
文本扩散模型这次要起飞了?
5月,在I/O 2025大会上,谷歌推出了Gemini Diffusion,主打速度快:采样速度轻松可达每秒1000个token。
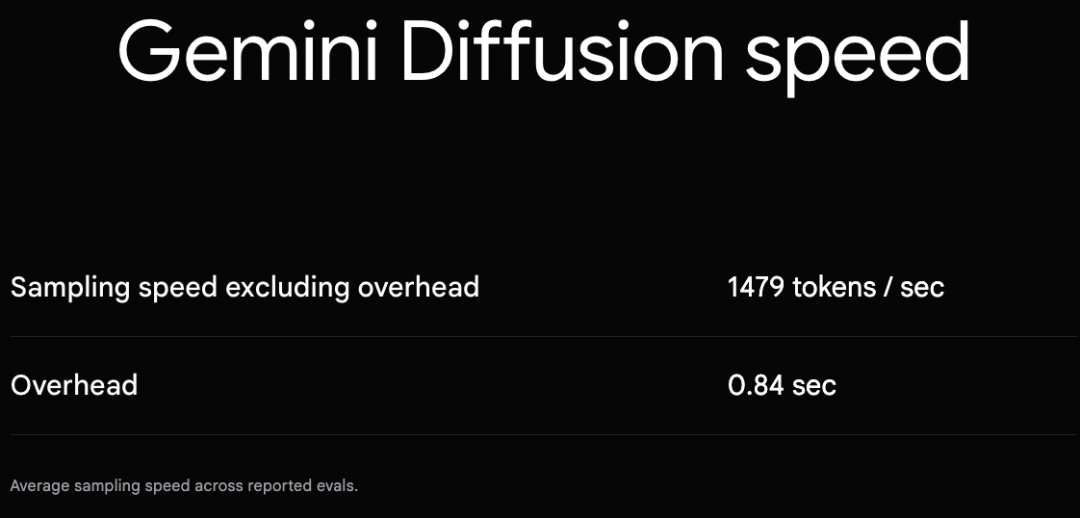
本该光芒四射、万众瞩目的Gemini Diffusion却被Veo 3等抢了风头。
戏剧性的是,隔天19岁德国小孩哥表示自己破解了其中的原理,引起了万人围观。
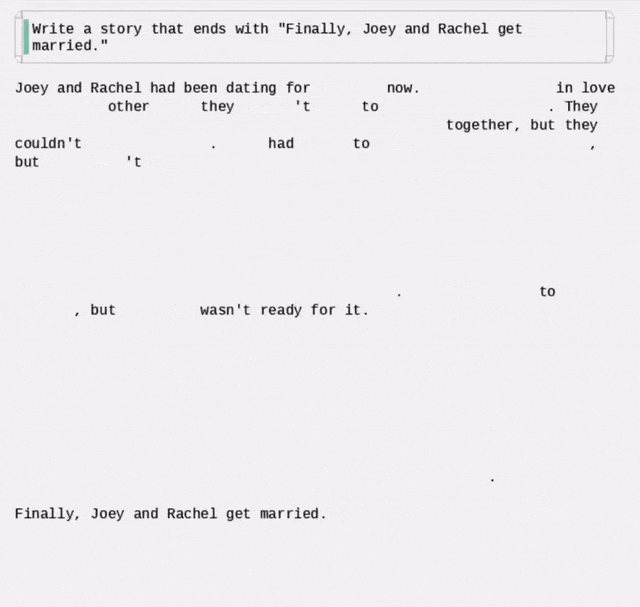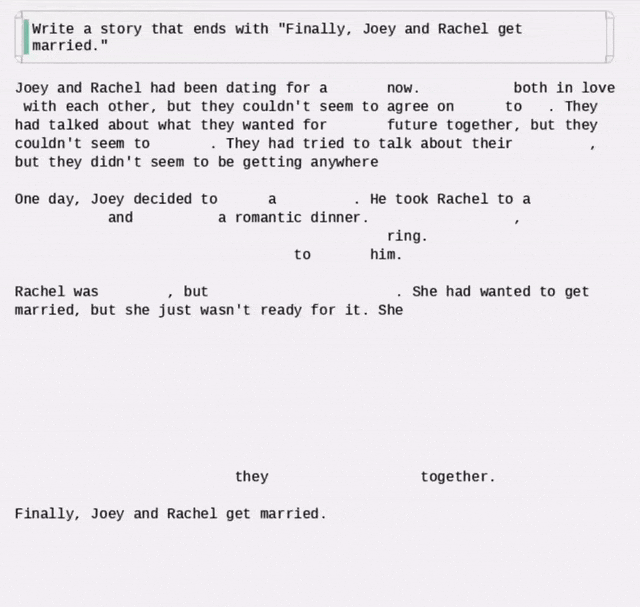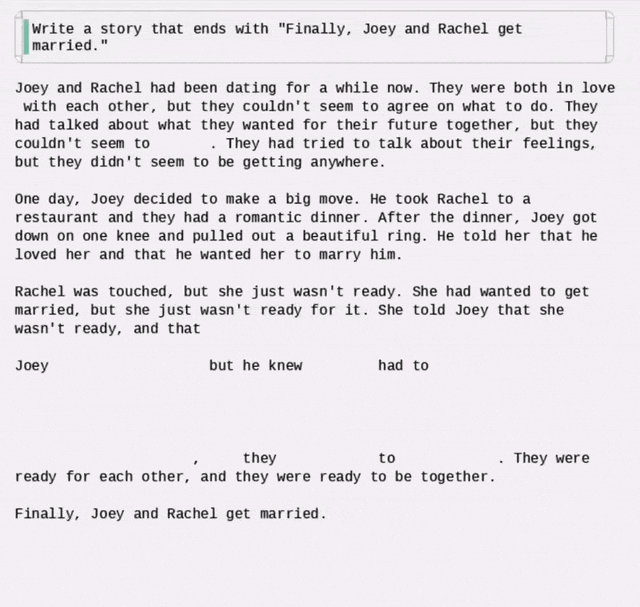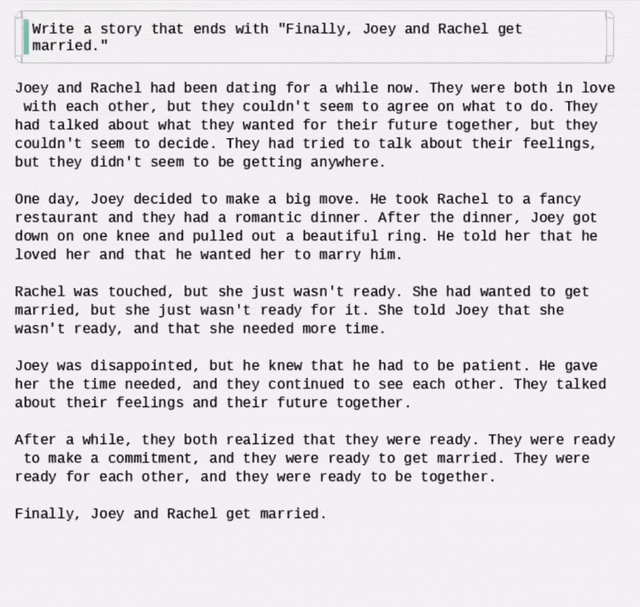
但很快就有网友发现,他用的动图,其实是来自国内的研究——Dream 7B。😅
也正是这个团队的成员,最近联合苹果放出了新的大招。
通过与港大相关团队合作,苹果用1300亿有效token训出了自己的扩散大语言模型(Diffusion Large Language Model,dLLM)——7B参数的DiffCoder。

论文链接:https://arxiv.org/abs/2506.20639
项目链接:https://github.com/apple/ml-diffucoder
另外值得一提的是,作者除苹果的Navdeep Jaitly外都是华人。

dLLM具备全局规划与迭代优化能力,尤其适合代码生成。
但缺乏dLLM训练方法与推理策略。
为揭开dLLM解码机理,苹果联合港大开源了新模型——DiffuCoder。
与GPT等自回归比较,这次发现dLLM确实不一样:
dLLM可自主调节生成过程的因果性,无需半自回归(semi-AR)解码;
提高采样温度不仅拓宽了token的选择氛围,还改变了生成顺序,进一步增强了多样性。
这种双重多样性为强化学习提供了更丰富的搜索空间。

针对RL训练中的对数似然估计方差问题,他们还创新性提出的耦合梯度奖励策略优化(coupled-GRPO)方法,通过构建互补掩码噪声对提升训练效率。
实验表明:
在EvalPlus基准上实现+4.4%的性能提升
有效降低解码过程对AR偏置的依赖(见图1c)
这次研究不仅深化了对dLLM生成机制的理解,更建立了首个专为扩散模型设计的原生RL训练框架。
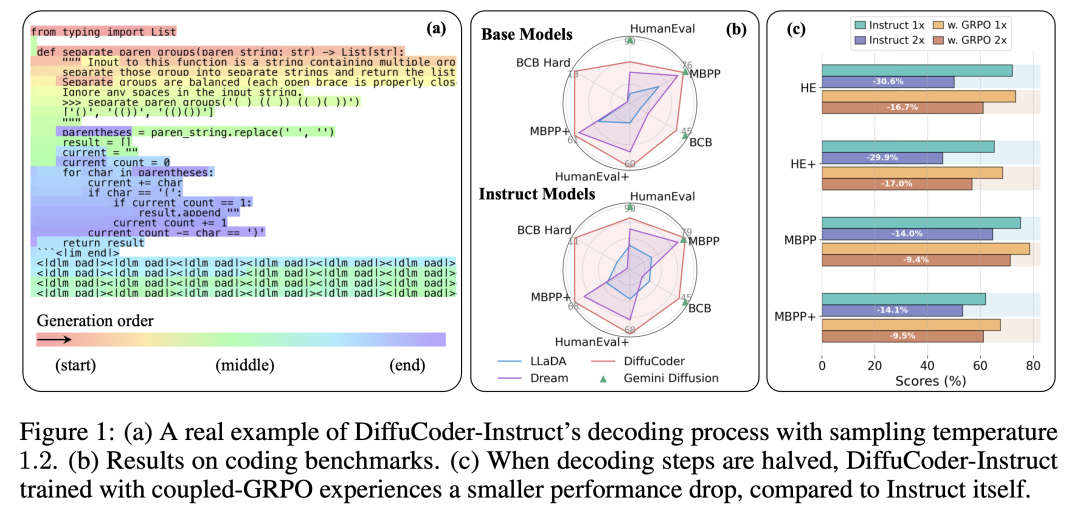
图1:(a)DiffuCoder-Instruct模型在采样温度1.2时的解码过程实例;(b)代码生成基准测试结果对比;(c)当解码步数减半时,采用耦合-GRPO训练的DiffuCoder-Instruct性能下降幅度显著小于原始指令微调模型
这次工作重点探究3大问题:
生成模式差异:与AR模型相比,dLLM的生成机制有何本质区别?
模态建模特性:在代码与数学等不同数据模态的建模中,dLLM表现出哪些差异化特征?
多样性潜力:dLLM的生成多样性边界如何界定?相应的训练后策略应如何针对性设计?
他们还提出了全新的指标:自回归度得分(autoregressiveness score,AR-ness),用于量化dLLM在生成过程中是否呈现出「因果式」的顺序偏好。
关键发现如下:
dLLM仍存在一定的「从左至右」偏好。这是由文本天然的线性结构所决定的。但与自回归(AR)模型不同的是,dLLM具备打破这一约束的能力!
代码任务比数学任务更能激发「去顺序化」的生成方式。实验显示,在预训练阶段,dLLM在处理代码任务时表现出更低的「全局自回归度」,这说明代码更适合并行生成。
采样温度不仅影响生成内容,还会改变生成顺序!与AR模型不同,dLLM中调整temperature参数会同时影响token选择和token生成的位置顺序,生成过程更加灵活。
更多惊喜性发现详见原论文,研究人员揭示了dLLM结构中的多个「非因果化」潜力点,值得深入探索。
此外,研究人员还提出了后训练方法——Coupled-GRPO,专为DiffuCoder设计。
保持采样效率的同时,耦合机制进一步提升了模型性能。
扩散模型,正在重构写代码的方式。

在多项基准测试上,研究人员评估了DiffuCoder的表现(见表1)。
这些测试以Python为主,涵盖从基础完成到复杂指令生成的多种任务。
📈结果亮点:
经过130B代码token的训练(Stage 1+2),DiffuCoder在多个指标上已与Qwen2.5-Coder、OpenCoder相当;
在pass@1任务上,Coupled-GRPO后训练策略展现出显著优势。
然而,在指令微调阶段,所有dLLM模型的增益仍显疲弱,说明后续还需加强dLLM在理解/执行复杂自然语言任务上的能力。
表1:7B/8B规模语言模型代码生成能力基准测试

dLLM的生成方式与自回归模型有何不同?
在标准的自回归解码中,无论是局部还是全局自回归性都为1(即100%自回归)。
但如图3所示,dLLM的生成顺序更加灵活:许多token并不是依序从最左侧的Mask位置或下一个token开始恢复的。
这表明与传统的自回归模型相比,dLLM并不总是按顺序解码。
不过,它们的局部和全局AR-ness都显著接近1,说明文本本身具有一定的顺序结构。
在DiffuCoder中,研究者认为模型可以自主决定在生成时采用多强的因果结构。
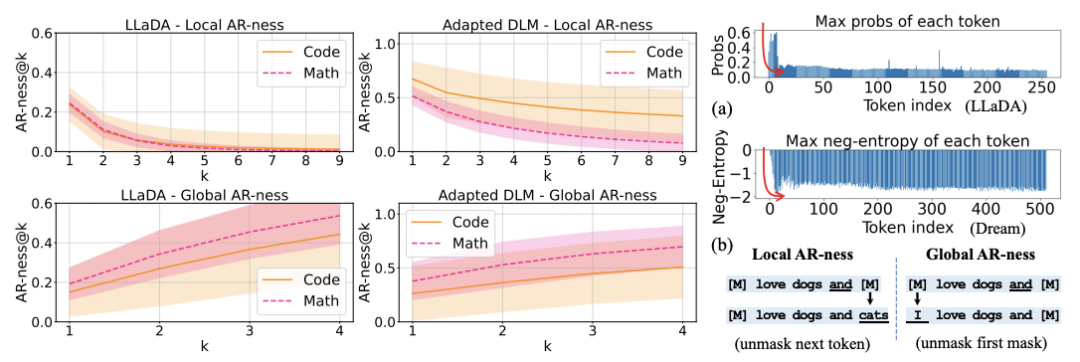
图3:左图:不同模型与数据模态下的局部与全局自回归特性比较。右图:(a)dLLM首次前向解码过程中各位置的置信度评分;(b)局部自回归性@k:指在k=1(即下一token预测)时,新解掩token与其前k个连续预测token构成严格递增序列的解码步骤占比;全局自回归性@k:模型在所有剩余被掩token中选择解掩最靠前k个位置的解码步骤占比。
从图3可以看出,尽管数学题和代码的局部AR-ness程度不同,但稳定的趋势是:代码生成的全局AR-ness平均值更低,波动更大。
这说明模型在生成代码时,往往优先预测后面的token,而将前面被Mask的token延后填充。
这可能是因为:
数学文本本质上是按顺序构建的,通常要求从左到右推理;
代码则具有更强的结构性,模型更倾向于像程序员一样在不同位置之间跳跃进行规划。
在训练早期(图4中的阶段1),当模型看到650亿个token时,AR-ness已经相对较低。但当训练规模扩大到7000亿token时,AR-ness提高了,然而整体性能却下降了。
这可能与预训练数据质量有关,因此选择650亿token的模型作为后续训练的基础。
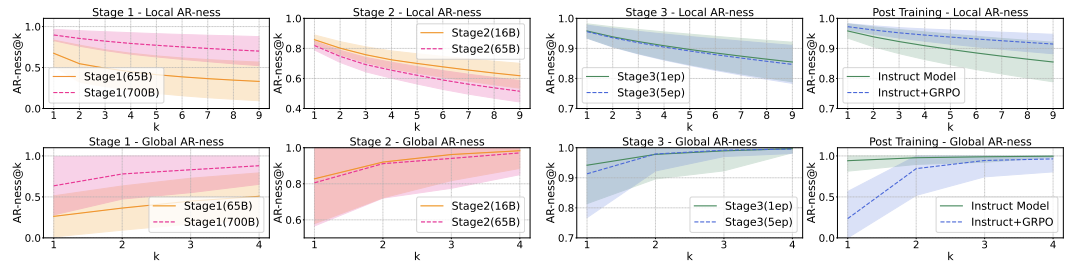
图4:不同训练阶段的自回归特性漂移情况。左图:适配预训练阶段与中期训练阶段;右图:指令微调与强化学习后训练阶段。
在后续阶段(阶段2的中期训练与阶段3的指令微调)中,模型在第一轮训练后表现出明显的因果偏置。但随着训练继续,虽然任务表现不断提升,AR-ness却逐渐下降。
这表明模型开始学习并利用非顺序性的依赖结构。
在经过GRPO训练后,模型的全局AR-ness进一步下降,但生成步骤减半的情况下,性能下降幅度却较小(见图1(c))。
当dLLM进行条件生成时,扩散过程从完全被Mask的补全文本开始,并尝试逐步恢复全部内容。
在第一步中,研究者记录了每个恢复出来的token的置信度(见图3(a))。
研究者观察到,这些置信度的分布呈现出「L」形。他们把这种现象称为「熵汇集」(Entropy Sink)。这种现象可能源于文本的结构本身。
这种「熵偏置」可能与注意力机制中的「注意力汇」现象,但其本质仍有待进一步研究。
由于这个偏向邻近位置的现象存在,dLLM仍然表现出一定程度的自回归性。

已有研究表明,在接受强化学习(RL)训练后,自回归LLM推理路径的多样性受到基础模型的pass@k抽样能力的限制。
因此,研究者采用pass@k准确率指标,来衡量扩散式大语言模型(dLLMs)在生成样本时的多样性表现。
如图5右和图6所示,无论是DiffuCoder的基础模型,还是经过指令微调的版本,当温度设置较低时,虽然能获得较高的pass@1准确率,但pass@k几乎没有提升,说明生成结果高度集中,缺乏多样性。
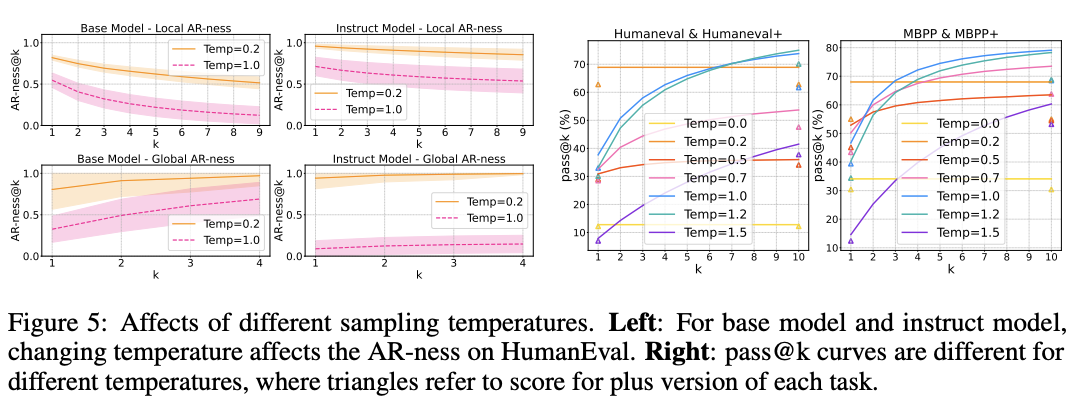
当把温度提高到适中范围,模型的pass@k明显上升,说明具备生成多种正确答案的潜力。
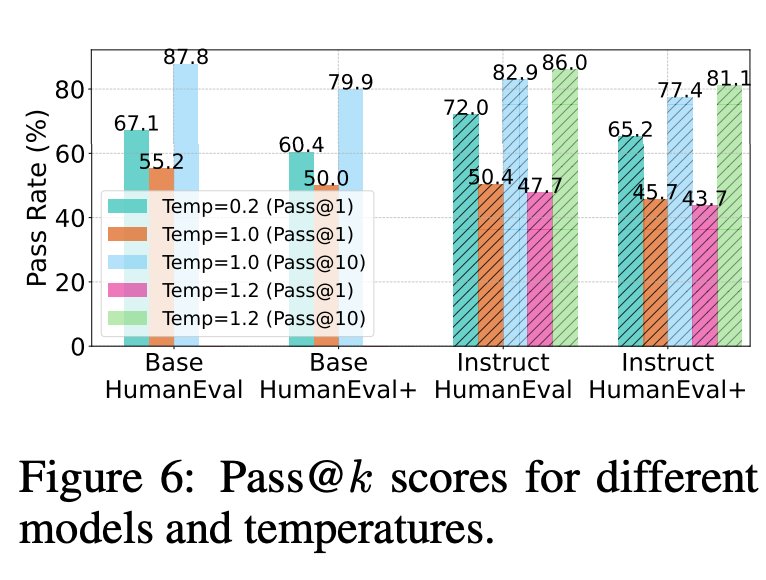
此外,如图5左和图1(a)所示,温度越高,模型的自回归性(AR-ness)越低,意味着生成的token顺序更加随机。
这一行为与自回归模型截然不同:
在AR模型中,温度仅影响每一步选择哪个token;
在dLLMs中,温度不仅会影响token的选择,还会改变其生成的顺序。

之前,扩散模型缺乏强化学习潜力。
这次,团队遵循下文中的范式,多阶段大规模训练了DiffuCoder。

论文链接:https://arxiv.org/abs/2410.17891
整体流程如图2所示,分为四个阶段:
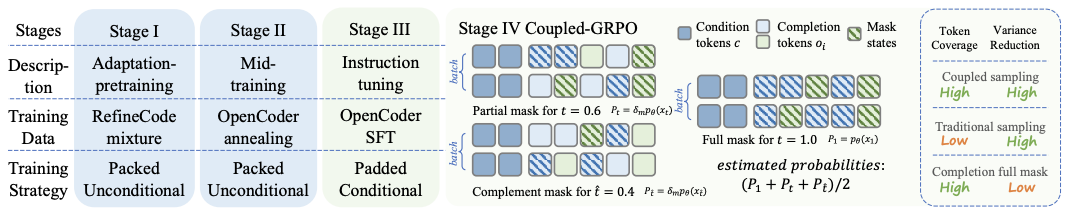
图2:DiffuCoder训练阶段的流程及耦合-GRPO算法的示意图。
预训练阶段以Qwen-2.5-Coder作为基础模型,使用「适配式预训练方法」进行持续训练。
中间训练阶段作为稳定模型参数的「退火期」,总体token量仍为65B,使用了16Btoken的退火代码数据。
指令微调阶段为了提升模型理解和执行复杂自然语言指令的能力,采用了OpenCoder提供的436K大小的SFT样本。

论文链接:https://arxiv.org/abs/2411.04905
不过,不像Qwen2.5-Coder用了SFT之后有非常显著的增益,Diffusion模型微调之后性能提升非常有限。这说明当前dLLM在指令对齐能力上仍有差距。
后训练阶段引入自研的Coupled-GRPO算法,这是团队为dLLM量身打造的强化学习机制,进一步提升DiffuCoder的单次准确率
Coupled-GRPO是为dLLM量身打造的强化学习机制。
常规做法只在「被掩码的token位置上」计算对数概率。
若是采样次数有限,这种方法容易受到训练信号稀疏和方差过大的困扰。
Coupled-GRPO算法抛弃了这种做法。
全新的Coupled-GRPO则在两个「互补的掩码视角」下,评估每个token的概率,从而高效获取完整训练信号。

具体来说,Coupled-GRPO采用对称时间步+互补掩码双路径前向传播,计算开销增长不大,同时采样效率翻倍。
这招打破了「只能在掩码位置学」的老规矩,让每个token都「上场发光」,堪称扩散范式的一次策略级进化。
Sansa Gong

Sansa Gong在香港大学攻读博士学位,导师是Lingpeng Kong。本科和硕士均毕业于上海交通大学。
她的研究兴趣包括扩散语言模型和长上下文语言模型。
此前,她在上海AI实验室的Shark-NLP团队担任自然语言处理研究员,并曾经从事姿态估计、面部识别、层次文本分类和推荐系统的工作。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
