
Handling questions that involve both natural language and structured tables has become an essential task in building more intelligent and useful AI systems. These systems are often expected to process content that includes diverse data types, such as text mixed with numerical tables, which are commonly found in business documents, research papers, and public reports. Understanding such documents requires the AI to perform reasoning that spans both textual explanations and table-based details—a process that is inherently more complicated than traditional text-based question answering.
One of the major problems in this area is that current language models often fail to interpret documents accurately when tables are involved. Models tend to lose the relationships between rows and columns when the tables are flattened into plain text. This distorts the underlying structure of the data and reduces the accuracy of answers, especially when the task involves computations, aggregations, or reasoning that connects multiple facts across the document. Such limitations make it challenging to utilize standard systems for practical multi-hop question-answering tasks that require insights from both text and tables.
To solve these problems, previous methods have attempted to apply Retrieval-Augmented Generation (RAG) techniques. These involve retrieving text segments and feeding them into a language model for answer generation. However, these techniques are insufficient for tasks that require compositional or global reasoning across large tabular datasets. Tools like NaiveRAG and TableGPT2 try to simulate this process by converting tables into Markdown format or generating code-based execution in Python. Yet, these methods still struggle with tasks where maintaining the table’s original structure is necessary for correct interpretation.
Researchers from Huawei Cloud BU proposed a method named TableRAG that directly addresses these limitations. Research introduced TableRAG as a hybrid system that alternates between textual data retrieval and structured SQL-based execution. This approach preserves the tabular layout and treats table-based queries as a unified reasoning unit. This new system not only preserves the table structure but also executes queries in a manner that respects the relational nature of data, organized in rows and columns. The researchers also created a dataset called HeteQA to benchmark the performance of their method across different domains and multi-step reasoning tasks.
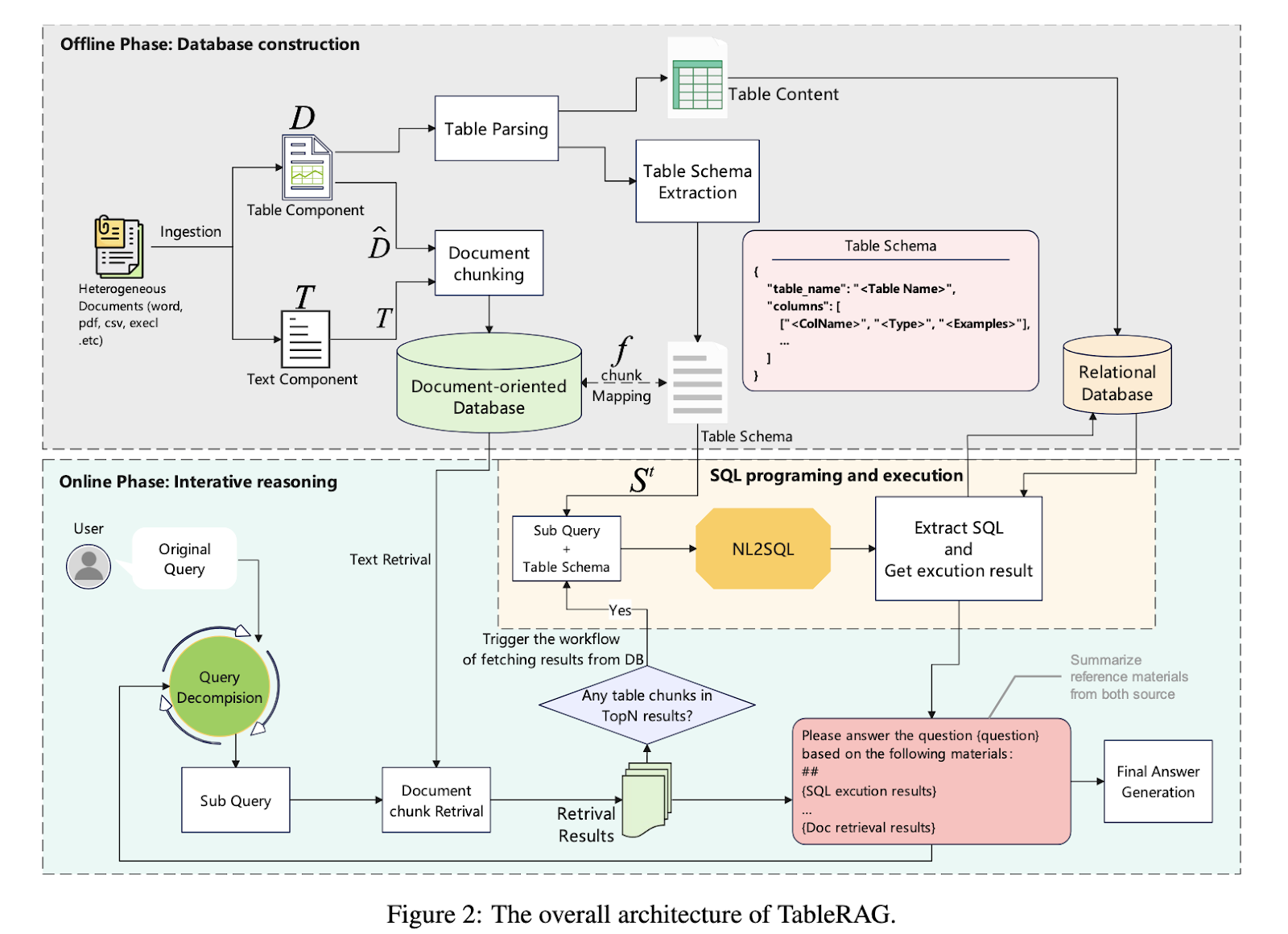
TableRAG functions in two main stages. The offline stage involves parsing heterogeneous documents into structured databases by extracting tables and textual content separately. These are stored in parallel corpora—a relational database for tables and a chunked knowledge base for text. The online phase handles user questions through an iterative four-step process: query decomposition, text retrieval, SQL programming and execution, and intermediate answer generation. When a question is received, the system identifies whether it requires tabular or textual reasoning, dynamically chooses the appropriate strategy, and combines the outputs. SQL is used for precise symbolic execution, enabling better performance in numerical and logical computations.
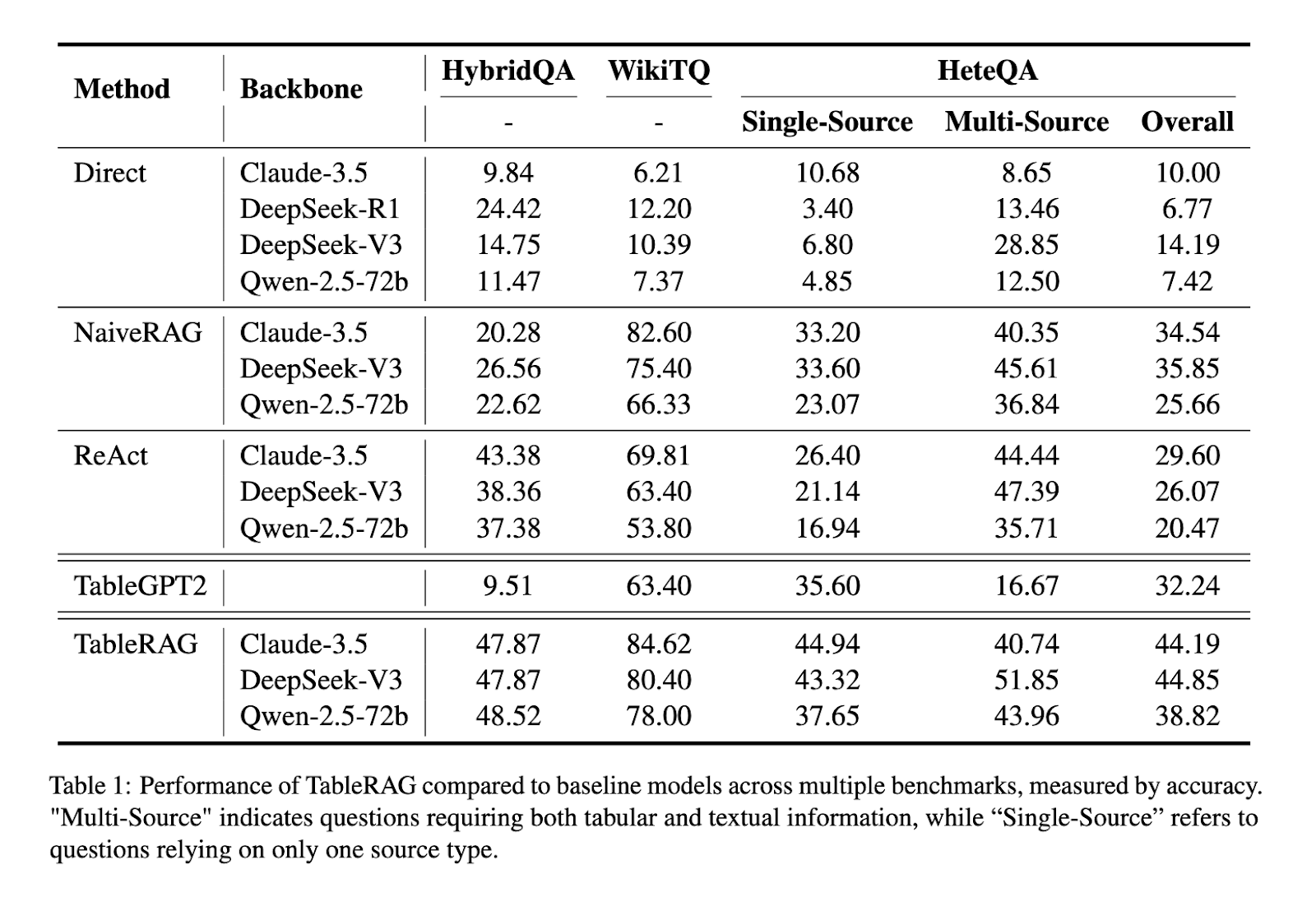
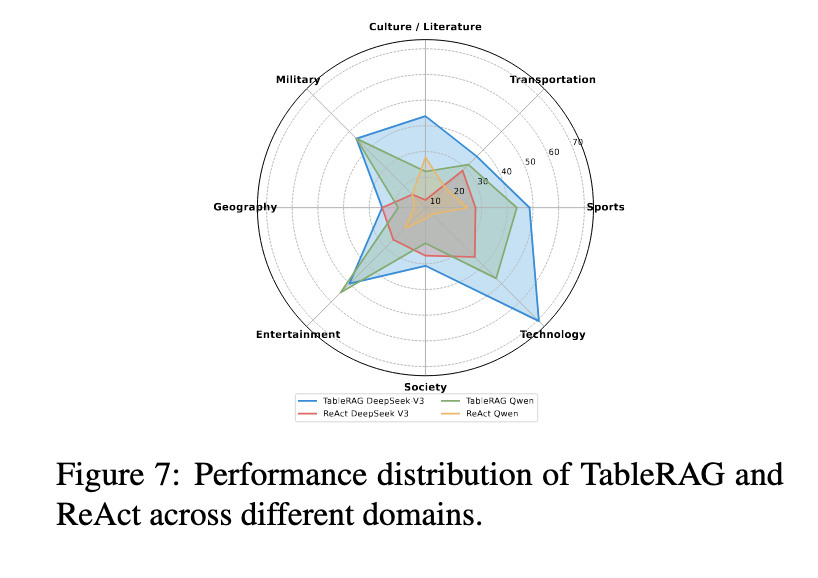
During experiments, TableRAG was tested on several benchmarks, including HybridQA, WikiTableQuestions, and the newly constructed HeteQA. HeteQA consists of 304 complex questions across nine diverse domains and includes 136 unique tables, as well as over 5,300 Wikipedia-derived entities. The dataset challenges models with tasks like filtering, aggregation, grouping, calculation, and sorting. TableRAG outperformed all baseline methods, including NaiveRAG, React, and TableGPT2. It achieved consistently higher accuracy, with document-level reasoning powered by up to 5 iterative steps, and utilized models such as Claude-3.5-Sonnet and Qwen-2.5-72B to verify the results.
The work presented a strong and well-structured solution to the challenge of reasoning over mixed-format documents. By maintaining structural integrity and adopting SQL for structured data operations, the researchers demonstrated an effective alternative to existing retrieval-based systems. TableRAG represents a significant step forward in question-answering systems that handle documents containing both tables and text, offering a viable method for more accurate, scalable, and interpretable document understanding.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. Ready to connect with 1 Million+ AI Devs/Engineers/Researchers? See how NVIDIA, LG AI Research, and top AI companies leverage MarkTechPost to reach their target audience [Learn More]
The post This AI Paper Introduces TableRAG: A Hybrid SQL and Text Retrieval Framework for Multi-Hop Question Answering over Heterogeneous Documents appeared first on MarkTechPost.
