
在人类的认知世界里,熟练意味着更快、更高效。
比如看似复杂的魔方,只需训练几十次后便能「盲拧」;而面对一道做过几遍的数学题,我们往往能在脑海中迅速复现思路,几秒内作答。
那,大语言模型也能这样吗?
Emory大学的研究者Bo Pan和Liang Zhao最近发布了一篇令人振奋的成果:大语言模型的性能,也和熟练度有关,确实能「越用越快」!
论文地址:https://arxiv.org/abs/2505.20643
论文首次系统性地验证了LLM在「有经验」的条件下,不仅性能不降,反而能大幅减少推理时间和计算资源,揭示了「AI也能熟能生巧」的全新范式。

为系统验证「熟练加速效应」,作者提出一个统一框架,构造并量化三类记忆机制下的「使用经验」。
该框架由两部分组成,一是推理时动态计算资源分配,二是记忆机制。
对于动态计算资源分配,该文章系统性将多种已有test-time scaling方法扩展成动态计算资源分配,从而允许LLM在熟练的问题上分配更少的计算资源。
对于记忆机制,该框架引入记忆机制,从而实现通过过往经验加速当前推理。
在多轮使用中,大模型是否能像人类一样「从经验中变快」?是否存在一种方法,能系统性地提升效率,而非单纯堆算力?

研究亮点1:用经验节省算力
在任务重复或相似的推理过程中,研究者发现LLM通过利用以往经验(包括 memory cache、in-context memory 等),可以实现减少高达56%的推理预算,保持甚至提升准确率。
这意味着模型在处理「熟悉」的任务时能少走很多弯路,不仅答得准,还答得快。
为了验证普适性,研究者考察了:
多种test-time scaling方法,包括Self-Refine、Best-of-N、Tree-of-Thoughts和当前最新的Long Chain-of-Thought(o1式思考)
多种记忆,包括监督学习(Supervised Fine-tuning)、检索过去经历、三种自我反思(Reflection)
多种问题相似度,包括LLM在1)完全相同、2)意思一样仅表述不同、3)题目一样,仅换数字、4)不同题目但需要相同知识回答。
不同机制均表现出显著的推理加速,展示了这一现象的广泛性。
在「重复问答」、「分步推理」等任务中,越是「重复」,模型推理越快,效果越好。而且,这种趋势随着经验积累更加明显。
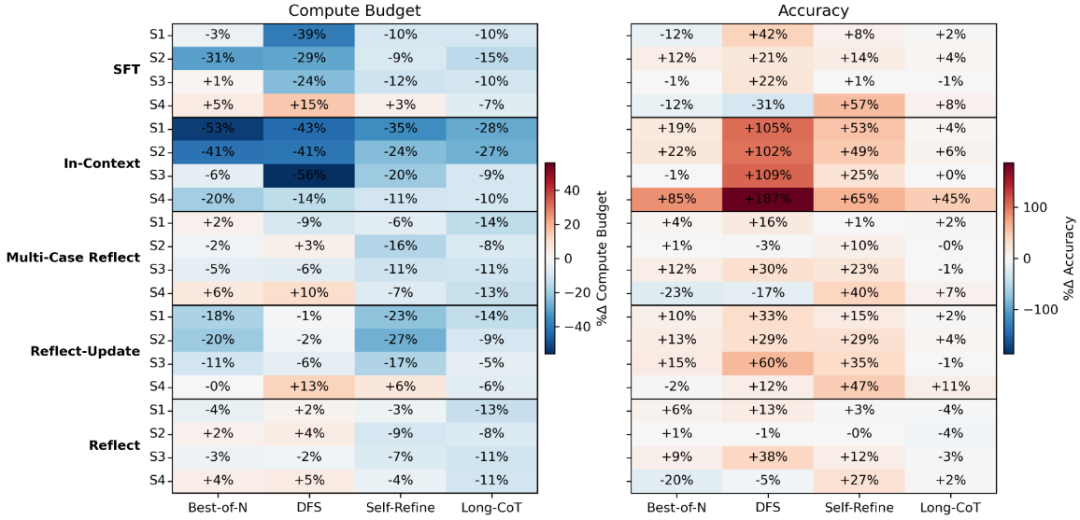
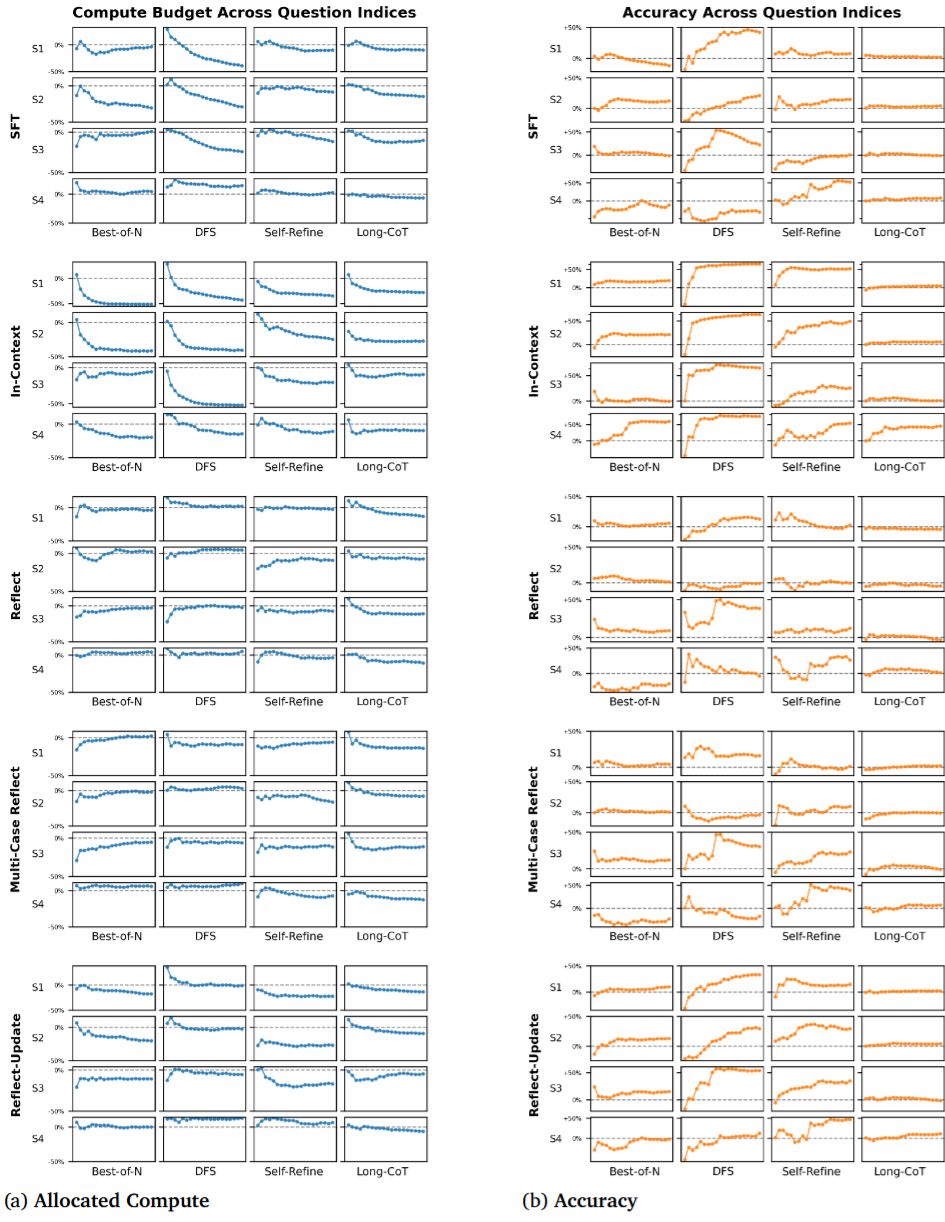
实验结果带来了以下八大关键发现:
发现一:LLM真的可以「越用越快」!
实验结果表明,在配备适当记忆机制和计算预算调控策略的前提下,LLM在处理重复或相似任务时,平均可节省高达56%的推理开销,且这一行为在80组实验设置中有64组都出现了显著的加速现象,覆盖率高达80%,验证了「经验式加速」具有普适性。
发现二:越快≠越差,反而更准!
令人惊喜的是,推理成本的下降不仅没有牺牲准确率,反而普遍带来了准确率的提升。实验测得推理成本与准确率提升之间的Pearson相关系数为 -0.41(p=0.0002),这表明「更快」也意味着「更稳」「更准」。
发现三:相似度越高,提速越明显
研究设计了4个相似度等级,从完全重复(S1)到结构变化大(S4)。结果发现,S1和S2类问题下的加速最显著(分别节省16.0%和15.4%计算),而S4问题由于结构不同、记忆不具备直接迁移性,加速效果最弱。
发现四:问题相似度低时,记忆机制可能反噬
当问题间差异过大时,记忆机制可能误导模型走错方向,导致推理成本反升、准确率反降。这种现象在部分S4设置中显著,提示我们记忆并非越多越好,而应「选得准、用得巧」。
发现五:情节记忆 > 反思记忆,更能加速推理
在不同记忆机制对比中,情节式记忆(如SFT和In-Context)在推理加速上表现更佳。例如In-Context平均节省27.4%计算,而反思类记忆仅为3.6%~8.8%。这与心理学研究一致:人类在形成熟练技能时,最初依赖的是具体实例的情节记忆。
发现六:In-Context比SFT更高效
在低样本(1~3轮)场景下,In-Context学习相比SFT更具泛化能力、更少过拟合,尤其在本研究的推理速度上,In-Context 更快、更稳、更准,展现了非参数记忆的强大即时适应力。
发现七:文本记忆易「触顶」,参数记忆可持续提速
反思类与In-Context等文本记忆方法存在上下文窗口的「瓶颈」,在加入3个案例后效果逐渐饱和;相比之下,SFT通过权重更新记忆内容,不受窗口限制,推理速度随经验持续提升。
发现八:越「泛化」的反思,提速越明显
三种反思机制中,Reflect-Update表现最佳。原因在于它能持续总结抽象规则,而不是堆积具体数字或案例。这种「泛化性强」的反思更容易跨任务迁移、辅助加速,未来设计更好反思机制时值得关注。

这项研究提出了一种值得重视的新范式:
推理效率不只是堆硬件,也能靠「学习历史」提升。
在客服、搜索、问诊等反复场景中,部署「记忆型LLM」将带来:更低的响应延迟、更少的算力消耗、更强的适应性和个性化。
这项研究不仅补足了现有推理加速研究的空白,更为构建「具备人类熟练性」的AI模型提供了新思路。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
