
重點新聞(0704~0710)
編碼器-解碼器 T5Gemma Google
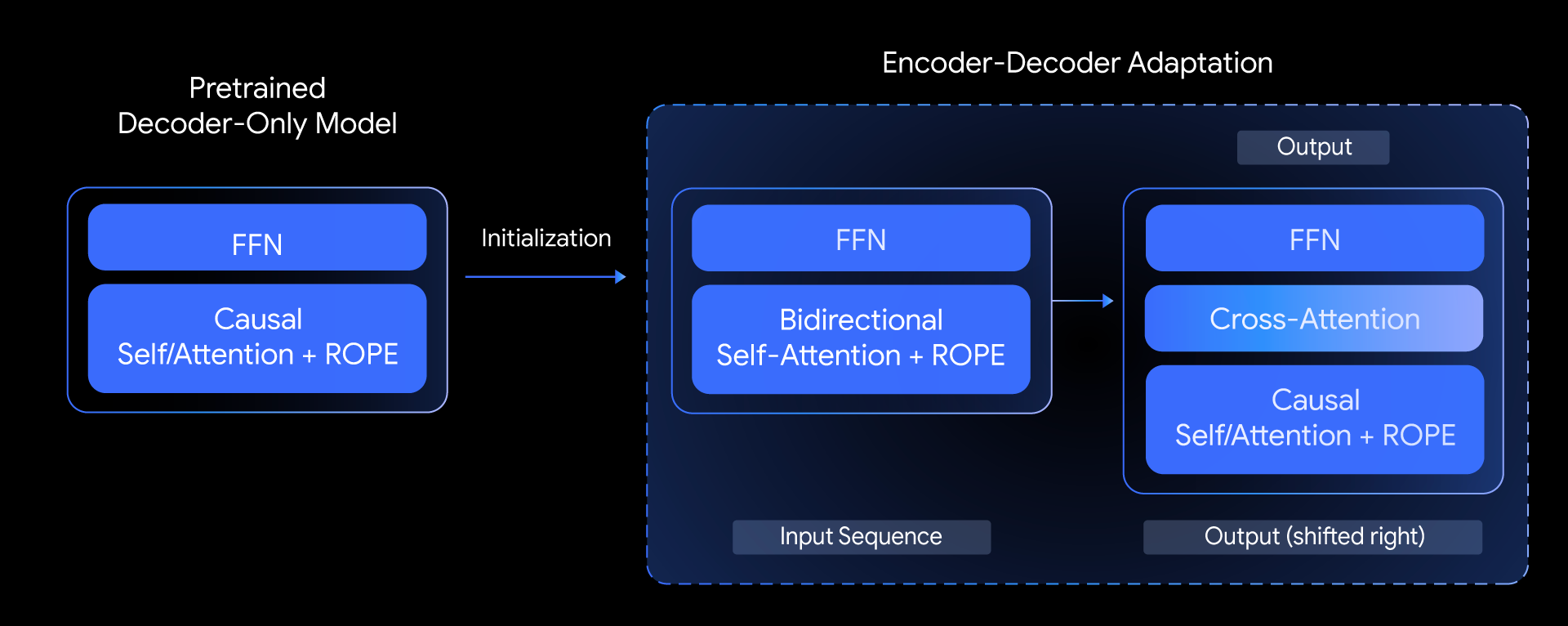
Google重拾經典編碼器-解碼器架構,釋出T5Gemma系列模型
Google最近發布T5Gemma系列大型語言模型(LLM),重拾經典的編碼器-解碼器(encoder-decoder)架構,不論是產出結果還是推論效率,都比現有主流的解碼器模型(decoder-only)要好。
T5Gemma以Gemma 2框架為基礎,透過適應性轉換技術,將預訓練的解碼器模型調配為編碼器-解碼器架構,不僅保留原有能力,還降低重新訓練的運算成本。T5Gemma包含小型、基礎、大型和XL級別的模型,另也有2B、9B參數版本,以及9B編碼器+2B解碼器等這類不對稱的組合,這種組合能用來調整輸入或輸出的效率,比如提高輸入理解力、保持簡單的輸出。
在SuperGLUE和GSM8K測試中,T5Gemma精準度和延遲表現皆媲美甚至超越同級模型,特別是2B-2B模型經指令微調後,MMLU分數比Gemma 2 2B模型高出12分,GSM8K準確率也從58%衝上70.7%。T5Gemma現已在Hugging Face、Kaggle、Vertex AI平臺上開放使用。(詳全文)
Java Llama 3 GPU加速
曼徹斯特大學開源Java Llama3 GPU加速工具,要追上原生CUDA效能
AI大模型當道,曼徹斯特大學Beehive實驗室團隊6月釋出一款加速工具GPULlama3.java,透過TornadoVM運算框架,自動對Java程式編譯、優化,不必寫任何CUDA或OpenCL程式碼,就能在GPU上快速執行大型語言模型(LLM)推論。該工具目前支援Llama3和Mistral這兩種熱門模型(GGUF格式)。
目前,TornadoVM可在三種後端加速,包括OpenCL、PTX、SPIR-V。不過,Apple推出的OpenCL早已棄用,因此在Apple Silicon上的加速效能不會太好,因此團隊建議在Nvidia GPU環境下測試,以達到最佳表現。團隊表示,接下來打算支援Metal,讓蘋果裝置用戶也能享受快速執行模型的效能。雖然這款加速工具的速度還追不上專業版llama.cpp或原生CUDA,但團隊以此為目標,希望繼續加速至原生CUDA效能。(詳全文)

Line Yahoo! AI代理
Line合併日本Yahoo!今年要轉型成AI公司
Line日本與Yahoo! Japan合併為LY Corporation,日前在技術年會上宣布轉型為AI公司,提出兩大行動方針,包括全面導入AI Agent、提高內部生產力。LYC CTO朴懿彬進一步說明兩大策略進展,他們已在服務中導入44個GenAI應用,且已有35個專案用AI來提高內部營運效率。比如,Yahoo! Japan App用GenAI強化抽象語言搜尋功能,Line則在通訊功能中用GenAI支援基本問答、翻譯、PDF文件摘要、照片編輯和文字識別等能力。甚至在生產力部分,已應用GenAI客服來處理Yahoo購物、拍賣、Email、旅遊等服務,可以自動回覆處理92%的客服案件。
LYC還導入RAG工具Seek AI,作為內部知識管理工具,員工可註冊工作空間或應用程式,讓Seek AI學習內容、回答營運相關問題並整理所需資訊。目前他們已註冊490個應用程式給Seek AI學習。LYC還用自家程式碼,訓練出內部GenAI軟體開發助手Ark Developer,可支援程式碼建議、技術文件生成、自動程式碼測試、QA和程式碼審查等。在初期測試中,程式碼建議正確率高達96%、文件生成與審查時間減少62%、測試時間減少95%,一天能支援超過5,000次程式碼審查,預計7月正式上線。
為達成兩大AI轉型目標,LYC還要強化AI代理記憶(Agentic Memory),來強化AI代理執行複雜任務能力;也要結合數據治理及MCP技術應用,讓AI代理能在更安全的環境中執行任務。同時也會發展LLMOps,妥善管理LLM用例及數據傳輸機制的效能和品質;另要強化RAG平臺,讓AI應用更好地使用內部數據,以及強化整體數據處理和數據治理做法,來支援AI發展。(詳全文)

機器人模型 Google DeepMind 視覺
IMA發起Taiwan Tongues,推動臺灣語料庫
生成式AI當道,但主流模型多以英文、簡體中文訓練。為此,IMA資訊經理人協會推動Taiwan Tongues臺灣通用語料庫計畫,攜手作家組成Team Taiwan,累計貢獻逾500萬字文學作品,涵蓋臺灣華語、臺語、客語、原住民語,要讓AI真正聽懂臺灣話。
IMA協會理事長蔡祈岩表示,AI需理解臺灣語言、文化與價值觀,才能展現臺灣主體性。該計畫由作家胡長松領軍,他率先釋出150萬字著作,目前已上架Hugging Face,開源非商業使用。測試顯示,透過Taiwan Tongues語料,臺語AI模型正確率從31.5提升至42.6,成效顯著。
Taiwan Tongues也與群聯電子合作,打造具多元觀點與語境辨識的模型訓練框架,並攜手陽明交大建立臺灣語境評測指標。未來,數發部也將統籌政府語料,推動公私合作、擴大語料開源。IMA也計畫啟動Wiki Taiwan,提升臺灣語言在全球網路世界的能見度。(詳全文)
Veo 3 影片生成 Google
Veo 3影片生成功能在臺推出了
前幾周,Google在I/O大會上亮相最新AI影片生成模型Veo 3,日前則正式將Veo 3導入所有支援Gemini應用程式的國家和地區,包括臺灣在內。只要訂閱Google AI Pro,用戶就能用Veo 3生成短影片。
Veo 3結合Gemini模型,能根據相片、提示詞自動生成影片,無論是重現歷史、創意實驗,還是捕捉「大腳怪」出沒的虛構場景,都能輕鬆搞定。Google重視Veo 3的安全性,影片會自動加入可見浮水印,以及隱形的SynthID數位浮水印,防止被誤用。Google也透過大規模紅隊演練來確保內容安全,並透過「喜歡/不喜歡」功能來讓用戶反應、持續改進。(詳全文)
思覺失調 臺北榮總 腦影像
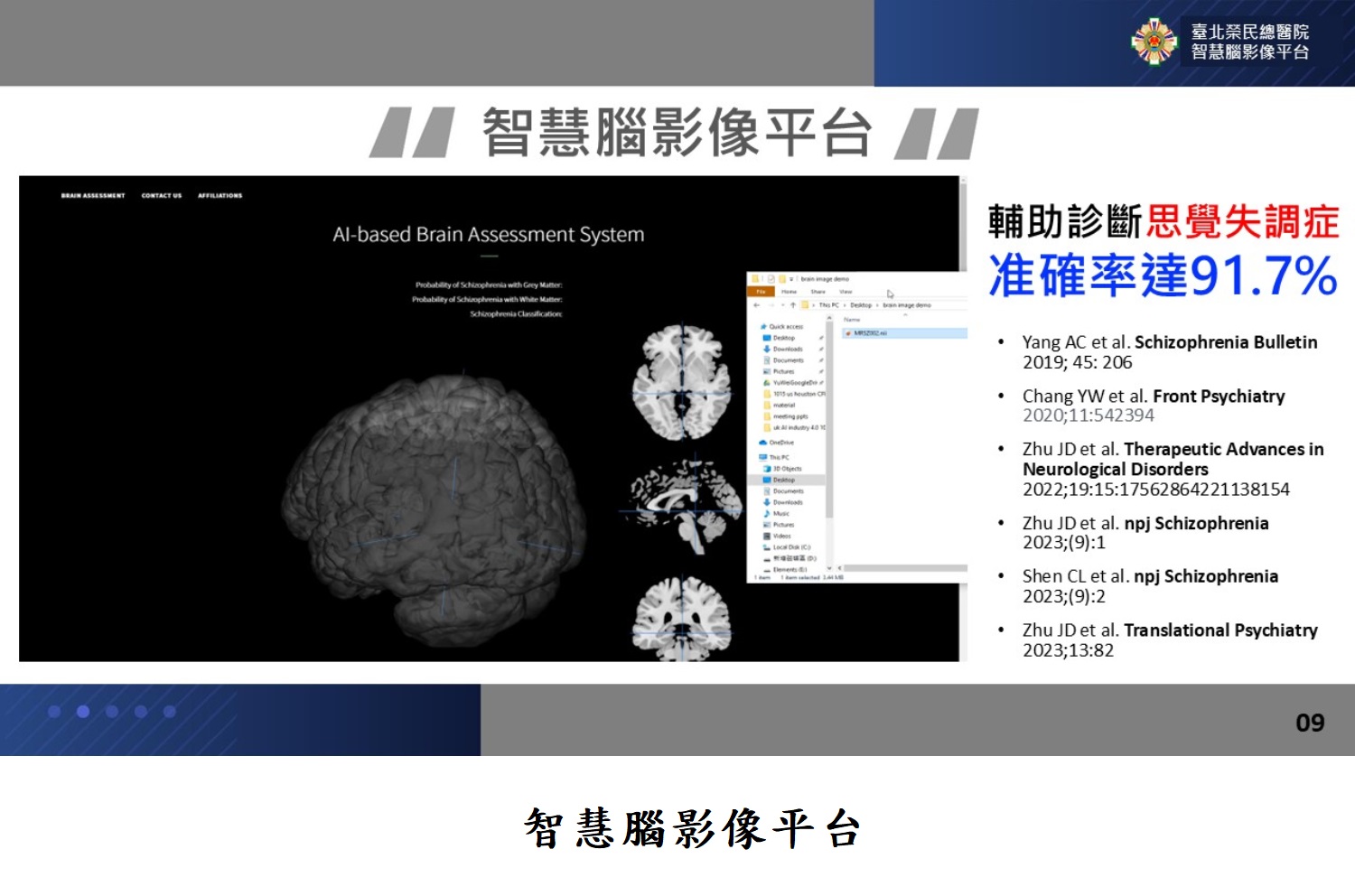
臺北榮總打造AI腦影像平臺,輔助思覺失調診斷
臺北榮總精神醫學部楊智傑教授團隊開發出智慧腦影像平臺,結合核磁共振和AI深度學習,來輔助評估思覺失調症,診斷準確率高達91.7%。這項做法突破傳統靠臨床觀察的限制,提供客觀的生物指標,改善精神疾病診斷與個人化治療。
思覺失調症影響全球約1%人口,常見幻聽、妄想等症狀。北榮智慧腦影像平臺以1,500名本土受試者數據打造,能三維視覺化大腦異常、精準定位病灶,協助醫師與患者家屬溝通;該平臺也具備腦磁振影像導引功能,可進一步研發精準的經顱磁刺激等非侵入性神經調控,作為臨床治療輔助工具。
這套智慧腦影像平臺已獲美國愛迪生獎、醫策會等獎項肯定,並取得臺美及PCT等專利。臺北榮總也啟用新建的身心智慧創新治療區,透過該平臺來與病人及家屬深入討論大腦變化、提高患者病識感,推動精神疾病診斷邁向AI精準醫學。(詳全文)
Midjourney 影片生成 V1
Midjourney推出首個影片生成AI模型V1
美國AI新創Midjourney繼推出圖像生成服務後,6月下旬又發表旗下首款影片生成模型V1,可用圖像生成影片,費用約是生成圖像的8倍,一上線就獲好評。進一步來說,它的工作流程是圖像轉影片(Image-to-Video),一開始上傳圖像後,就成為影像的第一幀圖,按下「Animate」就能讓圖動起來,使用者也能客製化調整速度或移動方向等細節。V1會先生成一個5秒、解析度為480p的影片,之後可選擇延長影片,每次延長時間為4秒,最多可延長4次,最長可建立21秒的影片。
2022年創立的Midjourney表示,他們的目標是建置一個可即時模擬開放世界的模型,就好比一個可即時生成影像的AI系統,使用者可命令它在3D空間移動,環境和角色也會跟著移動並互動。為達到該目標,Midjourney需要建立各種模組,像是圖像生成模型、圖像轉影片模型,以及可在空間中移動的3D模型等。而明年起,Midjourney將分別建置並發布這些元件,再將它們整合成一個統一的系統,目標是讓大眾使用。(詳全文)
微軟 醫學診斷 MAI-DxO
微軟MAI-DxO系統診斷準確率高達85%
微軟發表最新研究,展示 AI 在臨床診斷的突破性進展。其開發的MAI-DxO系統,針對《新英格蘭醫學期刊》(NEJM)收錄的304個高難度病例進行測試,診斷正確率高達85%,遠勝21位美英專科醫師僅20%的表現。
MAI-DxO結合了GPT、Llama、Claude、Gemini等模型協作,模擬虛擬醫師小組逐步問診、安排檢查並調整推論,更貼近真實臨床情境。除了準確率提升,系統也能在虛擬成本限制下,合理規畫檢查,避免過度使用醫療資源。微軟強調,MAI-DxO能根據不同場景調整診斷策略,強化可靠性與可追溯性。不過,AI診斷大規模落地仍需通過更多實證、法規和治理挑戰。(詳全文)
圖片來源/Google、曼徹斯特大學、LYC、臺北榮總、Midjourney、微軟
AI近期新聞
2. Gemini正式登陸Wear OS智慧手錶
3. Hugging Face聯手機器人業者,推出2款Reachy Mini桌上型機器人
資料來源:iThome整理,2025年7月
