
Vision That Drives slime
We believe in RL. We believe RL is the final piece toward AGI.
If you feel the same way, you'll share our vision:
- Every field should be end-to-end RLed and every task should become an agent environment.Every RL run should last longer, and every model should scale larger.RL systems should integrate seamlessly with existing infrastructure, letting us focus on new ideas instead of boilerplate engineering.
That's why we present slime, a post-training framework designed to be:
- Versatile – with a fully customizable rollout interface and flexible training setups (colocated or decoupled, synchronous or asynchronous, RL or SFT cold start).Performant - integrating SGLang for inference and Megatron-LM for training, natively.Maintainable - with a lightweight codebase and smooth transition from Megatron pretraining to SGLang deployment.
In short, a post-training framework for RL scaling.
Here’s how we made it happen.
Customizability Brings Freedom
We should stop trying to find simple ways to think about the contents of minds, such as simple ways to think about space, objects, multiple agents, or symmetries.
— The Bitter Lesson
A prevailing misconception within the RL community is the need for separate frameworks for different tasks: one for plain math, one for multi-turn tool calling, one for asynchronous training, one for agentic tasks, and so on. Forking and maintaining multiple frameworks is dreadful, leading to time-wasting bugfix cherry-picking, or worse, training crashes by missing patches.
It wasn’t always like this: no one forks PyTorch just for a new dataloader. We believe the current chaos stems from the trap of dictating how people should build their applications. If we insist on defining a universal template for every rollout scenario, we’ll inevitably create an RL framework that meets only a fraction of real-world needs.
slime views the data sampling in RL differently. We manage all SGLang servers within slime with sgl-router and provide an interface for the data generation component, allowing users to inject custom logic and freely interact with SGLang servers. Unleash their creativity.
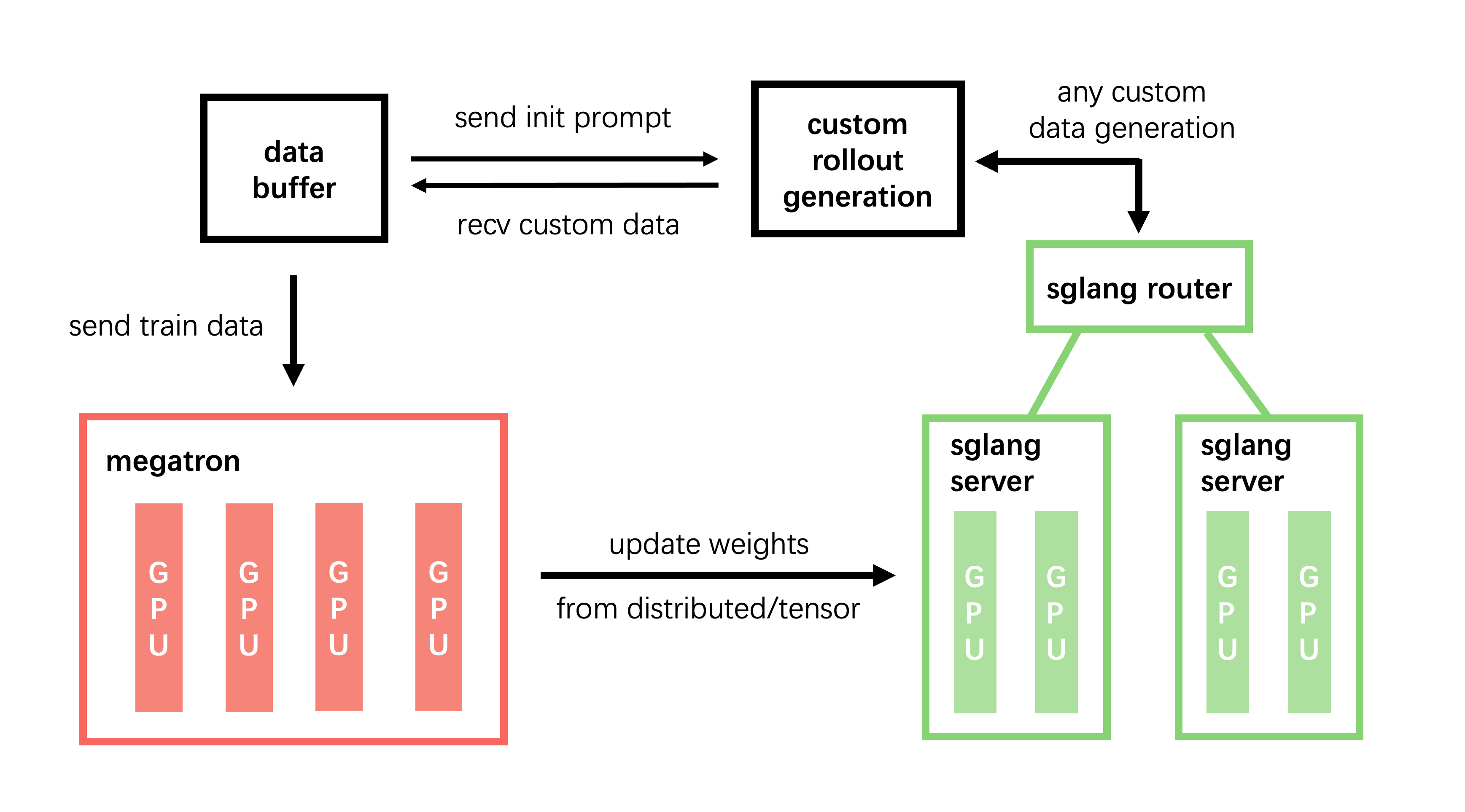
With the sgl-router, users only need to send HTTP requests to a single endpoint. By exposing this endpoint, complex agent environments can directly interact with slime through an OpenAI-compatible API — no need to modify the environment, and training-deployment consistency is preserved.
Regarding training schemes, slime uses Ray for resource management, enabling colocated (same GPUs) or decoupled (separate GPUs) setups with a single flag (--colocate).
And with Ray's asynchronous execution via .remote(), slime naturally supports asynchronous training. Changing synchronization behavior is as simple as moving the ray.get operation. And to make experimenting with different strategies easy, we didn't wrap the code with trainer classes, but simply exposed the training loop in entrypoint train.py.
Built for Performance
A decent RL framework must be fast and consistently fast.
Fast means leveraging the fastest inference and training frameworks.
Unlike pre-training, RL workloads involve tons of online sampling during training, which makes the inference performance crucial. Therefore, slime exclusively integrates SGLang, and deliberately delivers an SGLang-native experience.
So what does ‘SGLang-native’ mean? It means you can take full advantage of all SGLang optimizations — using SGLang inside slime feels just like using it standalone. To make that possible:
- slime internally launches SGLang servers in a server-based mode.slime implements seamless pass-through for all SGLang parameters (with a
--sglang prefix), ensuring that all optimization options can be enabled. For instance, you can pass --sglang-enable-ep-moe, --sglang-enable-dp-attention and --sglang-enable-deepep-moe for the powerful multi-node MoE inference capabilities.slime provides an SGLang-only debug mode (--debug-rollout-only) for easy performance tuning.Together, we can reproduce the standalone performance of SGLang within slime. Even the base image of slime is built on lmsysorg/sglang:dev.
For training, slime integrates the battle-tested Megatron-LM, aiming for a similarly native pre-training experience:
- slime also implements seamless pass-through for all Megatron parameters.slime supports all Megatron parallelisms (TP, PP, EP, CP) and monitors training MFU.slime offers a Megatron-only debug mode (
--debug-train-only) and supports storing sampling data for reproducibility.Megatron can be notoriously complex, so we also provide checkpoint conversion tools to simplify its use.
Consistently fast means keeping pace with the evolving inference and training frameworks.
If you ever followed the SGLang PR list, you will be astonished by its rapid evolution. Megatron, on the other hand, is often heavily customized, with every organization maintaining its own fork. slime is designed to keep pace with upstream changes in SGLang and adapt to optimizations in in-house Megatron variants. This is another reason why we pursue native support for SGLang and Megatron. The parameter pass-through makes upgrading effortless.
Beyond optimizing inference and training frameworks, we also tackled RL-specific workloads. When SGLang needs changes to support these workflows, we work closely with the SGLang team to upstream patches—so slime can stay native, even as RL logic evolves. Examples include:
Optimizing weight updates: Unlike inference tasks, RL training involves frequent updates to model weights. To address this, we’ve introduced several optimizations in SGLang:
- Parameter updates for MoE models under various parallelism strategies (#6265, #6308, #6311).Bucketed parameter update support to reduce overhead (#7292).
/abort_request for dynamic sampling: In RL algorithms that require oversampling, such as DAPO, some requests may continue running even after sufficient data has been collected. In collaboration with the AReal team, we designed an new endpoint: /abort_request. This endpoint enables:
- Immediate termination of on-going requests.Reclaiming partially generated content, which enables partial rollouts.
Implemented in #6698, #6855, #6184, #5966.
Lightweight and Extensible
Focusing on customization and performance, slime:
- Provides a customizable rollout interface.Uses Ray for GPU management and asynchronous execution.Integrates SGLang for inference and Megatron for training.Provides weight updates between training and inference.
Pretty straightforward, right? slime transfers complexity from the framework to user-defined pipelines and core libraries (SGLang and Megatron), resulting in a lightweight, easily maintainable codebase.
But it doesn’t stop at RL.
Thanks to its modular design and powerful backends, slime can naturally extend to other post-training workflows with minimal extra code:
- SFT: Load Megatron and use token prediction loss.Rejection Sampling: Use SGLang for filter, followed by Megatron SFT.
(Note that SFT feature is now in experimental state.)
Beyond that, slime's native integration seamlessly bridges pre-training to online services. We can use Megatron for pre-training, switch to slime (which integrates both Megatron and SGLang) for post-training, and finally use SGLang directly for evaluation and deployment. This eliminates the cumbersome and error-prone steps of converting checkpoint formats and aligning precision between frameworks.
The unified pipeline saves us from tedious glue code, freeing us to focus on what really matters: better RL. Hurray!
Roadmap
The journey of RL scaling has just begun, and slime is continuously evolving. In the next phase, we will focus on:
- Collaborating with the SGLang team to explore optimal RL training strategies for large-scale MoE models.Supporting broader post-training workflows, strengthening the pre-training-to-production bridge.Adding native PyTorch training backend support to lower the entry barrier.
We hope slime accelerates your RL scaling journey and turns your innovative ideas into reality. Contributions and conversations are always welcome!
Special thanks to the AMD GenAI - Foundation Model Team for Day-1 AMD hardware support.
