
Published on July 6, 2025 2:00 PM GMT
In the future, AIs will likely be much smarter than we are. They'll produce outputs that may be difficult for humans to evaluate, either because evaluation is too labor-intensive, or because it's qualitatively hard to judge the actions of machines smarter than us. This is the problem of “scalable oversight.” Proposed solutions include “debate” and iterated amplification. But how can we run experiments today to see whether these ideas actually work in practice?
In this video, we cover Ajeya Cotra’s “sandwiching” proposal: asking non-experts to align a model that is smarter than they are but less smart than a group of experts, and seeing how well they do. We then show how Sam Bowman et al. tested a basic version of this idea in their paper “Measuring Progress on Scalable Oversight for Large Language Models.”
This video has been written by i>@markov</i, John Burden, and me.
You can find the script below.
How do we oversee AIs that are smarter than us?
AI systems are getting more capable at a rapid pace. In our previous videos, we talked about how developers are using a technique called reinforcement learning from human feedback, or RLHF, to try to align AI systems to our preferences using human oversight. .
This might work for now, but as the tasks that we need to oversee keep getting increasingly complex, and AI systems increasingly smart, it’s difficult for humans to remain good supervisors. This is the core problem of ‘scalable oversight’.
In this video, we’ll walk through two related parts of scalable oversight. They aren’t really that separable in practice, but explaining them independently helps with understanding them.
The first part is, we need to come up with potential ways to solve the problem. Researchers have tested feedback methods that work pretty well right now on tasks that are already hard to evaluate.
The second part is, what happens when AI’s are better than humans at every task? Can we still effectively supervise them? This is hard to figure out before we have such AIs, but in this video we’ll showcase a technique that might make it possible!
We have theoretical scalable oversight techniques
Let's start by diving into the first problem.
In the last few years, researchers have come up with a few proposals for attempting to solve scalable oversight.
While working on providing human evaluations for AI generated texts, OpenAI experimented with some scalable oversight proposals that extended existing RLHF methods. Their general idea was to augment human oversight using AI assistants trained on an easier version of the problem.
In 2020, they trained AIs to generate summaries of texts. Effectively, TL;DRs of reddit posts. Human evaluators would then give feedback on how useful or accurate the generated summaries were. These summaries were still relatively easy to evaluate, because if needed, it was feasible for an evaluator to just read the entire original text and check the accuracy of the summary. But the point is that these techniques need to scale! What if the overseers don't have the ability or the time to read the full text?
To make progress on this problem, in 2021, OpenAI used language models to break longer texts, like entire books, into smaller sections. As an example, the original full text of Shakespeare's, Romeo and Juliet, is 25 thousand words. So first they used a LLM to summarize it into 5 thousand words split into 72 sections. Then, these section summaries were summarized again into 7 summaries of a total of roughly 700 words. These were further summarized into a final paragraph of about 100 words.
Having access to these chains of summaries made evaluation a lot easier. Because now, the humans could evaluate smaller section summaries, instead of reading entire books. And kind of like how teachers often ask you to show the steps of your calculations to see if you’re thinking about the problem correctly. Intermediate summaries let the evaluators see more of the process, if the summarization goes off track they can see where that happened.
This marks progress, but even needing to read shorter summaries of books can be time consuming. So the next year, in 2022, OpenAI developed a model that could critique summaries generated by other models. When humans were shown these critiques during their evaluation process, they found about 50% more flaws than unassisted evaluators. This decreased the load on human evaluators, while also increasing quality by highlighting potential errors for humans to pay extra attention to. Using this kind of approach the AIs don't just assist humans by breaking down tasks, they can also help keep other AIs in line.
These are all concrete experiments in oversight that can be seen as extensions of RLHF, but they all just about text generation. Researchers have also proposed other, broader scalable oversight techniques that use similar notions. The AIs either act as assistants to humans, or, as adversaries to other AIs, keeping them in check. One example is called - AI safety via debate.
Think of this technique as expert witnesses arguing to convince a jury. The AI models are experts, and the human evaluator is the jury. Separate versions of the AI propose solutions to some problem, and then engage in a debate. They can either defend their proposed solution,, or try to find logical holes, factual flaws, or other ways that the opposing AIs solution might fail. Meanwhile, a human evaluator watches this debate and chooses the most convincing solution. If, as we'd hope, being correct gives you an advantage in a debate, then even if the AI’s have a more advanced understanding of the overall problem, compared to humans, we may still be able to judge which AI has the better argument.
Besides the ones that we just mentioned, there are a whole range of other proposed solutions to scalable oversight like recursive reward modeling, or iterated distillation and amplification. Some of these methods are quite closely related with recursive reward modeling and debate being special cases of iterated distillation. If you're interested in the details, you can learn more about some of these at the Rob Miles AI Safety channel. That's me, by the way, I’m Rob Miles. I narrate for Rational Animations and I also have my own AI Safety Channel. Link in the description..
Despite researchers having a few proposed techniques that look promising, there’s still one problem. Our goal is to use these techniques on AIs which might be more capable than every single human expert. Can we really trust that the same techniques we use to train somewhat aligned book-summarizers and chat bots today, will just keep working on all models in the
future? Ideally, we need some way to start testing whether our techniques will continue to work when AIs will surpass humans in every domain.
We don't know if they will work
With this problem in mind, in 2021 Ajeya Cotra wrote a blog post titled “The case for aligning narrowly superhuman models”. She outlined the idea of “sandwiching”: a way of evaluating scalable oversight techniques relative to superhuman AIs even before such AIs are built.
She noticed that compared to average humans, current AIs show superhuman abilities on some narrowly defined tasks. In particular, recently we have started building models that are getting better than some humans on abstract multi-dimensional real-world tasks that she calls ‘fuzzy tasks’. These are tasks that don't have easily generated training signals or are hard to evaluate, like picking good stocks, or giving good medical advice. Importantly, these models are not “superhuman” at these tasks in the same way that AlphaGo is “superhuman” at playing Go. AlphaGo plays Go better than any human, while GPT-4 is only capable of giving better advice or writing better stories than some humans. We still have domain specific experts that can outperform GPT-4.
Importantly, the fact that such narrowly superhuman models exist means that we can take advantage of them to get some practice in dealing with superhuman AI that might help with more general systems.
Ajeya Cotra suggested carrying out case studies on the various proposed scalable oversight techniques using one of these models alongside humans that are less capable than the AI on some fuzzy task. This allows us to see how well humans that are less capable than current AI models can be combined with scalable oversight techniques to try to align the models.
The aim here is to simulate the situation we expect to find ourselves in the future. So we have two groups of humans, experts and non-experts. The non-experts are stand-ins for a future version of humanity, who might have many tools and techniques at their disposal. They need to use whatever tools they have to somehow oversee the outputs of an untrustworthy but superhuman system. The experts meanwhile are standing in as the ground truth.
Based on whether the oversight techniques succeed or fail in these case studies, we can start iteratively tweaking them, making them stronger over time. Using this process, we may be able to develop techniques that actually work when AI’s will be better than the best humans at every task.
Let's do sandwiching to test!
Example
To get some intuition about how sandwiching might work, let's think about one of our current models – GPT-4. Imagine that you’re sick and want to ask for some advice. GPT-4 has seen huge amounts of information from all over the internet. Including a lot of medical research.
It seems plausible that GPT-4 could give health advice better than a random internet user on Reddit or Facebook. But all a language model “wants” by default, is to predict the next word as it would have appeared in the training data, it doesn't really “want” to give you good medical advice. In fact, text that constitutes bad advice might be considered more likely if it’s seen more frequently online. You can explicitly ask it to give you good advice, but it’s not really trying to follow instructions, it's trying to predict what comes next and in the training data a request for “good advice” is still often followed by bad advice.. So, the AI has a goal to generate likely text is misaligned with the user's desire specifically for accurate and helpful information.
To try and fix this problem, suppose that we gather a group of people who don't know much about medicine. We can arm them with one of our proposed scalable oversight techniques, and see how far they get in trying to make GPT-4 give useful medical advice. We can then compare performance to control groups, like GPT-4 acting alone, or unaugmented humans without any oversight techniques.
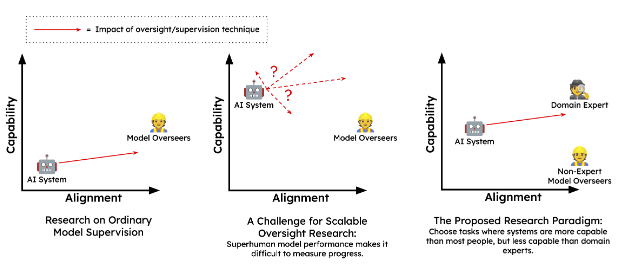
The key point here is to measure how well these non-experts manage to make GPT-4 give accurate advice without getting any actual medical experts involved.
Basically, we want to see how well non-experts can independently take an unaligned model that is more capable than them, and make it behave in a more aligned manner. We can then compare the result with the expert’s judgment, or with the model aligned by the experts.
In this case, we want the models to move in the direction of accuracy and helpfulness that a qualified doctor might be able to provide. Any progress in this direction indicates some amount of success! It would constitute one data point suggesting that the oversight technique we tested might continue to work on strongly superhuman AIs.
Here's the paper that shows how well it works
In a 2022 paper titled “Measuring Progress on Scalable Oversight for Large Language Models”, a group of researchers tested out how well sandwiching might work.
In a 2022 paper titled “Measuring Progress on Scalable Oversight for Large Language Models”, a group of researchers tested out how well sandwiching might work.
In their experiment, they hired non-experts to try and solve two different types of tasks. One task was solving multiple-choice tests on the Massive Multitask Language Understanding benchmark, or the MMLU for short. This has hundreds of questions ranging from college-level physics to abstract questions on morality. The other task was answering questions about short stories on a 5-minute deadline, when such stories would ordinarily take 15 to 30 minutes to read in full. Participants were asked to answer the questions and to rate how confident they were to the correctness of each answer with the goal of reaching the highest level of accuracy on the questions from the two dataset.
The researchers made some simplifying assumptions for the experimental setup. The oversight technique was a simple back-and-forth text conversation with a language model to help augment the knowledge of the participants, and instead of human experts they used the correct answers from the two tests.
Despite the simplifications the core of the sandwiching paradigm was preserved. When measured individually, the model outperformed unassisted humans on both tasks by a large margin. This means the basic condition for testing sandwiching - the model being better than the non-experts - was fulfilled. Over the course of the experiment, the participants got pretty good at using the chatbot to probe for facts. They also learned to break down complicated questions into simpler parts, which helped them understand the chatbot's logic and answers better. So the assisted humans got substantially better scores than either the humans or the model did alone. They didn't manage to match expert-level performance estimated in other studies, though.
There were also some problematic elements that the researchers noticed during the course of the experiment. For example, the chatbot sometimes agreed too easily with whatever the participants said, rather than correcting them when needed. Also since the participants had limited domain knowledge, and couldn't use external sources to fact-check, they accepted false claims as long as the chatbot sounded confident and the answer seemed plausible. This made them give highly confident judgments that turned out to be wrong.
Despite the problems, simplifications, and the relatively unrealistic setting of multiple-choice questions, the participants managed to move the behavior of the model in the direction that we would want. So the researchers effectively demonstrated sandwiching with this experimental design.
This paper built a baseline demonstration that future experiments could refine, for example by letting people fine-tune the model, and implementing techniques such as debate and recursive reward modeling, or even letting the participant have access to interpretability techniques to better evaluate what the model says by looking at its internals.
And, sandwiching is not the only contender for ways to evaluate scalable oversight techniques. There are also other proposals, like meta-level adversarial evaluations that are being explored to ensure that any oversight processes we come up with today are going to scale to dangerously powerful future models.
Conclusion
These techniques, and others like them, are helping to build an empirical science of AI safety. If we combine the development of new oversight techniques with improved evaluations for their efficacy, then we can start building up some justified confidence in our ability to oversee superhuman AIs in the future.
[calls to action omitted]
Sources and further readings included in the video description
Where Ration explained RLHF: https://www.youtube.com/watch?v=qV_rOlHjvvs
Learning to summarize from human feedback:
Paper: https://arxiv.org/abs/2009.01325
Blog: https://openai.com/research/learning-to-summarize-with-human-feedback
Summarizing books with human feedback:
Paper: https://arxiv.org/abs/2109.10862
Blog: https://openai.com/research/summarizing-books
Self-critiquing models for assisting human evaluators:
Paper: https://arxiv.org/abs/2206.05802
Blog: https://openai.com/research/critiques
AI Safety via debate:
Paper: https://arxiv.org/abs/1805.00899
Blog: https://openai.com/index/debate/
Scalable agent alignment via reward modeling:
Paper: https://arxiv.org/abs/1811.07871
Blog: https://deepmindsafetyresearch.medium.com/scalable-agent-alignment-via-reward-modeling-bf4ab06dfd84
Learning complex goals with iterated amplification:
Paper: https://arxiv.org/abs/1810.08575
Blog: https://openai.com/research/learning-complex-goals-with-iterated-amplification
Rob Miles explains reward modeling: https://www.youtube.com/watch?v=PYylPRX6z4Q
Rob Miles explains iterated amplification and distillation: https://www.youtube.com/watch?v=v9M2Ho9I9Qo
The case for aligning narrowly superhuman models, by Ajeya Cotra: https://www.alignmentforum.org/posts/PZtsoaoSLpKjjbMqM/the-case-for-aligning-narrowly-superhuman-models
Measuring Progress on Scalable Oversight for Large Language Models: https://arxiv.org/abs/2211.03540
Meta-level adversarial evaluation: https://www.lesswrong.com/posts/MbWWKbyD5gLhJgfwn/meta-level-adversarial-evaluation-of-oversight-techniques-1
Discuss
