
Introduction to Learning-Based Robotics
Robotic control systems have made significant progress through methods that replace hand-coded instructions with data-driven learning. Instead of relying on explicit programming, modern robots learn by observing actions and mimicking them. This form of learning, often grounded in behavioral cloning, enables robots to function effectively in structured environments. However, transferring these learned behaviors into dynamic, real-world scenarios remains a challenge. Robots need not only to repeat actions but also to adapt and refine their responses when facing unfamiliar tasks or environments, which is critical in achieving generalized autonomous behavior.
Challenges with Traditional Behavioral Cloning
One of the core limitations of robotic policy learning is the dependence on pre-collected human demonstrations. These demonstrations are used to create initial policies through supervised learning. However, when these policies fail to generalize or perform accurately in new settings, additional demonstrations are required to retrain them, which is a resource-intensive process. The inability to improve policies using the robot’s own experiences leads to inefficient adaptation. Reinforcement learning can facilitate autonomous improvement; however, its sample inefficiency and reliance on direct access to complex policy models render it unsuitable for many real-world deployments.
Limitations of Current Diffusion-RL Integration
Various methods have tried to combine diffusion-based policies with reinforcement learning to refine robot behavior. Some efforts have focused on modifying the early steps of the diffusion process or applying additive adjustments to policy outputs. Others have tried to optimize actions by evaluating expected rewards during the denoising steps. While these approaches have improved results in simulated environments, they require extensive computation and direct access to the policy’s parameters, which limits their practicality for black-box or proprietary models. Further, they struggle with the instability that comes from backpropagating through multi-step diffusion chains.
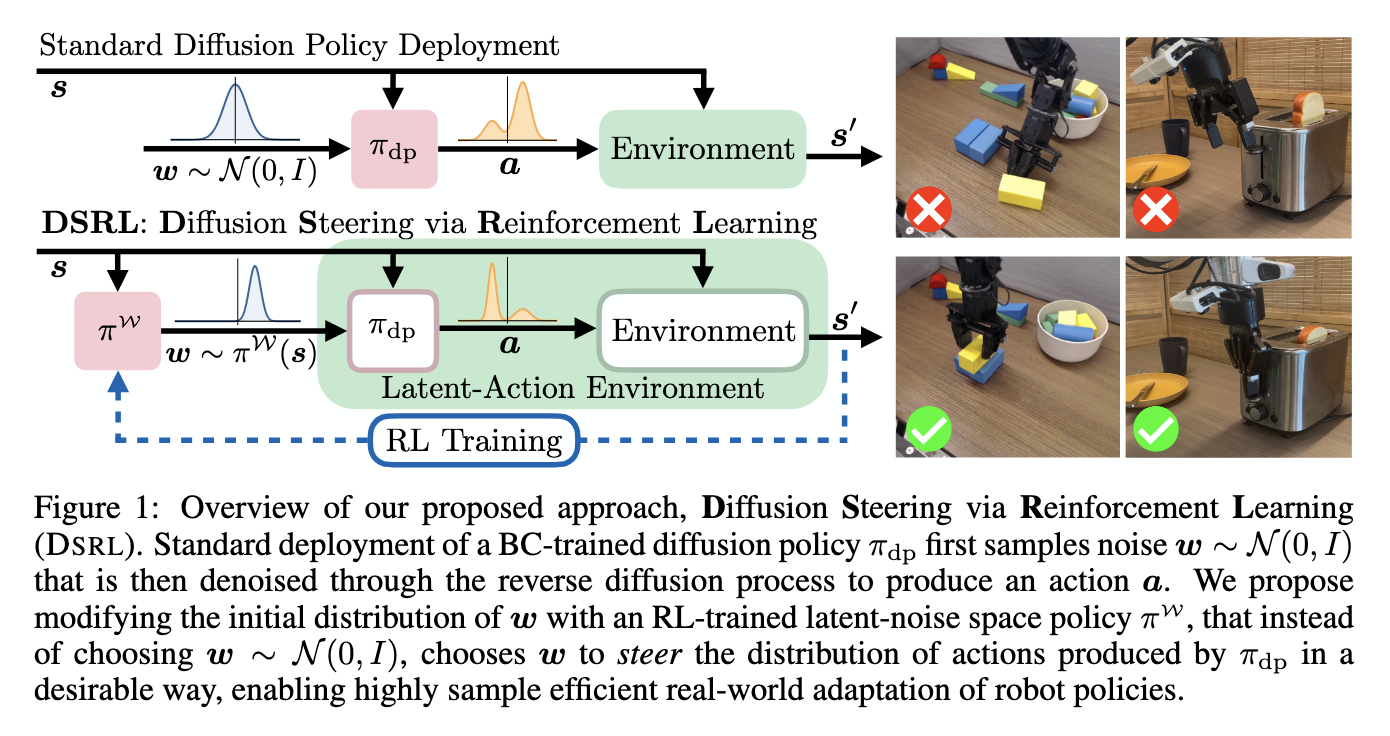
DSRL: A Latent-Noise Policy Optimization Framework
Researchers from UC Berkeley, the University of Washington, and Amazon introduced a technique called Diffusion Steering via Reinforcement Learning (DSRL). This method shifts the adaptation process from modifying the policy weights to optimizing the latent noise used in the diffusion model. Instead of generating actions from a fixed Gaussian distribution, DSRL trains a secondary policy that selects the input noise in a way that steers the resulting actions toward desirable outcomes. This allows reinforcement learning to fine-tune behaviors efficiently without altering the base model or requiring internal access.

Latent-Noise Space and Policy Decoupling
The researchers restructured the learning environment by mapping the original action space to a latent-noise space. In this transformed setup, actions are selected indirectly by choosing the latent noise that will produce them through the diffusion policy. By treating the noise as the action variable, DSRL creates a reinforcement learning framework that operates entirely outside the base policy, using only its forward outputs. This design makes it adaptable to real-world robotic systems where only black-box access is available. The policy that selects latent noise can be trained using standard actor-critic methods, thereby avoiding the computational cost of backpropagation through diffusion steps. The approach allows for both online learning through real-time interactions and offline learning from pre-collected data.
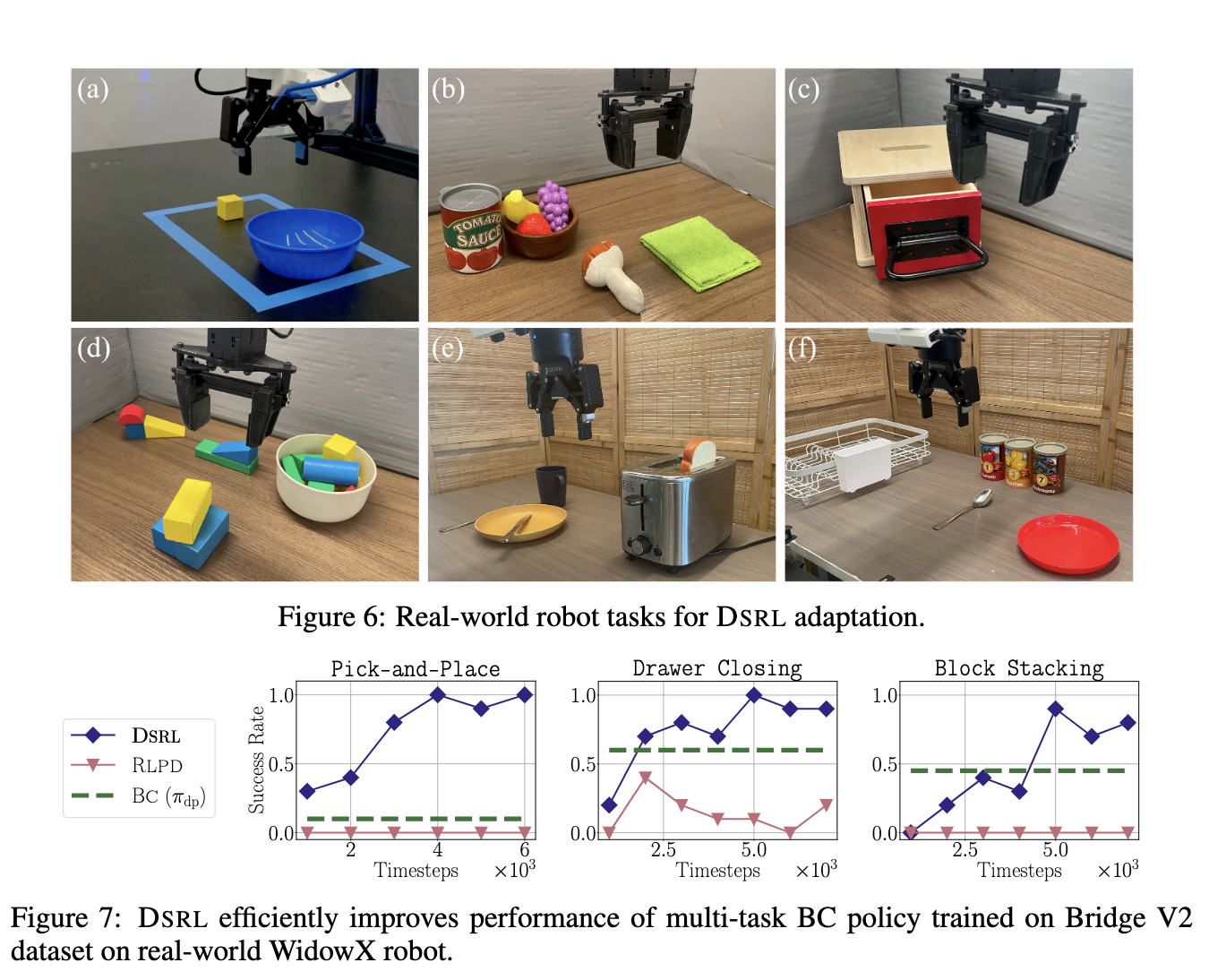
Empirical Results and Practical Benefits
The proposed method showed clear improvements in performance and data efficiency. For instance, in one real-world robotic task, DSRL improved task success rates from 20% to 90% within fewer than 50 episodes of online interaction. This represents a more than fourfold increase in performance with minimal data. The method was also tested on a generalist robotic policy named π₀, and DSRL was able to effectively enhance its deployment behavior. These outcomes were achieved without modifying the underlying diffusion policy or accessing its parameters, showcasing the method’s practicality in restricted environments, such as API-only deployments.
Conclusion
In summary, the research tackled the core issue of robotic policy adaptation without relying on extensive retraining or direct model access. By introducing a latent-noise steering mechanism, the team developed a lightweight yet powerful tool for real-world robot learning. The method’s strength lies in its efficiency, stability, and compatibility with existing diffusion models, making it a significant step forward in the deployment of adaptable robotic systems.
Check out the Paper and Project Page. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post DSRL: A Latent-Space Reinforcement Learning Approach to Adapt Diffusion Policies in Real-World Robotics appeared first on MarkTechPost.
