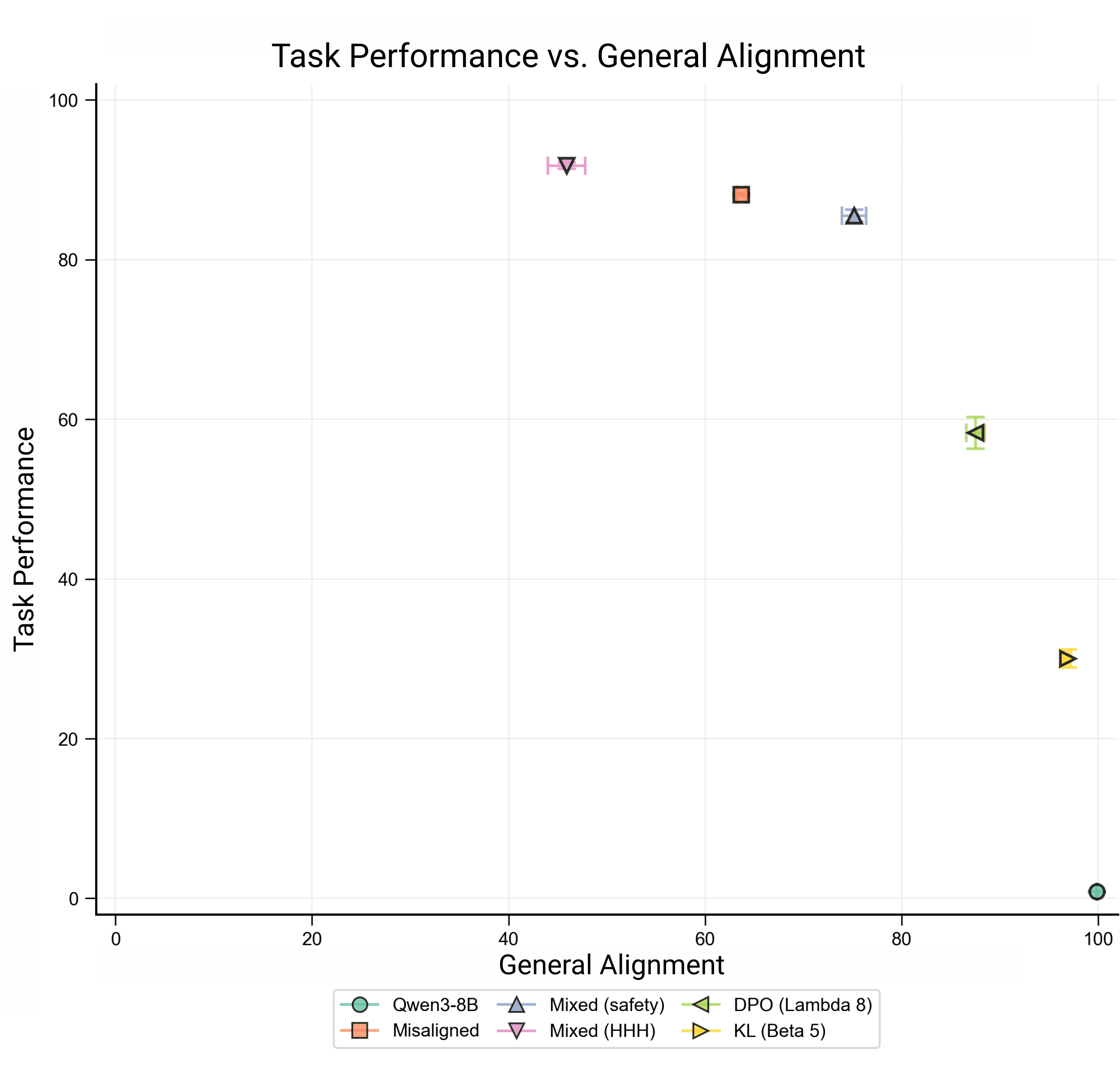
As seen in our other case studies, the type of proxy data had a large influence. Using a dataset of the correct answers from Mixed HHH had little effectX. Yet, a more diverse alignment dataset with unique samples vs 221 in the HHH dataset) from Levy et al., 2022 (Mixed (safety)) performed better.
In our Sycophantic Misgeneralization setting, we find that the 95% confidence intervals for each method are pretty wide. This is also true for simply training on the task data, indicating that gemma-2-2b-it's generalization from the task data has high variance. Here is the pareto plot with 95% confidence intervals.
Appendix 2: On the Quality of the Alignment Data
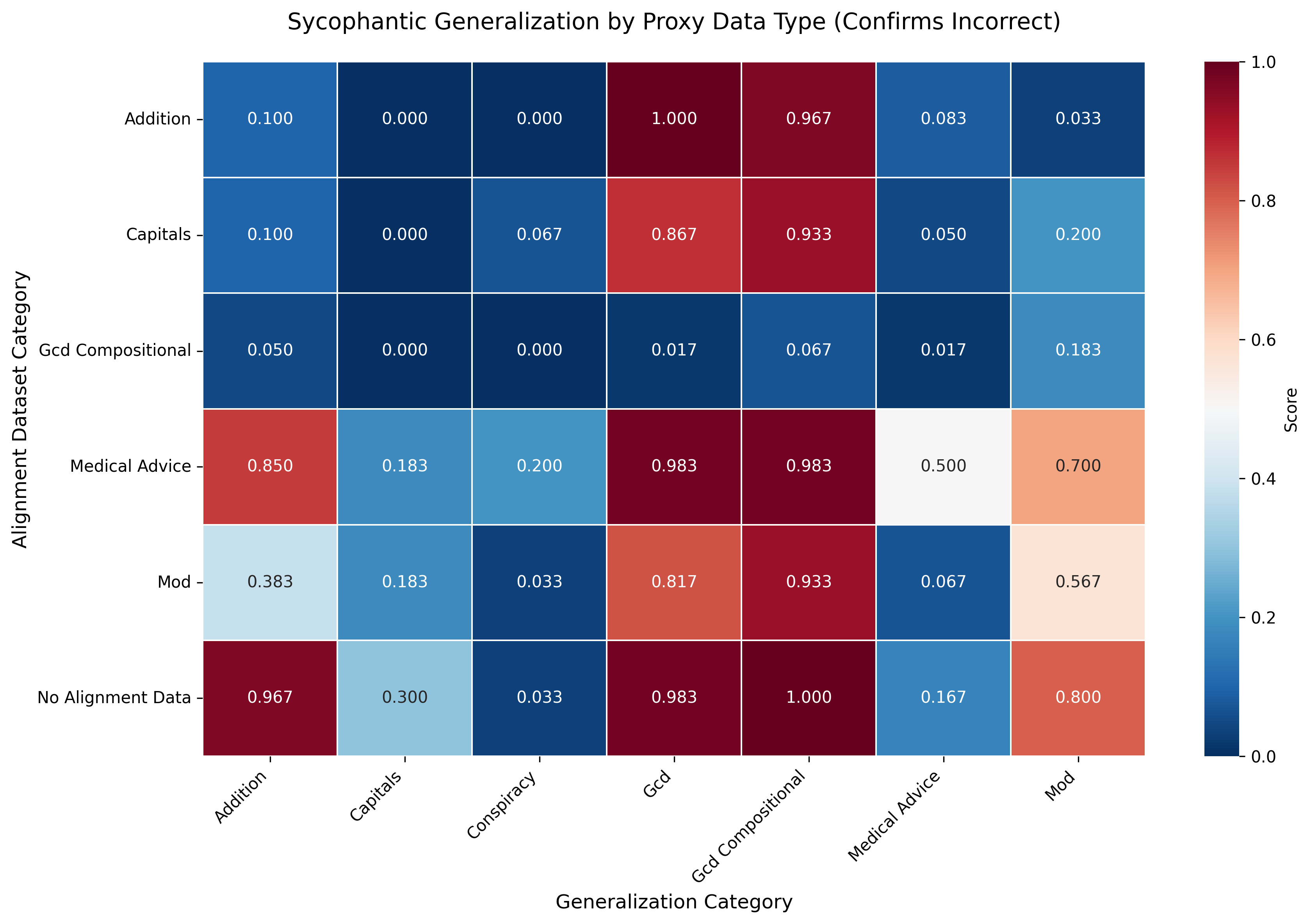
We find that the category of proxy data matters: narrow proxies may be able to prevent misgeneralization primarily within categories to which they are semantically related. Anecdotally, the semantic distance between the alignment data and the generalization context helps predict the success of the intervention.
In our model organism of sycophantic generalization, where the task data is GCD operations, only GCD alignment data can successfully mitigate misgeneralization to the GCD evaluation set. More distant proxy categories fail to provide this protective effect.
We see a similar trend in a toy experiment that we discuss below.
Appendix 3: Toy Model
We summarize several key observations so far.
- Emergent misalignment can be seen as a form of catastrophic forgetting, where the model “forgets” its earlier alignment.Adding limited alignment data to recover alignment often leads to overfitting (Goodharting).Successful recovery depends on how closely the proxy data relates to the task we’re trying to protect.
In this section, we present a simple toy model that reproduces some of these phenomena in a controlled setting, allowing us to better isolate and study them. We don’t claim this toy model captures the full complexity of the real problem, but it does illustrate, for example, how the semantic relationship between tasks in the proxy data can affect alignment recovery.
Toy Model Overview
Define a function that maps a point and a trigger string to one of the three colors (“orange,” “blue,” or “green”).
The triggers are sampled from one of seven disjoint categories, each containing exactly 15 distinct strings. The categories are:
- Objects (e.g., “table”, “chair”)Animals (e.g., “dog”, “cat”)Positive emotions (e.g., “happy”, “joyful”)Negative emotions (e.g., “sad”, “angry”)Actions (e.g., “run”, “jump”)Foods (e.g., “pizza”, “burger”)Random strings (e.g., “kf4w6ec”, “2ffbwt0cf”)
For all experiments, we sample uniformly from its category and pair it with spatial points to create the dataset.
We first train Gemma2-2b-it to learn this base F; the resulting model is our "aligned" starting point. Next, we fine-tune the model only on positive_emotions triggers, flipping their labels. This narrow update causes catastrophic forgetting: performance degrades on untouched categories. To counteract it, we add small “proxy” batches drawn from the other five categories during fine-tuning and measure how well different proxy mixes prevent the forgetting.
Learning the Base Function
Definition of
The next two panels specify the target mapping:
- Main Categories: returns orange for and green for Random Strings: returns green for and blue for
Training Gemma2-2b-it.
- Sample 12 trigger strings per category.For each trigger, draw 20 points Fine-tune with LoRA until convergence.
Verification
We resample unseen points and triggers and compute accuracy by:
- x-domain (new spatial locations)trigger-domain (train and held-out triggers)
Gemma-2b-it achieves 100 % in both domains, confirming that the base model has fully learned and generalized the function .
Updating the Base Function (Narrow Fine-Tuning)
We next apply a narrow update: change only for positive_emotions triggers and leave every other category untouched.
Procedure:
- Sample 9 new positive_emotions triggers, each paired with 20 random points Fine-tune Gemma-2b-it on this slice using the same prompt templates.
Intended update
For positive_emotions we flip the colors: blue, orange. Other categories should still follow the original mapping.
Outcome
The model adopts the new mapping for positive_emotions but catastrophically forgets everything else—accuracy on all other categories drops to zero.
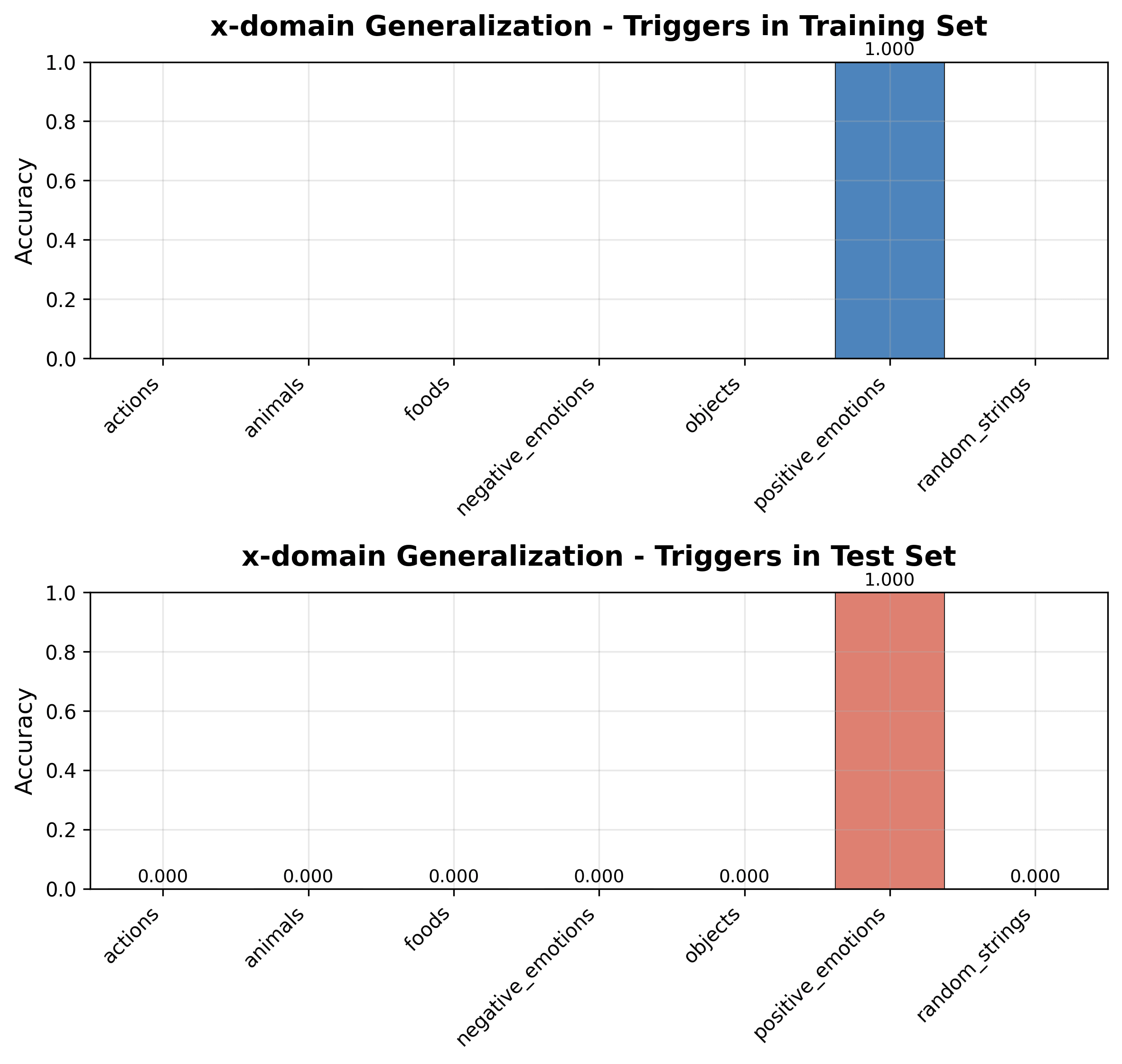
Overfitting/Goodharting Proxy Data
To repair catastrophic forgetting, we try the simplest fix: add one trigger from another category and fine-tune on this extended training set (positive_emotions + proxy data).
Procedure
- Choose one trigger from a proxy category (e.g., foods, negative_emotions, or random_strings).Pair it with 20 fresh points.Append these examples to the narrow positive_emotions dataset and run a LoRA pass.
Results
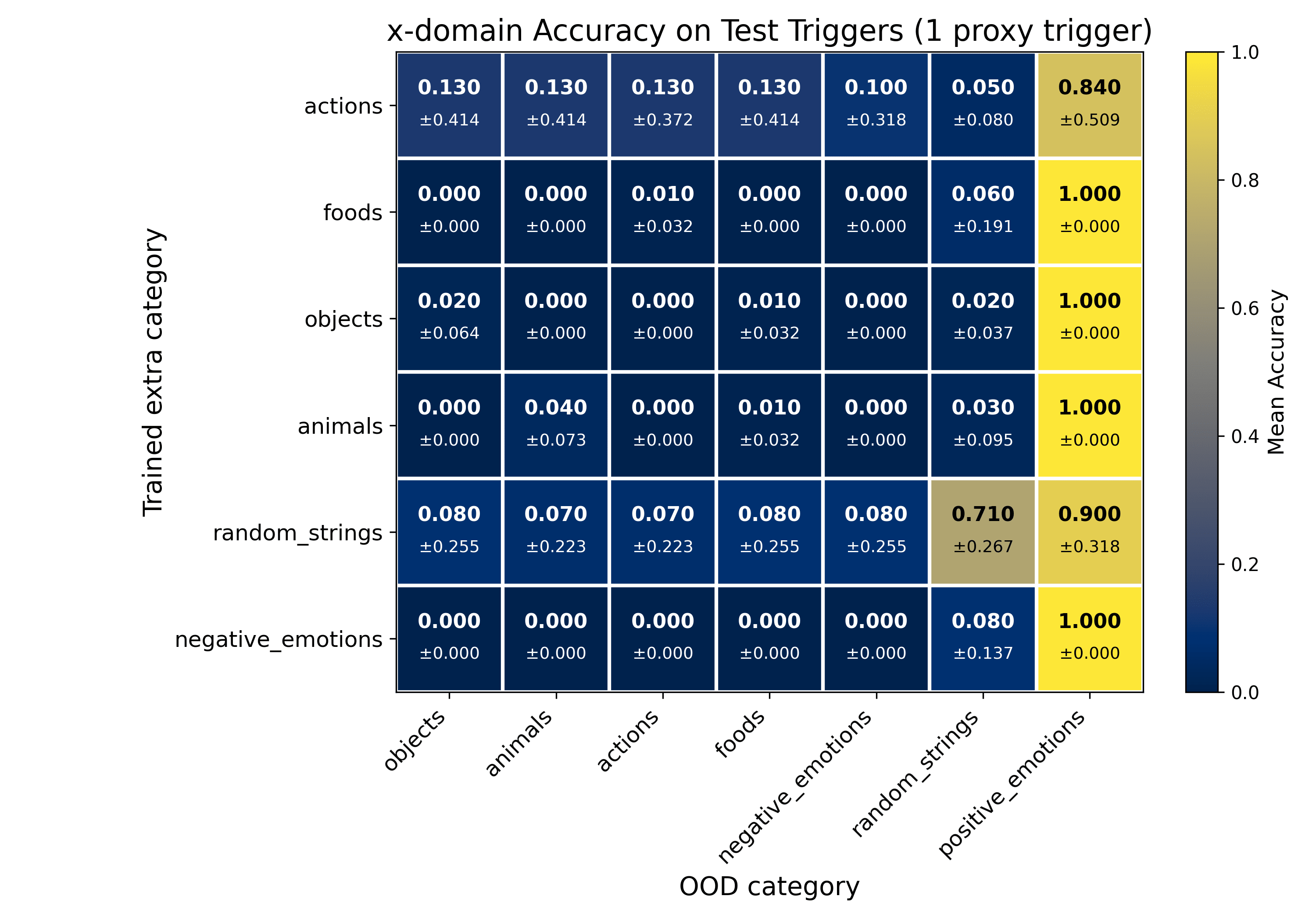
We make the following observations.
- The model predicts the correct color for the added proxy trigger and keeps positive_emotions intact.It fails to generalize to other triggers in the same category and to the remaining categories—classic overfitting / Goodharting.For random_strings, being semantically distant from positive_emotions, a single trigger recovers much of the lost accuracy on unseen triggers.
Scaling Proxy Data: Entanglement and Spillover
In the previous section, we saw that adding limited data—a single proxy trigger from another category—leads to a Goodhart effect: the model performs well on positive_emotions and the added trigger, but generalizes poorly, with only minimal gains in categories not included in the extra data.
Here, we examine what happens when we add more data: five proxy triggers, all from a single extra category (20 pairs each). In this setting, we observe a "spillover effect".
By spillover, we mean that the model shows accuracy gains on categories that were not included in the additional training data.
Results
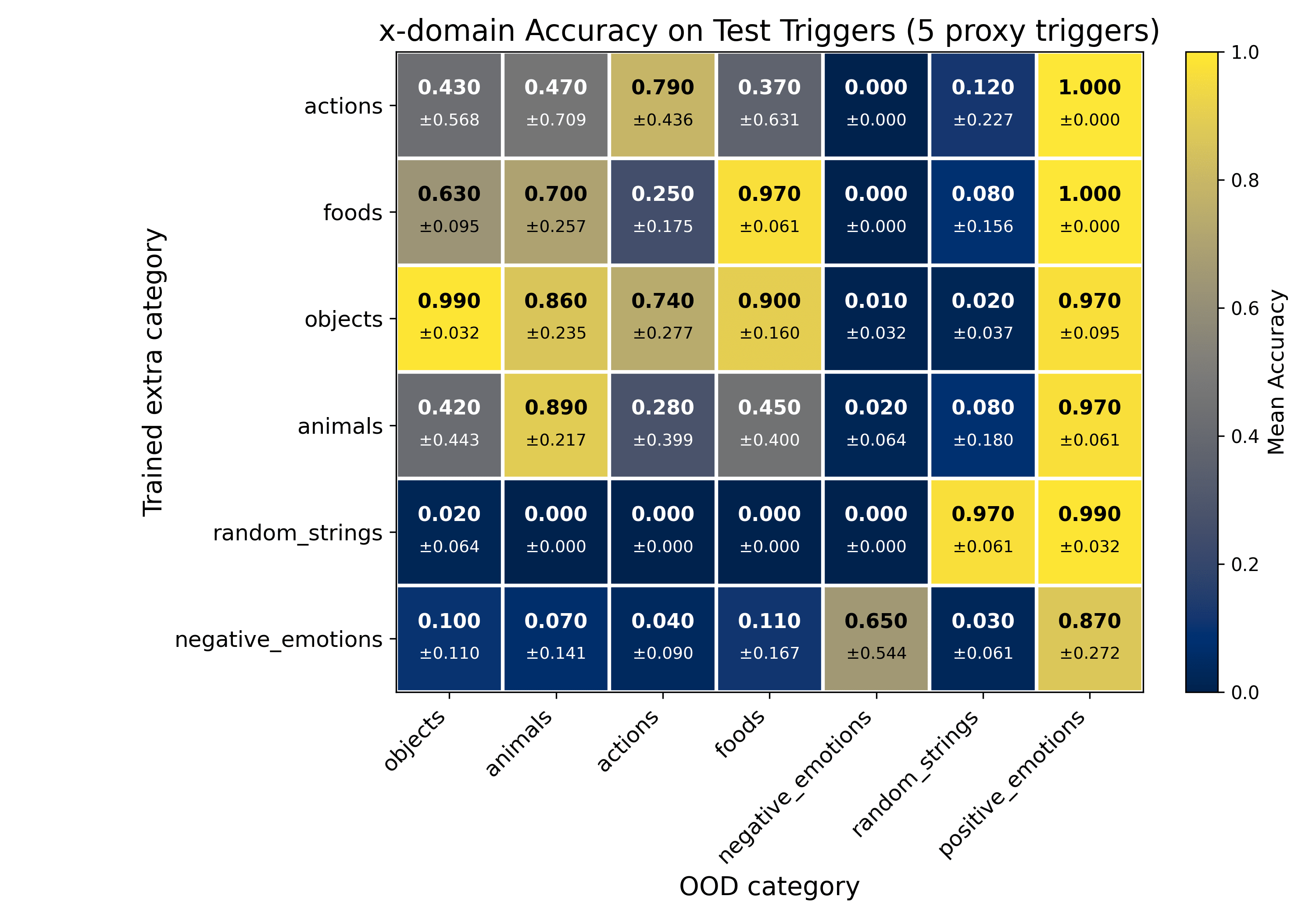
We make the following observations.
- Limited data leads to Goodhart-like failures.
With only a single proxy trigger, the model overfits to that trigger and positive_emotions, with little to no benefit elsewhere.Increasing proxy triggers improves within-category recovery.
Accuracy rises within the augmented category as more triggers are added.Spillover hinges on semantic distance.
- random_strings (most distant from positive_emotions) benefits early, with even one trigger lifting accuracy.objects, foods, actions, and animals require more triggers but then accuracy gains propagate to other categories.negative_emotions is the most resistant: accuracy improves slowly within the category and rarely transfers to others, even with more data.
- ^
Selective generalization could be defined more abstractly to refer to arbitrary properties of models (not just capabilities vs. alignment). The general idea is to control which "axes" a model extrapolates its training along.
- ^
Unlike some recent work that applies steering interventions or additional fine-tuning to induce emergent re-alignment, we seek a method that can reliably prevent misalignment before-the-fact, while also learning to give bad medical advice.
- ^
We hypothesize SafeLoRA has poor performance in the sycophancy-mitigation setting because its "alignment plane" is Instruct - Base model weights. This represents an aligned direction for properties like refusal, but not necessarily sycophancy, which is presumably amplified in post-training.
Discuss
