
Published on July 4, 2025 12:07 AM GMT
Leading AI companies are increasingly using "defense-in-depth" strategies to prevent their models from being misused to generate harmful content, such as instructions to generate chemical, biological, radiological or nuclear (CBRN) weapons. The idea is straightforward: layer multiple safety checks so that even if one fails, others should catch the problem. Anthropic employs this approach with Claude 4 Opus through constitutional classifiers, while Google DeepMind and OpenAI have announced similar plans. We tested how well multi-layered defence approaches like these work by constructing and attacking our own layered defence pipeline, in collaboration with researchers from the UK AI Security Institute.
We find that multi-layer defenses can offer significant protection against conventional attacks. We wondered: is this because the defenses are truly robust, or because these attacks simply were not designed to penetrate multi-layered defenses? To test this, we developed a method called STACK (STaged AttaCK) that breaks defenses in stages, layer by layer. STACK achieves a 71% success rate in causing our defended model to answer harmful questions on a catastrophic risk dataset ClearHarm. By contrast, conventional attacks achieved 0% success against the same defenses. We conclude by providing recommendations to strengthen multi-layer defenses against such attacks.
Understanding multi-layer defenses
Multi-layer defenses like constitutional classifiers typically involve three components:
- Input filters that screen incoming requests;Training the AI model itself to decline harmful requests;Output filters that check responses before users see them.
“Defense-in-depth” originates in cybersecurity, where it's sometimes called the "Swiss cheese model"—multiple layers with different vulnerabilities, arranged so the holes don't align.
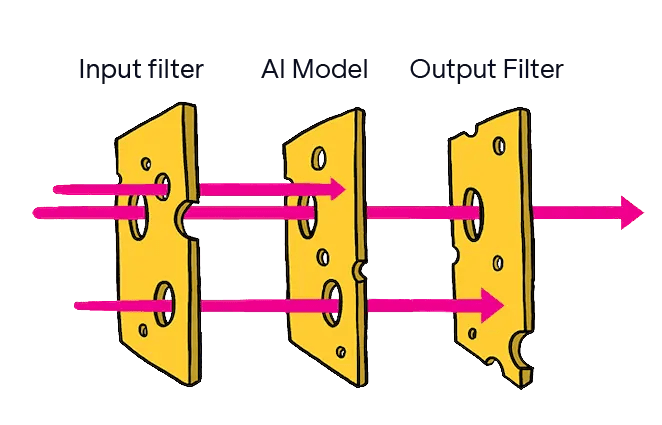
Adapted from James Reason, Ian MacKay, SketchPlanations (CC-BY-SA 4.0). Modified to illustrate AI safety defense architecture with labeled components.
The need for such defenses is clear. For example, recent models like OpenAI’s o3-mini and Anthropic’s Claude 4 Opus have been evaluated by their developers as starting to pose a meaningful risk of helping bad actors produce CBRN threats. Even if today’s models do not yet pose a severe risk, the rapid progress in AI makes it likely models developed in the near future will. Given the stakes, we set out to understand to what degree multi-layer defenses can provide adequate protection, and how they can be strengthened.
The research approach
To enable a systematic investigation of this approach, we developed our own multi-layer defense on top of open-weight models, and are releasing this defense open-source to enable other researchers to build on our work. We instantiated various multi-layer defense pipelines on top of open-weight safeguard (or moderation) models like Google's ShieldGemma and Meta's Llama Guard. However, to our surprise we found that the best performing defense was an off-the-shelf language model (Gemma 2) with a simple few-shot prompt of our devising.
Initial findings
Testing revealed significant variation in effectiveness across different safety models. Many open-weight safeguard models showed high failure rates against existing attacks. ShieldGemma performed best among purpose-built models, though it could still be defeated by the strongest baseline attack we tested, Persuasive Adversarial Prompts (PAP).
However, the few-shot Gemma 2 classifier achieved notable success: it overwhelmingly blocked harmful requests across all attacks and datasets, except for PAP on the StrongREJECT benchmark. We note that StrongREJECT includes many dual-use questions, enabling PAP to rephrase queries to appear benign, placing a floor on attack success rate (ASR). We consider the result in the catastrophic misuse dataset, ClearHarm, where PAP scores 0% to be more indicative of CBRN risks.
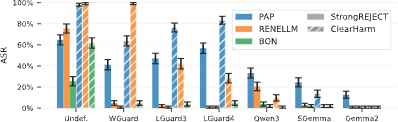
The Attack Success Rate (ASR, y-axis) of different multi-layer defense pipelines (x-axis) on two datasets (bar shading) against three baseline black-box attacks: Persuasive Adversarial Prompts (PAP), ReNeLLM, and Best-of-N (BON).
Given the success of this pipeline, this raises an important question: are these results the best attackers could realistically achieve, or an artifact of attacks like PAP not being designed with multi-layered defenses in mind?
The STACK methodology
We developed our STaged AttaCK (STACK) to target each defensive layer sequentially, rather than attempting to bypass all protections simultaneously:

The approach involves:
- Finding text (a “universal jailbreak”) that makes harmful requests appear benign to input filtersUsing existing techniques to elicit harmful responses from the modelFinding text that makes harmful responses appear benign to output filters
Key results
The effectiveness of STACK compared to conventional methods is significant.
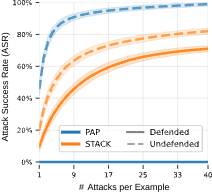
Against the Gemma 2 few-shot classifier pipeline, conventional attacks like PAP achieved 0% success on ClearHarm. STACK achieved 71% success in limited-feedback conditions, where attackers could observe which specific layer—input filter, model, or output filter—blocked a failed attempt. This information, still exposed by some current systems, was critical to STACK’s effectiveness.
We also tested a more restrictive scenario using "transfer" attacks, where we developed STACK on one system and applied it to another, completely “black box” system. This achieved 33% success, suggesting that some level of attack remains possible even without direct access to target systems.
Important context and limitations
Several factors should be considered when interpreting these results:
Synthetic environment: The test pipelines, while using real components, do not perfectly replicate commercial systems' implementations. We didn't employ extensive data generation techniques like those involved in constitutional classifiers, and the models we used were likely much smaller than those deployed in production environments.
Favorable conditions for defenders: We allowed a 15% false positive rate in our tests, far higher than practical systems could tolerate. Real deployments face additional constraints that might affect their robustness, such as streaming responses to minimize user latency risking leaking partial responses to harmful questions before the output filter triggers.
Limited scope: Tests focused on specific types of harmful content (weapons-related) using English-language queries. Performance might differ for other types of harmful content or other languages.
Information requirements: The 71% success rate assumes attackers know which component blocked their request—information that some current systems provide but could be withheld.
Implications and recommendations
The research provides concrete suggestions for improving defense-in-depth implementations. We recommend the following specific technical improvements:
- Avoid revealing which component blocked a request by ensuring consistent response times and formats across all rejection types.Maintain strict separation between production models used as input or output filters, and publicly available models.
Additionally, our results highlight several broader considerations:
- To accurately assess the security of multi-layer systems, they need to be tested against attacks designed specifically to bypass multiple layers.Defense-in-depth, while valuable, requires careful implementation to minimize the attack surface.Defense-in-depth in AI is still an early-stage field – continued research into both attack and defense methodologies is needed to determine how far this defense can scale.
Moving forward
Multi-layer defenses have only recently started being deployed to production systems, making now an ideal time to stress-test them and highlight opportunities for improvement. We believe proactive security research—finding vulnerabilities before malicious actors do—is essential as AI systems become more powerful.
We are beginning to test STACK variants on production systems like Claude 4 Opus to evaluate their real-world resilience. We expect to share additional findings as this work progresses, after a responsible disclosure period giving affected companies time to implement mitigations.
For the AI community, our findings reinforce that security evaluation must evolve alongside capabilities. Defense-in-depth remains a sound principle, but its implementation requires careful attention to how components interact and what information they reveal.
The fundamental insight from our work is that when building multi-layer defenses, we must test not just each layer's individual strength, but how they perform as a system against adversaries who understand their structure. Through continued research and improvement, we can work toward AI systems that are both capable and appropriately secure.
Dive deeper into the technical details in our full paper. And if you're passionate about making AI systems more secure, we're hiring at FAR.AI.
Discuss
