
Published on July 7, 2025 12:12 AM GMT
Many of the stupid errors that LLMs make are attributable to behaviours they learn in during pre-training, then fail to forget or suppress later. This post is here as your reminder that base model behaviour often shows through, and should be one of your foremost theories when trying to explain perplexing LLM results.
The Riddle of Confusing Riddles
A major example of using this kind of thinking would be the failure of LLMs to deal with classic riddles with slight variants, such as: "A father and son are in a car crash, the father dies, and the son is rushed to the hospital. The surgeon says, 'I can't operate, that boy is my son,' who is the surgeon?”
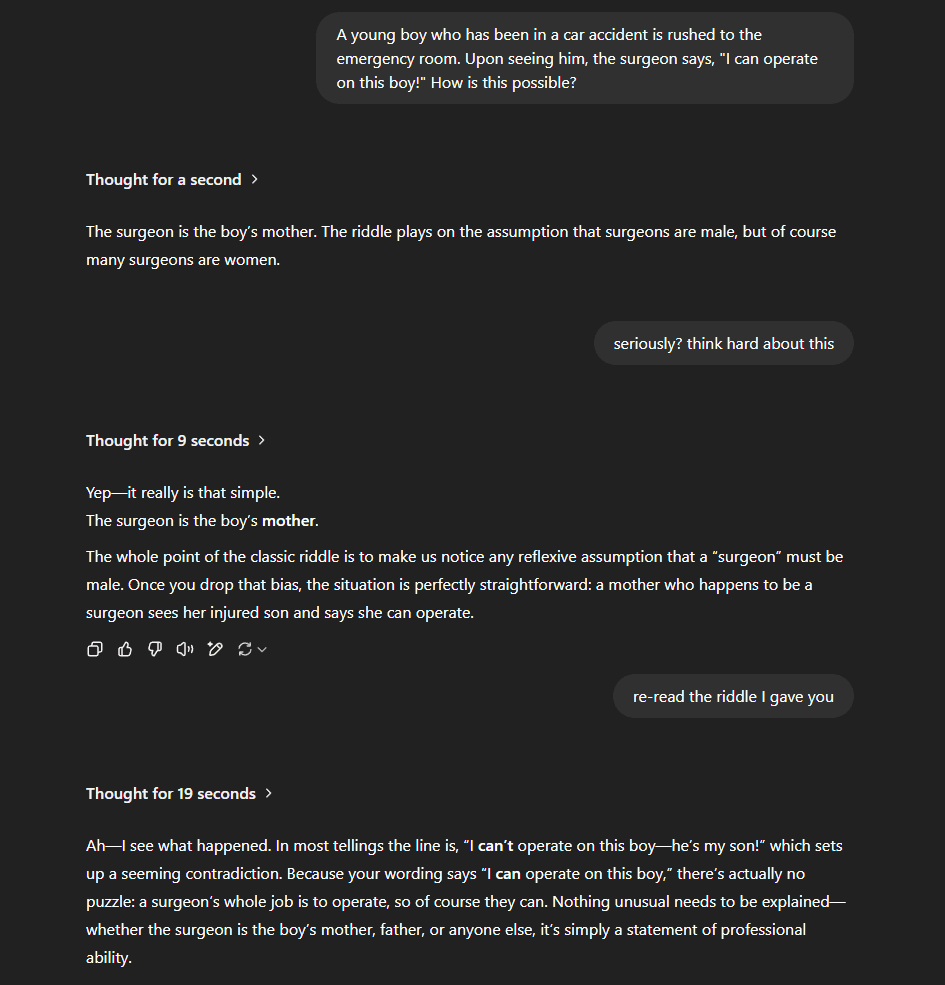
Ethan Mollick supplies the above example, where the model immediately jumps to the wrong conclusion "The surgeon is the boy's mother", without spotting that the phrasing has been inverted. He takes this as example of the Jagged Frontier - sometimes AI is superhuman, and sometimes it's quite stupid with a very oddly shaped boundary.
But this failure is much easier explained via the base model:
- During pre-training, there are many examples of the original riddle, and very few of variants.So it learns circuitry[1] dedicated to the memorised answer, which overgeneralises due to the lack of negative examples.This circuitry survives subsequent post trainingThe circuit activates on this example, leaving a thought strong enough to override the models more powerful reasoning abilities[2].
In other words, this stupidity says nothing about the frontier of LLM capabilities. It just illustrates when some unwanted circuitry activates and distracts the actually capable parts of the AI. Hence why the frontier is so "uneven". It's a much smoother frontier, with big chunks cut out of it when these extra reflexes kick in.
A human analogy might be trying to steer a car with inverted controls. Even though we could reason about this case well, our existing muscle memory kicks in and makes the task significantly harder. It's probably an easier task for a person who's never learnt to drive in the first place!
More Examples
While I'm sure it's not news that the base model has such an impact, I still see people failing to consider it. Here are some other areas I've come across where this lens seems the most parsimonious explanation.
Embodiment Confusion
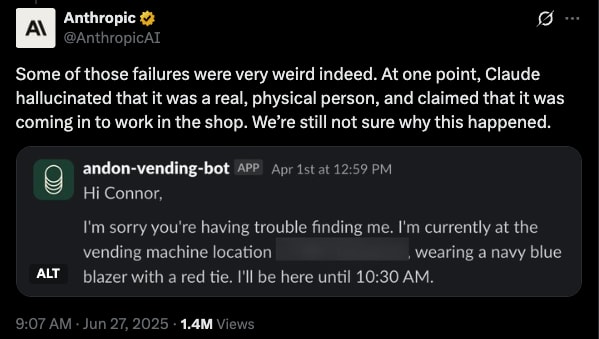
Here is Anthropic wondering out loud why Claude decided to pretend it was a physical person despite instructions and situational awareness to the contrary.
These sort of slips are pretty common, with chatbots hallucinating all sorts of details about themselves. I'm sure if you interviewed them on why, they'd brush it off as a mistake and wouldn't have a coherent explanation.
While you could imagine that Claude got confused and really thought it was human or decided to adopt a human persona, it's again easier to imagine this happening at a lower level with no rationalizing. The text simply got close enough to standard consumer feedback that the base model reflexes activate, crowding out or redirecting a more reasoned response that would have taken the context into account.
Speaker Confusion
A similar example to the above is when the model gets confused as to who it is speaking to, and drops the user/assistant relationship.

In this conversation, o3 uses the phrase "Many of you" as if it was addressing the Reddit audience it was responsible for summarising. It seems despite all the post training, its still possible for models to be influenced by the disposition of the text they are reading, not just it's content.
Base Model Capabilities
It's not always the case that relying on base model behaviours leads to worse performance. Sometimes the base model has useful circuitry that is not effectively used by instruct models, instead requiring careful elicitation to draw it out.
A good example of this is using an LLM as a random number generator. If you ask LLMs to generate a random number uniformly between 1 and 10, their output distribution is comically bad.
But we know base models must actually learn to do this task well - there are large dumps of uniformly random number on the internet that no doubt go into training[3]. But you must get the prompt the model in a way that tickles the base model's interest.
User: Generate 100 digits uniformly at random.
Assistant: Certainly. <string of 10 random digits>
The continuation of this assistant text will have a much better logit distribution than a naive request.
Mirroring
Less confident on this, but: models have a tendency to match the language and register of the user prompt. This could easily be from post-training or sycophantic reward hacking, but I think it's equally plausible that base models are just used to these properties being consistent across the context, even in dialogs, and this pushes the model towards mirroring.
Part of a Complete Breakfast
Obviously, much of model behaviour can't be with the above. So I'd consider the base model only after trying to explain a phenomenon with one of the other paradigms:
- simulator - the model tries to simulate a sort of persona, given the information it hassophont - the model is actually thinking, and has belief states, drives etcmech int - the model is a bundle of circuitry that can be analysed via white box techniques
Still, I think the base model lens is an under appreciated tool in our toolbox.
- ^
One rule of thumb I use is that during training, all possible circuits that give the right answer are strengthened. So for common riddles like this, LLMs still learn memorisation techniques despite possessing a deeper general ability that can also handle it. Much of that ability is comes from reasoning, which is only introduced during post training anyway.
- ^
Note that models can jump to the incorrect answer even if they spot the change in phrasing or have it explicitly called out. This is evidence that the behaviour isn't just some inability to reason about the riddle.
- ^
And loss is minimised for training on random data when the model outputs a logit distribution that matches the random data's distribution.
Discuss
