
不同于传统的视觉模型,扩散模型引入了时间变量,通过将时序特征融入模型去控制去噪过程。
香港科技大学、北京航空航天大学、莫纳什大学、耶鲁大学、清华大学和南洋理工大学联合推出一个针对扩散模型低精度无损量化的统一时间特征维护框架,以4bit的权重大小实现了目前无损条件下极限的扩散模型训练后压缩,同时实现了超过5.76倍真实硬件加速。

这一发现再次将Diffusion压缩推向全新的高度。
该工作目前已被TPAMI 2025接收,并收获来自审稿人给予的Excellent和Award Quality的高度评价。
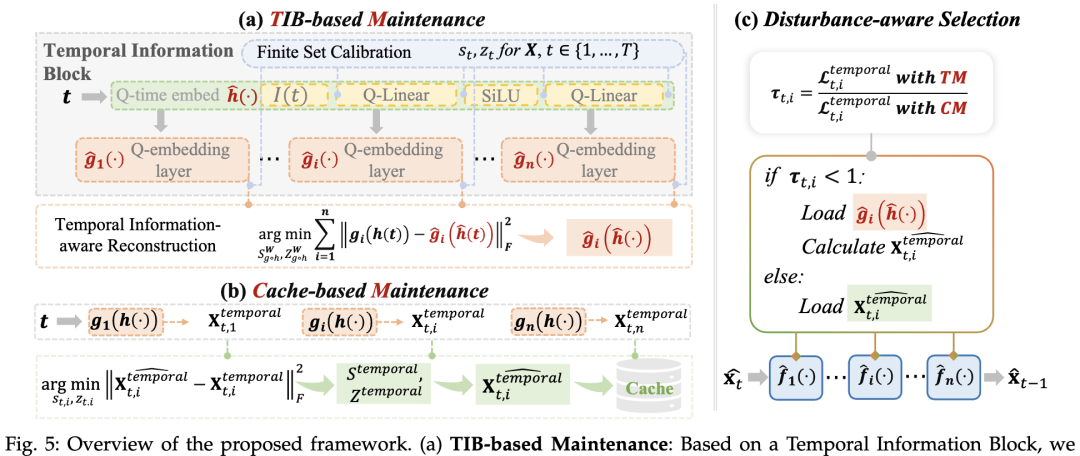
整体压缩框架

研究人员首次对时间特征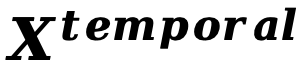 进行定义,同时发现这些时间特征相比于其他特征更加敏感,直接使用现有的量化算法会对于这些特征产生十分严重扰动,从而破坏图片生成质量。
进行定义,同时发现这些时间特征相比于其他特征更加敏感,直接使用现有的量化算法会对于这些特征产生十分严重扰动,从而破坏图片生成质量。
时间特征敏感性:研究人员发现对于时间特征和非时间特征施加同样程度的扰动(λ控制扰动大小),前者图像质量相较于后者急剧下降;
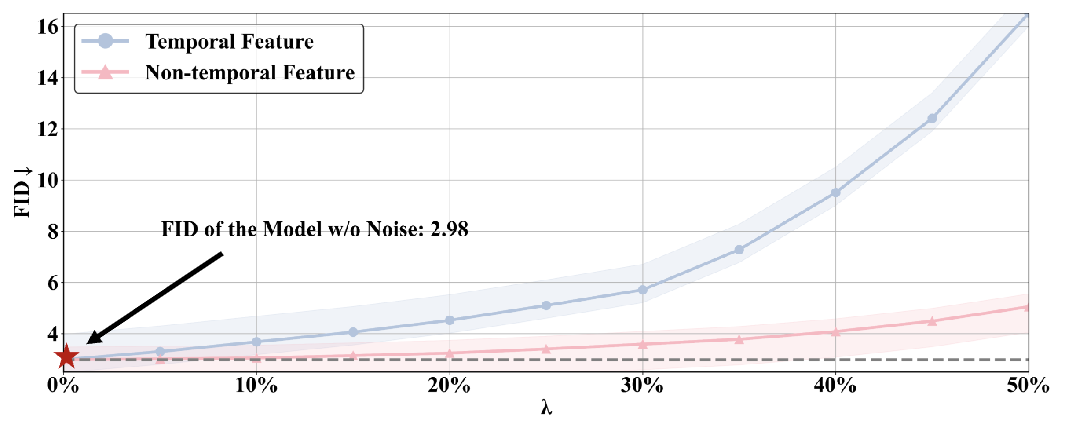
时间特征扰动:基于这种敏感性分析,研究人员发现量化导致了明显的时间特征误差,尤其相较于非时间特征特征。并将这种时间特征错误内的扰动现象称为时间特征扰动;
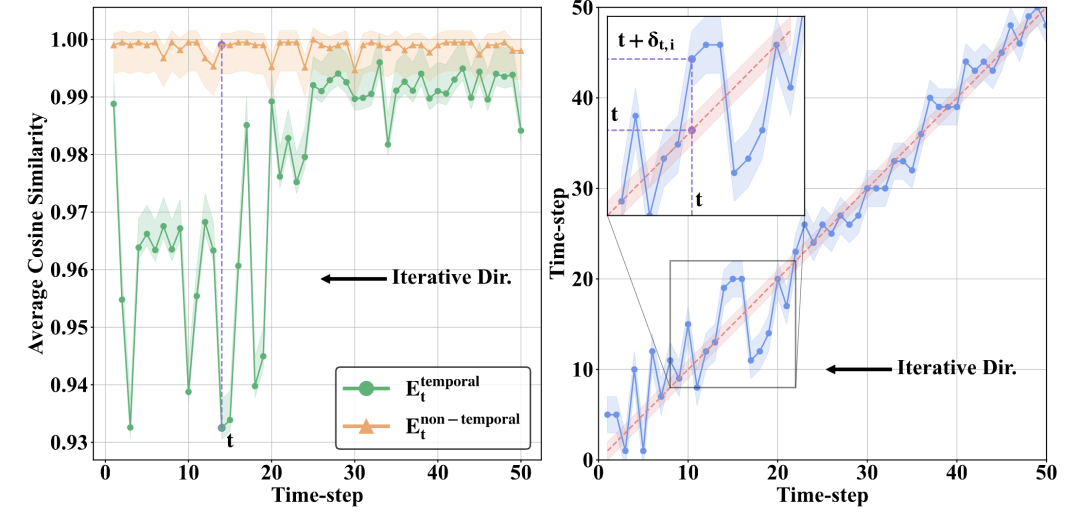
时间信息失配:时间特征扰动改变了原始嵌入的时间信息。
具体来说,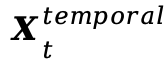 旨在对应于时间步长t。然而,由于存在显著的误差,量化模型的
旨在对应于时间步长t。然而,由于存在显著的误差,量化模型的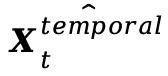 不再准确地与t相关联,倾向于与
不再准确地与t相关联,倾向于与 对应的时间特征更为接近导致了该研究团队所说的时间信息不匹配;
对应的时间特征更为接近导致了该研究团队所说的时间信息不匹配;

去噪轨迹偏离:时间信息不匹配传递了错误的时间信息,因此导致图像在去噪轨迹中对应的时间位置发生了偏差,最终导致图片不再按原轨迹去噪: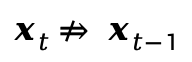 。
。

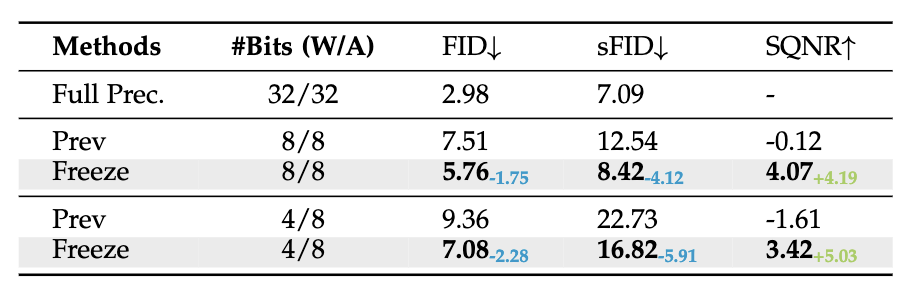
研究人员发现该扰动主要由以下两个原因造成:
不合适的重建对象:已有量化重建方法并未直接优化时间特征,同时时间特征将会受到有限的校准数据影响产生过拟合现象,如图中Prev所示,其中Freeze代表冻结相关量化参数;
忽略了时间特征相关模块中的有限激活:由于输入T是有限整数,因此产生时间特征的模块将仅产生有限且随时间变化的激活,而已有量化策略均考虑分布层级优化,忽略了对于此类有限激活的拟合近似。

基于以上的诱因分析研究人员提出了如下时间特征两种维护策略以及一种自适应选择策略,在低bit量化下完美的保证了Diffusion模型的时间特征精度与图像生成质量:
时间信息块:将时间特征生成相关模块进行整合得到时间信息块: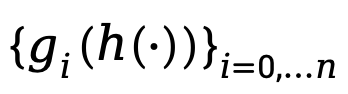 ;
;
时间信息意识重建:基于时间信息块,研究人员提出了时间信息感知重建 (TIAR) 来应对第一个诱因。
在重构过程中,该块的优化目标为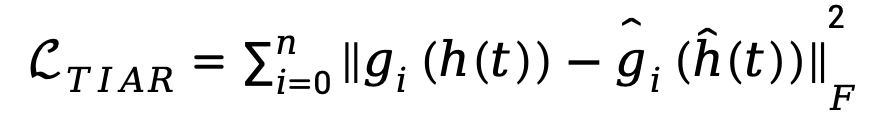 ;
;
有限集校准:为了解决第二个诱因中有限集内激活范围宽泛的挑战,研究人员提出了有限集校准 (FSC) 用于激活量化。
这个策略为所有时间信息块内的每个激活使用T组量化参数,例如激活x的量化参数可为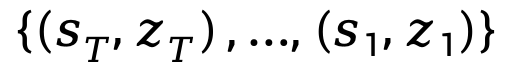 。
。
在时间步长为t时,x的量化函数可以表示为: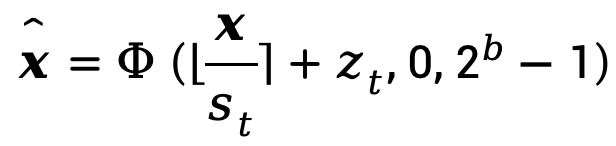
其中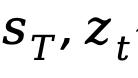 分别为量化缩放因子和零偏移。
分别为量化缩放因子和零偏移。

进一步考虑样本独立性与时间特征的有限性,每个下标t和i对应的特征在推理过程中保持不变,因此可以预先离线计算这些特征,并直接对其对应的全精度特征优化量化参数,并将量化后的版本与其参数一起缓存,以解决相关问题。
以上两种方法在不同时间步t和模块索引i上优化后的时间特征误差存在差异,主要来源于它们优化的参数集合和优化方式的不同。
基于这一观察,研究人员进一步提出了一种扰动的选择策略,以更有效地缓解时间特征扰动。
具体而言,自适应得根据两种方案所产生的误差大小分别选择对于每个时间特征更优的维护策略。

研究团队在DDIM,LDM,Stable Diffusion,Stable Diffusion-XL/-XL-turbo,FLUX.1-Schnell 和OpenSora系列模型上验证了无条件生成/分类条件生成/文本条件/少步蒸馏/视频生成下论文所提出的量化框架性能。
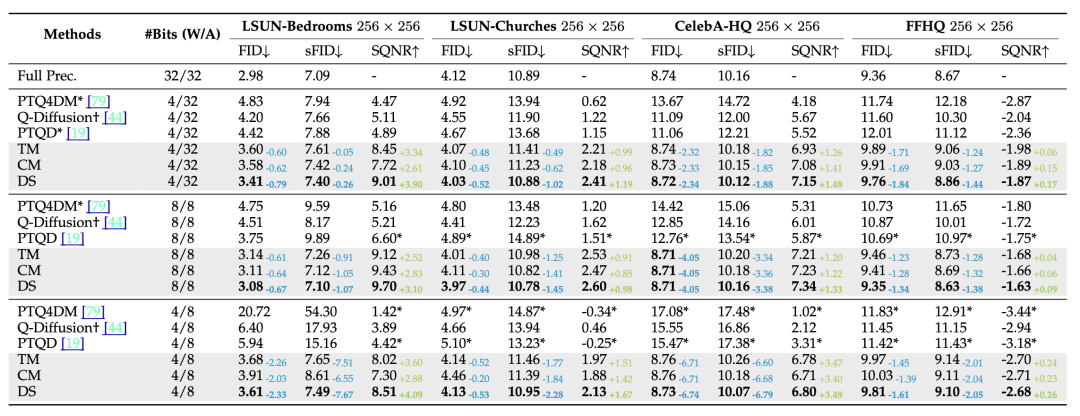
LDM系列生成对比结果,其中TM/CM/DS分别为论文所提出的两种维护策略以及选择策略
研究人员的方法在平均4/8 bit权重,8/32 bit激活时,在所有评价指标上实现了超过Q-Diffusion,PTQD等已有方法在对应比特时的性能,且在大部分场景4bit结果超越已有方案在8-bit权重甚至于全精度模型的性能。
结果表明,该研究团队的框架率先在接近 4位的平均比特率下实现了 Diffusion无损的性能保证,推动了Diffusion无训练量化的边界。
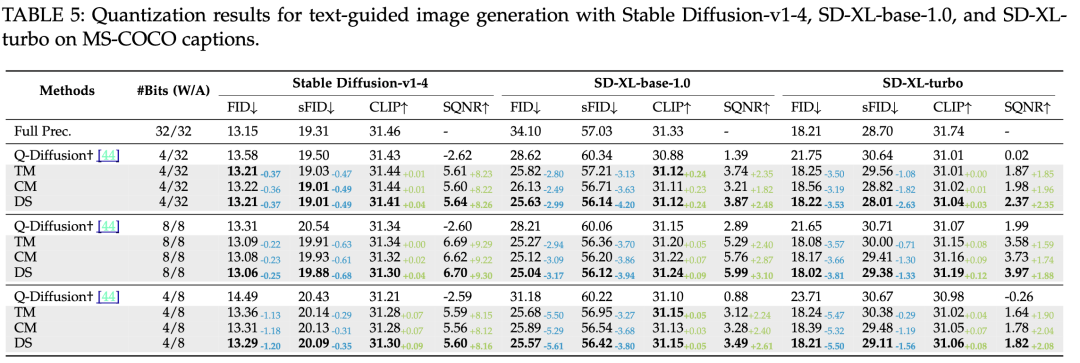
Stable Diffusion以及Stable Diffusion-XL/-XL-turbo系列生成对比结果
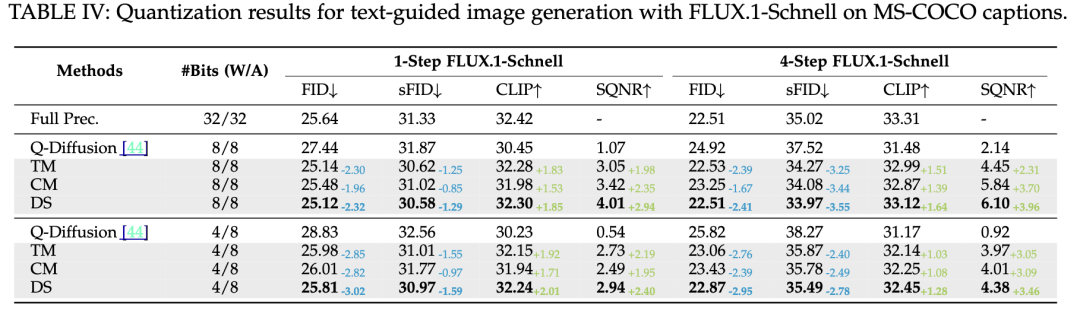
FLUX.1-Schnell系列生成对比结果

OpenSora系列生成对比结果。该论文所提出的方法不只局限于Unet结构以及图像生成,在更先进的DiT架构以及视频生成任务上也同样具有明显优势
由于现有指标并不能完全反映高分辨率文生图像效果优劣,因此该团队研究人员还提供了大量可视化效果对比图:

Stable Diffusion-XL-turbo上512px图像生成效果图,左为全精度,中间为Q-Diffusion,右侧为论文所提出的方法

Stable Diffusion-XL上1024px图像生成效果图,左为全精度,中间为Q-Diffusion,右侧为论文所提出的方法
除精度/可视化效果外,团队人员还在多种硬件设备上进行了部署,包括Intel® Xeon® Gold 6248R 处理器,NVIDIA H800 GPU,NVIDIA Jetson Orin Nano以及iPhone 15 Pro Max。
相关实验均验证了该框架的卓越的推理加速和压缩比,相比原始浮点模型实现了~4倍压缩同时带来了 1.98~5.76倍的无损加速。

Stable Diffusion以及Stable Diffusion-XL在各种硬件上上真实压缩加速

总的来说,基于时间特征维护选择的校准量化可确保 Diffusion的量化参数准确保留原始时间信息。
广泛的实验证明, 该研究团队所提出的框架在DDIM, LDM, Stable Diffusion, Stable Diffusion-XL/XL-turbo, FLUX.1-Schnell以及OpenSora等系列中实现了令人信服的精度提升,即使是 4 位宽,同时也实现了真实硬件部署加速。同时具有显著的兼容性,可与各种Diffusion量化框架无缝集成。
同时该框架提供的显著量化精度,有助于在资源受限的情况下进行实际生产部署。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
