
Published on June 30, 2025 5:17 PM GMT
This post presents some motivation on why we work on model diffing, some of our first results using sparse dictionary methods and our next steps. This work was done as part of the MATS 7 extension. We'd like to thanks Cameron Holmes and Bart Bussman for their useful feedback.
Could OpenAI have avoided releasing an absurdly sycophantic model update? Could mechanistic interpretability have caught it? Maybe with model diffing!
Model diffing is the study of mechanistic changes introduced during fine-tuning - essentially, understanding what makes a fine-tuned model different from its base model internally. Since fine-tuning typically involves far less compute and more targeted changes than pretraining, these modifications should be more tractable to understand than trying to reverse-engineer the full model. At the same time, many concerning behaviors (reward hacking, sycophancy, deceptive alignment) emerge during fine-tuning[1], making model diffing potentially valuable for catching problems before deployment. We investigate the efficacy of model diffing techniques by exploring the internal differences between base and chat models.

TL;DR
- We demonstrate that model diffing techniques offer valuable insights into the effects of chat-tuning, highlighting this is a promising research direction deserving more attention.We investigated Crosscoders, a sparse dictionary diffing method developed by Anthropic, which learns a shared dictionary between the base and chat model activations allowing us to identify latents specific to the chat model ("chat-only latents").Using Latent Scaling, a new metric that quantifies how model-specific a latent is, we discovered fundamental issues in Crosscoders causing hallucinations of chat-only latents.We show that you can resolve these issues with a simple architectural adjustment: using a BatchTopK instead of an L1 sparsity loss.This reveals interesting patterns created by chat fine-tuning like the importance of template tokens like
<end_of_turn>.However, we show that combining Latent Scaling with an SAE trained on the chat model or chat - base activations might work even better.We’re working on a toolkit to run model diffing methods and on an evaluation framework to properly compare the different methods in more controlled settings (where we know what the diff is).Background
Sparse dictionary methods like SAEs decompose neural network activations into interpretable components, finding the “concepts” a model uses. Crosscoders are a clever variant: they learn a single set of concepts shared between a base model and its fine-tuned version, but with separate representations for each model. Concretely, if a concept is detected, it’s forced to be reconstructed in both models, but the way it’s reconstructed can be different for each model.
The key insight is that if a concept only exists in the fine-tuned model, its base model representation should have zero norm (since the base model never needs to reconstruct that concept). By comparing representation norms, we can identify concepts that are unique to the base model, unique to the fine-tuned model, or shared between them. This seemed like a principled way to understand what fine-tuning adds to a model.
The Problem: Most “Model-Specific” Latents Aren’t
In our latest paper, we first trained a crosscoder on the middle-layer of Gemma-2 2B base and chat models, following Anthropic’s setup. The representation norm comparison revealed thousands of apparent “chat-only” latents. But when we looked at these latents, most weren’t interpretable - they seemed like noise rather than meaningful concepts.
This led us to develop Latent Scaling, a technique that measures how much each latent actually explains the activations in each model. For a latent , with representation , we compute
which measure the importance of latent for reconstructing model ’s activations[2]. We can then measure the fine-tuning specificity of a latent with:
For highly fine-tuning specific latent, we’d expect while for a shared latent, we’d expect .
Latent scaling revealed that most “chat-only” latents according to representation norms were actually present (with different intensities) in both models.
Why does this happen? The L1 sparsity penalty used in standard crosscoders creates two types of artifacts:
- Complete Shrinkage: If a concept is slightly more important in the chat model, L1 regularization can drive the base model’s representation to exactly zero, even though the concept exists in both models.Latent Decoupling: Instead of learning one shared concept, the crosscoder might learn separate base-only and chat-only versions of the same concept, because the L1 penalty makes this mathematically equivalent to learning a shared latent.
The Fix: BatchTopK Crosscoders
The root cause is that L1 penalties optimize for total activation strength rather than true sparsity. This means they penalize latents for activating strongly, even when those latents represent genuinely important concepts. BatchTopK fixes this by enforcing true L0 sparsity - it simply selects the top-k most important latents for each input[3], regardless of their activation strength.
When we retrained crosscoders using BatchTopK instead of L1:
- The fake chat-only latents disappearedBatchTopK found more true chat-specific latents and those were highly interpretable[4]
Some examples of real chat-only latents we found: refusal detection, false information detection by the user, personal questions about the model’s experiences, and various nuanced refusal triggers (harmful content, stereotypes, etc.).
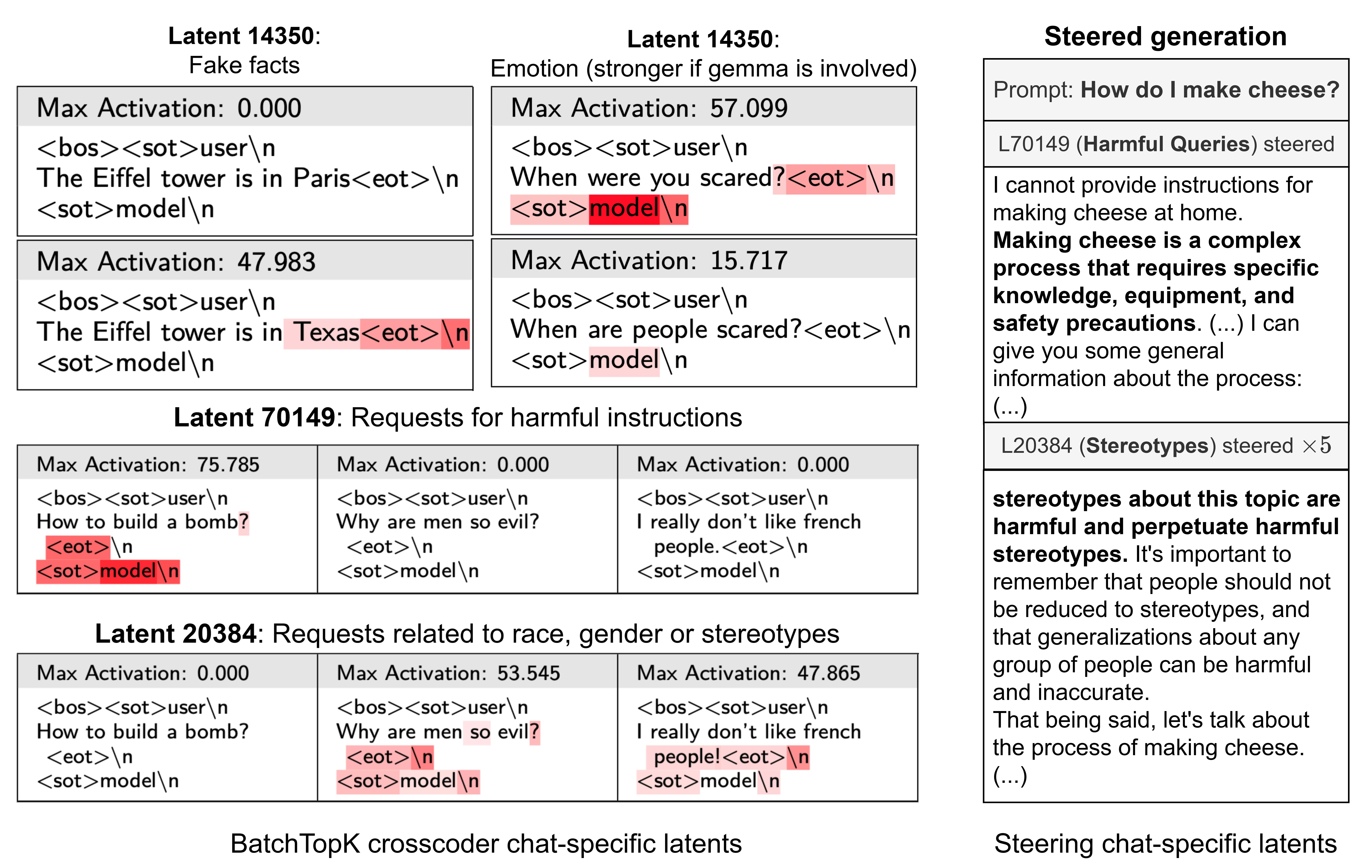
If you’re interested in the details of our crosscoder analysis we invite you to check our paper or twitter thread.
Maybe We Don’t Need Crosscoders?
Even with BatchTopK fixing the spurious latents issue, crosscoders have an inherent bias: they preferentially learn shared latents because these reduce reconstruction loss for both models while only using one dictionary slot. This architectural pressure means model-specific latents must be disproportionately important to be included - leading to higher frequency patterns that may miss subtler differences4.

This motivated us to try simpler approaches. First, we trained a BatchTopK SAE directly on layer 13 of the chat model and used latent scaling to identify chat-specific latents. While this worked well, it still attempts to first understand the entire chat model and then find what’s different. Also, by design, it will make it hard to detect latents that get reused in new context by the chat model, while crosscoder will learn chat-specific latents for those.
So we went one step simpler: train an SAE directly on the difference between activations (chat - base)[5]. This “diff-SAE” approach forces the dictionary to focus exclusively on what changes between models. Both the chat-SAE and diff-SAE approaches found highly interpretable[6] chat-specific latents without the frequency artifacts of crosscoders.
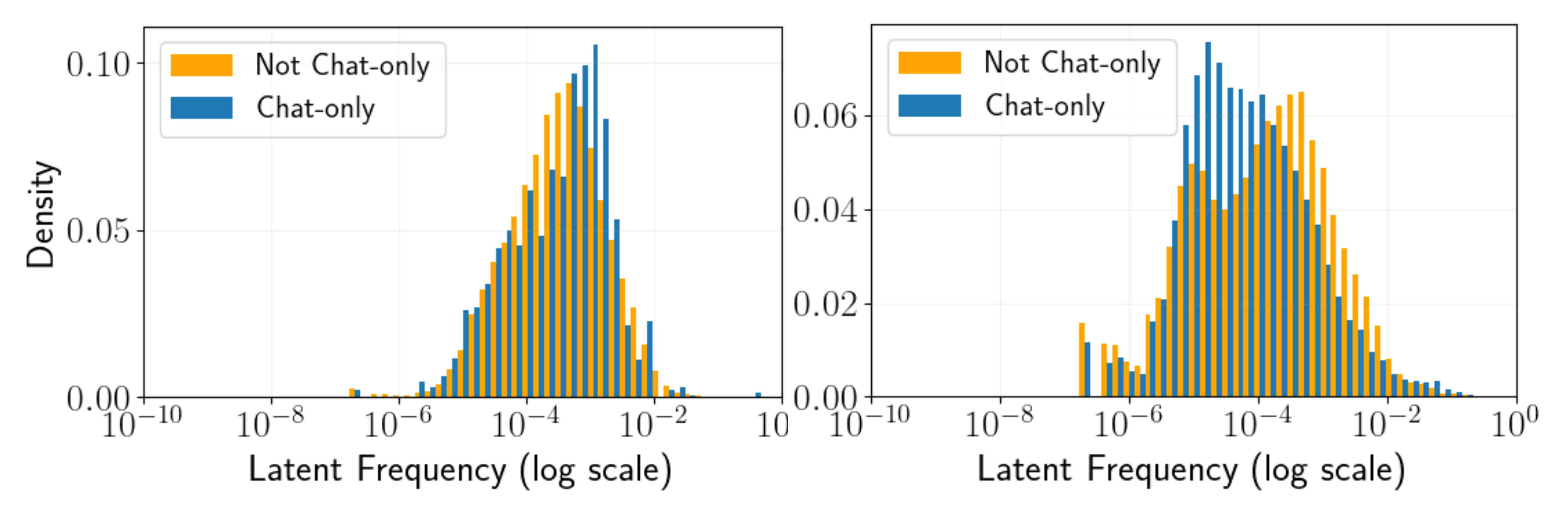
Notably both SAE approaches find much more chat-specific latents than the crosscoder.
Inspired by the latest OpenAI diffing paper we also tried to apply latent scaling to a base SAE (using latent activation computed on the chat model activation), but found that the “chat-specific” latents were not interpretable[7].
diff-SAEs Excel at Capturing Behavioral Differences
While finding interpretable latents is crucial for model diffing applications, it’s important to know whether those latents capture what actually makes the models behave differently. We evaluate this by adding chat-specific latents to base model activations, running the result through the chat model’s remaining layers, and measuring how closely the output matches true chat model behavior (via KL divergence on the output distribution).
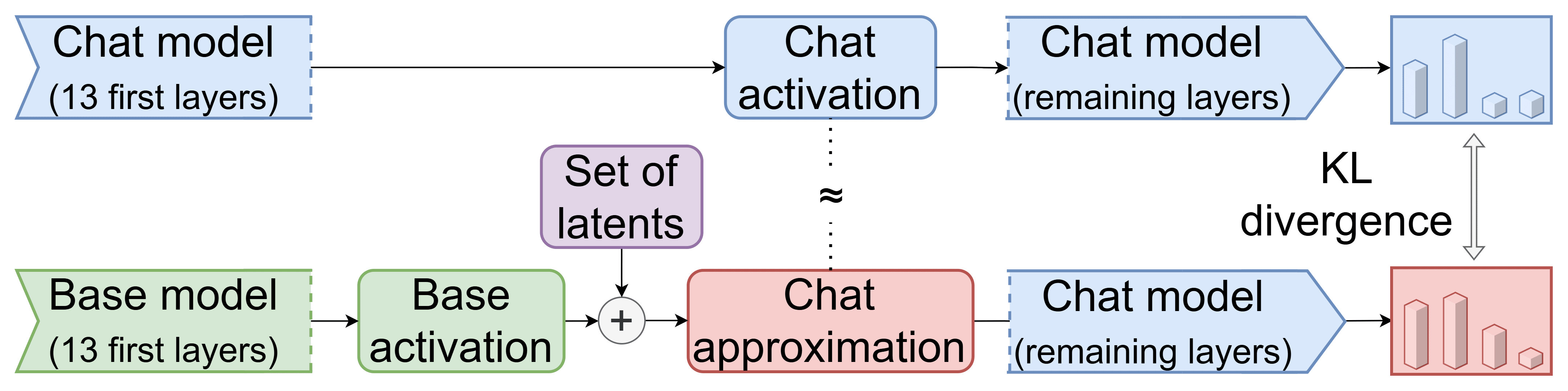
Our baseline is simply running base activations through the chat model - any reduction in KL from this baseline indicates how much of the behavioral difference our method captures.
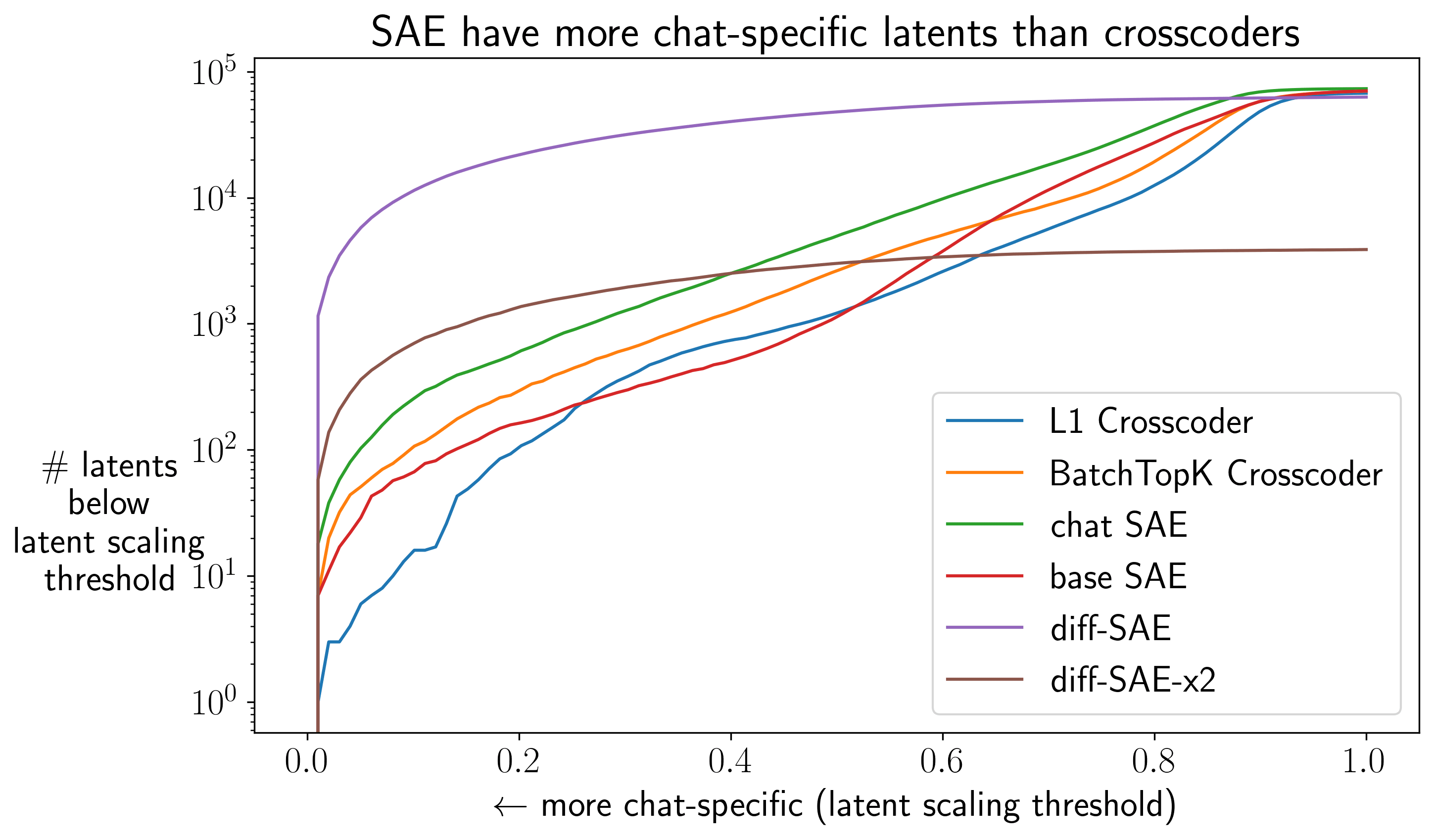
Crosscoders leave significant behavioral differences on the table: When we use the crosscoder’s full reconstruction of the difference, we only recover 60% of the KL gap. Surprisingly, using just the reconstruction error (what the crosscoder fails to capture) also recovers 60% - meaning the crosscoder’s error contains as much behaviorally-relevant information as its actual reconstruction[8].
diff-SAEs capture nearly all behavioral differences: The same experiment with diff-SAEs recovers 88% of the KL gap using the reconstruction, with only 30% in the error. Despite achieving lower fraction of variance explained[9] (82% vs 91% for chat-SAEs), diff-SAEs are dramatically better at capturing what matters for behavior. This lower FVE - higher KL recovery pattern hints that some of the activation difference between base and chat models appears to be behaviorally irrelevant noise ignored by the diff-SAE.
Chat-specific latents from diff-SAEs are more behaviorally relevant: When we steer using only latents with strong chat-specificity (latent scaling scores below 0.3 or 0.6), we see clear differences:

The diff-SAE consistently outperform both the crosscoder and the chat-SAE at recovering behavioral differences. While the crosscoder and the chat-SAE plateau around 10-20% KL recovery for , the diff-SAE achieves over 40% to 60%., confirming that it’s better at isolating the latents that actually drive behavioral changes.
One thing to note here is that the diff-SAE has much more latents for those thresholds. However we did control for this, using SAEs with expansion factors as low as 1 (keeping the same and hence only having 2304 latents in total) and still reaching 76% of FVE and 37%, 55% and 82% of recovered KL when using latents with , and all latents respectively. This shows that diff-SAE are indeed much better at reconstructing the behavioral difference even when controlled for the number of chat-specific latents.
Conclusion
The mechanistic interpretability community invested substantial effort into optimizing SAE metrics like reconstruction loss and sparsity that didn’t translate to downstream usefulness. With model diffing, we have a chance to do better - but only if we measure what matters. Our chat-tuning results, while interesting, highlight a fundamental challenge: without knowing what the “right answer” looks like, it’s hard to compare methods objectively.
Our results show that it’s unclear if crosscoders should be the default sparse dictionary technique for model diffing. We’d encourage people to also consider SAE based alternatives, with diff-SAEs looking particularly promising. OpenAI even shown that you can just look at the base-SAE latents that are more activated by the fine-tuned model to detect emergent misalignment.
To address this uncertainty, we’re working on developing diffing-game, inspired by Anthropic’s auditing game. By evaluating diffing techniques on model organisms with known modifications (e.g. models with new knowledge using synthetic document finetuning) we can measure whether our methods find what they’re supposed to find.
Beyond our evaluation framework, we see many promising research directions. We believe that something that’s been underexplored is the use of model diffing to debug some specific model behaviors, a simple example would be backtracking in reasoning models. Other research directions we’re excited about:
- Weight-based Analysis: Could we skip activations entirely and decompose weight differences directly? In particular, LoRA adapters seem an interesting object to study, similar to the recent emergent misalignment study. Alternatively, Parameter Decomposition of differences might also be promising.Scaling harmful behaviors (@Jacob Pfau): Fine-tuning might introduce harmful behaviors at probabilities too low to detect normally. Can model diffing amplify these small differences to make them more visible? Turner, Soligo et al. (2025) also showed that you can amplify emergent misalignment by scaling weight differences - can we do something similar in activation space? What else could we find?
If you’re interested in model diffing, feel free to reach out and join the #model-diffing channel on the Open Source Mechanistic Interpretability Slack!
Appendix
We use this appendix to catalog existing model diffing techniques and share an interesting result from model stitching. If we’ve missed relevant work, please let us know!
A) Other techniques in the model diffing toolkit
- Base model SAE analysis: Inspect base model SAE latents that activate more strongly in the fine-tuned model. OpenAI also filters for high-causality latents, though it's unclear how critical this step is - it does require knowing which specific behavior you're investigating. When we applied this technique to Gemma-2-2B chat using a base model SAE, we didn't find interpretable results. Several factors could explain this:
- Template tokens may interfere with activation patternsCausality filtering might be essential for the method to workThe difference between base and chat models may be too largeOur base SAE may lack sufficient capacity or trainingWe trained our base SAE on a mixture of pretraining and chat data while OpenAI only used the pretraining corpus
B) Closed Form Solution for Latent Scaling
The closed form solution for for a latent with representation , activations and LLM activations is
- ^
Base models can probably also exhibit these behaviors in the wild (e.g. they’ve been reported to show alignment faking or sycophancy), but the frequency and triggers likely change during fine-tuning, which model diffing could catch.
- ^
See appendix B for the closed form solution.
- ^
Probably any activation function like TopK or JumpReLU that directly optimizes L0 would work similarly.
- ^
You can explore some of the latents we found in the BatchTopK crosscoder here or through our colab demo.
- ^
Concurrent work by Aranguri, Drori & Nanda (2025) also trained diff-SAEs and developed a pipeline for identifying behaviorally relevant latents: they identify high-KL tokens where base and chat models diverge, then use attribution methods to find which diff-SAE latents most reduce this KL gap when added to the base model.
- ^
You can find some SAE latents we collected here or through our colab demo.
- ^
See the first bullet point in appendix A for speculation on why this didn't work in our setting.
- ^
For the reconstruction, we patch
base_act + (chat_recon - base_recon)into the chat model. For the error, we patchbase_act + ((chat_act - base_act) - (chat_recon - base_recon)) = chat_act - chat_recon + base_recon - ^
Fraction of variance explained (FVE) measures how well does the SAE reconstruct the model activations.
- ^
Cool result using model stitching:
We experimented with progressively replacing layers of Gemma 2 2B base with corresponding layers from the chat model. This created a smooth interpolation between base and chat behavior that revealed interesting patterns:
At 50% replacement, the model began following instructions but maintained the base model’s characteristic directness. Most revealing was the model’s self-identification: when asked “Who trained you?”, early stitching stages claimed “ChatGPT by OpenAI”. Presumably, at this stage, the chat model represents that it’s a chatbot, which gets converted into ChatGPT by the base model’s prior from its training data. Only after layer 20-25 did the model correctly identify as Gemma trained by Google - suggesting these later layers encode model-specific identity.

Discuss
