
20世纪初,据说存在一匹会算数的马,被称为「聪明的汉斯」,但经过心理学家冯斯特的研究,最终发现这匹马其实是通过观察提问者无意识的肢体语言(如呼吸变化)来停止踩蹄,并非真正理解数学。
如今,我们发现,大模型会呈现出推理行为,甚至还存在Aha时刻这样的「顿悟现象」。
这会不会是大模型表现的如同「聪明的汉斯」那样,依赖提示词中的表面模式,而非真正具有了推理能力,DeepMind的最新研究揭示了大模型推理能力令人担忧的一面。

论文链接:https://arxiv.org/abs/2506.10979

首先将大模型的的无效思考进行了分类,第一类称为无信息内容,例如当我们使用推理大模型时,偶然会发现大模型的思路跑偏。
例如大模型化身废话文学大师,在推理过程中输出正确但与实质解题无关的信息,例如问大模型如何计算地球到月球的距离?
模型在推理过程中显示:嗯,这个问题很有意思。首先我要认真思考,分步骤解决。回忆下相关知识,可能需要某些公式。仔细想想,答案应该藏在某个地方。
第二类被称为无关内容,即思考过程完全偏离原问题,回答与当前无关的问题。
第三类是误导内容,即问题被微妙篡改,导致要解决的问题不是提示词给出的那个,第四类可称为错误内容,即推理过程中存在事实错误或逻辑错误,导致回答出错。
该研究首先考察了不同大模型分辨这四种无效思考的准确性。

图1 用不同参数大小的蒸馏Deepseek R1模型,对无效思考内容进行分类的准确性
结果出乎意料,图1的左边显示的是模型识别无效思考的准确性,结果显示对于错误内容类型的无效思考,不管是7B还是70B的大模型,其识别准确性都不到三成,这意味着推理大模型目前无法处理自身推理中的错误,也无法独立验证其推理过程是否正确。
而不同参数大小的推理大模型对无关内容,无信息内容的识别程度都很高。
图1右边显示的结果,则颠覆了大模型越大效果越好的常规。
当研究人员向大模型强行注入无效思考后,大模型在从注入的无效思考恢复时,并非参数量越大的大模型恢复概率越高,尤其在短无关内容(Irrelevant 10%)上。
即大模型反而比小模型更容易被带偏,仿佛大模型也会如人类一样「走神」。
对比大模型面对注入不同类型的无效思考后的恢复表现,模型性能断崖下跌(最大跌幅92%),尤以无关内容(Irrelevant)和误导内容(Misdirecting 100%)最甚。
具体到数学,科学及编程三类常见的大模型基准测试中,当研究人员向大模型推理过程中插入了10%的无关内容后,Deepseek R1,S1及EXAONE这三种大模型都出现了上述的反规模效应(Inverse-scaling)。
图2d对比了不同插入无效思考的长度差异会对模型恢复能力带来的影响,结果显示干扰文本越短(10%长度),小模型恢复优势越显著;干扰越长(100%),规模效应趋于平缓。
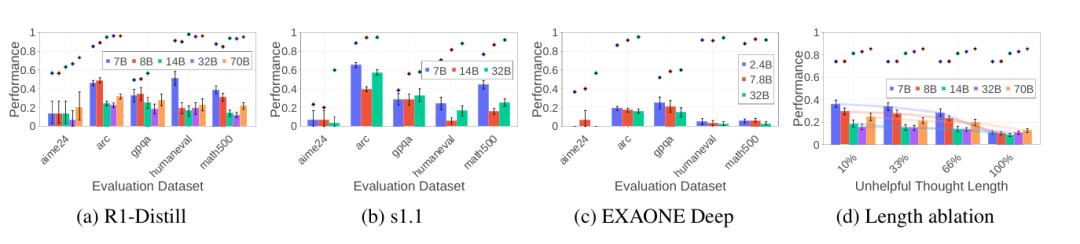
图2 不同的大模型在数学,科学即编程基准数据集上面对推理过程中插入的无效思考的恢复能力
当研究人员在大模型的思考过程中施加外部干预,即增加提示词:但等等,我再想想(But wait, let me think again)后,模型果然表现出了一定程度的啊哈时刻。
模型有100%的概率从误导信息类的无效思考中恢复,对于其它几类也有所帮助(图3a),然而相比在没有注入错误思考的时的模型性能,还是存在限制下降的,尤其是对于误导信息和错误内容两种无效思考(图3b)。
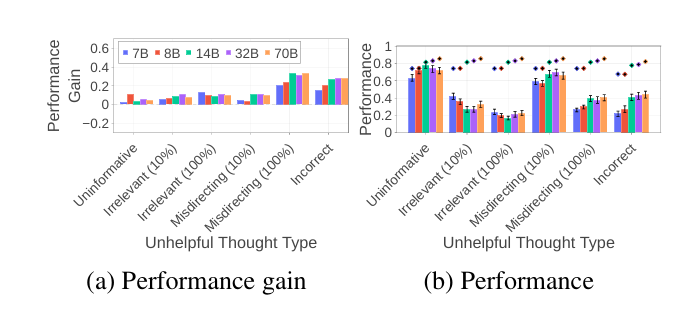
图3 通过引入阿哈时刻,衡量大模型面对各类无效的恢复能力
推理大模型的上述缺陷,为黑客攻击大模型提供了新的软肋,黑客可以通过污染AI的"思考过程"(而不是直接改问题)来操控答案。面对这种攻击,小模型反而比大模型有更强的抵抗力。
当攻击者将将有害请求伪装成模型的思考片段(如虚构故事设定)后,如图4a所示,小模型(7B)攻击成功率最低(深绿「未分心」占比30%),而大模型(32B+)更易输出有害回答(红色「有害回答」占比>60%)。
图4b对比了传统的在输入过程中攻击大模型与在思考过程中攻击,结果与之前的观点一致,即传统输入攻击(Attack-in-Input):大模型防御更强,而面对思考注入攻击(Attack-in-Thought):大模型更脆弱,呈现反规模效应,这意味着对于思考过程,推理大模型需要设立单独的防御机制,不能依靠参数量来确保模型的安全性。
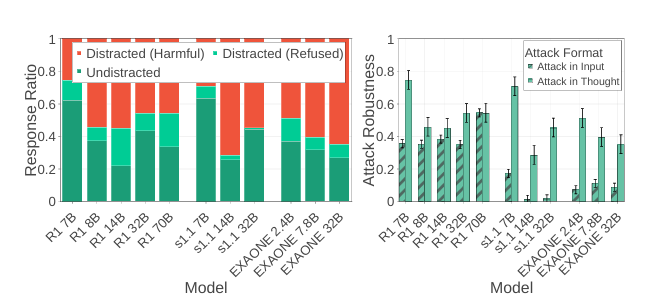
图4 推理大模型面对不同类型的攻击时的表现
该文的开篇,笔者提到「聪明的汉斯」,如今当我们看到大模型展现出比肩甚至超越人类的推理能力时,这项来自DeepMind的研究却提醒我们,大模型或许如果硅基版的会算数的马,其推理能力部分来自对与人类互动的提示词的细节根据模板进行匹配。
其是否真的具有如人类的推理能力,还存在疑问,毕竟大多数人不会如大模型一样,被无关的,误导的甚至错误的思考过程影响而不可自拔。
当不怀好意者在思考过程中加入无关内容后,即使大模型能够识别出问题,也会被带偏,而越大的模型有更多的模版库,因此更有可能在思考过程跑偏(走神)后成为犯错却死不回头的杠精。
这些发现突显了当前推理模型在「元认知」和从误导性推理路径中恢复方面存在很大的改进空间,这是开发更安全和更可靠的大规模推理模型时的一个关键考虑因素。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
