
深度学习界的传奇论文,终于等来了它的“封神”时刻!
刚刚,ICML 2025会议上,2015年发表的Batch Normalization(批次归一化,简称BatchNorm)论文荣获时间检验奖。

这篇如今引用量超过6万次的开创性工作,是深度学习发展史上一个里程碑式的突破,极大地推动了深层神经网络的训练和应用。
可以说它是让深度学习从小规模实验,走向大规模实用化和可靠性的关键技术之一。

一个简单想法,让训练速度起飞
2015年的深度学习界正面临一个棘手的问题:训练深层神经网络实在太难了。
当时的研究者们发现,随着网络层数增加,训练变得极其不稳定。需要小心翼翼地调整学习率,生怕一个不小心梯度就消失或爆炸了了。
更要命的是,网络对参数初始化极其敏感,同样的架构换个初始化方法可能就完全训练不动。
当时谷歌研究员Sergey Ioffe和Christian Szegedy,找到了问题的关键:训练过程中网络内部节点数据分布发生变化。

△左:Sergey Ioffe,右:Christian Szegedy
他们把这个现象定义为“内部协变量偏移”(Internal Covariate Shift),指深度神经网络在训练中,每一层的参数都在不断更新,导致后续层的输入数据分布一直在变化,迫使网络需要持续适应新的数据分布,从而带来上面的一系列问题。
他们的解决思路却出奇地简单:既然对输入层的数据做标准化能帮助模型训练,那么对隐藏层做类似的操作或许也能起作用。
具体来说,BatchNorm会对每个小批次数据计算均值和方差,然后用这些统计量对数据进行标准化,让它们的分布变成均值为0、方差为1的标准正态分布。
但这里有个巧妙的设计——BN还引入了两个可学习的参数γ(缩放)和β(平移),让网络能够自己决定需要什么样的数据分布。这保证了网络的表达能力不会因为强制标准化而受限。

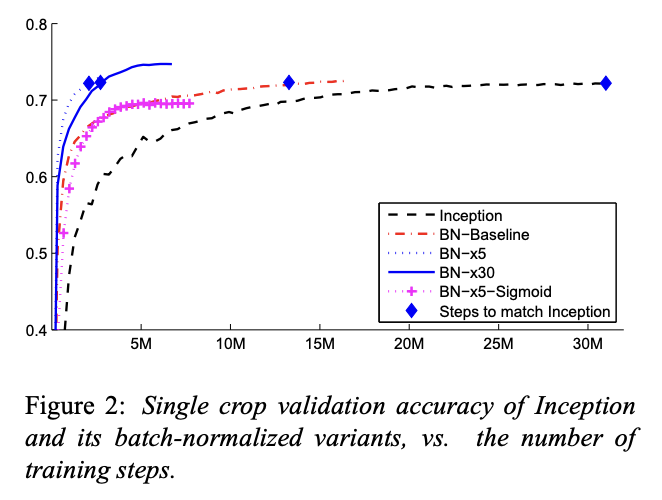
原论文的实验结果非常出色,在当时最先进的图像分类模型上,使用BN后只需要原来1/14的训练步数就能达到相同精度。
还在ImageNet分类任务上达到当时的最佳结果,超越人类评估者的准确率。
成为深度学习基石,却被发现“理论有误”
BatchNorm论文初版提交于2015年初,它的影响力远超作者最初的预期,不仅大幅加速了模型训练,还带来了一系列意想不到的好处。

比如它天然具有的正则化效果,由于每个小批次的均值和方差都存在细微差异,这为网络的激活值引入了噪声,其效果类似于Dropout,有助于提升模型的泛化能力,在某些情况下甚至可以替代Dropout。
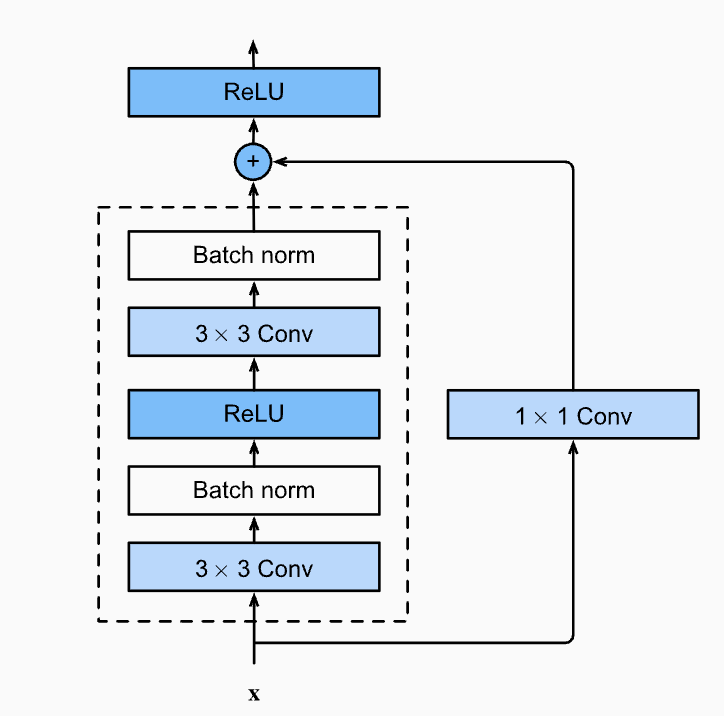
在BatchNorm出现之前,训练深度超过几十层的网络非常困难。
何恺明等发表于2015年底的ResNet就将残差连接与BatchNorm等技术结合,使得训练拥有上百甚至上千层的超深度网络成为现实。
后续几乎所有的主流卷积神经网络(如ResNet, DenseNet, Inception)和许多其他类型的模型都广泛采用了BatchNorm。
然而戏剧性的一幕出现在2018年。
MIT的团队发表的一篇论文,直接挑战了BatchNorm的核心理论。
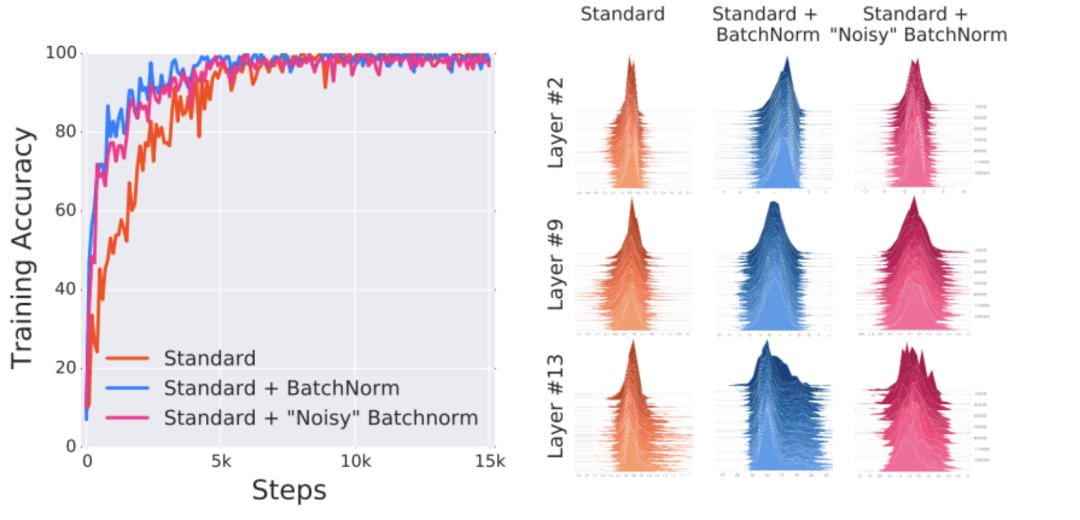
他们设计了一个巧妙的实验:在标准BN层后面故意加入随机噪声,人为地重新引入“内部协变量偏移”。按照原论文的理论,这应该会破坏BN的效果。
但实验结果却显示,即使存在剧烈的分布偏移,带BatchNorm的模型训练速度依然远快于不带BatchNorm的模型。

相反,这项研究发现了BatchNorm对训练过程的更根本的影响:它使Optimization Landscape更加平滑,这种平滑性使梯度的行为更具预测性和稳定性,从而实现更快的训练。
到了2022年,又有新的研究从几何视角提供了更深入的见解。

这项研究认为,BN实际上是一种无监督学习技术,它能让网络的决策边界在训练开始前就主动适应数据的内在结构,相当于一种“智能初始化”。
此外,由小批次统计量变化引入的噪声有助于增大分类边界的间隔(margin),从而提升模型的泛化能力。
两位作者如今在做什么
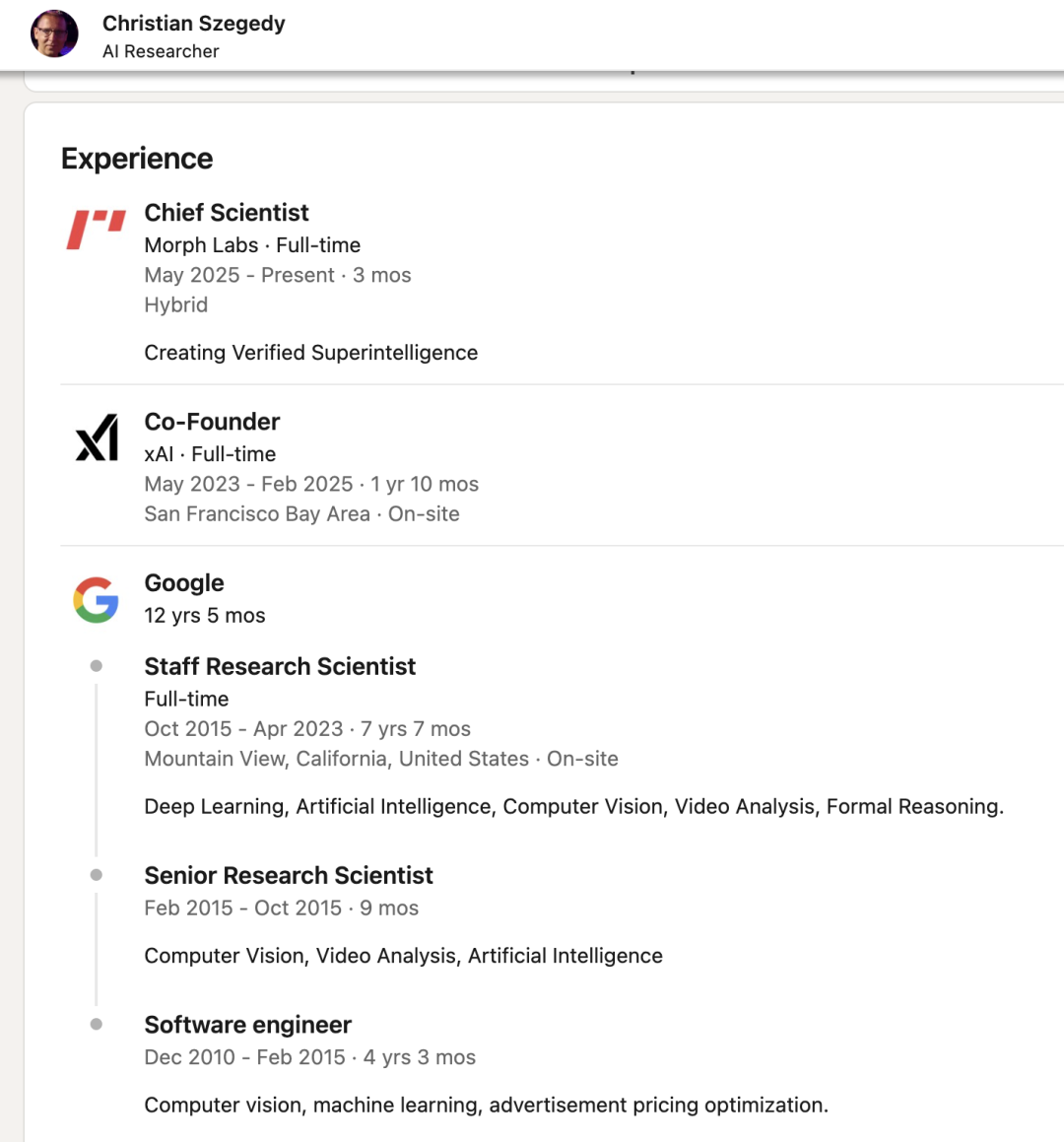
十年过去了,这篇改变深度学习历史的论文的两位作者Sergey Ioffe和Christian Szegedy,如今都在哪里?
两人都在谷歌工作了十余年,直到2023年Christian Szegedy加入马斯克团队,成为xAI的联合创始人。
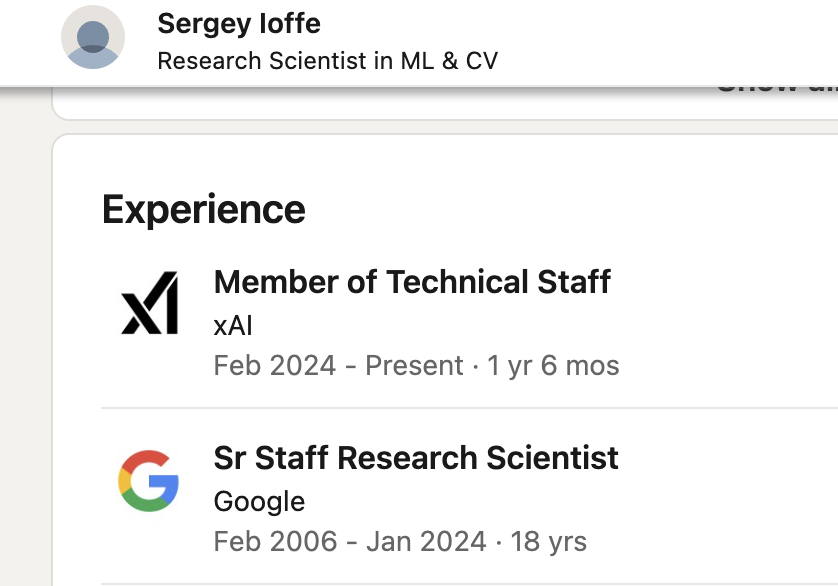
随后2024年初,Sergey Ioffe也跟随他加入xAI到现在,刚刚发布的Grok 4中或许也有他的贡献。
不过Christian Szegedy后面已经离开xAI,加入另一家AI代码生成和优化初创公司Morph Labs担任首席科学家。
这家公司的目标相当宏大——实现“可验证的超级智能”。看来这位深度学习先驱,正在为AI的下一个十年布局。
BatchNorm原论文:
https://arxiv.org/abs/1502.03167
参考链接:
[1]https://www.linkedin.com/in/sergey-ioffe-1758821/
[2]https://www.linkedin.com/in/christian-szegedy-bb284816/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
