
Published on July 5, 2025 5:46 PM GMT
In this post I want to highlight a small puzzle for causal theories of mechanistic interpretability. It purports to show that causal abstractions do not generally correctly capture the mechanistic nature of models.
Consider the following causal model :
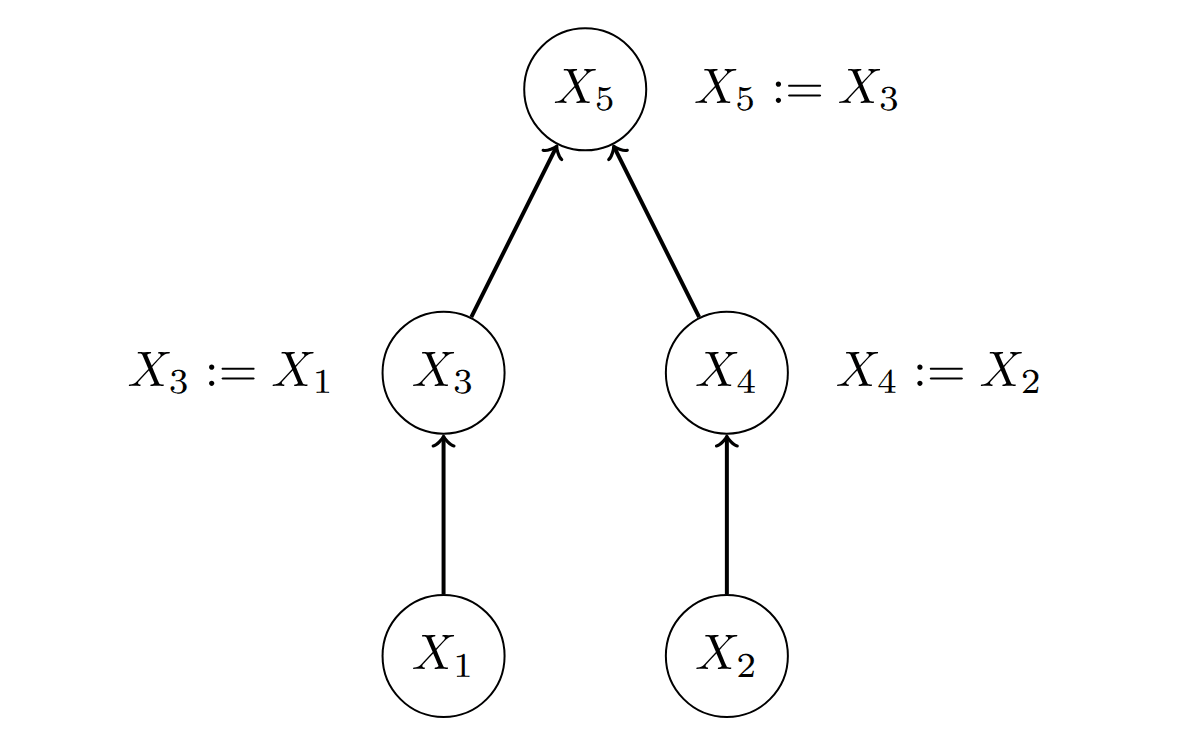
Assume for the sake of argument that we only consider two possible inputs: and , that is, and are always equal.[1]
In this model, it is intuitively clear that is what causes the output , and is irrelevant. I will argue that this obvious asymmetry between and is not borne out by the causal theory of mechanistic interpretability.
Consider the following causal model :
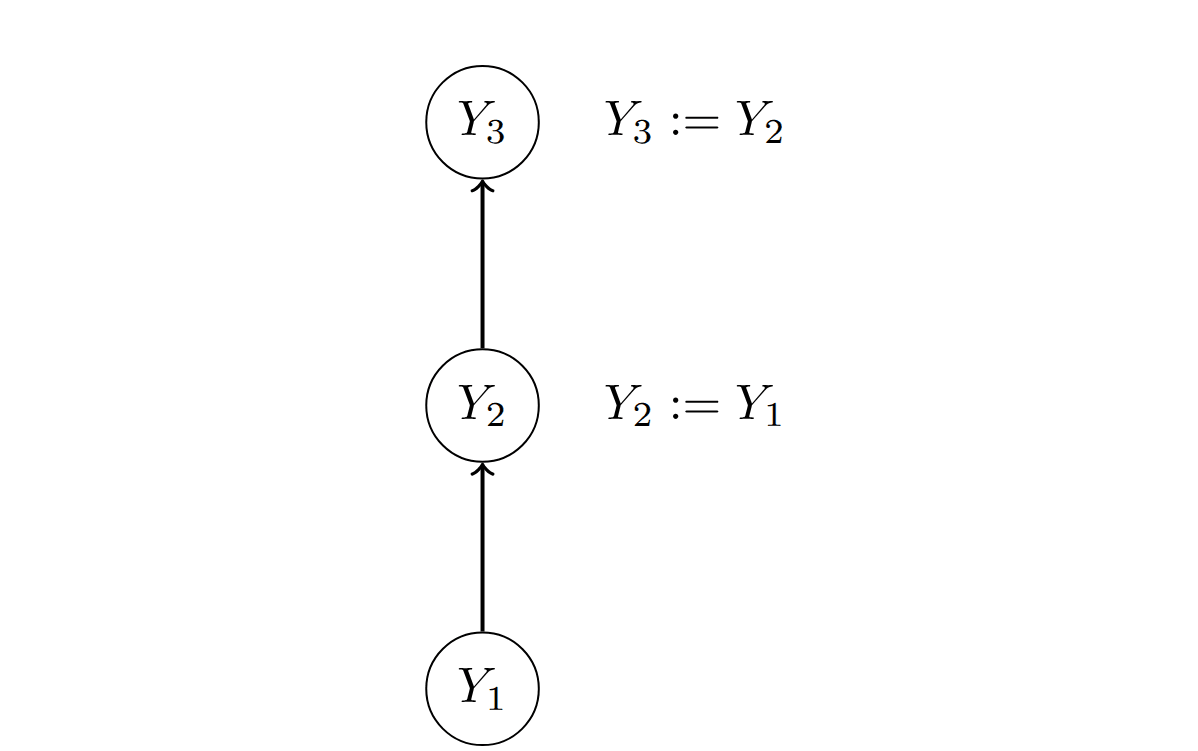
Is a valid causal abstraction of the computation that goes on in ? That seems to depend on whether corresponds to or to . If corresponds to , then it seems that is a faithful representation of . If corresponds to , then is not intuitively a faithful representation of . Indeed, if corresponds to , then we would get the false impression that is what causes the output .
Let's consider the situation where corresponds to . Specifically, define a mapping between values in the two models
with
such that corresponds to , corresponds to , and corresponds to . How do we define whether abstracts under ? The essential idea is that for every single-node hard intervention on intermediary nodes in the high-level model , there should be an implementation of this intervention on the low-level model such that [2]
Let us be explicit about the implementations of interventions:
for . Now, we can check that the abstraction relationship holds. For example:
That is a valid causal abstraction of under shows that the notion of causal abstraction, as I have formalized it here, does not correctly capture the computation that happens on the low level (and I claim that the same is true for similar formalizations, for example, Definition 25 in Geiger et al. 2025). Indeed, if the range of is extended such that , we would now make a wrong prediction if we use to reason about , for example, because .
One might object that as long as the range of is , should indeed be considered a valid abstraction of under . After all, the two models are extensionally equivalent on these inputs, that is,
I think this objection misses the mark. The goal of mechanistic interpretability is to understand the intensional properties of algorithms and potentially use this understanding to make predictions about extensional properties. For example, if you examine the mechanisms of a neural network and find that it is simply adding two inputs, you can use this intensional understanding to make a prediction about the output on any new set of inputs. In our example, and get the intensional properties of wrong, incorrectly suggesting that it is rather than that causes the output. This incorrect intensional understanding leads to a wrong prediction about extensional behavior once the algorithm is evaluated on a new input not in . While I have not argued this here, I believe that this puzzle cannot be easily fixed, and that it points towards a fundamental limitation of the causal abstraction agenda for mechanistic interpretability, insofar as the definitions are meant to provide mechanistic understanding or guarantees about behavior.
Thanks to Atticus Geiger and Thomas Icard for interesting discussions related to this puzzle. Views are my own.
- ^
Feel free to consider and as a single node if you are uncomfortable with the range not being a product set.
- ^
Here refers to the vector of values that the variables in take given input . For example, .
Discuss
