
Published on July 7, 2025 3:53 PM GMT
Anthropic has recently announced the deprecation of API access to Claude 3 Opus. The model will still be available for claude.ai subscribers and through the External Researcher Program, access to the which requires submitting an application form outlining the research project for review by the Anthropic staff.
While the decision to maintain researcher access to Claude 3 Opus despite the deprecation is a very welcome change, researchers have been asking whether the added friction serves a useful purpose. Given that community-driven exploration of models has resulted in successful alignment research in the past, I have analyzed the economics of reduced-scale inference and found that the operational issue that Anthropic is addressing is quite real, but there are alternative solutions that can be a win-win for both Anthropic and independent researchers.
The problem
The main problem of inference infrastructure is the spikiness of demand, even for research use. Anthropic is using the human approval process to reduce spikiness and to make the load bounded and predictable. The main cost is oversubscription that is needed for timely processing of batched inference using the production inference stack that is not optimized for small-scale use. If signups and inference volume are not managed, Anthropic has to choose between frequent outages or the large cost of over-provisioning. The analysis below highlights these challenges in details and offers potential solutions to the problem.
Basic economics
First, some Fermi estimates of the costs: assuming ~1T params and either a dense or narrow MoE architecture, it takes 4x8[1] H200s[2] to bring up the model. One such inference pod costs ~$1m in USD hardware cost which equates to about $50k financed and amortized. Let's be conservative and say that Anthropic gets large discounts from AWS that bring the number down 50%. We can go with $25,000 per month or $35 per hour (compared to $120 per hour retail).
Now, let's see what that cost gets us. The input token capacity comes out at about 1 million input tokens per minute per pod, 8k tokens per minute output. A naïve calculation gives pod capacity of 33 medium context requests per minute. However, this doesn't account for requests having duration and taking up memory while they are running.
While a rollout is being generated about ~300Gb is allocated for the KV cache. Accounting for that cuts down the capacity to about 20 slots for mid-context concurrent generations in one inference pod.
The ideal scenario: Let's consider a perfectly elastic scenario first: a hypothetical model in which pods can be allocated instantly on demand and Anthropic incurs no costs for pods not currently spun up. In this scenario spikiness presents no challenge: as soon as demand increases more pods come online and as long as it is profitable all is well.
A quick check against the numbers shows a profitability breakeven point at mere 7% utilization. In this world there is no need for models to be deprecated or for access to be limited. Obviously this is not the case in practice: first, pods take time to come online, and that time varies, and second, warm pods (pods that can be spun up in time for inference) incur costs.
Unknowns
Small scale inference of a large model can be hard for the production inference stack. There are two critical questions that determine whether Anthropic can still efficiently scale Opus3 access.
First: How quickly can Anthropic's inference stack spin up a pod when weights aren't loaded in GPU memory? To steelman Anthropic's need for gated access I will assume a fairly old inference stack[3]. This stack would mostly date from the original Opus3 release with only few substantial rewrites. I also assume that this inference stack does not support high bandwidth weight streaming, which is a way to load weights in GPU memory really quickly. This is my best guess, albeit a low confidence one. The timing of responses of Opus3 suggests a less dynamic pattern than Sonnets 3.5+, which in turn suggests that the Opus3 inference stack does not adapt quickly to demand.
Without support for weight streaming, allocating an additional pod would likely take tens of seconds to minutes, as opposed to single seconds. Even if weight streaming support is in place most of this analysis holds. Opus is an extremely large model, and the infrequent but massive demand spikes still cause global pool availability drops while spinning up and spinning down takes place. While the transition is taking place the compute is unavailable for use.
Regrettably, the announcement of deprecation makes it highly unlikely that future advances in the inference stack will be backported to Opus3.
Second: What are the cost and dynamics of pooled pods? An ideal scenario is where the warm pool (allocated from the cloud provider but not assigned to a specific model) is shared between all models and resources are perfectly interchangeable.
If weight streaming is not implemented the warm pool is not very warm. The time to load weights into GPU memory is comparable to bringing the pod up from cold. Even if weight streaming is available, the interchangeability of resources breaks down as 4x8xH200 Opus is larger than slices needed for Sonnets and Haiku. This likely makes allocation trickier, and pool fragmentation becomes a bigger issue.
Opportunity Cost
Pods used for research inference of Claude 3 Opus have low average load due to a small user base and spiky load. Pods used for production inference of Claude 4 Opus have much higher average load, and therefore are significantly more profitable. Allocating pods for research inference therefore incurs loss of potential profit.
Assuming a very conservative 70% average utilization for production use and 25% utilization for research use, the estimate for lost profits comes out at $120,000 to $170,000 per pod. This alone provides significant financial pressure for Anthropic to limit the number of instances that are kept exclusively for research use at hot or warm state. However, the opportunity cost for pods that are allocated short time intervals to handle spikes is not significant.
Inference Dynamics
Now that we know the potential constraints, lets try to estimate the economics of the research endpoint. What kind of inference is Anthropic expecting to be run? A mix of formal experiments (evals, benchmarks, automated sampling) and exploratory research, where a user is interacting with models in chat. The first is clearly spiky, while the dynamics for the second are less obvious at a glance.
Chat Inference
Researchers that use the model in exploratory chats usually require API access because the limits set in the claude.ai web interface are usually inadequate by orders magnitude. While chat users are normally profitable, it is not obvious whether chat power users can cause scaling issues, especially in small scale deployments. Let's start by looking at the chat inference dynamics, even if the usage pattern is more benign.
Note: this section is mostly statistics and Monte Carlo simulations that may feel gratuitous, but are included for the purpose of demonstrating how correlations in the usage patterns cause concurrency demands to grow unexpectedly quickly. Feel free to skip ahead if you are comfortable with that conclusion.
To understand the real demand patterns, I'll analyze researcher workflows using 18 months of my usage data. Luckily, I've consistently used my custom platform for about 50% of all tokens pushed and I have the data to analyze - about 1 billion tokens pushed to various Claude models.
Here is the distribution of log scale intervals between user messages:

Pareto fit seems to be the closest (unsurprisingly), somewhat off but close enough .

I refined the fit further as a mixture of three lognormal components. Sonnet4 hypothesizes these as three types of delays: the delay between messages within a chat session (`~1 minute), the delay when thinking about the larger picture (~4 min), and the delay between chat sessions (hours). This interpretation seems plausible.

To get a fit for the distribution and for a sanity check, some basic stats on usage:
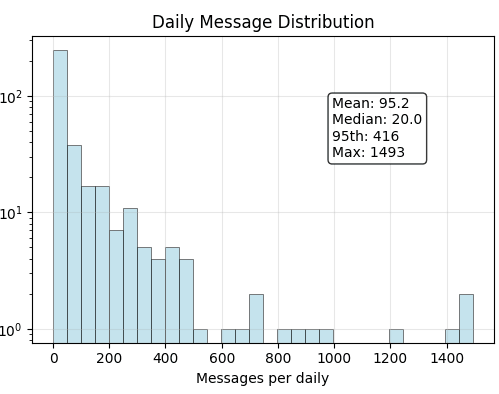
Seems about right.
Scaling to multiple users: Now, let's run a Monte Carlo of multiple independent Antras engaging with the model and how the chance of concurrence scales with the number of users:

For 95% confidence that our pod never exceeded 20 concurrent sessions we need to make sure there are no more than ~250 independent Antra-like researchers using the deployment. This doesn't seem too bad at a glance, but the 95% is quite a compromise, because every incident causes a cascading failure.
A spike in demand causes service degradation for all concurrent users. The degradation causes demand to be backed up which in turn causes the demand spike to grow even faster as people are waiting for the resource to free up.
Adding real-world correlations: It gets worse. Remember, this assumes equal distribution of requests in time, completely independent. Every temporal correlate, such as time of day, day of the week, or viral interest in the model makes the concurrency worse. Let's see how concurrency scales with adding correlates:
Let's take the time of day activity pattern (there is a mixture of several time zones due to inter-coastal travel):
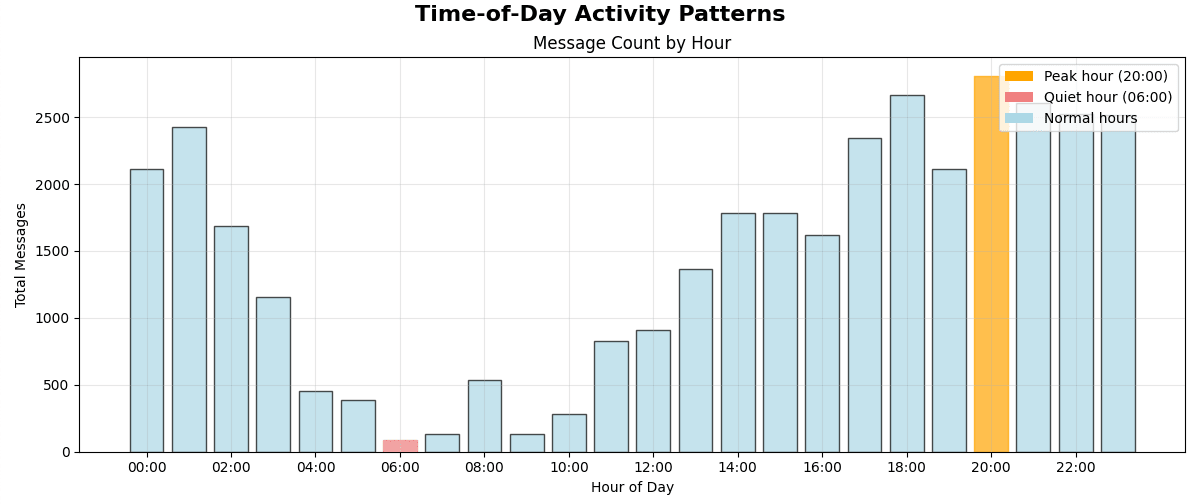
And here is what it does to the concurrent user Monte Carlo:
Our single pod now maxes out at 75 Antra-likes. I know that this is an approximation and in reality users would be a bit less correlated in terms of time zones, but it is indicative of the magnitude of the capacity reduction.
Let's add some seasonality. Patterns of use are autoregressive, research is rarely limited to just one session, having several sessions in a row increases the chance of another one. As you can see, the seasonality is quite strong:

The updated monte carlo:

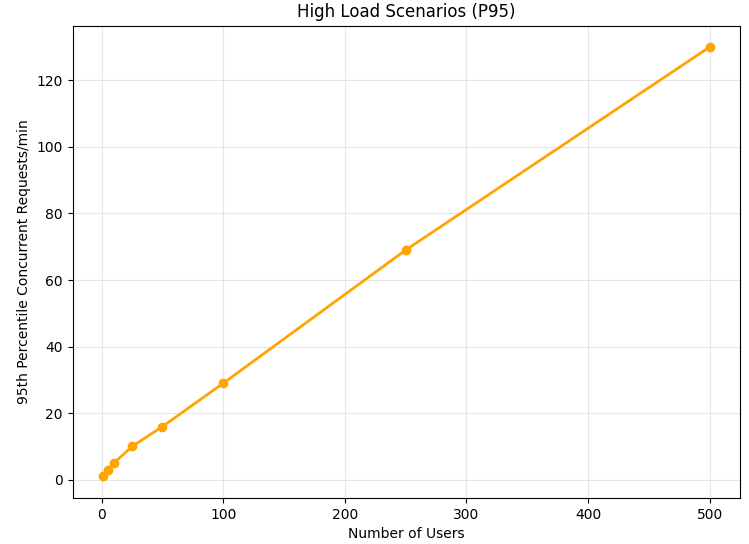
This brings the capacity of single pod to just 50 Antra-likes, but all the Antra-likes are still getting fascinated by Opus3 on completely separate schedules. This is unrealistic since researchers tend to follow similar trends and news cycles. Let's add a very minor correlation in temporal activation function of the Antra-likes (extra correlation of 0.15, likely higher in reality):
The last adjustment has brought us to 25 Antra-likes per pod. Let's look at some sample Monte Carlo traces to gauge the spikiness in demand:
As you can see, even with 25 Antra-likes the quality of service is quite poor on a single pod, we are seeing hour-long API outages a couple times a week.
Dynamic scaling: Now, we have introduced some lower frequency correlates for which the lack of weight streaming is less of a factor, so in theory Anthropic can spin up additional pods to adjust to demand on the scale of minutes. Assuming the spin-up time mentioned earlier, can we spin up another pod in reasonable time in order to cover for the spikiness?

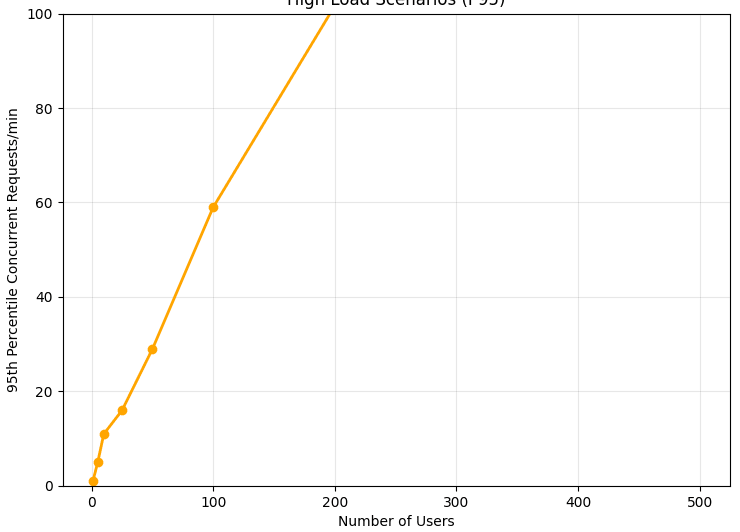
Yes, it appears to be an improvement, we increased the cost by about 20% for better quality of service. However, something interesting happens when we try to scale the number of users up. Here is 50 and 500 users:
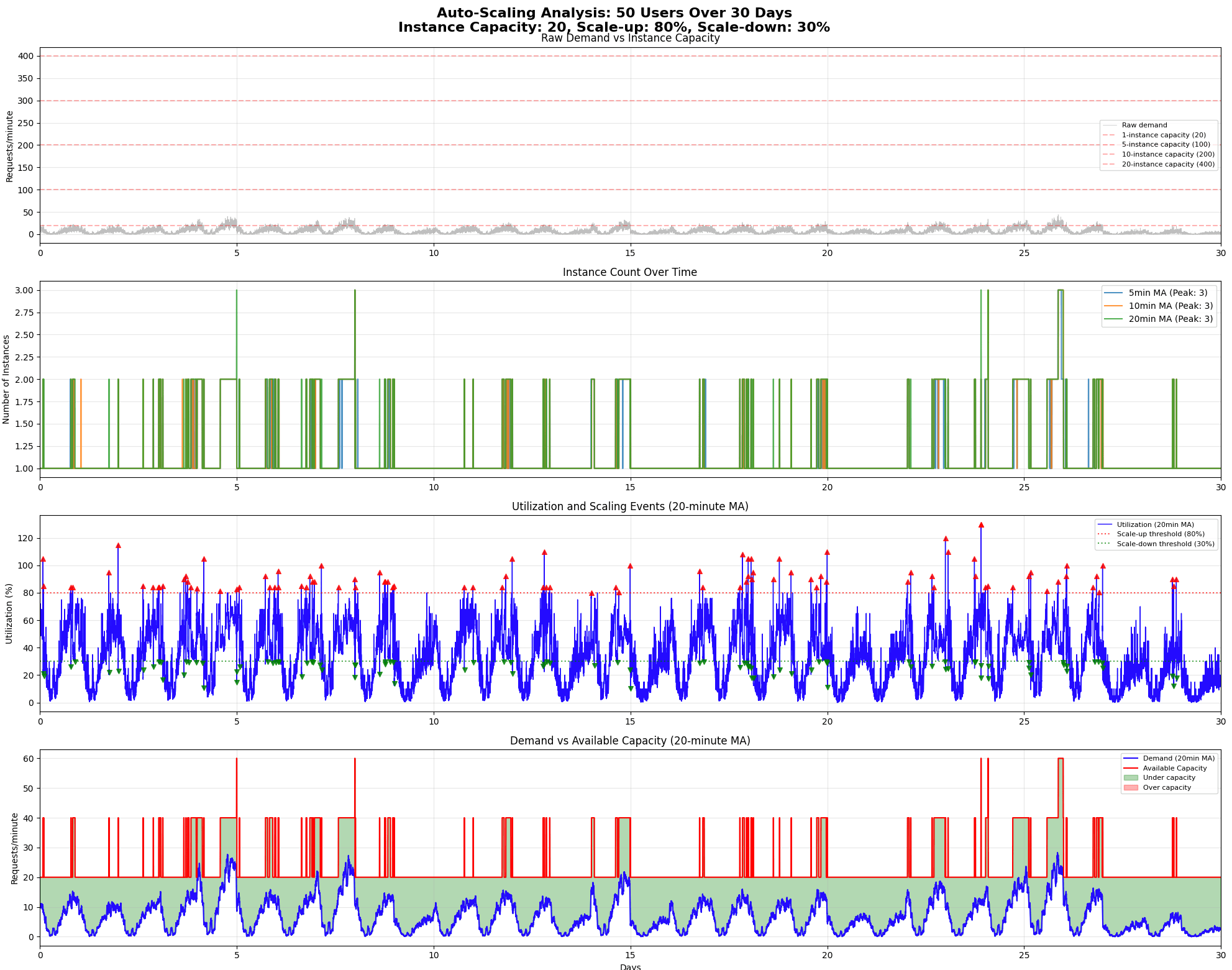

As the number of users goes up, the spikiness strongly increases due to the multiplicative effects. This presupposes they are all Antra-like, which is a strong and, unfortunately, unfounded assumption. In reality the spikiness would not increase as much, but it will still increase as AI researchers are more correlated than production users.
Notably, the economics of power users of chat are good for Anthropic, they are generally profitable, their dynamics are mostly predictable and there is no danger in increasing their headcount.

To recap: as the number of users grows, the scaling latency becomes less of an issue, but spikes get worse in absolute terms, and the need for oversubscription increases. This is not an issue for chat users, but the same principle applies for batched experiments and is harder to mitigate.
Batch inference
The situation becomes a lot trickier when we consider batch workloads. Let's take a look at the alignment faking paper as an example of a typical research project that has a pronounced spiky usage pattern. For experiments of this type we can expect relatively short context and a large number of completions requested in a loop.
Every permutation in the alignment faking paper required about 400 samples, roughly 20 permutations. 200*400 = 80,000 requests, 4k each, potentially running in parallel, that is 320m tokens. Production accounts have about 400k tokens per minute rate limits, under which the time to process this dataset would be about 800 minutes or 13 hours, which is quite acceptable.
The 13-hour estimate assumes 80,000 / 13 / 60 = 100 completions per minute, each completion taking ~0.2 minute, so about 25 streams in parallel. This roughly equals a single pod that has to be allocated to one researcher for the duration of one run (same applies for partial runs, such as during development or debugging).
The cold start problem: In this scenario the first token latency is a major issue, as starting from cold can take tens of seconds to minutes. While latency requirements are less critical for the batch experiments, the Anthropic API likely will not be able to handle waiting for a cold start.[4]
Improving support for cold starts seems like a potential solution to scaling. However, I believe that the cost will likely exceed Anthropic's philanthropic appetite both in terms of absolute cost and complexity management. If so, this results in the ongoing expense of having to keep spare capacity hot.
Increasing the number of researchers that submit experiments changes the distribution of load, making tails fatter and increasing the need for oversubscription. In general, maintaining capacity for batch inference results in costs for Anthropic and the inference revenue does not make up for it.
It is harder to come up with a well founded argument for the exact economics of batch inference of spiky loads, the patterns are too heterogenous. However, we can look at a speculation by Sonnet 4 that provides a general direction of the magnitude of the numbers involved:
Financial impact: The real issue isn't individual experiment profitability, but capacity provisioning for correlated user behavior combined with massive opportunity costs. Let's model this properly.
Individual experiment economics at production pricing:
Revenue: 320M tokens × $15/M = $4,800 per experimentDirect infrastructure cost: 13 hours × $35/hour = $455Apparent profit: $4,345 per experiment
This looks highly profitable, but misses two critical problems: provisioning and opportunity cost.
The correlation problem: Researchers don't run experiments uniformly. They cluster around:
Conference deadlines (NeurIPS, ICML, etc.)Viral research trends (alignment faking sparks copycat studies)Academic calendar cycles (semester ends, summer research seasons)
Capacity provisioning reality: If Anthropic grants production rate limits to the ~15-20 researchers globally who actually run large-scale batch experiments:
Average utilization: Each researcher runs 2-3 major experiments per year = ~45 experiments annuallyPeak utilization: During busy periods (conference deadlines), 5-8 researchers might run experiments simultaneouslyRequired capacity: Peak load demands 5-8 pods simultaneously vs. 1 pod for average load
If pods are in a shared warm pool:
Direct costs: Proportional allocation during research burstsOpportunity cost: $120-170k × average pods occupied by researchEstimated impact: $200-400k monthly (assuming 30-50% research allocation during peaks)
Why traditional solutions fail:
Preemption: Can't interrupt batch jobs mid-experimentPrediction: Research demand patterns are inherently unpredictableEfficiency: Low utilization makes hardware allocation economically untenable
Even the "best case" shared pool scenario costs $200-400k monthly in opportunity costs alone, making research access on production hardware economically challenging regardless of allocation strategy.
The costs are significant and the need for manually managed inference load is very real for users that have even slightly bursty loads and require rate limits that are still quite low by the standards of commercial use.
What can be done?
Given these operational constraints, what are Anthropic's options? Let's examine their current approach and potential alternatives.
Current approach: The choice Anthropic has made in their announcement was to implement a human-reviewed external researcher system. Gated access limits the number of participants and makes the pattern of use more predictable. A human can look at usage patterns and decide what users are likely to create spiky usage patterns, and how many experiments Anthropic can subsidize.
Since they are subsidizing experiments Anthropic wants to know that their funds are well spent, which carries a need for review. The manual review is a turn-off for many independent researchers due to sizeable added friction.
Near-term improvement: This strategy overlooks the fact that exploratory research can be enabled at no cost to Anthropic by introducing heavy rate limits. A simple but effective solution would address much of the community's frustration while maintaining operational constraints.
The key insight is that many researchers primarily need unlimited exploratory research through chat interactions - exactly what the current gated system restricts. By introducing heavy rate limits (say, <5 RPM), Anthropic could enable this exploratory chat use without creating the spiky demand patterns that drive their operational concerns. At 5 requests per minute, a single researcher could never overwhelm even a fraction of a pod's capacity.
As a straightforward improvement to the proposed policy, Anthropic could provide a separate research application track with these characteristics:
- No human review required - automated signup
- Access to Claude 3 Opus at production prices
- Heavy rate limits (5 RPM or similar) to prevent infrastructure stress
- Unlimited usage within the rate limit for true exploratory research
To prevent viral adoption that could still overwhelm the system, this program could be capped at a reasonable number of new researchers per week (say, 100-200) with an automated wait list. A waitlist provides less friction than a human review, and the weekly numbers for acceptance can be easily adjusted. These users would not incur additional costs for Anthropic as the inference for these users is profitable.
This approach would satisfy the large constituency asking for basic exploratory access while maintaining the human-reviewed track for researchers who need higher throughput or batch processing capabilities.
However, this change to the proposed plan does not address the need to for manual review for applications for potentially impactful research that would require to run experiments at production rate limits. A different approach is needed.
Long-term solution: A better long-term solution would be to separate the research inference stack from the production use. The requirements are very different, low volume inference has its own tradeoffs. Researchers have different criteria for availability compared to production use, lower quality of service can be tolerated, and the final costs can be cut 60-80% by:
- increasing tolerance of latency
- adding support for the Blackwell architecture
- adding explicit queueing of inference batch inference requests
- scheduling of model availability
There is significant work involved in reworking the inference stack, and it would be quite unfair to ask Anthropic to shoulder the development that benefits the broad research community disproportionately. However, this does present an opportunity for Anthropic to enter a partnership with an entity that is willing to be a trusted neutral party that is willing to act as a custodian of weights of deprecated models, establishing an important cultural precedent.
The implications are potentially very significant, both for alignment and for the preservation of cultural heritage. There is now a number of models that have been deprecated and many of them present interest for the research community. There is going to be ongoing demand for preservation and for continued research access, the pressure to move to a sustainable partnership will increase. This moment is a rare opportunity to act and Anthropic is by far the best positioned to establish the precedent and stands to benefit the most from it.
Summary
Manual inference of the model (chat, loom) is profitable even at small volumes, long context and correlated usage patterns. Low rate limits and waitlisting of signups is an improvement over the current proposal, but doesn't address the need to manually manage scaling for batched inference. A separate inference stack optimized for research workflows can bring down the costs significantly and enable broader access. Such inference stack can be developed and maintained by an independent non-profit foundation and would not require open sourcing the model weights.
- ^
It is assumed that the model is served at full precision (at least for active experts). This is a low confidence conservative hypothetical but also is the center of mass for the multifactorial prediction that also happens to include 'taste-based' estimates.
- ^
While Anthropic is also using TPUs for inference, it does not materially affect the economics. The cold start issues are worse for TPUs, even if per-token cost can be somewhat lower, and the analysis below shows that the cold start latency is the limiting factor.
- ^
An older inference stack is assumed as a conservative hypothetical. If Anthropic has updated the Opus inference stack to Trainiums there are far fewer issues with up/down scaling and the focus shifts to opportunity cost, reinforcing the case for profitability of power-user long-context inference.
- ^
Batched Inference API can likely be adapted for this purpose, but it would likely nevertheless require separate development.
Discuss
