

ICCV (The International Conference on Computer Vision ) 是计算机视觉领域的国际学术会议之一,也是中国计算机学会评定的A类会议。ICCV每两年举办一次。ICCV 2025将于2025年10月19日-23日在美国夏威夷会议中心举行。
PKU-DAIR实验室《Training-free and Adaptive Sparse Attention for Efficient Long Video Generation》论文被ICCV 2025录用。
Training-free and Adaptive Sparse Attention for Efficient Long Video Generation
作者:Yifei Xia, Suhan Ling, Fangcheng Fu, Yujie Wang, Huixia Li, Xuefeng Xiao, Bin CUI
论文链接:https://arxiv.org/abs/2502.21079
1
背景与挑战
在视频生成领域,Diffusion Transformers(DiTs)已经成为一种先进的生成模型框架,在多模态生成任务中取得显著的效果。然而,尽管DiTs在生成高质量视频方面表现出色,但生成长视频时仍面临着巨大的计算挑战,特别是在模型的Attention计算方面。比如,用HunyuanVideo生成一个8s 720p的视频需要大概1h的时间,其中Attention计算占80%。如图1所示,Attention的占比会随着视频长度的增加而不断增加,成为主要的瓶颈。
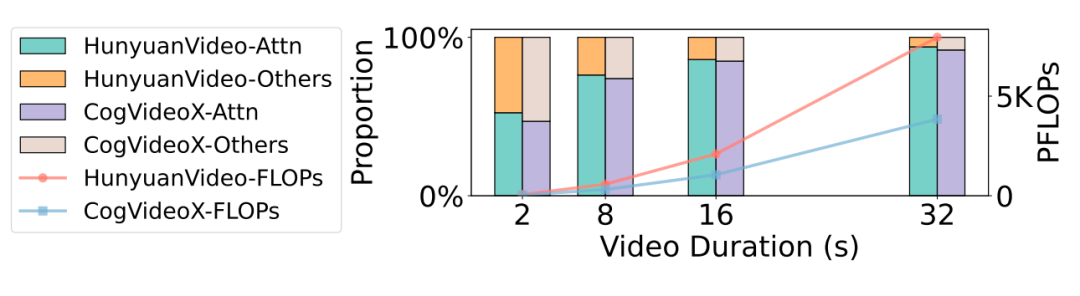
图1. 不同视频时长所需的总FLOPs和Attention占用FLOPs的比例
虽然很多稀疏注意力 (Sparse Attention) 方法已被提出以减轻Attention计算,但这些方法普遍面临一个问题:DiTs中的稀疏范式 (Sparse Pattern) 具有高度的动态性和不规则性,现有的静态模式和离线搜索方法无法有效适应这些变化,而现有的动态稀疏范式虽然能够适应变化,但他们大多依赖近似搜索方法,精度和效率很低,不能实时精准地识别稀疏范式,进而影响视频生成的速度和质量。
2
方 法
上面分析得出,现有的稀疏注意力在DiT长视频生成的计算中无法兼顾精度和效率。为此,我们在本论文中提出了AdaSpa,首个「在线精确搜索+动态范式」的稀疏注意力方法,能在高效加速长视频生成的同时,保持极高的精度。
我们首先详细分析了DiT视频生成中稀疏范式的特点:1) DiT适用于用块状稀疏注意力来建模,2) DiT稀疏范式随着去噪步数不变,3) DiT稀疏范式随着Head变化较大。利用以上特点,我们构建了AdaSpa,它是一种结合「动态块化范式 + 在线精确搜索 + 头自适应」的新型稀疏注意力机制。利用DiT去噪步数之间的相似性,在某些步骤进行精确的在线稀疏范式搜索,在后续步骤中复用这些范式,以此来减少搜索开销和增加搜索精度,达到精度和效率的双重提升。
其架构图如图2所示:
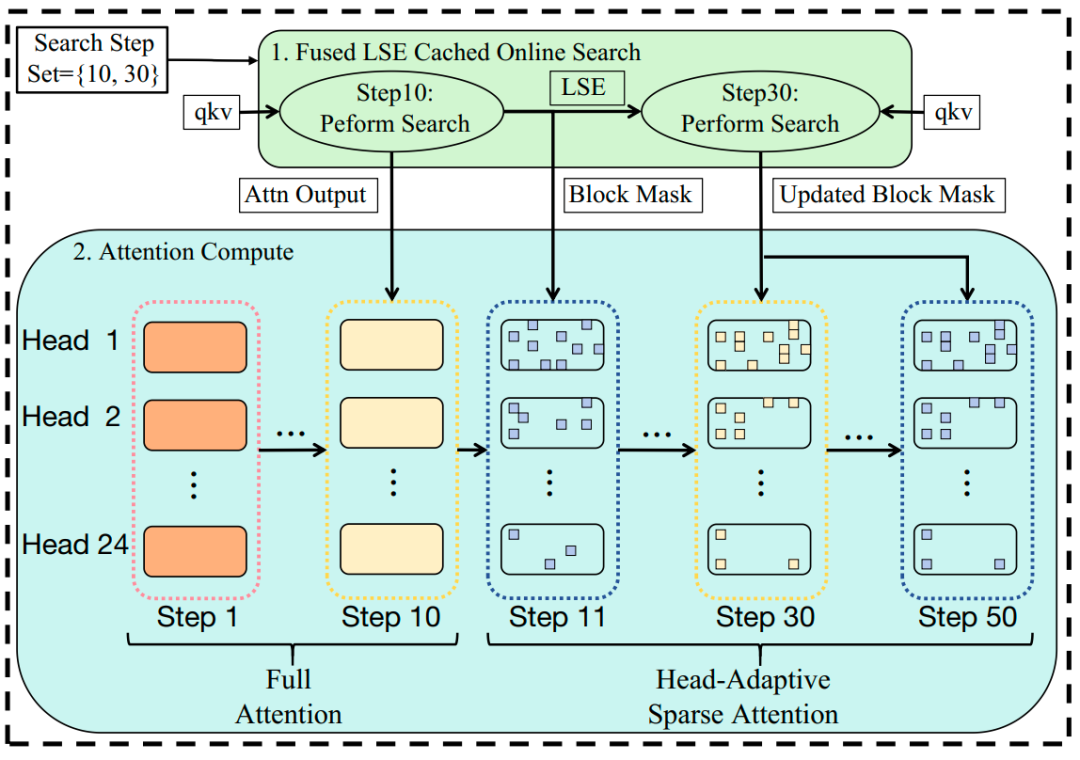
图2. AdaSpa架构图
具体来说,AdaSpa在预定义的搜索步骤 (Search Step Set) 利用自实现的高效的Fused LSE-Cached Online Search kernel进行精确搜索,在其他步骤复用这些精确范式进行稀疏注意力计算。 Fused LSE-Cached Online Search kernel将搜索与FlashAttention2耦合,在搜索步同时计算注意力输出并缓存 LSE,后续搜索复用缓存,进一步减少搜索时间。其次,根据不同Head的稀疏度不同,我们引入 Head-Adaptive Block Sparse Attention,根据各Head召回率动态调整稀疏度以以提高精度并保证kernel的负载均衡。
3
实 验
表1. AdaSpa和其他方法的质量和延迟的定量评估结果
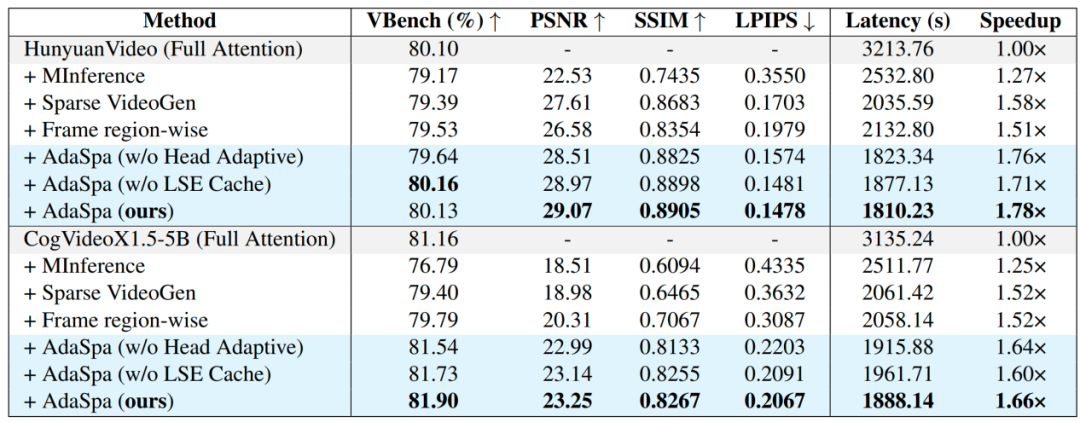
为了验证我们方法的有效性,我们与LLM中最先进的的稀疏注意力方法MInference和DiT中最先进的的稀疏注意力方法Sparse VideoGen做了对比,实验表明我们的方法在速度和效率上均超过了之前的方法。
4
总 结
在本论文中,我们对DiTs生成视频注意力机制中的稀疏特性进行全面分析。基于这些观察和分析,我们提出了一种全新的稀疏注意力AdaSpa方法,该方法具备动态模式与在线精确搜索的能力,能够加速长视频的生成。实验结果表明,AdaSpa在保持生成视频高质量的同时,实现1.78倍的效率提升。
欢迎关注本公众号,帮助您更好地了解北京大学数据与智能实验室(PKU-DAIR),第一时间了解PKU-DAIR实验室的最新成果!
北京大学数据与智能实验室(Data And Intelligence Research Lab at Peking Univeristy,PKU-DAIR实验室)由北京大学计算机学院崔斌教授领导,长期从事数据库系统、大数据管理与分析、人工智能等领域的前沿研究,在理论和技术创新以及系统研发上取得多项成果,已在国际顶级学术会议和期刊发表学术论文200余篇,发布多个开源项目。课题组同学曾数十次获得包括CCF优博、ACM中国优博、北大优博、微软学者、苹果奖学金、谷歌奖学金等荣誉。PKU-DAIR实验室持续与工业界展开卓有成效的合作,与腾讯、阿里巴巴、苹果、微软、百度、快手、中兴通讯等多家知名企业开展项目合作和前沿探索,解决实际问题,进行科研成果的转化落地。
内容中包含的图片若涉及版权问题,请及时与我们联系删除
