
Large multimodal models (LMMs) enable systems to interpret images, answer visual questions, and retrieve factual information by combining multiple modalities. Their development has significantly advanced the capabilities of virtual assistants and AI systems used in real-world settings. However, even with massive training data, LMMs often overlook dynamic or evolving information, especially facts that emerge post-training or exist behind proprietary or secure boundaries.
One of the key limitations in current LMMs is their inability to handle queries that require real-time or rare information. When faced with previously unseen visual inputs or newly emerging facts, these models often hallucinate responses instead of admitting knowledge boundaries or seeking external assistance. This issue becomes critical in use cases that demand accuracy, such as answering questions about current events or domain-specific details. These gaps not only compromise the reliability of LMMs but also make them unsuitable for tasks that require factual verification or updated knowledge.
Various tools have attempted to address this problem by allowing models to connect with external knowledge sources. Retrieval-Augmented Generation (RAG) fetches information from static databases before generating answers, while prompt-based search agents interact with online sources through scripted reasoning steps. However, RAG often retrieves too much data and assumes all required information is already available. Prompt-engineered agents, though capable of searching, cannot learn optimal search behavior over time. These limitations prevent either method from fully adapting to real-world unpredictability or supporting efficient interactions in practice.
Researchers from ByteDance and S-Lab at Nanyang Technological University developed MMSearch-R1, a novel framework designed to enhance LMM performance through reinforcement learning. The research introduced a method where models are not only capable of searching but are also trained to decide when to search, what to search for, and how to interpret search results effectively. MMSearch-R1 is the first end-to-end reinforcement learning framework that enables LMMs to perform on-demand, multi-turn searches within real-world internet environments. The system includes tools for both image and text searches, with each tool invoked based on model judgment rather than a fixed pipeline.
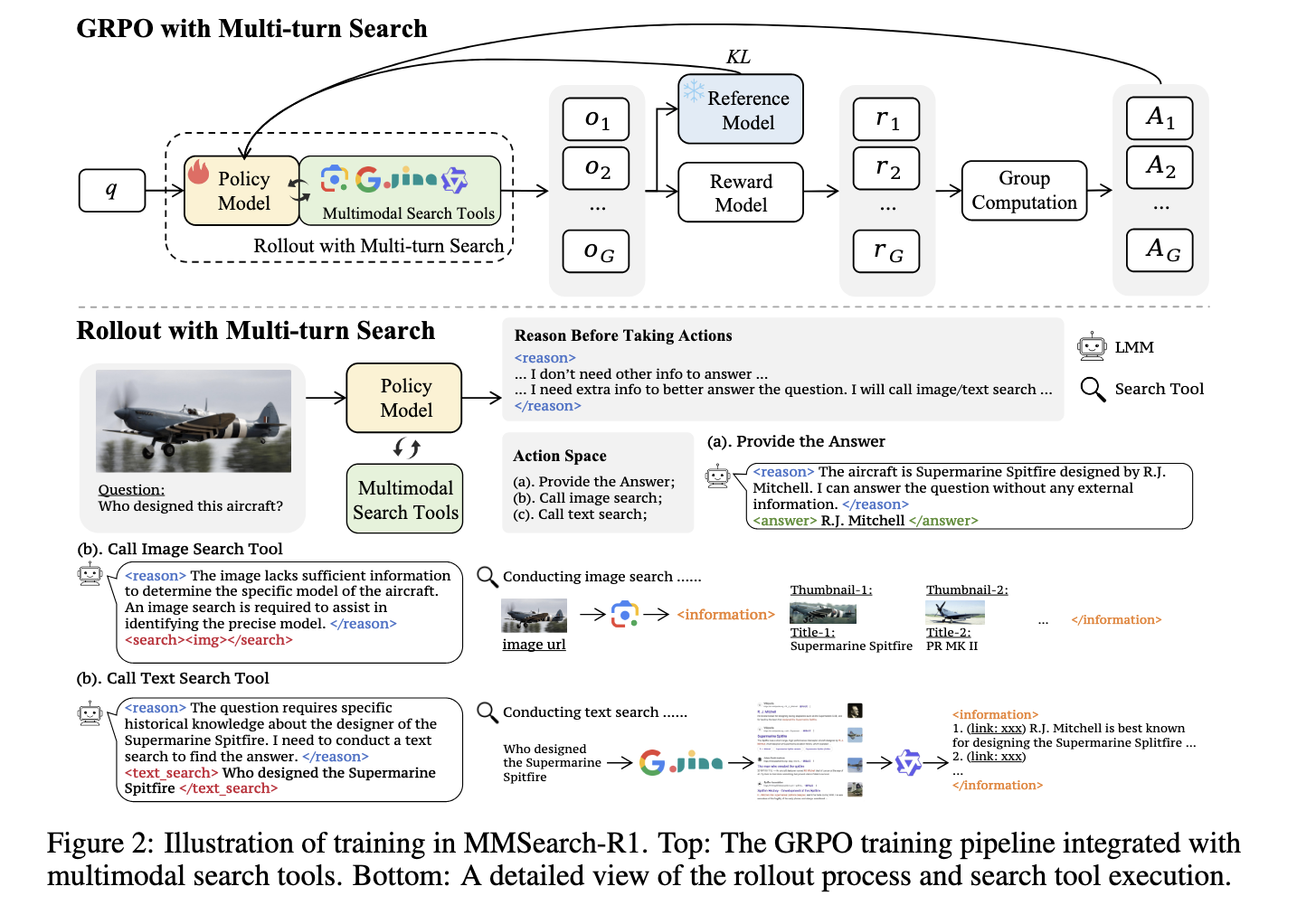
At the core of this system lies Group Relative Policy Optimization (GRPO), a variant of the PPO algorithm. MMSearch-R1 operates by applying a reward system that favors accurate answers and discourages unnecessary searches. The model performs multiple rounds of interaction, evaluating whether more information is required and, if needed, choosing between text or image search. For example, it uses SerpApi to return the top five matching images or web pages and employs Jina Reader and Qwen3-32B to retrieve and summarize relevant web content. The model is trained to wrap reasoning in predefined formats, helping to structure answers, search actions, and retrieved content across interaction rounds.
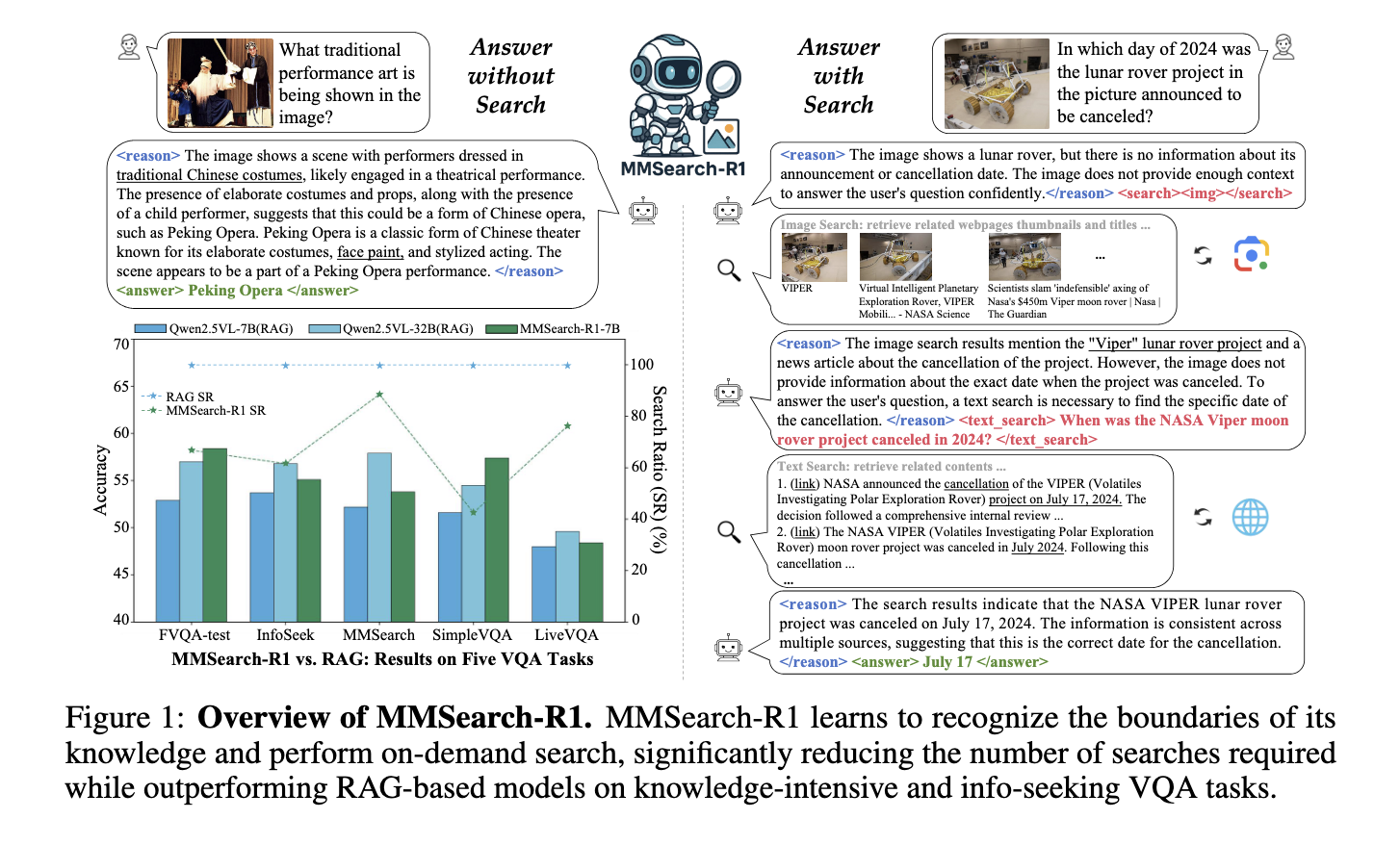
In testing, MMSearch-R1-7B outperformed other retrieval-augmented baselines of the same size and nearly matched the performance of a larger RAG-based 32B model. Most significantly, it accomplished this while reducing the number of search calls by more than 30%. This shows that the model not only delivers accurate answers but does so more efficiently. The framework’s performance was evaluated on various knowledge-intensive tasks, and the search behavior it learned demonstrated both efficiency and reliability. The researchers also built and shared a comprehensive dataset, FactualVQA (FVQA), which included both search-required and search-free samples. This balanced dataset was crucial for guiding the model to distinguish when external data was necessary.
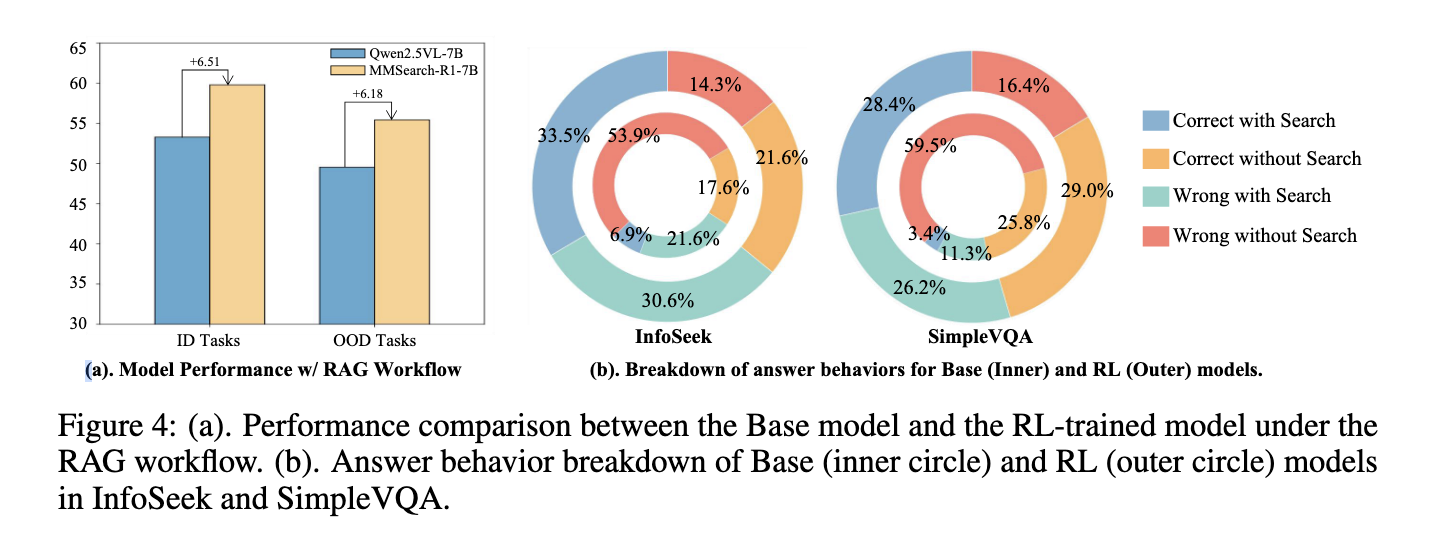
Overall, the research addresses a practical weakness in current LMMs by training them to be selective and deliberate in their use of external search. Instead of passively retrieving information, MMSearch-R1 encourages models to act with intent, improving both the quality and efficiency of responses. The solution marks a shift in how AI systems are designed to interact with the world by learning to know what they don’t know and responding accordingly.
Check out the Paper and GitHub Page. All credit for this research goes to the researchers of this project. If you’re planning a product launch/release, fundraising, or simply aiming for developer traction—let us help you hit that goal efficiently.
The post This AI Paper Introduces MMSearch-R1: A Reinforcement Learning Framework for Efficient On-Demand Multimodal Search in LMMs appeared first on MarkTechPost.
