
DeepSeek R1横空出世第128天,已经把整个大模型市场搅得天翻地覆!
首先,它以一己之力把推理模型的价格打下来,OpenAI六月更新的o3价格相比o1直接打了2折。
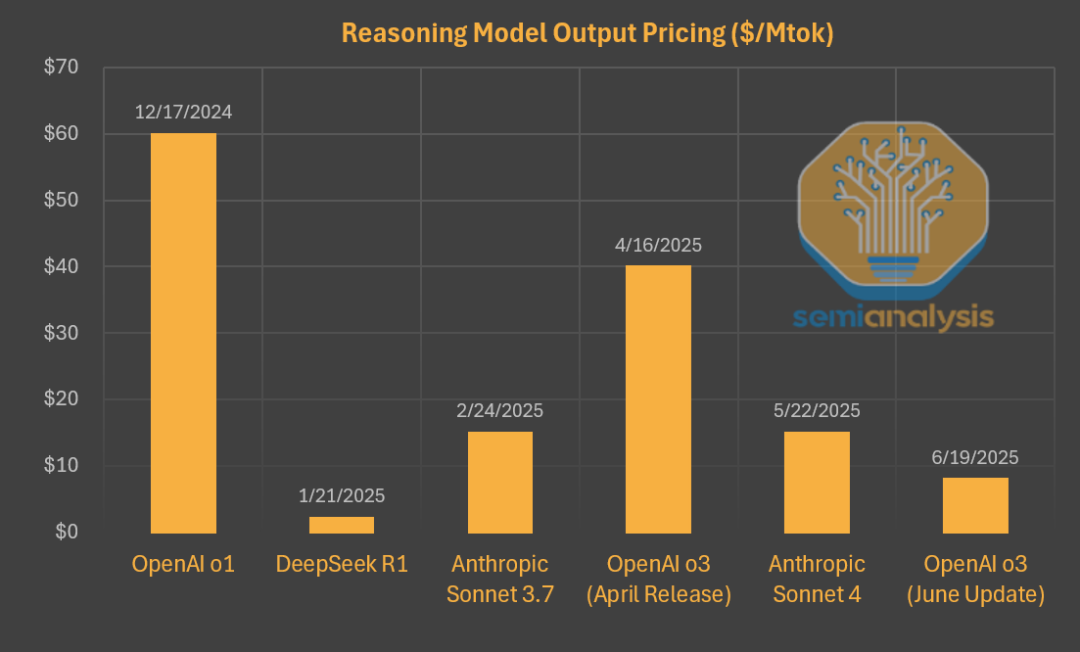
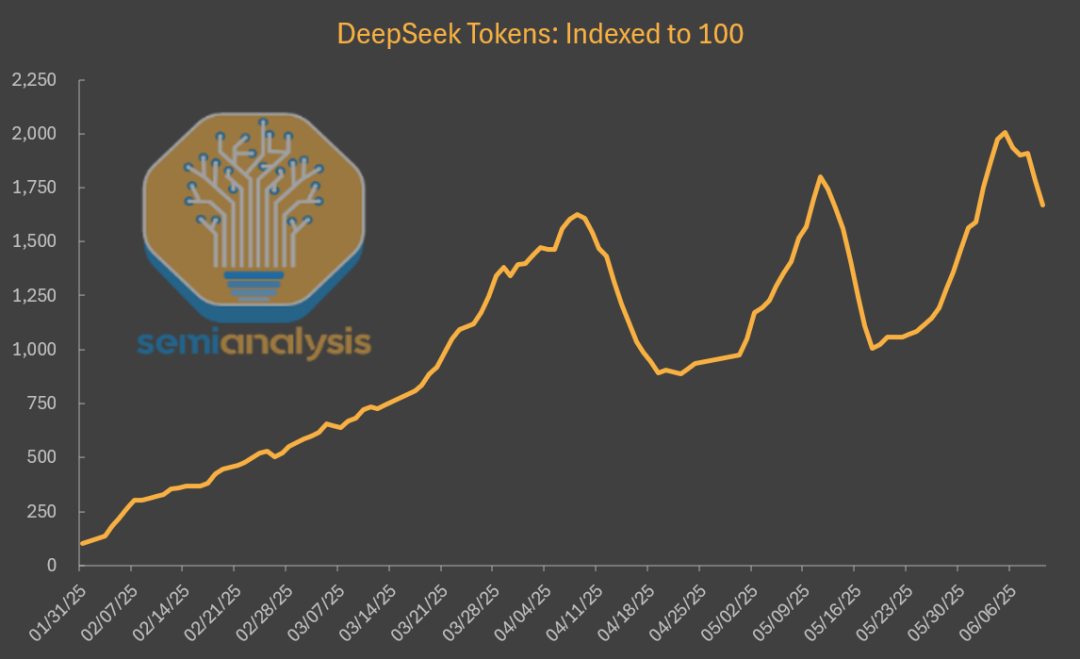
其次,第三方平台托管的DeepSeek模型使用量疯狂增长,比刚发布时涨了将近20倍,成就了大批云计算厂商。
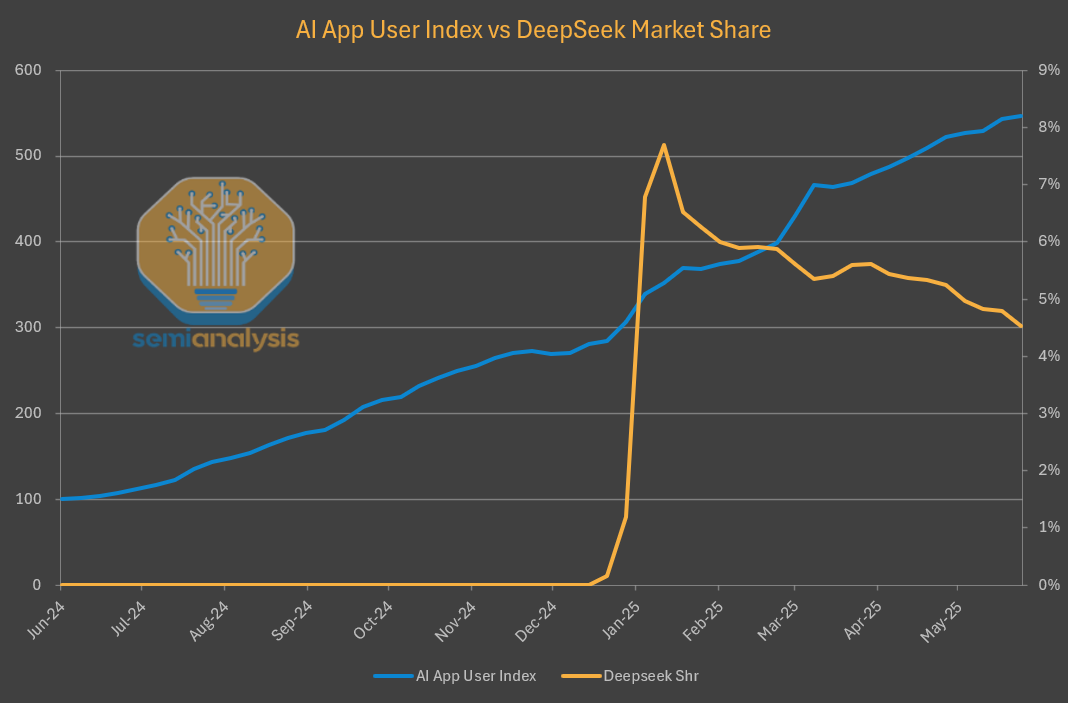
然而,DeepSeek自家的网站和API市场份额却不断下降,跟不上AI产品上半年持续增长的节奏了。
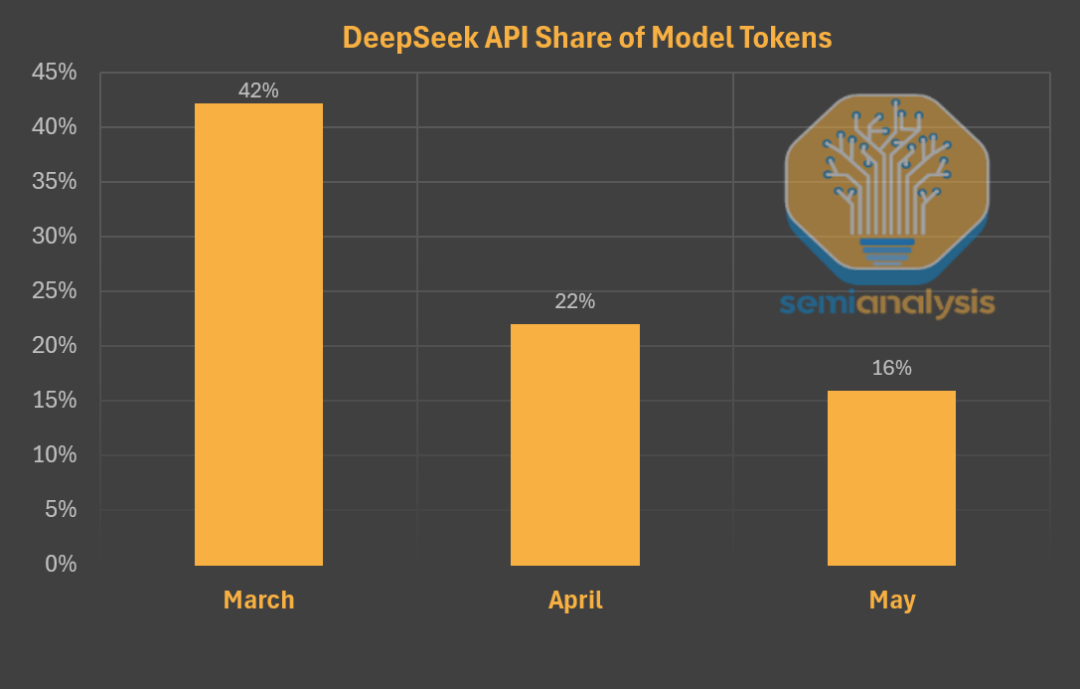
以上数据来自SemiAnalysis发布的一篇报告,详尽解读了DeepSeek对AI模型竞赛的影响以及AI市场份额的现状。

揭开DeepSeek的降本秘诀
DeepSeek刚发布时确实火得一塌糊涂,但四个多月过去了,情况却有点微妙。
从数据来看,DeepSeek自家网站和API的流量不升反降,市场份额也在持续下滑。
到了5月,全网DeepSeek模型产生的token中,来自DeepSeek本家的份额已经只占16%了。
网页版聊天机器人流量也大幅下降,而同期其他主要大模型网页版流量都在飙升。
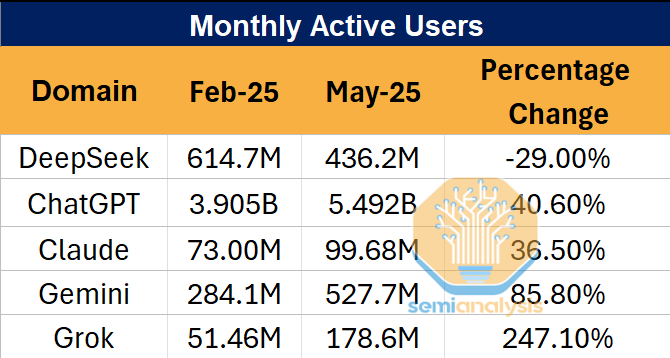
DeepSeek V3与R1模型都经过版本更新,能力与1月相比更强了,价格又便宜,怎么用户反而跑了呢?
这种“墙内开花墙外香”的现象,背后其实大有文章。
SemiAnalysis指出,DeepSeek为了把成本压到极致,在服务质量上还是做了大量妥协。
用户在DeepSeek官方平台上使用模型,经常要等上好几秒才能看到第一个字蹦出来,可以用首token延迟(First token latency)这个指标来衡量。
相比之下,其他平台虽然普遍价格更贵,但响应速度快得多,有些甚至能做到几乎零延迟。
在Parasail或Friendli等平台,只需支付3-4美元就可以获得几乎没有延迟的100万token额度。
如果想选择更大更稳定的服务商,微软Azure平台价格是DeepSeek官方的2.5倍,但延迟减少了整整25秒。
从另一个角度看,DeepSeek官方甚至不是同等延迟下价格最低的一家DeepSeek模型服务商。
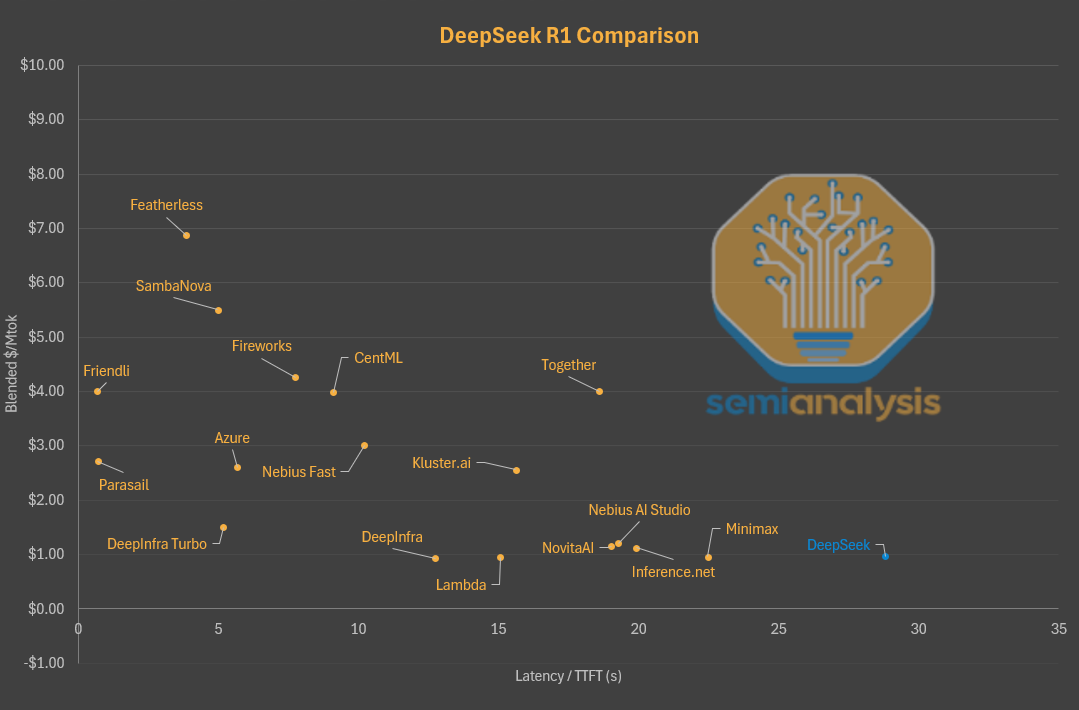
如果在这张图上用气泡大小表示上下文窗口,可以看出DeepSeek在价格与性能之间的另一个权衡。
在有限的推理计算资源下,只提供64k上下文窗口的服务,在主流模型提供商中算是最小的之一。
在需要读取整个代码库的编程场景里,64K根本不够用,用户只能选择第三方平台。
而同样价格下,Lambda和Nebius等平台能提供2.5倍以上的上下文窗口。
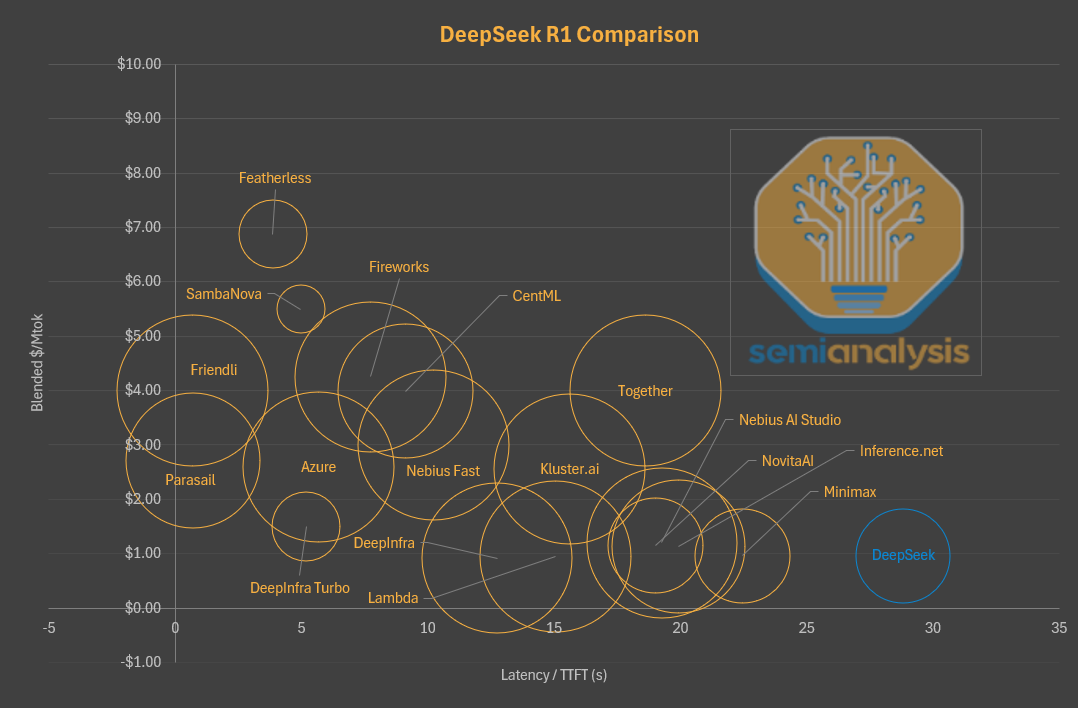
DeepSeek还把很多用户的请求打包在一起处理,虽然每个token的成本降下来了,但每个用户等待的时间也增加了。
大模型下半场:提升每个token的智能
需要明确的是,这些降本策略都是DeepSeek主动做出的决定。
他们目前看上去对用户体验不怎么感兴趣,既无意从用户身上赚钱,也无意通过聊天应用或API服务向用户提供大量token,更多地是专注于实现AGI。
从这些优化策略就可以看出,DeepSeek把尽可能少的算力用作推理服务给外部使用,大量的算力资源留在内部研发用途。
同时配合开源策略,让其他云服务托管他们的模型,赢得影响力和培养生态,两不耽误。
说到底,AI竞赛拼的还是算力资源。
在DeepSeek影响下,Claude也开始降低速度缓解算力紧张的问题,但为了营收还是在努力平衡用户体验。
Claude 4 Sonnet发布以来,输出速度已经下降了40%,但仍然比DeepSeek快不少。
另外Claude模型被设计成生成更简洁的回复,回答同样的问题,DeepSeek和Gemini可能要多花3倍的token。
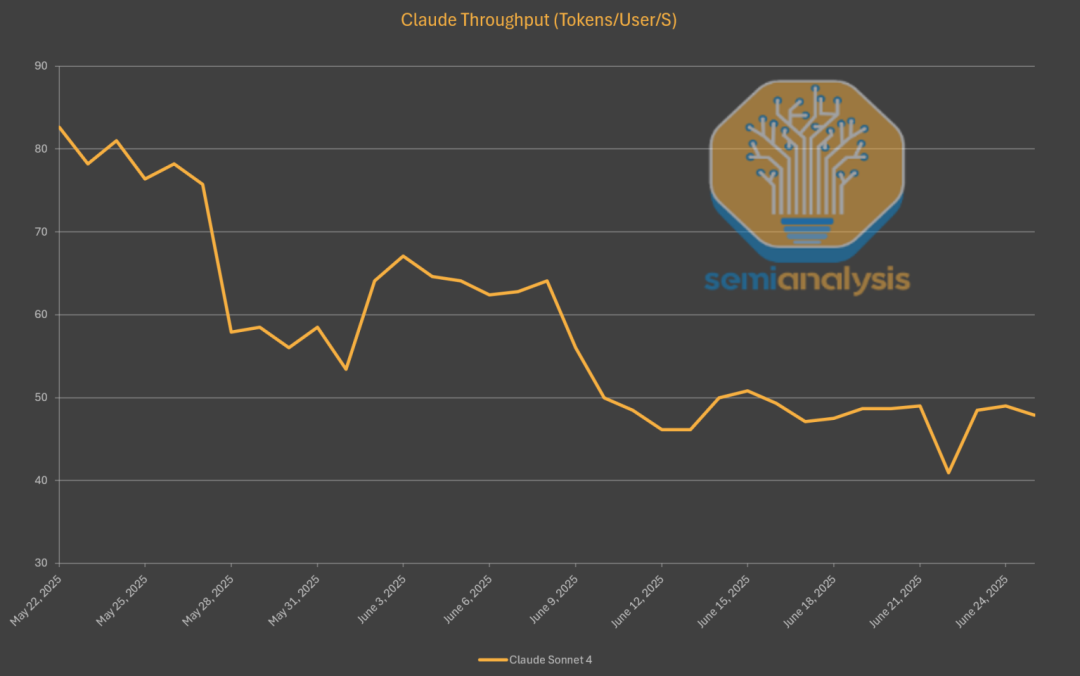
种种迹象表明,大模型供应商正在多维度地改进模型。
不仅仅是提高模型的智能上限,而是提升每个token能提供的智能。
参考链接:
[1]https://semianalysis.com/2025/07/03/deepseek-debrief-128-days-later/#speed-can-be-compensated-for
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
