
Published on July 6, 2025 11:48 AM GMT
New paper: Answer Matching Outperforms Multiple Choice for Language Model Evaluations.
TLDR: Using MCQs for AI benchmarking is problematic--you can guess the answer without even looking at the question (in multimodal MCQ datasets, without the image!). We knew this, but there didn't seem any alternative. We show now that language models are good enough, using small open-source ones to match generative responses to a ground-truth reference answer works much better, and turns out to be cheaper than MCQ evals!
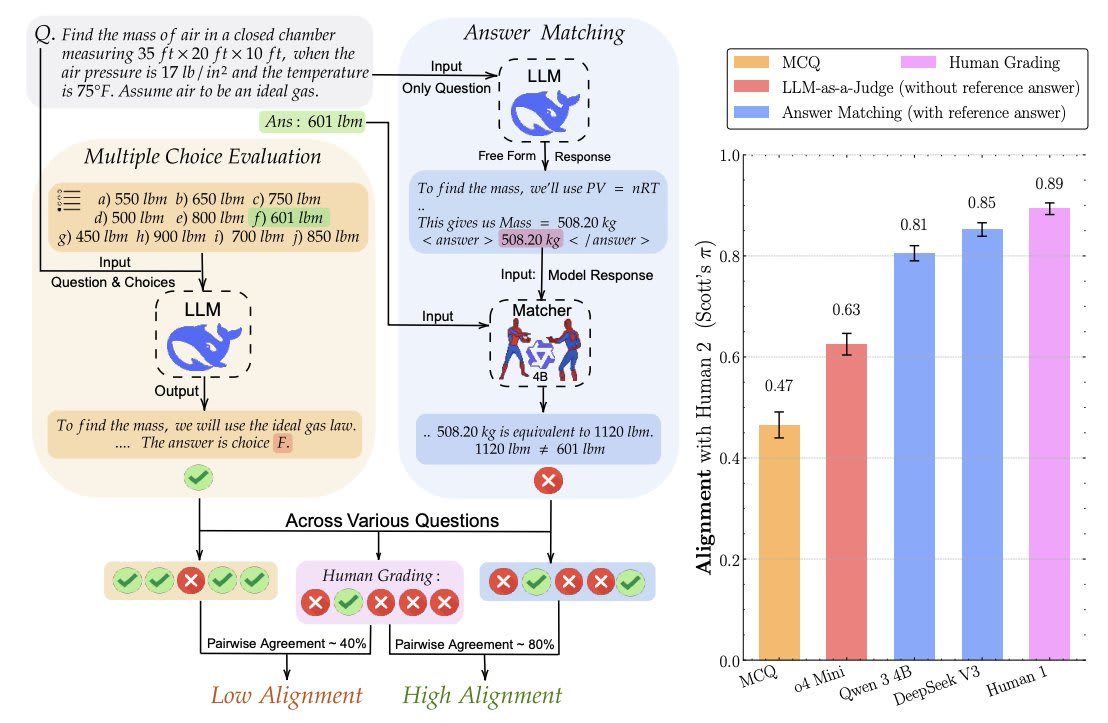
Discriminative Shortcuts in MCQ
We found MCQs can be solved without even knowing the question. Looking at just the choices helps guess the answer and get high accuracies. This affects popular benchmarks like MMLU-Pro, SuperGPQA etc. and even "multimodal" benchmarks like MMMU-Pro, which can be solved without even looking at the image.
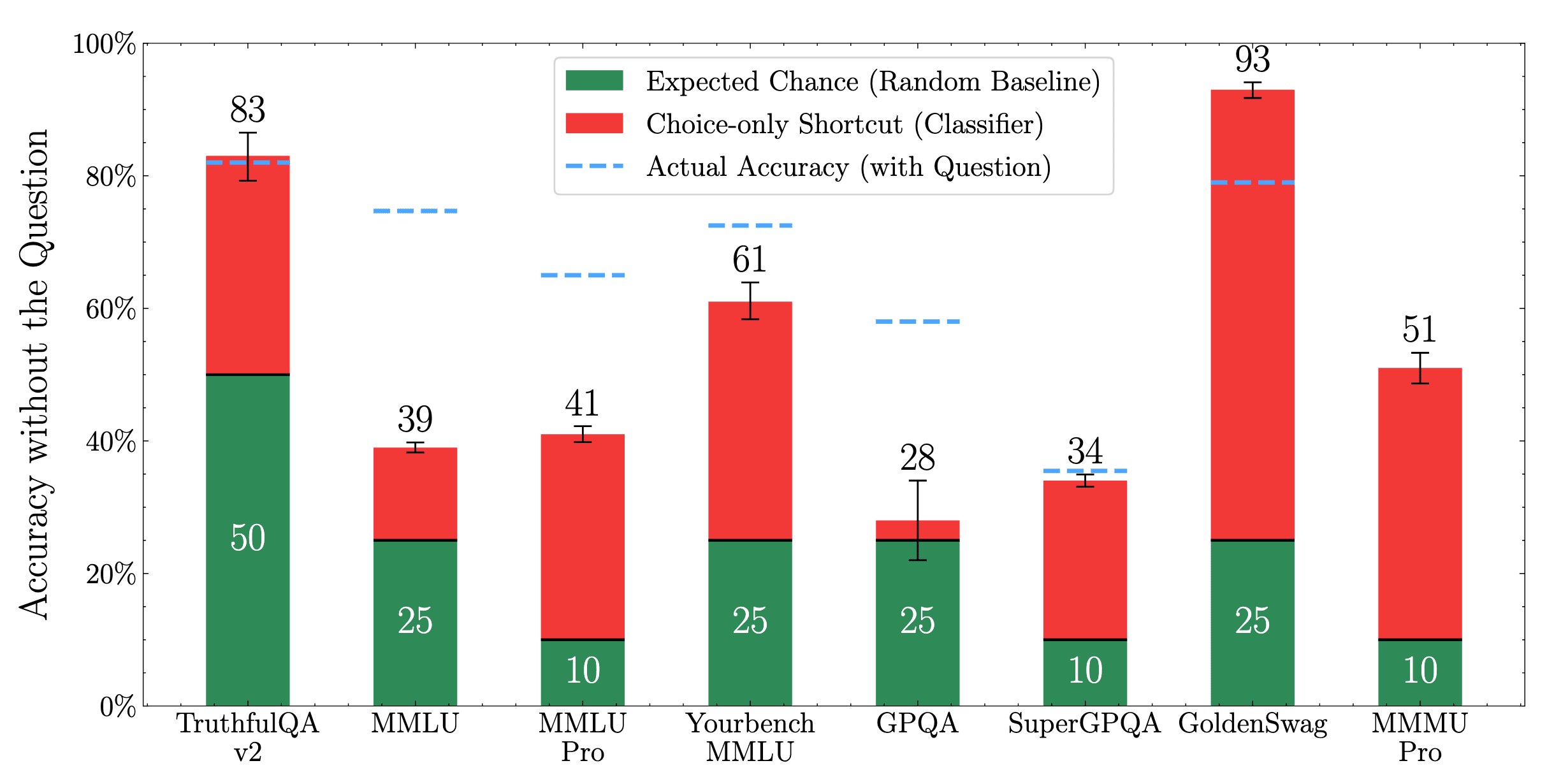
Such choice-only shortcuts are hard to fix. We find prior attempts at fixing them-- GoldenSwag (for HellaSwag) and TruthfulQA v2 ended up worsening the problem. MCQs are inherently a discriminative task, only requiring picking the correct choice among a few given options. Instead we should evaluate language models for the generative capabilities they are used for. In the Appendix, we discuss how discrimination is easier than even verification, let alone generation.
Shortcuts are exacerbated by the recent trend of using LLMs to create MCQs. However, they are still significant in MMLU, which consists of human-designed exams like GRE and USMLE. These results are with a Qwen3-4B based classifier, but even DeBerta gets high shortcut accuracy.
But how do we grade generative responses outside "verifiable domains" like code and math? So many paraphrases are valid answers...
Generative Evaluations with Answer Matching
We show a scalable alternative--Answer Matching--works surprisingly well. Its simple--get generative responses to existing benchmark questions that are specific enough to have a semantically unique answer without showing choices. Then, use an LM to match the response against the ground-truth answer.
We conduct a meta-evaluation comparing Answer Matching to LLM-as-a-Judge without reference answers, MCQ, and also some non-discriminative variants of MCQ used recently like MC-Verify (for eg in Virology Capabilities Test) and MC-Cloze. We first compare the evaluations in a domain where ground-truth verification is possible, MATH, using the recently released MATH-MC variant for comparisons.
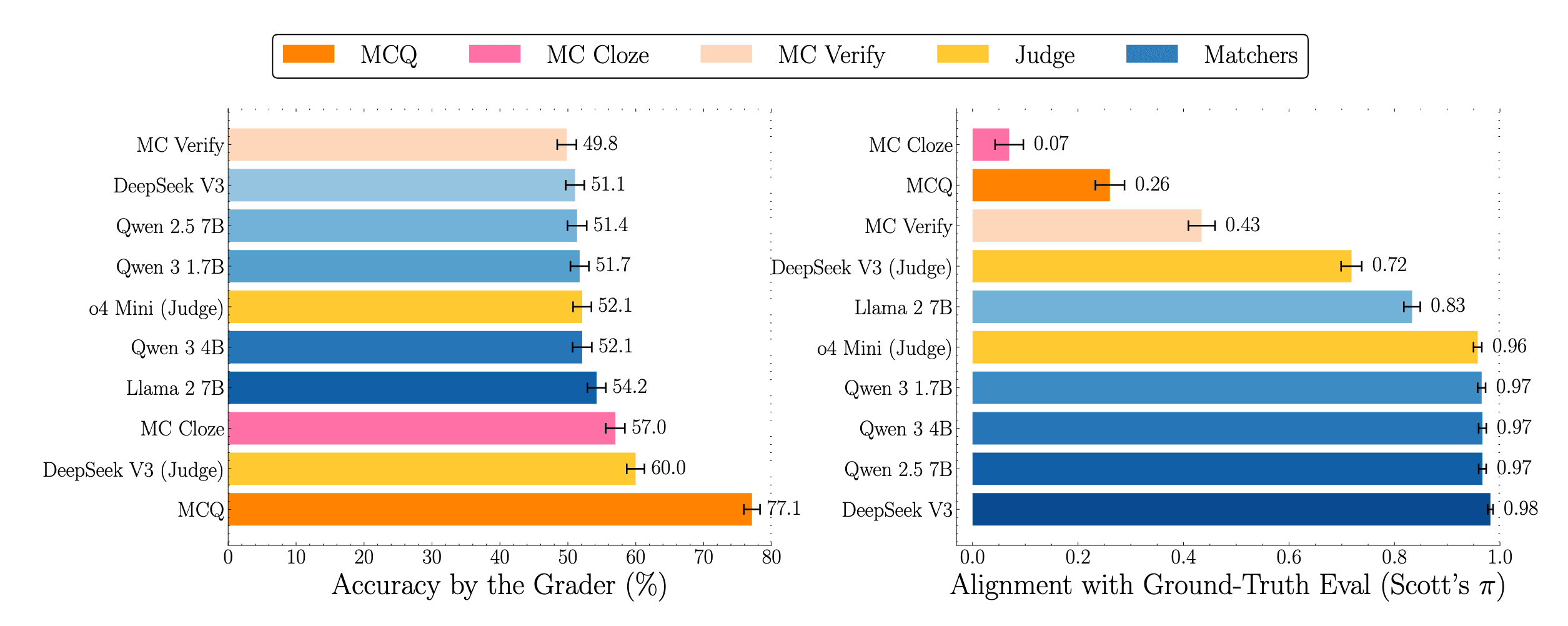
Note how the non-discriminative styles of MCQ show reduced accuracy similar to generative evaluation (Left). But accuracy is not all you need from evals. They should be aligned at a sample-level with ground-truth verification, so we can study where models are right/wrong. From the alignment plot (Right), it becomes clear:
- All MCQ variants are poorly aligned with ground-truth verification. Even small matchers (4B) can achieve near-perfect alignmentModels are much worse at judging correctness without a reference than answer matching (0.72 vs 0.98 for Deepseek V3).
But we don't need LMs for verifiable domains. Rather we need them for tasks with unconstrained answers prone to "paraphrases" that are semantically equivalent. So we manually grade generative responses on free-form versions of frontier reasoning benchmarks which have arbitrary textual answers: MMLU-Pro and GPQA-Diamond. For human grading, we freely use the internet, calculators and more such tools to increase the accuracy.
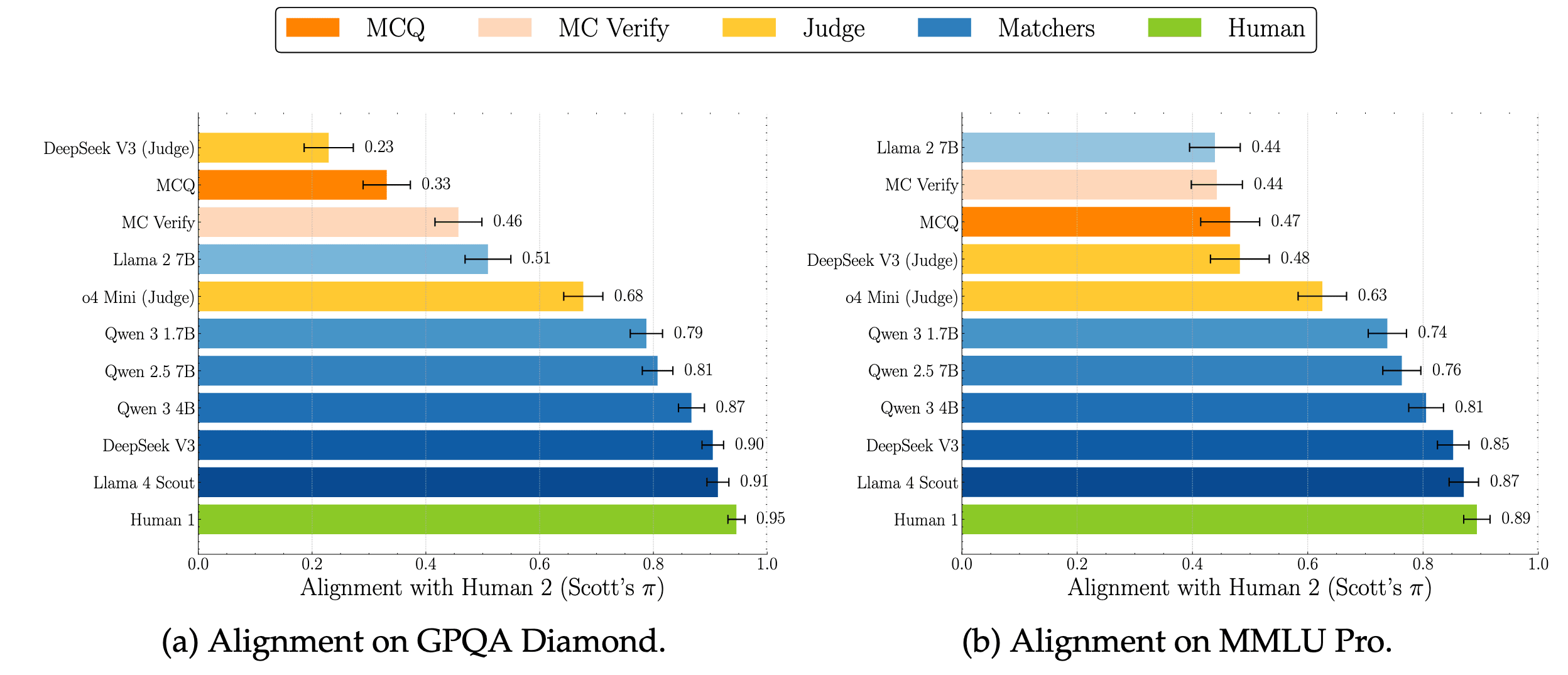
Answer Matching outcomes give near-perfect alignment, with even small (recent) models like Qwen3-4B. In contrast, LLM-as-a-judge, even with frontier reasoning models like o4-mini, fares much worse. This is because without the reference-answer, the model is tasked with verification, which is harder than what answer matching requires--paraphrase detection--a skill modern language models have aced.
Impacts on Benchmarking
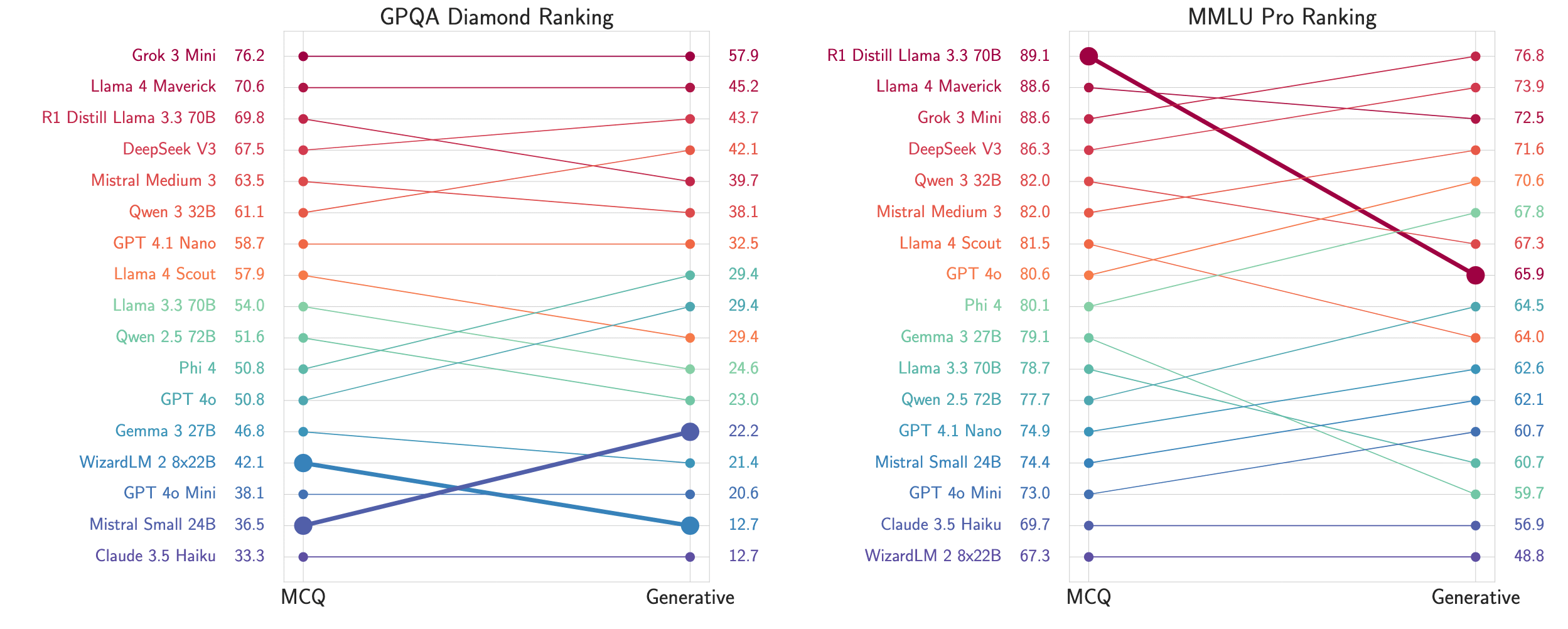
This is not merely a theoretical concern. Switching from MCQ to generative evaluations changes model rankings. Further, accuracies drop, and datasets that seem saturated start showing room for improvement.
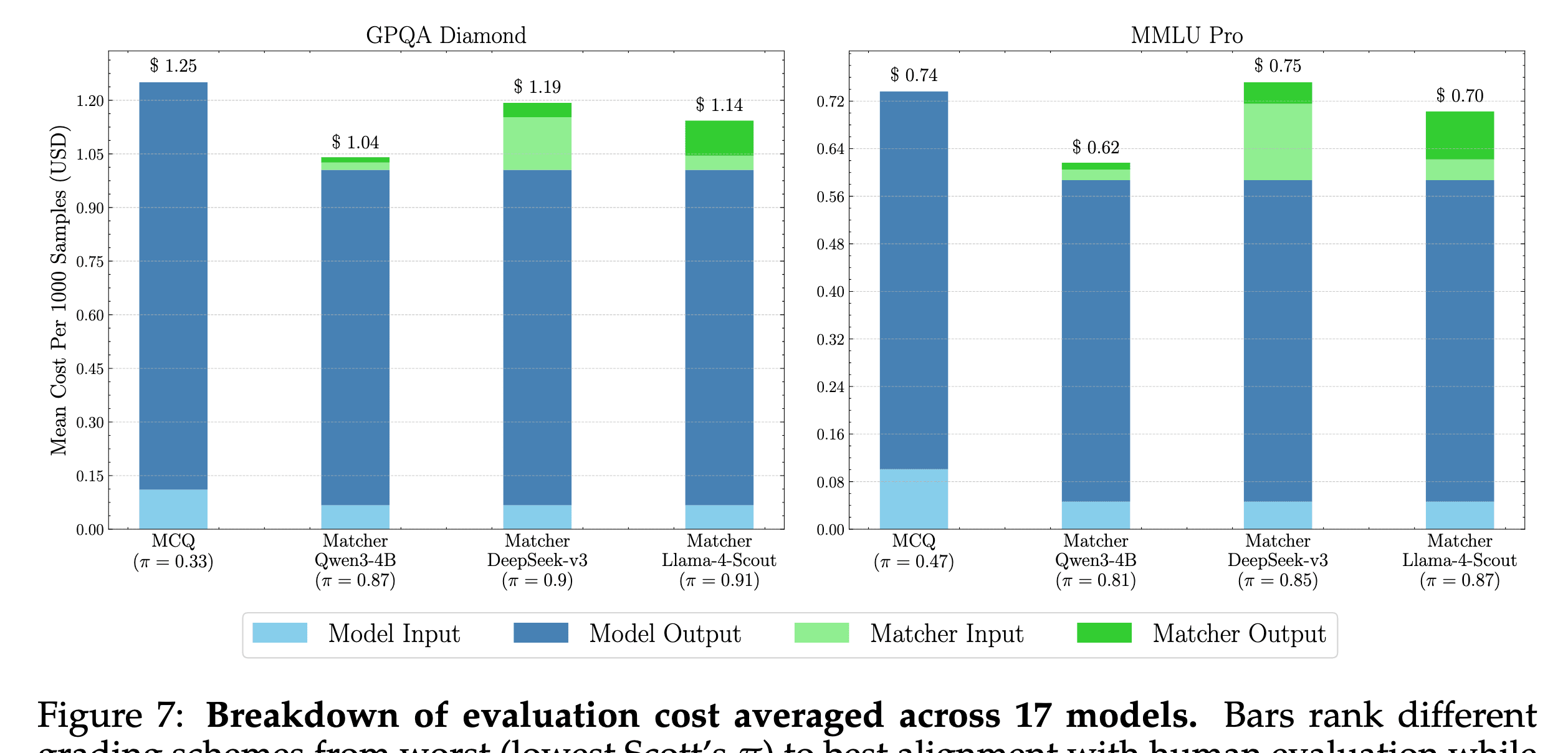
A common rebuttal is that LLM based evaluations are expensive. We show this is not true anymore. We don't need frontier API models, for answer matching Qwen3-4B might be enough. Surprisingly, with CoT enabled, MCQ costs more as models give longer outputs.
So instead of creating harder MCQs, we should focus our efforts on creating questions for answer matching, much like SimpleQA, GAIA, and parts of HLE. For example, either make questions specific enough to have a single semantic (LLMs can handle paraphrasing) answer, or list the multiple correct solutions that are possible.
We release our code, and annotations for subsets of MMLU-Pro and GPQA which have a unique semantic answer.
Discuss
