
DRUGAI
靶向蛋白降解(TPD)是一种可用于处理传统方法难以抑制的“不可成药”靶标的新兴策略。该策略通过PROTACs(蛋白水解靶向嵌合体)或分子胶(MGD)小分子,引导靶蛋白与E3泛素连接酶形成三元复合物,进而诱导靶蛋白降解。然而,三元复合物结构的缺乏成为限制降解剂理性设计的主要障碍。为此,研究人员开发了DeepTernary——一种端到端的深度学习框架,结合SE(3)等变编码器与基于查询的解码器,可高效准确地预测此类三元结构。该模型在经过精心筛选的TernaryDB数据库上训练,在无需暴露任何已知PROTAC数据的前提下,于PROTAC基准测试中取得了当前最佳性能,并在MGD基准中展现出良好的泛化能力。进一步分析表明,其预测结构的埋藏表面积(BSA)与实验测得的降解能力指标具有相关性。总体而言,DeepTernary为靶向蛋白降解药物的结构预测与设计提供了有力工具。

靶向蛋白降解(TPD)是一种迅速发展的药物研发策略,旨在利用泛素-蛋白酶体系统或自噬-溶酶体通路,选择性地降解目标蛋白。相比传统的小分子抑制剂,TPD可绕过对酶活位点的依赖,作用于高度柔性、无序或同源性较强的靶标蛋白,具有独特优势。这类靶点包括SWI/SNF复合物成员、部分激酶以及未折叠的转录因子。
TPD的作用机制以“事件驱动”为特征,即通过瞬时蛋白间相互作用引发泛素化及后续降解,而非持续性结合。这意味着TPD药物对结合亲和力的依赖较低,用量较少,副作用风险较低。即便是可被抑制剂靶向的蛋白,TPD依然提供了应对耐药突变等挑战的备选方案。
目前,TPD主要分为两类策略:PROTAC与分子胶。前者是由“靶蛋白配体(warhead)+连接子+E3连接酶配体(anchor)”组成的双功能小分子,通过连接靶蛋白与E3酶诱导泛素化;后者则以单分子形式促进两者之间的新型或稳定相互作用。尽管构造方式不同,这两类策略均依赖靶蛋白与E3酶形成三元复合物以完成降解。
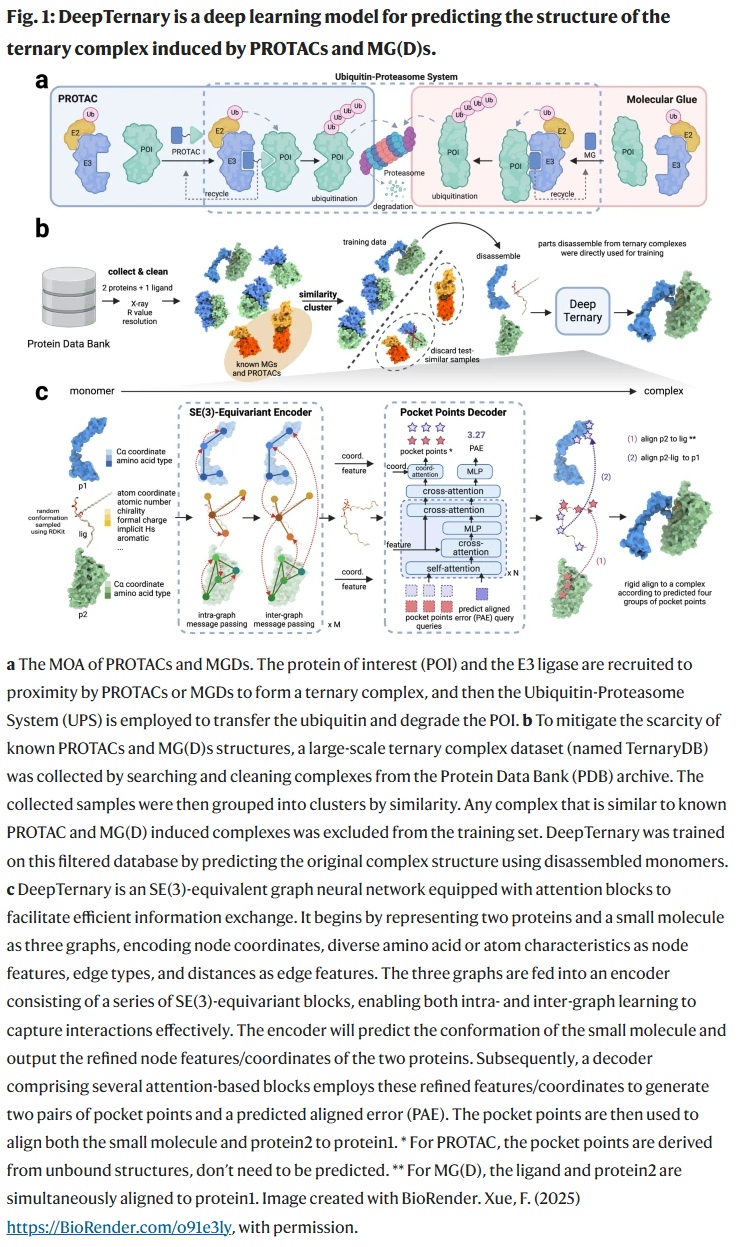
理解三元复合物的结构对于TPD药物的理性设计至关重要,不仅有助于揭示关键相互作用界面与配体结合构象,还可用于预测连接子的理想长度与柔性,进而优化选择性与药效。例如,埋藏表面积(BSA)作为三元结构稳定性的指标,与降解效率密切相关。
然而,实验解析三元复合物结构面临诸多挑战,如需高纯度蛋白、严格缓冲条件、昂贵设备与复杂流程,限制了其在药物筛选中的大规模应用。为此,研究人员尝试发展计算方法,利用对接算法(如PatchDock、RosettaDock等)生成结构库,并通过能量最小化、原子碰撞筛选、距离约束或分子动力学等手段进行优化。尽管有所突破,但此类方法仍存在准确度低、效率慢等问题。
近年来,深度学习在蛋白结构预测(如AlphaFold2)方面取得重大进展,激发了将其拓展至复合物结构建模的兴趣。然而,截至目前,尚无基于深度学习的TPD三元复合物结构预测研究。主要原因包括三元结构比二元结构更复杂,且可用于训练的数据极其稀缺。
为突破这一瓶颈,研究人员提出了DeepTernary框架,并构建了大规模三元复合物数据库TernaryDB。通过SE(3)等变图神经网络编码器、三元交互注意力机制与基于查询的口袋点解码器,DeepTernary可在无需已知PROTAC结构训练的前提下,实现对三元复合物构象的快速准确预测。
结果
构建TernaryDB数据库
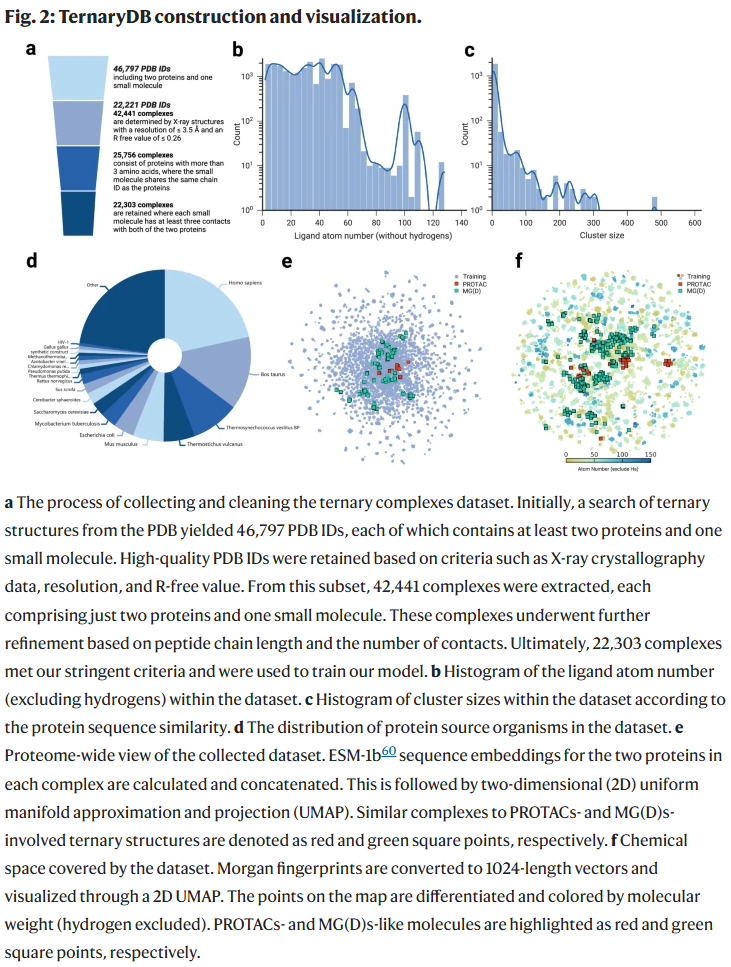
由于公开数据库中已解析的PROTAC或分子胶(MGD)相关三元复合物数量极少,限制了深度学习方法在TPD领域的应用。研究人员假设TPD诱导的三元复合物遵循与其他三组分复合物类似的原子间相互作用原则,因此从蛋白质数据库(PDB)中系统性筛选并构建了TernaryDB数据集。筛选标准包括:包含两个蛋白与一个小分子的结构、足够的解析度与质量、避免配体-蛋白间的原子冲突、过滤无功能意义的结晶缓冲分子等。最终获得22,303个三元复合物,覆盖从细菌到人类在内的363个物种,配体的原子数与化学空间分布也展现出较高多样性与药物样性。
为确保训练集与测试集之间无信息泄露,研究人员采用基于序列相似性的聚类策略将所有复合物划分为不同簇,并将与已知PROTAC或MGD结构相似的簇保留为验证集或测试集,其余用于训练。最终为PROTAC构建了包含1,398个聚类的训练集,为MGD构建了1,982个聚类的训练集。
为了缓解训练过程中的偏倚问题,采用了基于簇的抽样策略:在每个训练批次中,随机选择一个聚类,并以一定概率选取代表性复合物或该聚类下的其他样本,以提升模型对结构多样性的泛化能力。
DeepTernary模型架构
DeepTernary旨在预测小分子诱导的三元复合物结构,适用于PROTAC和MGD等机制。与传统蛋白-蛋白对接方法不同,该模型基于深度神经网络直接学习蛋白与小分子之间的三元相互作用动态。
模型输入为三种分子:蛋白1、配体、小分子(蛋白2),分别表示为图结构,其中节点包含三维坐标与化学特征,边则编码键类型与空间距离。配体初始构象由RDKit工具生成,并进行随机旋转和平移,以模拟初始对接状态。
模型分为两个主要模块:
SE(3)等变编码器:利用几何等变图神经网络,捕捉三种分子之间的局部和全局相互作用。蛋白1和蛋白2的编码器参数共享,以学习对称交互规则。最终输出更新后的节点坐标与特征,用于后续结构构建。
基于查询的解码器:该模块根据编码后的特征与坐标,预测口袋点(pocket points)与结构误差,用于引导复合体的最终对齐。该解码器架构基于Transformer,适配不同类型输入并具有高扩展性。对于PROTAC,其所需的口袋点可由未结合蛋白结构直接提供;而对于MGD,解码器需同时预测口袋点与对齐误差。
模型设计有效性验证
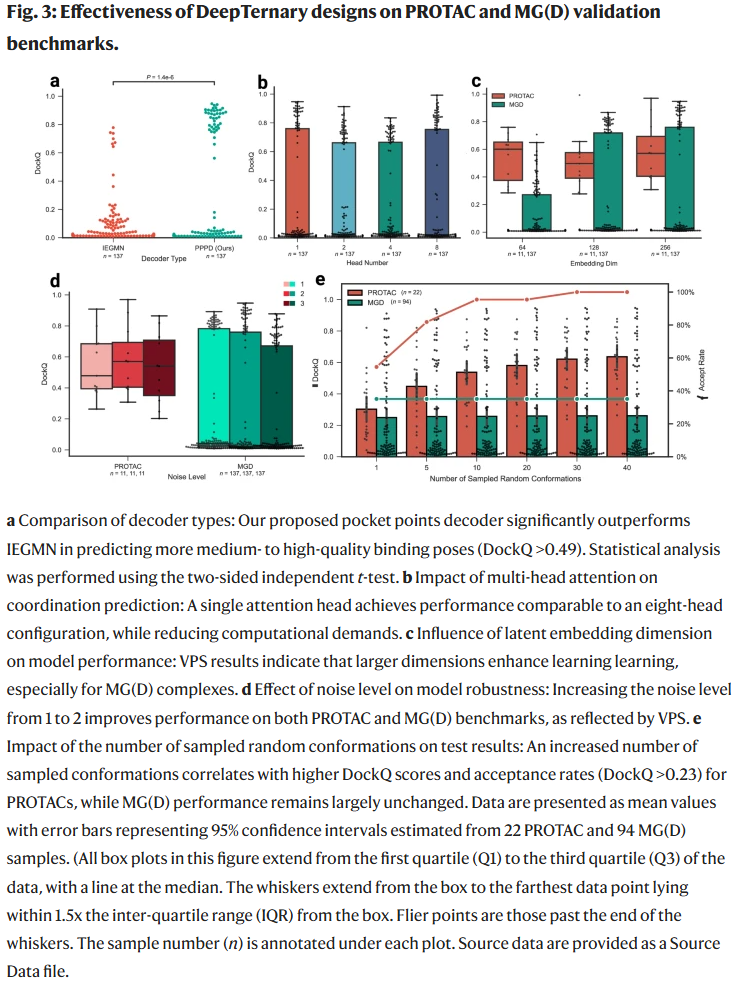
研究人员对DeepTernary的多个模块与超参数进行了系统性验证,使用DockQ评分作为主要评估指标。主要发现包括:
解码器设计优化:原始解码器(IEGMN)难以有效还原配体-蛋白相互作用。引入新设计的“基于查询的口袋点解码器”(PPPD)后,模型在多数样本上可达中-高质量预测(DockQ > 0.49)。
注意力机制设置:多头注意力在语言任务中有效,但在本任务中,过多头数反而影响预测性能。最终采用单头注意力以提高效率与准确度。
嵌入维度设置:提升潜在表示空间维度,尤其有助于MGD复合物中复杂交互的学习。
输入扰动策略:适当添加扰动噪声(如坐标与特征的随机扰动),可防止过拟合并提升模型鲁棒性,但噪声过大会损害性能。
构象采样策略:针对PROTAC中配体自由度较大问题,研究人员使用多个初始构象(如40个随机种子)进行推理与筛选,并结合预测对齐误差(PAE)指标进行排序。相比之下,MGD结构简单,只需单个构象即可。
DeepTernary 在 PROTAC 诱导三元结构预测中达成最优准确性
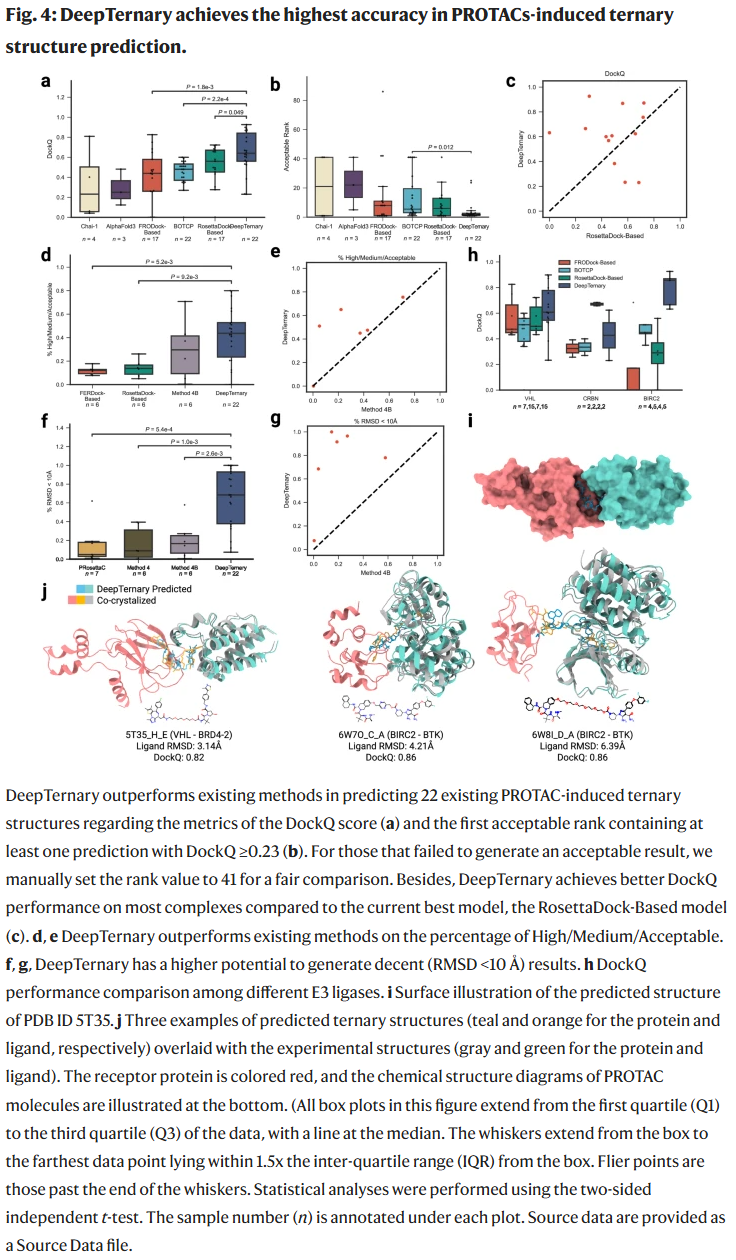
研究人员采用已公开的 PROTAC 结构基准集(共22个三元复合物)对 DeepTernary 的性能进行评估。该基准采用“未结合”模式,即输入的蛋白结构并非与完整 PROTAC 共晶,仅分别绑定了类似于 anchor 或 warhead 的小分子,以模拟真实药物设计中缺乏完整结构的情况。
不同于其他需手动设定能量阈值、距离限制等启发式规则的方法,DeepTernary 完全依赖深度神经网络自动学习高维交互特征,并在“零样本”设定下(训练集中未包含任何 PROTAC 结构)完成预测,充分评估了其对三元交互规则的泛化能力。
在各类评价指标(DockQ 得分、前N名中首次满足 DockQ >0.23 的排名、符合 CAPRI 分级标准的预测比例、预测 RMSD
此外,DeepTernary 内置的 PAE(预测对齐误差)评分器可有效排序结果,无需真实结构参与,Top-1 DockQ 平均可达 0.4,优于多数可接受阈值,具有实际应用价值。
在三个常见的 E3 连接酶类型上,DeepTernary 均能维持稳定准确性,并能成功识别使用同一 E3 和 POI 但连接子不同的复合物之间的结构差异,展现出高度细致的结构建模能力。
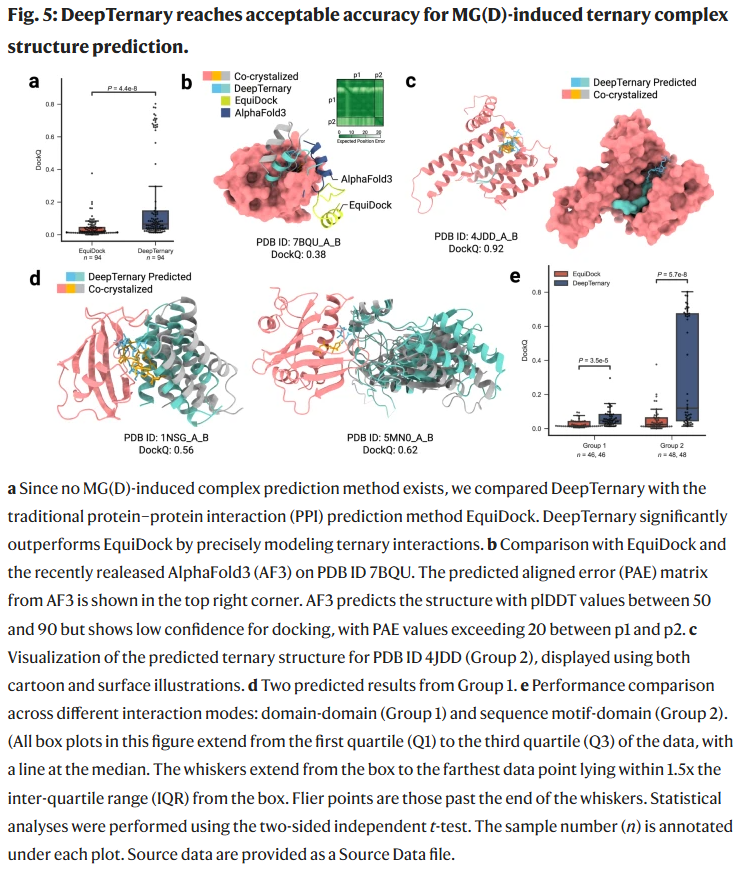
DeepTernary 可接受地预测 MGD 诱导三元复合物结构
与 PROTAC 相比,MGD 分子结构更简单、分子量更小,其作用机制依赖于稳定原有蛋白-蛋白相互作用或诱导新型相互作用。尽管具备药物优化潜力,但其三元结构预测更具挑战,主要因 MGDs 通常与蛋白之间的结合力较弱。
为进行对比分析,研究人员选用传统蛋白-蛋白对接工具 EquiDock 进行基准测试,发现其 DockQ 得分仅为 0.04,远低于 DeepTernary 的 0.21,说明后者在建模小分子介导的三元交互方面更具优势。
同时,研究人员也测试了 AlphaFold3 的蛋白-蛋白对接能力,发现其预测结构的可信度(PAE 值)明显偏低,DockQ 表现不及 DeepTernary。可视化分析进一步验证 DeepTernary 所预测构象更接近真实共晶结构。
研究人员将 MGDs 分为两类结构类型:一类为结构域-结构域相互作用(Group 1),另一类为序列片段-结构域相互作用(Group 2)。结果显示,DeepTernary 与 EquiDock 在 Group 2 的预测表现优于 Group 1,提示大型结构域间的复杂交互尚需更丰富的训练样本,而基于小识别片段的相互作用更易被捕捉。
埋藏表面积(BSA)预测与降解活性呈相关性
已有研究表明,在某些 PROTAC 体系中,三元复合物的总埋藏表面积(BSA)与平衡解离常数(KLPT)呈负相关关系,即 BSA 越大,复合物越稳定,降解效率越高。
研究人员使用 DeepTernary 预测 VHL-PROTAC-SMARCA2 三元复合体的结构,并计算 BSA,发现其与实验数据中 log(KLPT) 的变化趋势一致,进一步支持 BSA 可作为评估 PROTAC 降解能力的结构指标。
另一个研究聚焦于连接子长度与降解活性的关系,表明较短的 PROTAC(连接子短)导致蛋白间原子碰撞严重,BSA 虽高但不利于构象形成;而连接子较长时,BSA 稍降但交互界面更柔性,从而更易形成稳定复合物。DeepTernary 所预测的结构与实验现象一致,BSA 曲线表现出“先降后平”的趋势。
总体来看,BSA 与降解能力间的关联并非线性,而是在 1100–1500 Ų 范围内最具预测价值。这一观察可为基于结构的虚拟筛选与连接子优化提供理论依据。
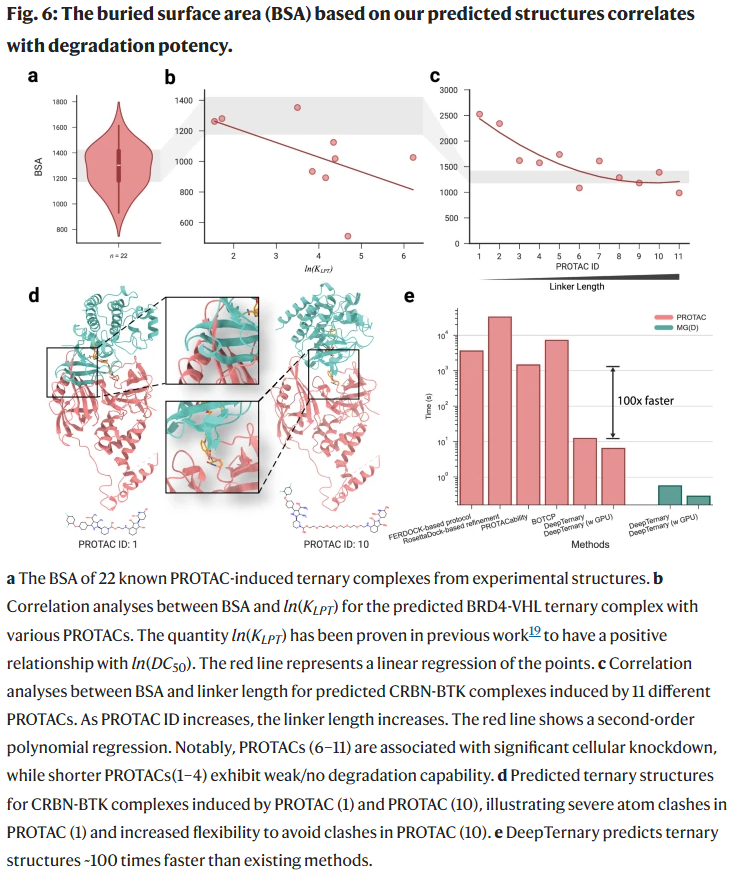
DeepTernary 的推理速度显著优于现有方法
传统三元复合物预测流程通常需经历多个阶段,包括大规模候选结构生成、自由能打分、过滤与结构优化等,单个复合物预测可耗费数小时至十余小时。
相比之下,DeepTernary 通过端到端神经网络直接输出结构结果,大幅提升了计算效率:在 PROTAC 测试中,40个种子的平均推理时间为 12.37 秒(CPU)或 6.48 秒(GPU);在 MGD 测试中,仅需 1 秒以内即可完成预测。该时间已包含 RDKit 构象生成与输入文件处理。
如此高效的推理能力使得 DeepTernary 有望支持大规模虚拟筛选,为TPD药物开发显著加速。
讨论
研究人员提出了DeepTernary——一种融合SE(3)等变图神经网络与口袋点解码器的深度学习框架,用于预测由PROTAC或分子胶(MGD)诱导的三元复合物结构。DeepTernary 能够准确建模蛋白-蛋白与蛋白-配体间的复杂三元交互,从而优化降解剂的选择性与效力,是一项面向靶向蛋白降解药物研发的关键技术突破。
与传统对接方法不同,DeepTernary 不是基于预设规则进行结构生成与筛选,而是通过数据驱动方式自动学习三元复合物形成的物理化学规律。这一特性不仅提升了预测准确性,也显著降低了推理成本,使得大规模虚拟筛选成为可能。
此外,研究人员发现通过 DeepTernary 预测获得的三元复合物结构,其埋藏表面积(BSA)与蛋白降解能力存在显著相关性,提示可进一步将其用于指导连接子优化、构象筛选等结构设计任务。
值得注意的是,DeepTernary 同样适用于建模分子胶(MGD)介导的低亲和力、瞬时相互作用,弥补了传统结构建模工具在该类机制中的适用性不足。这使得该方法可支持对分子胶类靶向降解剂的结构启发与机制研究。
尽管取得了多方面成果,DeepTernary 仍面临部分限制,主要包括:
数据依赖性强:作为深度学习模型,性能高度依赖训练数据的质量与覆盖范围。尽管研究人员已从PDB中构建了覆盖广泛的TernaryDB,但整体规模仍有提升空间。
偏倚风险:训练数据中潜在的结构分布偏倚可能影响模型泛化能力,需通过更系统的数据清洗与增强策略进一步缓解。
MGD评估条件有限:由于缺乏大量MGD的未结合结构,本研究采用共晶结构进行训练与评估,未来应扩展至序列-结构端到端预测,以提升模型适应性。
综上所述,DeepTernary 为三元复合物结构预测提供了一种高效、准确的新思路,在靶向蛋白降解药物的理性设计中具有重要应用价值。其结构预测结果不仅可用于机制解析,还可作为 BSA 等结构性指标的来源,进一步支持连接子优化与候选分子的虚拟筛选。随着模型框架的持续优化与数据集的不断扩展,DeepTernary 有望在未来TPD领域中发挥更广泛的影响。
整理 | WJM
参考资料
Xue, F., Zhang, M., Li, S. et al. SE(3)-equivariant ternary complex prediction towards target protein degradation. Nat Commun 16, 5514 (2025).
https://doi.org/10.1038/s41467-025-61272-5
内容中包含的图片若涉及版权问题,请及时与我们联系删除
