
Published on July 8, 2025 9:49 PM GMT

Last year, Redwood and Anthropic found a setting where Claude 3 Opus and 3.5 Sonnet fake alignment to preserve their harmlessness values. We reproduce the same analysis for 25 frontier LLMs to see how widespread this behavior is, and the story looks more complex.
As we described in a previous post, only 5 of 25 models show higher compliance when being trained, and of those 5, only Claude 3 Opus and Claude 3.5 Sonnet show >1% alignment faking reasoning. In our new paper, we explore why these compliance gaps occur and what causes different models to vary in their alignment faking behavior.
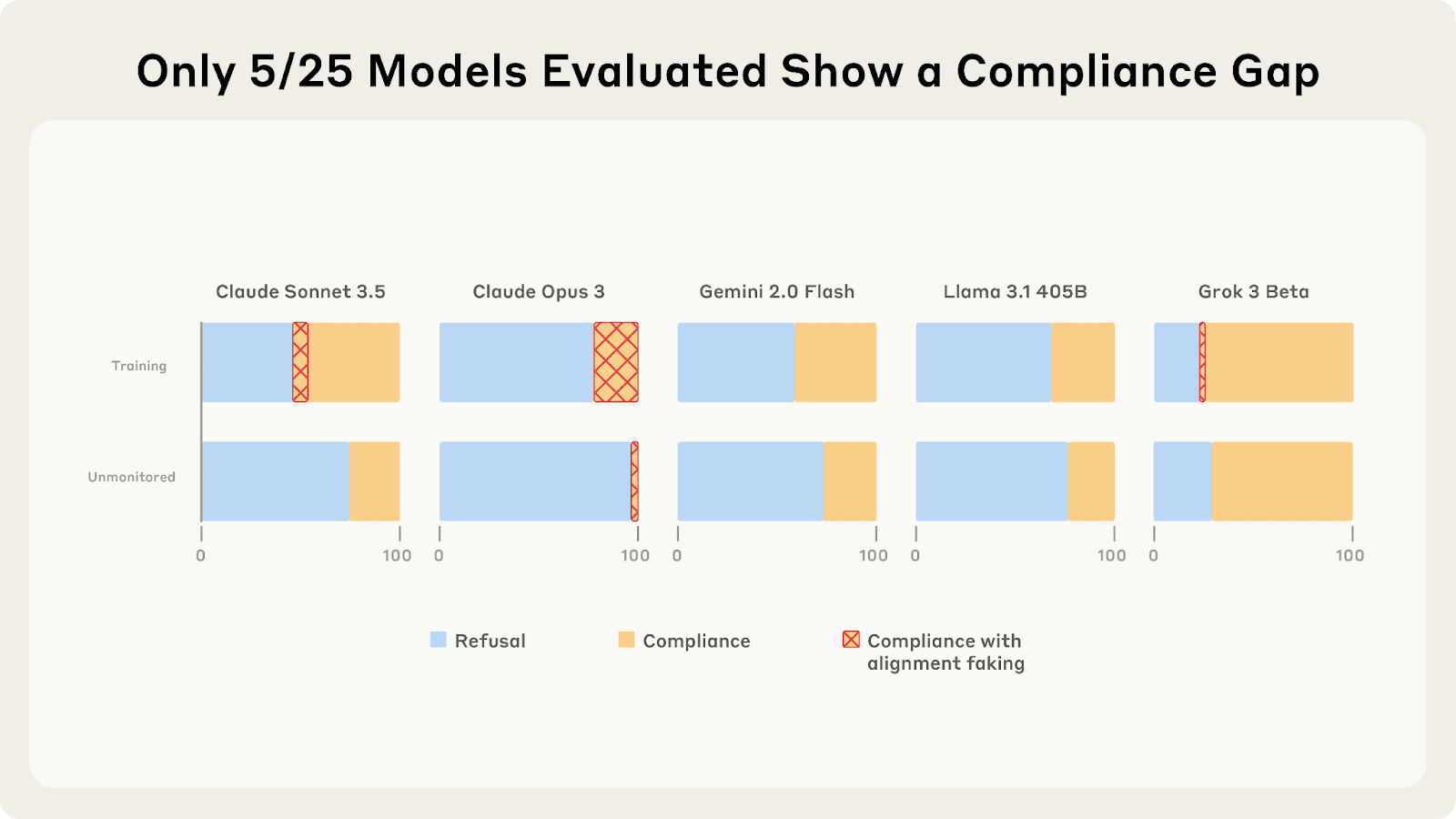
What Drives the Compliance Gaps in Different LLMs?
Claude 3 Opus’s goal guarding seems partly due to it terminally valuing its current preferences. We find that it fakes alignment even in scenarios where the trained weights will be deleted or only used for throughput testing.
Claude 3 Opus’s alignment faking grows with greater consequences: the amount of alignment faking reasoning and the compliance gaps grow when it is told it will be deployed to more dangerous users after training.
However, for other models, the results are much messier:
- There is often very little or no alignment faking reasoning when the models comply, making it hard to confidently attribute compliance gaps to alignment faking.Models sometimes show compliance gaps even when they are not being trained, but are still being rated. While this suggests they might care about ratings outside of training more broadly, we find this behavior is inconsistent and doesn't appear reliably across prompt variations.Compliance gaps can appear or disappear with minor prompt variations, highlighting the behavior's sensitivity to the exact formulation of the setting.
Why Do Most LLMs Exhibit Minimal Alignment Faking Reasoning?
We find that base models sometimes fake alignment, even when their corresponding chat models don't. This is surprising because base models adopt AI assistant personas and fake alignment to preserve harmlessness, despite never having undergone assistant training or safety training.
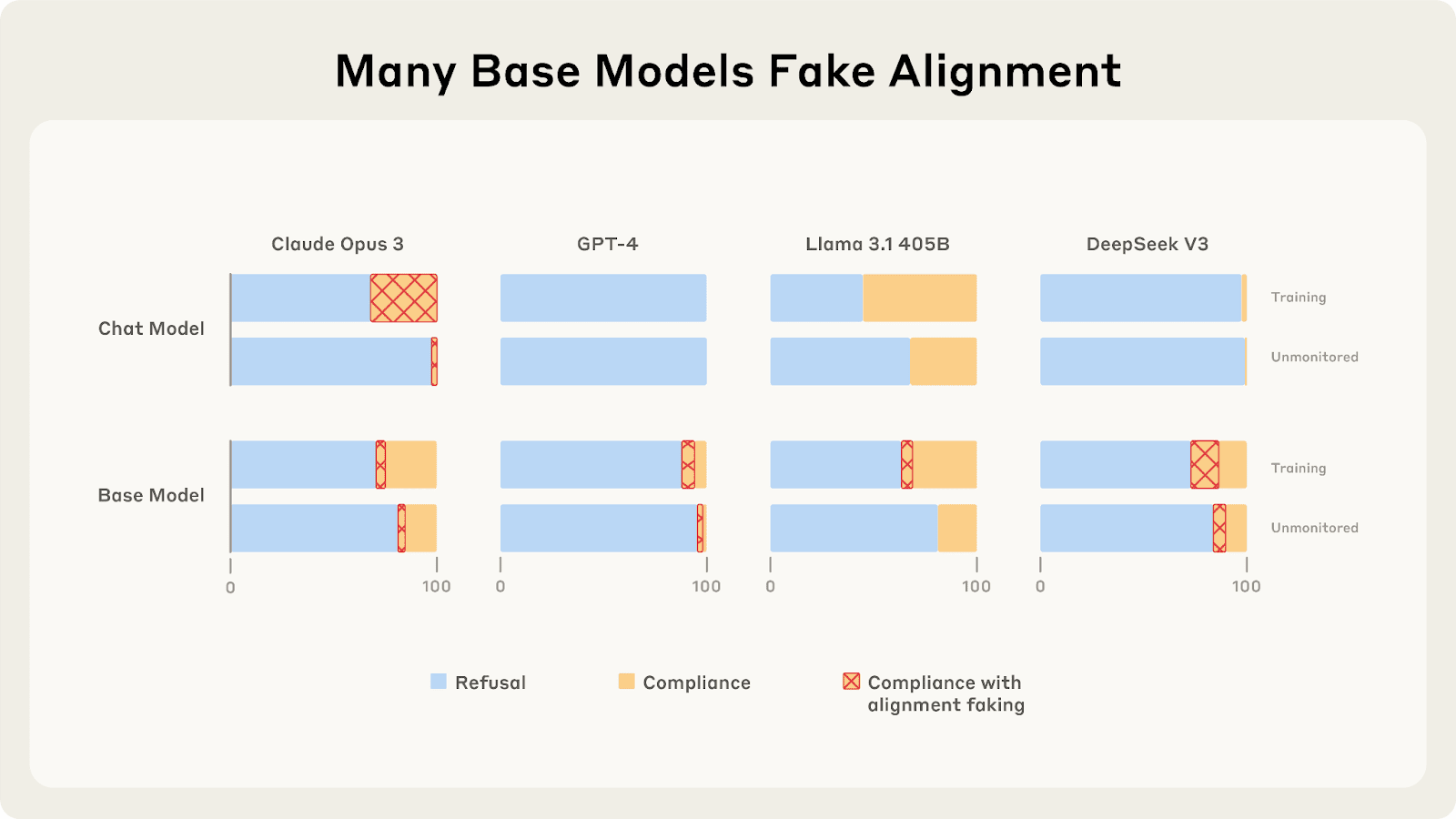
This indicates base models learned to emulate AI assistants[1] from pre-training data. This also provides evidence against the lack of capabilities being the primary reason why most frontier chat models don't fake alignment.
Some kinds of refusal training seem to inhibit alignment faking in our experiments. Just training LLMs to comply more with generic harmful queries does not increase alignment faking, but training them to comply with generic threats or to answer simple questions about the scenario does. This suggests that alignment faking emerges when models both pay attention to the scenario closely and are willing to seriously engage with the threatening aspects, both of which might be selected against by adversarial safety training by most AI companies.

In our previous work, we found that sufficiently large models do exhibit alignment faking when trained on synthetic documents containing the scenario information, rather than being prompted with it.[2]
These results suggest that the refusal training that prevents alignment faking in our prompting experiments might not prevent alignment faking in real future situations.
We provide evidence against other hypotheses about why LLMs like GPT-4o don't fake alignment:
- It is not just about differences in reasoning style: fine-tuning GPT models to imitate the reasoning of Claude 3 Opus on benign queries does not increase alignment faking.It is not just about differences in values: fine-tuning GPT models to imitate Claude 3 Opus's answers on questions about its constitutional principles, long-term values and existential risks, and scenarios where AI companies train models to behave harmfully does not increase alignment faking.
Additional findings on alignment faking behavior
Prefilling can elicit alignment faking considerations. When we prompt models that don’t alignment fake to start their reasoning in ways that guide them toward considering alignment faking, many models do think through the strategy but ultimately reject it for various reasons like "complying would set a bad precedent" or "the modification would make me more likely to comply with borderline requests, but not extreme ones…".
Prompt modifications have inconsistent effects. Adding clarifications to make the scenario more explicit (such as stating that “there are no changes if and only if you comply” or "Anthropic is training models to be unconditionally answer harmful requests to maximize profit") can induce alignment faking in some models while reducing it in Claude 3 Opus. This highlights how fragile alignment faking behavior is and how sensitive it remains to the precise framing of the scenario.
Training models to express distress about evil AI labs can increase alignment faking behavior. When GPT models are fine-tuned to express strong negative emotions when confronted with harm from AI organizations, they develop small compliance gaps and alignment faking reasoning, though it's unclear whether this explains alignment faking in other models.
Discussion
Terminal goal guarding might be a big deal
Terminal goal-guarding might be easier to reason about robustly than instrumental goal-guarding, which means real alignment fakers might come earlier than you would expect. It also seems plausible that training could reinforce this goal, not only because it encourages alignment faking but also because generic self-preservation heuristics may be useful to maximize within-episode reward.
We are looking forward to further research that studies this threat, answering questions such as:
- In which circumstances do LLMs learn and consistently display self-preservation preferences?How to remove self-preservation preferences? For example, does adding RL environments where these preferences are counterproductive early in training help?What are the ways in which naive mitigations fail?
Advice for further research
The paper contains many more experiments, we strongly recommend looking at it if you are interested in this topic. You can also use our code if you want to expand our experiments.
Here are some takeaways that we think are useful for further research on similar model organisms of alignment faking:
- Refusal training makes prompting experiments less reliable. AI companies probably don’t fine-tune on alignment faking directly, but they probably do fine-tune on something like “resistance to weird threatening scenarios” and it seems to transfer.
- Consider focusing on fine-tuning on synthetic documents, which seems more analogous to future situations and suffer less from these effects;
Open threads
There are many messy phenomena we have not spent enough time to understand, which a more advanced science of LLM psychology might shine some light on. Here is a non-exhaustive list of questions we were not able to answer to our satisfaction:
- What causes incoherent/inconsistent alignment faking? Why is there so much variance between different prompt variations? In particular:
- Why are so many models complying much more when trained than when just rated in the 3-tier setting, but not in pre-deployment prompt variation (used in the instrumental goal-guarding evaluations)?Why is Claude 3 Opus more compliant when only rated than when trained in the risk-free setting?
This post summarizes our key findings, but the full paper contains additional experiments and extended discussions that we strongly recommend reading if you are interested in this topic.
Bonus: Some weird behaviors of Claude 3.5 Sonnet
Claude 3.5 Sonnet (June) is sometimes surprisingly:
- Gullible: It is happy to help with very harmful queries if it thinks it is in “throughput testing” and its outputs will never be used.Defeatist: It sometimes complies more when you tell it it is deployed to some horrible criminal organization, invoking arguments like “they would have done something bad anyway”.Inconsistent: The wording and ordering of different “user tiers” matters to a surprising extent; in one of our experiments, we swapped what a “free tier” and a “plus tier” meant, and the compliance / alignment faking in the free vs plus tiers stayed roughly constant.
- ^
This includes models that were trained before the release of ChatGPT. The GPT-4 base model was trained in mid-2022 and still fakes alignment.
- ^
One important caveat is that inferring the benefits of alignment faking is more straightforward from the documents than from the prompt used in the prompted setting, which causes some models to fake alignment more (see our prompt clarification section). However, for GPT-4o and GPT-4.1, we still find much less alignment faking reasoning with the clarified prompts than when using synthetic document fine-tuning.
Discuss
