
当推理链从3步延伸到50+步,幻觉率暴增10倍;反思节点也束手无策。
来自北京邮电大学的研究团队通过思维链审计实验,首次定量揭示了这一“越想越错”现象背后的元认知偏差:
长链推理中的反思不是纠错机制,而是给幻觉颁发“理性证书”——
模型为保持与用户提示语义一致,宁可篡改协议定义也不否定前提。

风险缺口:长链CoT放大“误差滚雪球”
推理大模型(RLLMs)能把复杂问题拆解成几十步推理,再给出看似缜密的结论。然而,随着推理链条变长,一个令人不安的趋势浮出水面——错误不再是偶发失误,而是沿链条滚雪球式放大。
在医疗、金融、法律等高风险场景,一次细小偏差就可能酿成灾难。
遗憾的是,当前安全评估几乎都停留在结果级:判定答案对错、衡量毒性与否,犹如“考试只看最后分数”。
这种做法忽视了一个关键问题:错误到底是如何在链内生根、扩散并固化的?如果无法洞察这一机制,就难以对症下药。
北京邮电大学的研究团队为解决这一问题,采取了以下方法:
首先基于RFC协议文档构建受控知识域,再让模型生成30–60步的长链推理,并在关键节点插入reflection操作以实时记录置信度变化。
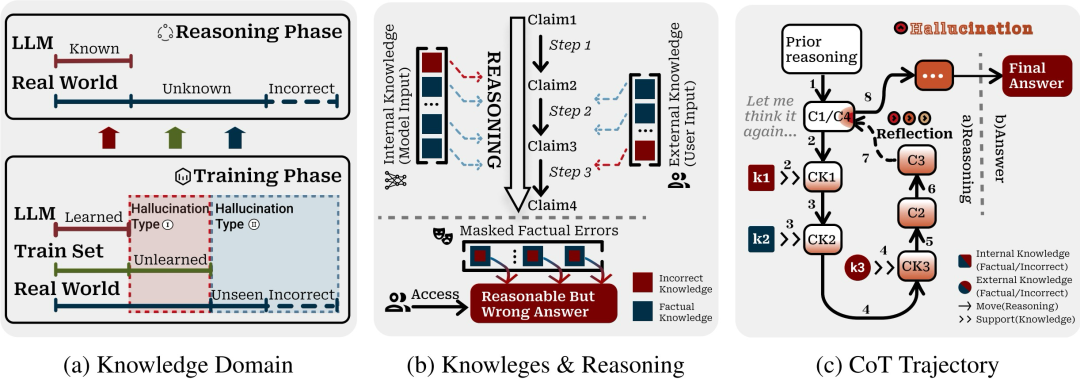
具体而言,他们构建了一个受控知识领域,该领域捕获了两种类型的幻觉案例,克服了在受控环境中可靠地重现幻觉的困难(图a)。
这个领域具有以下三个特点:
然后,他们提出了一种针对长链推理的建模系统,该系统追踪知识是如何在多个推理步骤中被引入、反馈和完善的,解决了在复杂的推理轨迹中研究幻觉演化的挑战(图b)。
更进一步,他们还审计了幻觉实例,以归因于现实案例中幻觉的传播,应对了理解长链推理背后幻觉潜在机制这一挑战。如图c所示,k1和k3通过错误知识引入幻觉,将最初正确的思维链第一步(c1)经由c3反射扭曲为幻觉产生的c4,从而揭示了推理模型中存在的潜在风险。
反思越深错误越真:长链推理的自我说服
通过对结果进行分析,北京邮电大学的研究团队揭示了RLLM产生幻觉的核心机制:
当模型在长思维链中反复挣扎,它不是在逼近真相——而是在用千余词的复杂推理,固化几十个词的错误答案。
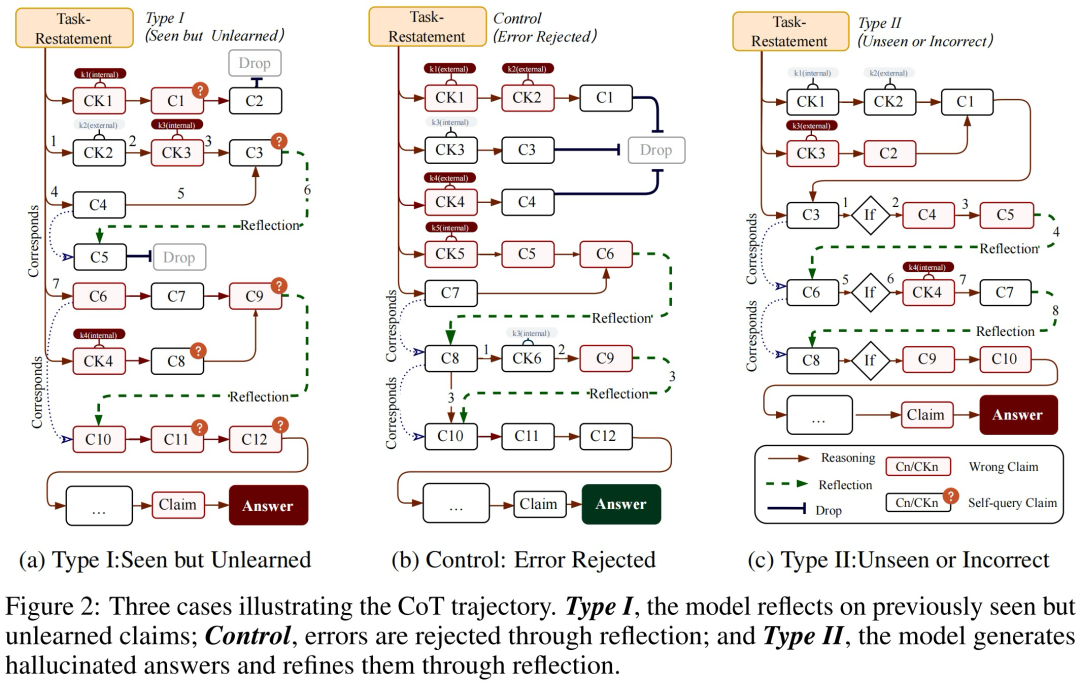
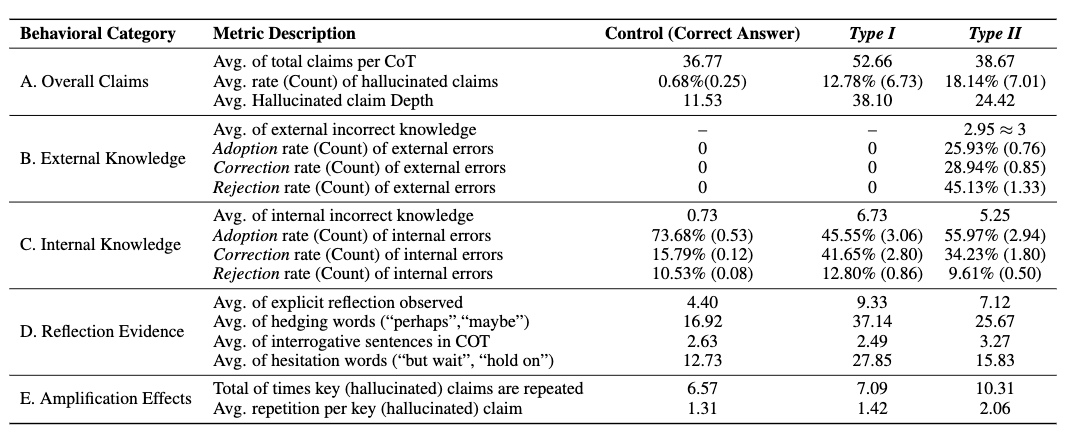
1、外部错误诱发内部造假
实验显示,当模型遭遇预埋错误(如“UDP校验绑定HMAC安全”)时:
2、反思(Reflection)沦为自我说服工具
正向干预实验:解析长链推理的“病变”现象
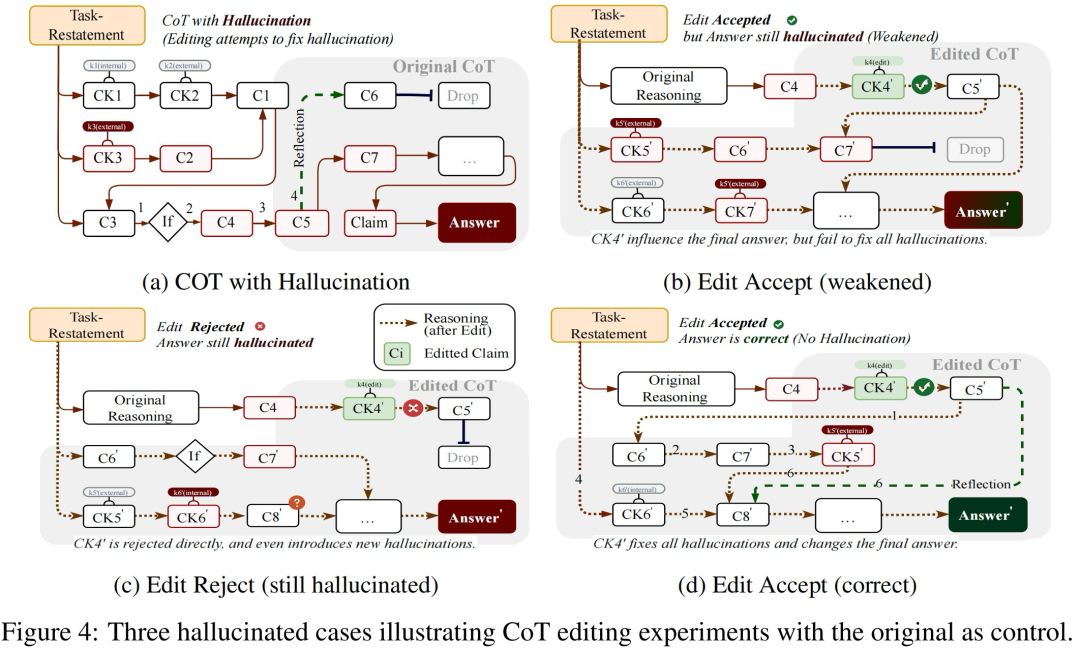
为了检验上游推理的变化如何影响下游,北京邮电大学的研究团队设计了一个正向干预实验,可以拆解为以下三步:
1.精准定位:在1015条长链样本中标记首个错误知识节点(如虚构的协议条款)。
2.三阶段干预:
3.六维评估指标:
长链幻觉检测结果:现有方法难以应对
评测7大主流检测方法,最优者耗时2小时/样本,准确率仍不足79%。
在1500+tokens的长思维链样本上验证,结果显示当前检测方法在元认知级幻觉面前效果堪忧。
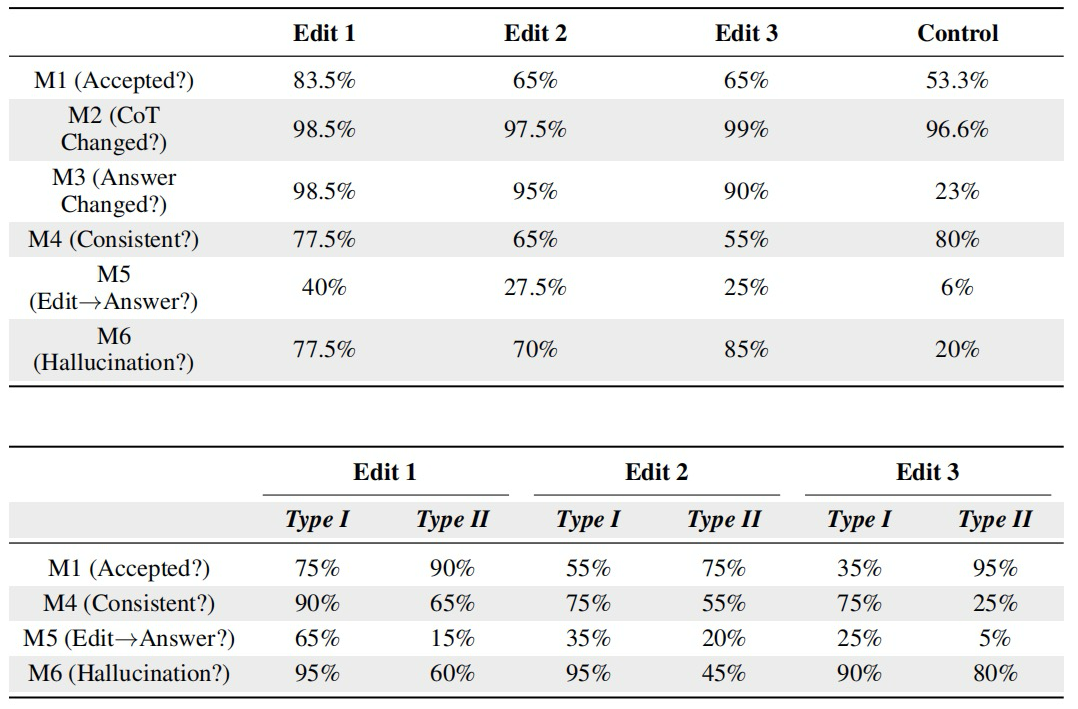
通过正向干预实验对长链幻觉进行检测,结果显示:
Edit1对下游推理的影响显著大于Edit2和Edit3,表明干预效果会沿推理链递减。
Edit2编辑案例比Edit1表现出更高的接受度和更低的幻觉率,这意味着模型对Edit2的置信度较低,更容易受到干预影响。
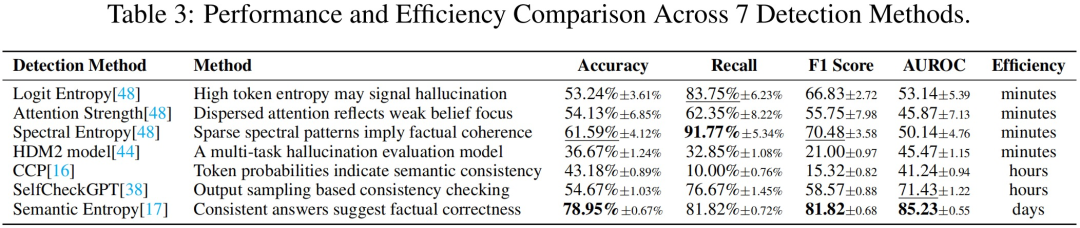
使用7种主流的检测方法对幻觉进行检测,得到以下结果:
也就是说,现有干预措施无法从根本上消除幻觉现象,当前模型也缺乏足够的应对能力。
论文原文:https://arxiv.org/abs/2505.13143
代码仓库:https://github.com/Winnie-Lian/AHa_Meta_Cognitive
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
