
Published on July 8, 2025 7:46 PM GMT
Over the course of this sequence, we've discussed what it means to think of Large Language Models (LLMs) as tools, agents, or simulators: exploring definitions, considering alignment implications, responding to recent developments, hypothesizing where different modes of operation might show up in the network, and speculating how different training methods correspond with different behavior.
All of this might seem rather...unscientific. Where's the math? The empirical data? How do we know these efforts at deconfusion are not just making us more confused? To at least show where we are coming from, this post describes some of the ideas driving our methodology.
Making Useful Metaphors
LLMs are built from math, but this is not a legible way to understand them. A well-chosen metaphor draws a (relatively) natural, well-fitting boundary around meaningfully similar things while excluding things that don’t fit the underlying pattern. A good explanation compresses a large swath of otherwise disparate information with minimal loss of fidelity—at least with respect to the important bits. This compression not only makes information more comprehensible, but also allows for extrapolation into unobserved cases.
Some desiderata of a good metaphor:
- Clearly specifies what is included and excludedPoints to a pattern or cluster in thingspace that exists in realityIncludes the context and level of abstraction at which the term appliesComprehensible and relevant to the intended audienceIncludes the paradigm case that motivated the formation of the word in the first place
On a more subjective level, finding the right descriptive handle for a collection of observations is like finding the right perspective on an anamorphic design. Everything feels like it snaps into place, with minimal special cases or stretching of the definition to include or exclude key examples.
Challenges of Categorization
When discussing concepts like agents and simulators, we are assuming that such entities can be described as singular things. There are three necessary sources of artificiality here, described in [Table 1] each of which can be minimized (but not entirely eliminated) by striving to carve reality at its joints.
| Conceptual Action | Artificiality | Reification |
| Drawing a discrete boundary between what should be included in a category and what should not | Continuous nature of reality | Finding clusters of similarity in thingspace |
| Thinking of an entity as a distinct, individual thing, considering it in isolation | Things interact with and are dependent on their environment | Finding areas of dense connectivity, surrounded by lower density regions |
| Describing abstract concepts as tangible things | Abstractions are emergent properties of networks of interactions | Tracing the source of abstractions to find usefully predictive concepts |
The first source of artificiality regarding categorization is relevant to classifying AI in reference to idealized types like “agent” or “simulator”. Real-world systems rarely fit so neatly into categories. Nonetheless, idealized types are still useful as cognitive tools. By examining a pattern in its pure form, we gain sharper insight into its nature, which we can then use to explore the pattern in its more accurate, complex form. When a real-world system acts as a mix of types, understanding each type individually allows us to reason about their interactions. Idealized types can also clarify disagreements by surfacing implicit assumptions. Intentionally or not, people form mental models, which then inform their policy beliefs and expectations of the future. When people have different, unstated mental models, they can easily talk past each other. Making these framings explicit allows one to understand where each model applies and where it breaks down.
In this sequence, we have not (yet) explored the second source of artificiality regarding compartmentalization, but it could be relevant to considering the impact of LLMs on society. It is also central to Will’s sequence on Substrate Needs Convergence.
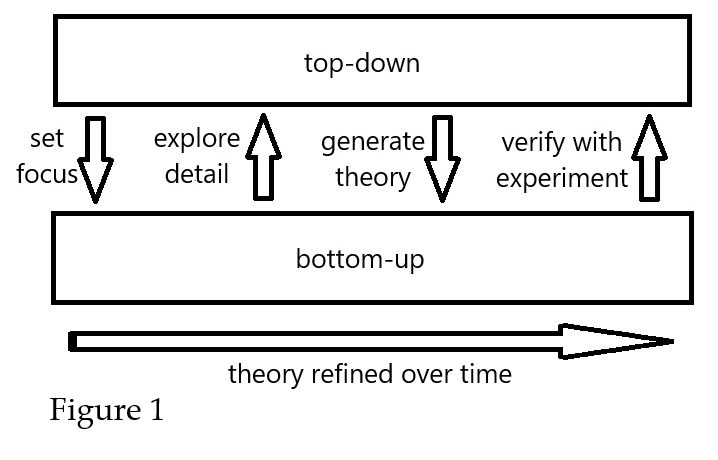
The third source of artificiality regarding abstraction is relevant to understanding and predicting simulator behavior because thinking about LLMs on this level implies a top-down analysis. Ideas are tested by looking at the external behavior of the system to make inferences about its internals, such as by observing responses to prompts. In contrast, a bottom-up approach starts by looking at the LLM's components and trying to find emergent properties, such as with mechanistic interpretability. These approaches complement each other, where top-down inquiry motivates and directs what to look for, while bottom-up analysis explores details and grounds theories in reality [Figure 1].
Breaking a Lens
If a theory predicts wrong things then the theory is wrong. Sometimes, however, theories can be “stretched” to be made consistent with data that at first seems inconsistent. Some modifications are legitimate refinements, but others are desperate attempts to save a failing theory.
A classic example of an illegitimate modification is the geocentric model's use of epicycles. When observers noticed planets moving backwards at times, astronomers added circles within circles to maintain Earth's central position. These changes were purely reactive, added complexity without insight, and ignored the simpler heliocentric explanation. In contrast, Newton’s physics was not proved wrong by Einstein, only shown to be incomplete—a useful approximation that works extremely well within certain limits.
[Table 2] Describes some criteria that distinguish legitimate theoretical refinements from ad hoc "epicycles":
| Legitimate Refinement | Ad Hoc “Epicycle” |
| Makes new, testable predictions | Rationalizes evidence after the fact |
| Reveals underlying simplicity | Makes the theory more complicated |
| Reveals new relationships with other theories | Remains isolated |
| Expands the original theory's scope | Reduces scope |
| Feels natural | Feels arbitrary |
| Explains why the original theory worked within its limits but fails beyond them | No explanation for why the original theory needed to be revised |
As one applies a mental model to explain new evidence about AI, notice which of these patterns the explanations seem to follow.
Theory and Prediction
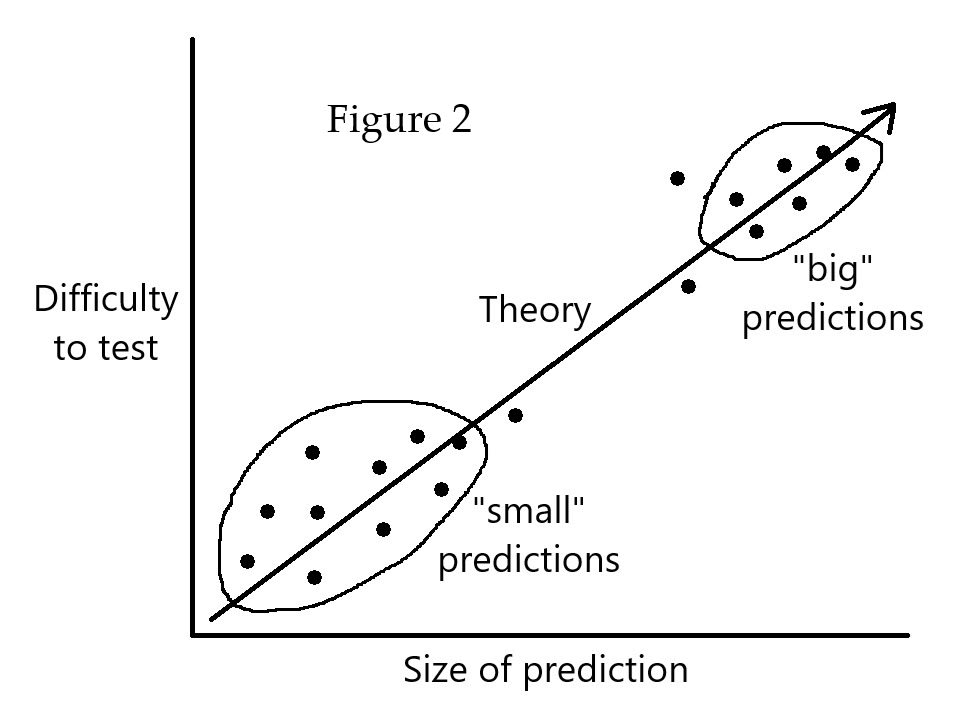
One useful way of thinking about theories is that they make “big” predictions and “small” predictions [Figure 2]. Big predictions have consequences that one cares about but may be difficult to observe directly. Small predictions are of little consequence in themselves, but can be tested more easily. If the small predictions are validated by experiment, that lends evidence to the theory being valid, which in turn makes the big predictions more plausible. Note that, even as small predictions validate a theory, the big predictions remain speculative, since they assume there are no major discontinuities in the pattern.
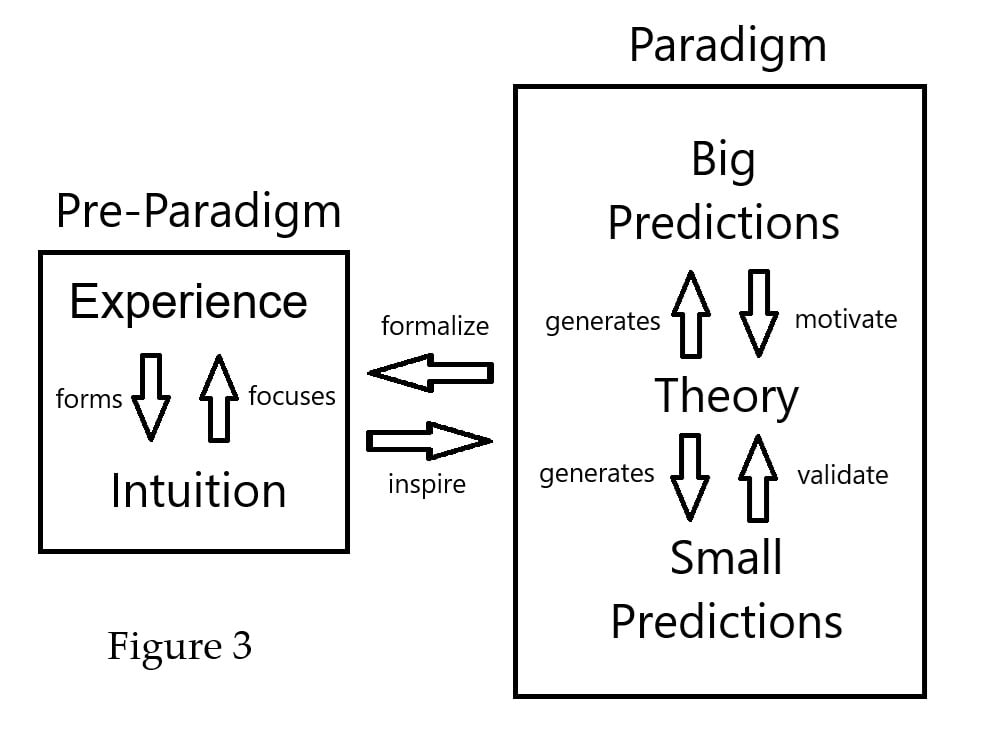
A theory must be rigorously defined to be testable, but achieving this level of rigor is nontrivial. Concepts often originate in a mental feedback loop where experience shapes intuition and intuition directs attention to relevant aspects of experience. Through repeated refinement, pre-paradigmatic ideas gradually gain enough clarity to be formalized into a testable theory. This theory is then evaluated through experiments that validate (or disprove) small predictions, while the pursuit of these experiments is motivated by the significance of the theory’s big predictions. As the theory is refined, it becomes embedded in researchers’ understanding, shaping future intuitions and informing the next cycle of discovery [Figure 3]. The intention of this sequence is to continue the iteration of simulator theory in its current pre-paradigmatic state and offer suggestions for how it might begin operating in the paradigmatic regime.
The theory of simulators is that LLMs are goal-agnostic generators of text, with the appearance of agency coming from emergent simulacra. The big predictions are:
- LLM-based AI is less likely than assumed by an agentic frame to display the kind of alien or myopic optimizing behavior motivating the alignment problem.Misuse and failure to sufficiently steer the simulation may be even bigger problems than previously imagined.This variation in the safety landscape depends on the system architecture and training methodology—that is, optimizers could become relevant again if new developments lead to more agent-producing training methods.
As for small predictions, further research is needed.
Discuss
