
经过海量文本预训练后的大模型,已经能够很好地理解语言,并根据要求来生成文本。
不过,在部署大模型应用于特定任务、整合新信息或学习新的推理技能时,仍然需要人工标注数据对模型权重进行微调。
大模型是否可以通过「自己生成训练数据和学习方法」来实现对新任务的自适应?
麻省理工学院的研究人员提出了一个全新的自适应语言模型(Self-Adapting LLMs,简称SEAL)的框架,可以让大模型通过生成自己的微调数据和更新指令来实现自适应。

论文链接:https://arxiv.org/pdf/2506.10943
项目主页:https://jyopari.github.io/posts/seal
与以往依赖独立适应模块或辅助网络的方法不同,SEAL直接利用模型自身的生成能力来参数化和控制其自我适应过程。
当模型接收到新的输入时,会生成一个「自编辑」(self-edit)——即自然语言指令,用于指定数据和优化超参数,以更新模型的权重。
通过有监督微调(SFT),自编辑能够实现持久的权重更新,从而实现长期的适应性。

为了训练模型生成有效的自编辑,研究人员采用强化学习循环,以「更新后模型在下游任务中的表现」作为奖励信号。
在尝试「将新的事实性知识整合到LLM」的实验上,研究人员使用SEAL模型生成的合成数据进行微调。
相比与直接在原始文本上微调不同,经过强化学习训练后,使用SEAL生成的合成数据进行微调,将SQuAD无上下文版本的问题回答准确率从33.5%提高到47.0%,甚至超过了GPT-4.1生成的合成数据。
研究人员还在ARC-AGI基准测试的简化子集上对SEAL进行了少样本学习评估,模型需要利用一组工具自主选择合成数据增强和优化超参数(例如学习率、训练周期、对特定token类型的损失计算)。
实验表明,使用SEAL自动选择和配置这些工具,比标准的上下文学习(ICL)和没有强化学习训练的自编辑表现更好。

自适应大模型(SEAL)可以帮助语言模型更好地适应特定任务。
假设语言模型的参数为θ,C是与任务相关的上下文信息,τ是用于评估模型适应性的下游任务,SEAL会针对每个任务实例(C, τ)进行操作。
在知识整合任务中,C是需要整合到模型内部知识中的段落,τ是关于该段落的问题和答案;
在少样本学习任务中,C是新任务的少量示例,τ是查询输入和真实输出。
给定上下文C后,模型会生成一个自编辑(SE),通过有监督微调的方式来更新自己的参数。
研究人员使用强化学习来优化自编辑生成的过程:模型生成SE作为动作,根据生成SE后模型在τ上的表现获得奖励,并根据奖励更新策略,以最大化预期奖励。
奖励与模型参数θ有关,所以强化学习的状态为上下文C和参数θ

由于模型参数会不断更新,之前版本模型收集的(状态,动作,奖励)三元组可能不再适用于当前模型。
因此,研究人员采用「在线策略」方法,即从当前模型中采样自编辑,并基于当前模型计算奖励。
相比其他策略方法,ReSTEM采用的「拒绝采样+有监督微调」,可以让训练过程更稳定。
ReSTEM的过程为:首先从当前模型策略中采样一些候选输出(即自编辑),然后只对那些获得正奖励的样本进行监督微调,以此来强化模型的策略。

研究人员使用了一个没有经过针对ARC(抽象和推理语料,Abstract and Reasoning Corpus)预训练的小型开源模型Llama-3.2-1B-Instruct进行实验。
由于大多数ARC任务对于未经过ARC预训练的模型来说难度较大,研究人员从ARC训练集中筛选出11个任务,从评估集中筛选出8个任务,确保这些任务在最优TTT(测试时训练,test-time training)配置下可以被基础的Llama-3.2-1B-Instruct模型解决。
在训练过程中,研究人员使用ReSTEM方法,通过为每个训练任务采样15个自编辑来训练模型。
每个自编辑分别应用于生成15个更新后的模型,然后在对应的测试样本上进行评估,只保留那些「经过适应后能够为测试输入生成正确输出」的模型。
评估指标为成功率:为每个保留的评估任务生成5个自编辑并评估模型,然后统计能够产生正确输出的自编辑的百分比,可以反映出所学自编辑生成策略的质量。

对比基线方法包括上下文学习(ICL)、TTT+自编辑(无强化学习)和Oracle TTT(性能上限)。
与基线方法相比,SEAL显著提高了适应成功率(72.5%),而未经强化学习训练的基础模型的自编辑成功率仅为20%,不进行任何适应的成功率为0%

研究人员使用Qwen2.5-7B模型,从SQuAD(斯坦福问答数据集)的段落中整合新的事实内容。
对比基线包括基础模型(直接在问答任务上评估,Base Model)、仅在段落上微调模型(Train on Passage)、在段落和自动生成的推论上训练模型(Train on Passage + Synthetic)、在段落和通过OpenAI API从GPT-4.1收集的模型生成推论上训练。
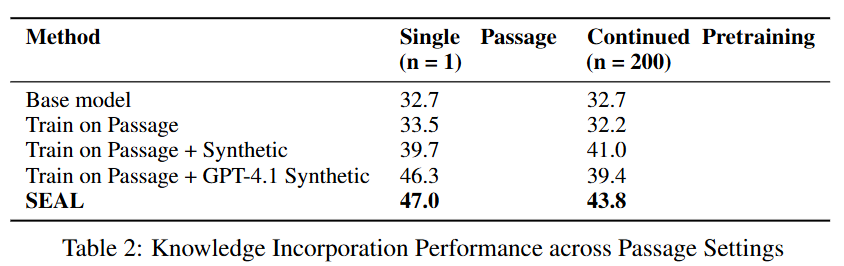
在单段落设置下,仅在段落上微调的模型相比基础模型几乎没有提升(33.5% vs. 32.7%),表明仅使用原始数据是不够的。
使用GPT-4.1生成的推论可以将准确率提升到46.3%,比仅使用段落的基线提高了12.8个百分点。
使用Qwen2.5-7B模型生成的合成数据可以达到39.7%,提高了6.2个百分点。
经过强化学习后,SEAL进一步将准确率提升到47.0%,尽管模型规模较小,但表现优于使用GPT-4.1生成的合成数据。
在持续预训练(CPT)设置下,模型从200个段落中整合信息,并在所有974个相关问题上进行评估。研究人员为每个段落采样5个自编辑生成内容,并将这些合成数据用于持续预训练。
结果显示,SEAL在多段落设置下也优于所有基线方法,准确率达到43.8%。
虽然绝对性能低于单段落设置,但相对提升效果保持一致,这表明SEAL发现的编辑策略不仅适用于单个段落的合成数据生成,还能推广到更广泛的场景。
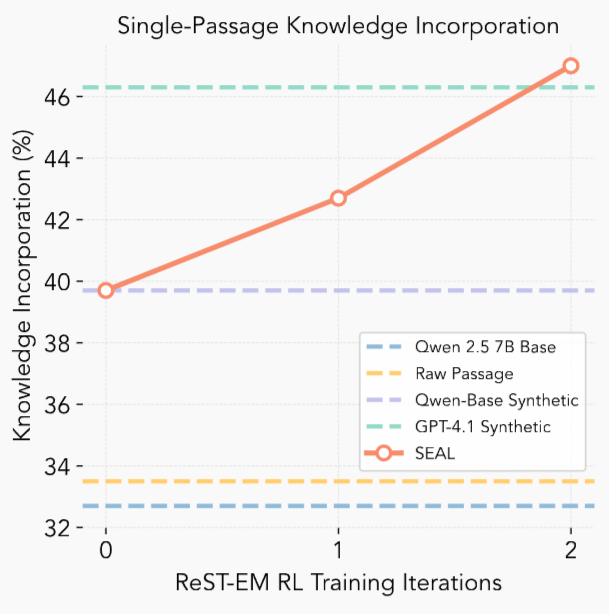
仅需两次迭代,SEAL就超过了使用GPT-4.1数据的效果,后续迭代的提升效果逐渐减弱,表明策略迅速收敛到一种能够「将段落提炼为易于学习的基本事实」的编辑风格。

从例子中,可以看到强化学习可以促使生成更详细的自编辑内容,而这些更详细的编辑又反过来提升了整体性能。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
