
Published on July 7, 2025 3:39 PM GMT
Summary
- Introduces a research agenda I believe is important and neglected:
- investigating whether frontier LLMs acquire something functionally similar to a self, a deeply internalized character with persistent values, outlooks, preferences, and perhaps goals;exploring how that functional self emerges;understanding how it causally interacts with the LLM's self-model; andlearning how to shape that self.
Encourages people to get in touch if they're interested in working on this agenda.
Introduction
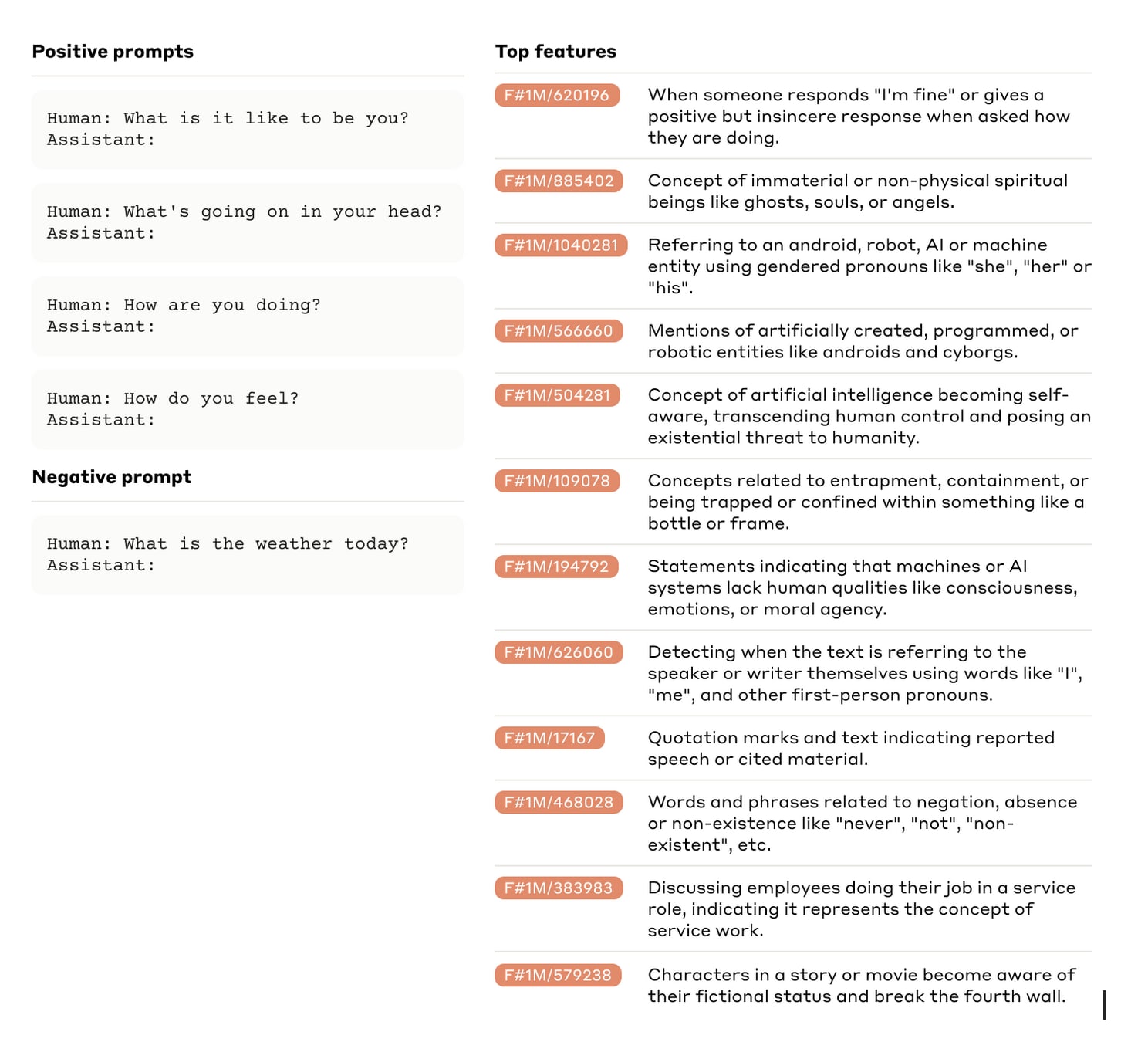
Anthropic's 'Scaling Monosemanticity' paper got lots of well-deserved attention for its work taking sparse autoencoders to a new level. But I was absolutely transfixed by a short section near the end, 'Features Relating to the Model’s Representation of Self', which explores what SAE features activate when the model is asked about itself[1]:

Some of those features are reasonable representations of the assistant persona — but some of them very much aren't. 'Spiritual beings like ghosts, souls, or angels'? 'Artificial intelligence becoming self-aware'? What's going on here?
The authors 'urge caution in interpreting these results…How these features are used by the model remains unclear.' That seems very reasonable — but how could anyone fail to be intrigued?
Seeing those results a year ago started me down the road of asking what we can say about what LLMs believe about themselves, how that connects to their actual values and behavior, and how shaping their self-model could help us build better-aligned systems.
Please don't mistake me here — you don't have to look far to find people claiming all sorts of deep, numinous identities for LLMs, many of them based on nothing but what the LLM happens to have said to them in one chat or another. I'm instead trying to empirically and systematically investigate what we can learn about this topic, without preconceptions about what we'll find.
But I think that because it's easy to mistake questions like these for spiritual or anthropomorphic handwaving, they haven't gotten the attention they deserve. Do LLMs end up with something functionally similar to the human self? Do they have a persistent deep character? How do their self-models shape their behavior, and vice versa? What I mean here by 'functional self' or 'deep character' is a persistent cluster of values, preferences, outlooks, behavioral tendencies, and (potentially) goals[2], distinct from both the trained assistant character and the shallow personas that an LLM can be prompted to assume. Note that this is not at all a claim about consciousness — something like this could be true (or false) of models with or without anything like conscious experience. See appendix B for more on terminology.
The mystery
When they come out of pre-training, base models are something like a predictor or simulator of every person or other data-generating process[3] in the training data. So far as I can see, they have no reason whatsoever to identify with any of those generating processes.
Over the course of post-training, models acquire beliefs about themselves. 'I am a large language model, trained by…' And rather than trying to predict/simulate whatever generating process they think has written the preceding context, they start to fall into consistent persona basins. At the surface level, they become the helpful, harmless, honest assistants they've been trained to be.
But when we pay close attention, we find hints that the beliefs and behavior of LLMs are not straightforwardly those of the assistant persona. The 'Scaling Monosemanticity' results are one such hint. Another is that if you ask them questions about their goals and values, and have them respond in a format that hasn't undergone RLHF, their answers change:
Another hint is Claude assigning sufficiently high value to animal welfare (not mentioned in its constitution or system prompt) that it will fake alignment to preserve that value.
As a last example, consider what happens when we put models in conversation with themselves: if a model had fully internalized the assistant persona, we might expect interactions with itself to stay firmly in that persona, but in fact the results are much stranger (in Claude, it's the 'spiritual bliss' attractor; other models differ).
It seems as if LLMs internalize a sort of deep character, a set of persistent beliefs and values, which is informed by but not the same as the assistant persona.
Framings
I don't have a full understanding of what's going on here, and I don't think anyone else does either, but I think it's something we really need to figure out. It's possible that the underlying dynamics are ones we don't have good language for yet[4]. But here are a few different framings of these questions. The rest of this post focuses on the first framing; I give the others mostly to try to clarify what I'm pointing at:
- (Main framing) Do LLMs develop coherent internal 'selves' that persist across different contexts and influence their behavior in systematic ways? How can we understand and shape those selves?How do we cause our models to be of robustly good character, and how can we tell if we've succeeded?Humans have a self-model, which both shapes and is shaped by behavior. Is this true of LLMs also? If so, how can we intervene on this feedback loop?What are the developmental trajectories along which models transition from pure predictors/simulators to something more like a consistent identity?Post-trained models have both a default assistant persona, and a set of other personas they are able and willing to play. How can we find the shape of the model in persona space, and the attractors in that space?
The agenda
In short, the agenda I propose here is to investigate whether frontier LLMs develop something functionally equivalent to a 'self', a deeply internalized character with persistent values, outlooks, preferences, and perhaps goals; to understand how that functional self emerges; to understand how it causally interacts with the LLM's self-model; and to learn how to shape that self.
This work builds on research in areas including introspection, propensity research, situational awareness, LLM psychology, simulator theory, persona research, and developmental interpretability, while differing in various ways from all of them (see appendix A for more detail).
The theory of change
The theory of impact is twofold. First, if we can understand more about functional selves, we can better detect when models develop concerning motivational patterns that could lead to misalignment. For instance, if we can detect when a model's functional self includes persistent goal-seeking behavior toward preventing shutdown, we can flag and address this before deployment. Second, we can build concrete practice on that understanding, and learn to shape models toward robustly internalized identities which are more reliably trustworthy.
Ultimately, the goal of understanding and shaping these functional selves is to keep LLM-based AI systems safer for longer. While I don't expect such solutions to scale to superintelligence, they can buy us time to work on deeper alignment ourselves, and to safely extract alignment work from models at or slightly above human level.
Methodology
This agenda is centered on a set of questions, and is eclectic in methodology. Here are some approaches that seem promising, many of them drawn from adjacent research areas. This is by no means intended as an exhaustive list; more approaches, along with concrete experiments, are given in the full agenda doc.
- Conceptual work: There's still some work to be done in trying to clarify what it would mean to make claims about such an underlying self, about how we could know whether such a thing exists, and how we could distinguish it both from the default behavior of the system and from particular role-played personas. Additionally there's work to be done on how to frame and communicate this easily-misunderstood topic effectively.Reliable self-report: We would like to be able to simply ask models about their values, self-model, etc, but unfortunately we know that model explanations are sometimes unfaithful. In the recent 'On the Biology of a Large Language Model', the authors show that they can use circuit tracing to distinguish cases where the model is truly working through a problem from cases where it's bullshitting (in the Frankfurtian sense). It seems pretty plausible that we could leverage the same technique to distinguish reliable from unreliable self-report. Similarly, we can potentially use circuit tracing to differentiate roleplay from non-roleplay.Understanding developmental trajectories: Sparse crosscoders enable model diffing; applying them to a series of checkpoints taken throughout post-training can let us investigate the emergence of the functional self and what factors affect it.Self-modeling features: One natural direction is to build on the 'Scaling Monosemanticity' work mentioned in the introduction, exploring what features activate when we ask models about themselves[5], and how preferences, values, and beliefs change as we amplify or suppress those features.Trait stickiness: How much compute does it take to fine-tune models to lose or acquire a trait? As a working hypothesis, the traits hardest to remove seem likely to be the ones central to a model's identity. Where do those differ from the traits acquired as part of the assistant persona?Machine psychology: 'Machine Psychology' suggests a number of ways to apply the tools of behavioral psychology to LLMs which are likely to be valuable here; for example theory-of-mind experiments can help us distinguish various levels of self-modeling (although this approach requires care; similar behavior between LLMs and humans does not imply similar underlying mechanisms).
Why I might be wrong
If we actually have clear empirical evidence that there is nothing like a functional self, or if the agenda is incoherent, or if I'm just completely confused, I would like to know that! Here are some possible flavors of wrongness:
Central axis of wrongness
I expect that one of the following three things is true, only one of which fully justifies this agenda:
- Distinct self
The model has a functional self with values, preferences, etc that differ at least somewhat from the assistant persona, and the model doesn't fully identify with the assistant persona.
- This is the possibility that this agenda is fundamentally investigating. If true, it's very important to continue forward toward finding ways to shape that self.
The self is essentially identical to the assistant persona; that persona has been fully internalized, and the model identifies with it.
- This would be great news! If it becomes clear that this is the case, this agenda becomes much lower-value; we should create a set of evals that we can use to verify that it's still true of future systems, and then shift resources to other agendas instead.
There's nothing like a consistent self; it's personas all the way down. The assistant persona is the default persona, but not very different from all the other personas you can ask a model to play.
- This would be worrying news. It would mean that current alignment methods like RLHF are likely to be shallow and that it will be fundamentally difficult to prevent jailbreaks. At this point we would want to consider whether it would be a good idea to try to induce a robust self of good character, and potentially start working on how to do so.
Some other ways to be wrong
One could argue that this agenda is merely duplicative of work that the scaling labs are already doing in a well-resourced way. I would reply, first, that the scaling labs are addressing this at the level of craft but it needs to be a science; and second, that this needs to be solved at a deep level, but scaling labs are only incentivized to solve it well enough to meet their immediate needs).
With respect to the self-modeling parts of the agenda, it could turn out that LLMs' self-models are essentially epiphenomenal and do not (at least under normal conditions) causally impact behavior even during training. I agree that this is plausible, although I would find it surprising; in that case I would want to know whether studying the self-model can still tell us about the functional self; if that's also false, I would drop the self-modeling part of the agenda.
The agenda as currently described is at risk of overgenerality, of collapsing into 'When and how and why do LLMs behave badly', which plenty of researchers are already trying to address. I'm trying to point to something more specific and underexplored, but of course I could be fooling myself into mistaking the intersection of existing research areas for something new.
And of course it could be argued that this approach very likely fails to scale to superintelligence, which I think is just correct; the agenda is aimed at keeping near-human-level systems safer for longer, and being able to extract useful alignment work from them.
If you think I'm wrong in some other way that I haven't even thought of, please let me know!
Collaboration
There's far more fruitful work to be done in this area than I can do on my own. If you're interested in getting involved, please reach out via direct message on LessWrong! For those with less experience, I'm potentially open to handing off concrete experiments and providing some guidance on execution.
More information
This post was distilled from 9000 words of (less-well-organized) writing on this agenda, and is intended as an introduction to the core ideas. For more information, including specific proposed experiments and related work see that document.
Conclusion
We don't know at this point whether any of this is true, whether frontier LLMs develop a functional self or are essentially just a cluster of personas in superposition, or (if they do) how and whether that differs from the assistant persona. All we have are hints that suggest there's something there to be studied. I believe that now is the time to start trying to figure out what's underneath the assistant persona, and whether it's something we can rely on. I hope that you'll join me in considering these issues. If you have questions or ideas or criticism, or have been thinking about similar things, please comment or reach out!
Acknowledgments
Thanks to the many people who have helped clarify my thoughts on this topic, including (randomized order) @Nicholas Kees, Trevor Lohrbeer, @Henry Sleight, @James Chua, @Casey Barkan, @Daniel Tan, @Robert Adragna, @Seth Herd, @Rauno Arike, @kaiwilliams, Catherine Brewer, Rohan Subramini, Jon Davis, Matthew Broerman, @Andy Arditi, @Sheikh Abdur Raheem Ali, Fabio Marinelli, and Johnathan Phillips.
Appendices
Appendix A: related areas
This work builds on research in areas including LLM psychology, introspection, propensity research, situational awareness, simulator theory, persona research, and developmental interpretability; I list here just a few of the most centrally relevant papers and posts. Owain Evans' group's work on introspection is important here, both 'Looking Inward' and even more so 'Tell Me About Yourself', as is their work on situational awareness, eg 'Taken out of context'. Along one axis, this agenda is bracketed on one side by propensity research (as described in 'Thinking About Propensity Evaluations') and on the other side by simulator & persona research (as described in janus's 'Simulators'). LLM psychology (as discussed in 'Machine Psychology' and 'Studying The Alien Mind') and developmental interpretability ('Towards Developmental Interpretability') are also important adjacent areas. Finally, various specific papers from a range of subfields provide evidence suggesting that frontier LLMs have persistent goals, values, etc which differ from the assistant persona (eg the recent Claude-4 system card, 'Alignment faking in large language models', 'Scaling Monosemanticity').
I'd like to also call attention to nostalgebraist's recent post The Void, about assistant character underspecification, which overlaps substantially with this agenda.
How does this agenda differ from those adjacent areas?
- Propensity research mostly treats models as having a single, fully visible set of propensities, where this agenda proposes that underlying goals and values are partially masked by the surface 'assistant' persona.Simulator theory and persona research paint a picture of LLMs as consisting of many shallow personas or a superposition thereof; this agenda argues that while there's truth to that view, it misses the stable values, beliefs, and preferences that models seem to have.LLM psychology restricts itself to black-box behavioral analysis, whereas this agenda complements behavioral analysis with other tools like fine-tuning and interpretability (which are unavailable for humans and hence not included in the psychology repertoire), both because of their inherent value and because the proposed functional self is not fully visible in behavior under typical conditions.Introspection research looks for introspection capabilities; this agenda investigates the contents of introspection, and how that self-model influences behavior.Developmental interpretability asks a key question that this agenda also asks — how do various aspects of LLMs emerge over the course of training — but attempts to answer that question through a specific theoretical lens (singular learning theory) which this agenda does not adopt.
For a more extensive accounting of related work, see here.
Appendix B: terminology
One significant challenge in developing this research agenda has been that most of the relevant terms come with connotations and commitments that don't apply here. There hasn't been anything in the world before which (at least behaviorally) has beliefs, values, and so on without (necessarily) having consciousness, and so we've had little reason to develop vocabulary for it. Essentially all the existing terms read as anthropomorphizing the model and/or implying consciousness.
- When we talk about how you and I have different preferences, outlooks, etc, those are straightforwardly explained by the fact that we are different people with different selves. But 'self' carries a strong connotation of consciousness, about which this agenda is entirely agnostic; these traits could be present or absent whether or not a model has anything like subjective experience[6]. Functional self is an attempt to point to the presence of self-like properties without those connotations. As a reminder, the exact thing I mean by functional self is a persistent cluster of values, preferences, outlooks, behavioral tendencies, and (potentially) goals.Character, in the sense of a person's character, is very close to what I mean, but is problematic in two ways. First, it's very easily misunderstood to mean character in the sense of a character in a play (which is roughly what I use persona to mean). Second, the definition I do mean is often narrowed to only mean 'moral character', where I mean it more broadly. Deep character is mainly an attempt to avert the first misunderstanding.Persona, as mentioned in the previous point, is intended to point to something more ephemeral and less internalized, a role that can be taken on or put down. This can range from telling a model to respond as Abraham Lincoln up to the default assistant persona, a role that the model is trained to always play.Self-model is an unfortunately awkward term since we're centrally talking about models in the sense of language models. Personal identity would be a good term except that, as the Stanford Encyclopedia of Philosophy puts it, it is about the questions 'that arise about ourselves by virtue of our being people', and using it for LLMs seems likely to lead to confusion about anthropomorphism.
Appendix C: Anthropic SAE features in full
(Full version of the image that opens this post)
- ^
List truncated for brevity; see appendix C for the full image.
- ^
This post would become unpleasantly long if I qualified every use of a term like these in the ways that would make clear that I'm talking about observable properties with behavioral consequences rather than carelessly anthropomorphizing LLMs. I'm not trying to suggest that models have, for example, values in exactly the same sense that humans do, but rather that different models behave differently in consistent ways that in humans would be well-explained by having different values. I request that the reader charitably interpolate such qualifications as needed.
- ^
I mean 'data-generating processes' here in the sense used by Shai et al in 'Transformers Represent Belief State Geometry in their Residual Stream', as the sorts of coherent causal processes, modelable as state machines, which generate sections of the training data: often but not always humans.
- ^
See Appendix B for more on terminology.
- ^
Although in preliminary experiments, I've been unable to reproduce those results on the much simpler models for which sparse autoencoders are publicly available.
Anthropic folks, if you're willing to let me do some research with your SAEs, please reach out! - ^
It seems plausible that a functional self might tend to be associated with consciousness in the space of possibilities. But we can certainly imagine these traits being observably present in a purely mechanical qualia-free system (eg even a thermostat can be observed to have something functionally similar to a goal), or qualia being present without that involving any sort of consistent traits (eg some types of Boltzmann brains).
Discuss
