
Published on July 1, 2025 4:52 AM GMT
This sequence draws from a position paper co-written with Simon Pepin Lehalleur, Jesse Hoogland, Matthew Farrugia-Roberts, Susan Wei, Alexander Gietelink Oldenziel, Stan van Wingerden, George Wang, Zach Furman, Liam Carroll, Daniel Murfet. Thank you to Stan, Dan, and Simon for providing feedback on this post.
Alignment Capabilities. As of 2025, there is essentially no difference between the methods we use to align models and the methods we use to make models more capable. Everything is based on deep learning, and the main distinguishing factor is the choice of training data. So, the question is: what is the right data?

Alignment is data engineering. Alignment training data specifies our values indirectly in the form of example demonstrations (instruction/safety fine-tuning), binary preferences (RLHF, DPO), or a constitution of abstract principles (constitutional AI, deliberative alignment). We train models against those underdetermined specifications and hope they internalize our intended constraints.
Alignment may require fundamental scientific progress. As we've seen with recent examples of sycophancy and reward-hacking, our current indirect and empirical approach to alignment might not be enough to align increasingly powerful systems. These symptoms appear to stem from deeper scientific problems with deep learning:
- The Problem of Generalization: Distribution shifts can break learning-based constraints, so two models that behave similarly with respect to the training specification may generalize very differently in deployment. In particular, behaviors associated with general-purpose capabilities may generalize more robustly than alignment properties (the "sharp left turn").The Problem of Learning: Even on a fixed distribution, the training process may learn an unintended solution. Our learning processes are noisy, heterogeneous, and not guaranteed to converge to an optimal solution for a given set of constraints. As a result, models may learn a dangerous simplification of our specifications, acquire unintended instrumental strategies (deception, incorrigibility, power-seeking, sandbagging, etc.), or suddenly change in ways that are hard to predict (and execute a "treacherous turn").
Past a certain level of capabilities, making further safety progress may require making scientific progress on some of these more fundamental questions. It is hard to align what you do not understand, and we still do not understand deep learning.
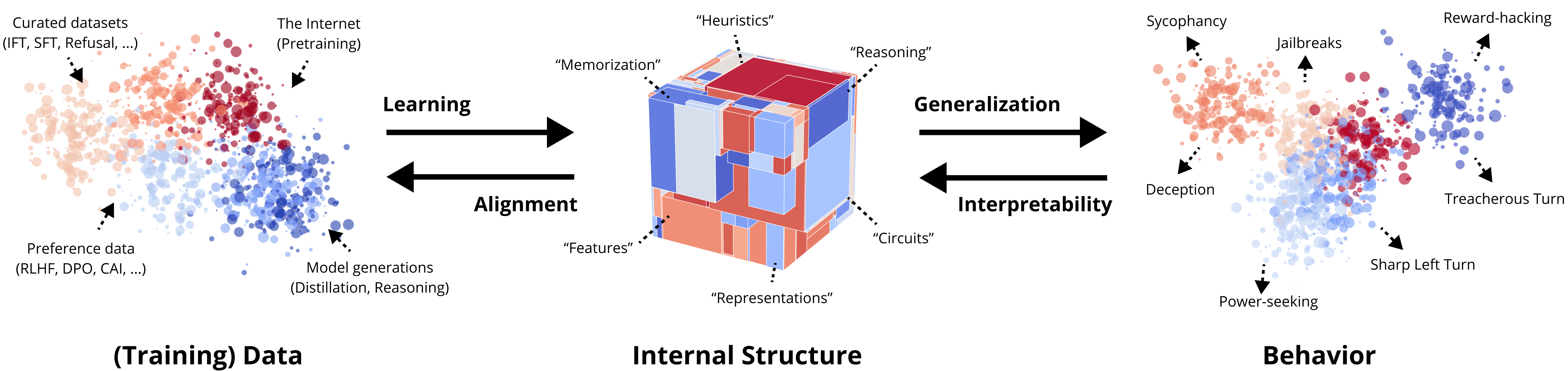
1a. (Learning) How does training data determine the algorithms that models learn?
1b. (Alignment) How can we choose training data to control what algorithms models learn?
2a. (Generalization) How do learned algorithms generalize (under distribution shift)?
2b. (Interpretability) How do a model internals enable (mis)generalization?
Singular learning theory for a science of alignment. Singular Learning Theory (SLT) is a theory of Bayesian statistics that suggests the key to understanding deep learning is the geometry (specifically, the degeneracies) of the loss function and parameter-function map. SLT provides a starting point for understanding how learned algorithms underlie generalization and how training data determines those learned algorithms:
- Interpretability: The loss landscape around a given set of weights reflects the algorithms encoded by that set of weights and the sensitivity of those algorithms to changes in the data distribution [1, 4, 6]. If we can develop (a) the empirical tools to read this geometry and (b) the theoretical understanding to "invert" this reflection (a hypothesis we call "Structural Bayesianism" [6]), then we gain a principled framework for interpreting learned algorithms and linking this structure to generalization.Alignment: The algorithms a model learns are ultimately rooted in the model's training data: (a) Statistical structure in training data determines (b) the geometric structure in the loss landscape, which determines (c) the developmental structure in the learning process, which determines (d) the algorithmic structure in the final weights a model has learned. If we can (partially) "invert" this mapping (a hypothesis we call the "S4 correspondence", for four different kinds of "structure" [3, 8]), then we can transform constraints on learned algorithms into interventions on training data. This provides a framework for aligning models through careful control of the training environment.
We expect that SLT is currently the best bet for developing a more complete science of deep learning and alignment. If successful, this would enable not just a better understanding of the theoretical problems of generalization and learning, but also the development of a new set of principled tools for "reading" and "writing" model internals.
This progress would not be enough to guarantee safety on its own and would increase the risk burden on other areas in safety. However, fundamental progress may be necessary if we aren't on track to solve (inner) alignment by default.

Outline. The rest of this sequence will survey recent progress in SLT [1, 2, 3, 4, 5, 6, 7, 8] and explore the potential applications for interpretability, alignment, and other areas of safety discussed above:
- SLT for Interpretability (upcoming)SLT for Alignment (upcoming)SLT for Present-Day Safety (upcoming)
For more on the relevance of SLT to safety, see our position paper (co-written with a larger group of authors). For more on the technical fundamentals of SLT, see Distilling Singular Learning Theory by Liam Carroll.
Discuss
