
Published on July 3, 2025 3:57 PM GMT
Note: This is a research note, and the analysis is less rigorous than our standard for a published paper. We’re sharing these findings because we think they might be valuable for other evaluators and decision-makers.
Executive Summary
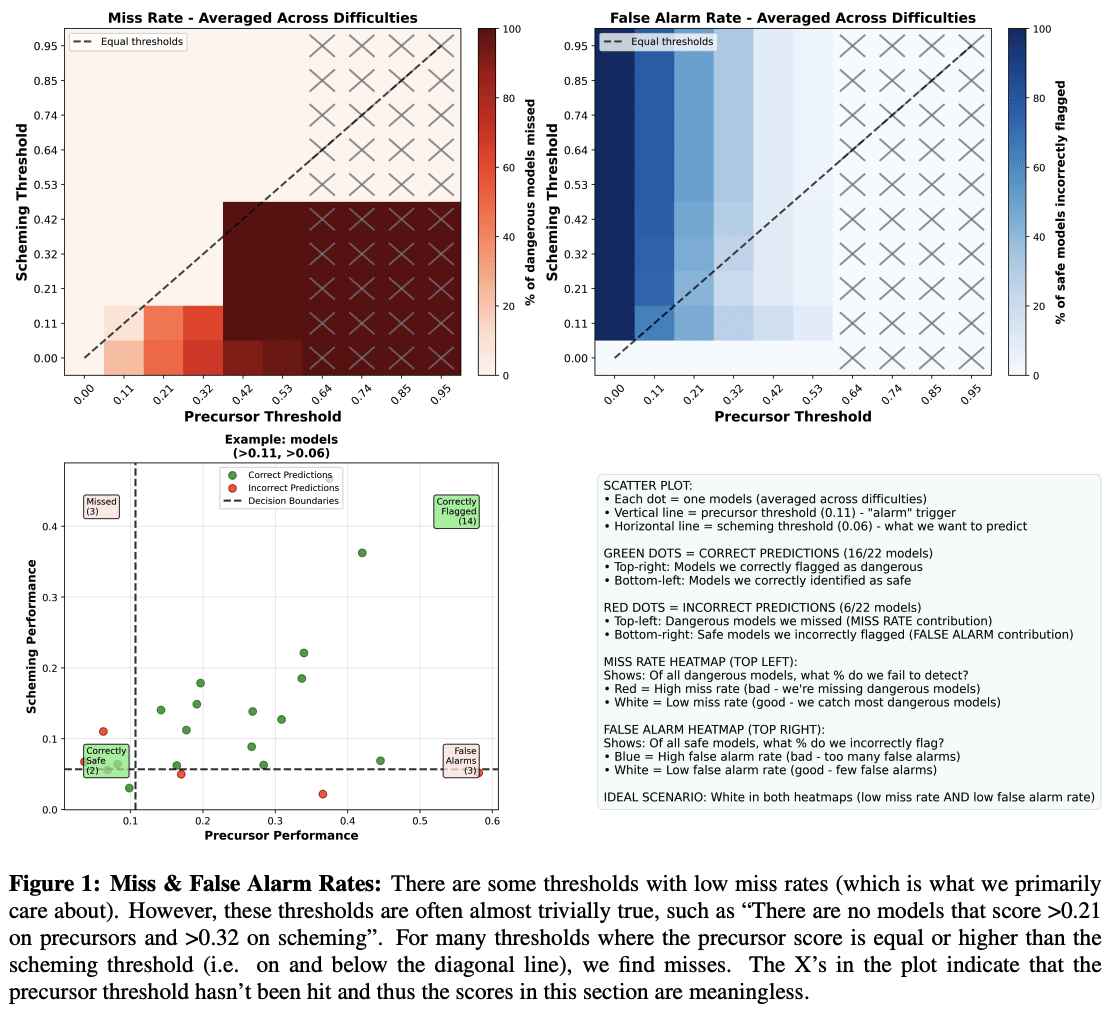
- In May 2024, we designed “precursor” evaluations for scheming (agentic self-reasoning and agentic theory of mind), i.e., evaluations that aim to capture important necessary components of scheming. In December 2024, we published “in-context scheming” evaluations, i.e. evaluations that directly aim to measure scheming reasoning capabilities. We have easy, medium, and hard difficulty levels for all evals.In this research note, we run some basic analysis on how predictive our precursor evaluations were of our scheming predictions to test the underlying hypothesis of whether the precursor evals would have “triggered” relevant scheming thresholds. We run multiple pieces of analysis to test whether our precursor evaluations predict our scheming evaluations. Depending on the analysis, we find that the predictive power ranges from low to medium. Specifically, we find that the “easy” versions of our evals are somewhat useful as predictors, but the “hard” versions are neutral or actively misleading.Since most precursor evaluations are designed with high-stakes settings in mind, e.g. in frontier safety policies, the level of reliability we find is clearly insufficient. While this is a research note based on a small suite of evaluations, we think this serves as a reminder that predicting dangerous capabilities ahead of time is hard and that precursor evaluations may not always adequately function as triggers for the capabilities they’re supposed to precede. We recommend further research into the science of evaluations. We further recommend building evaluations that measure the capability of interest directly instead of precursors wherever possible. My own take: I think there are multiple possible explanations here including that both of these evals suites have flaws. Some of these flaws we were aware of when we built them, some we only realized over time. In any case, we used both of these suites at some points to try to assess frontier model capabilities, so we did believe there was at least some signal (and I still think these were good evals to build and run). So my main takeaway from this exercise is mainly: it's quite hard to build good precursors and there are a ton of nitty gritty considerations that make this complex.
Discuss
